

代码拉取完成,页面将自动刷新
List中存储的数据是有顺序的,并且值允许重复;Map中存 储 的数据是无序的,它的键是不允许重复的,但是值是允 许重 复的;Set中存储的数据是无顺序的,并且不允许重 复,但 元素在集合中的位置是由元素的hashcode决定,即 位置是固 定的(Set集合是根据hashcode来进行数据存储 的,所以位置 是固定的,但是这个位置不是用户可以控制 的,所以对于用 户来说set中的元素还是无序的)
- ArrayList是基于数组的数据结构,LinkedList是基于链 表的 数据结构。
- ArrayList适用于查询操作,LinkedList适用于插入和删 除操 作。
HashMap和Hashtable的比较是Java面试中的常见问题, 用来 考验程序员是否能够正确使用集合类以及是否可以随机应 变使用多种思路解决问题。HashMap的工作原理、 ArrayList与Vector的比较以及这个问题是有关Java 集合框架的 最经典的问题。Hashtable是个过时的集合类,存在于Java API 中很久了。在Java 4中被重写了,实现了Map接口,所以自此以后也成了Java集合框架中的一部分。 Hashtable和HashMap在Java面试中相当容易被问到,甚至成为 了集合框架面试题中最常被考的问题,所以在参加任何 Java面试之前,都不要忘了准备这一题。 1父类不同 第一个不同主要是历史原因。Hashtable是基于陈旧的 Dictionary类的,HashMap是Java 1.2引进的Map接口的一个 实现。 public class HashMap<K, V> extendsAbstractMap<K, V> implements Cloneable, Serializable {...} public class Hashtable<K, V> extends Dictionary<K, V> implementsMap<K,V>,Cloneable, Serializable {...} 而HashMap继承的抽象类AbstractMap实现了Map接口: public abstract class AbstractMap<K, V> implements Map<K, V> {...} 2 线程安全不一样 Hashtable 中的方法是同步的,而HashMap中的方法在默 认情况下是非同步的。在多线程并发的环境下,可以直接 使用Hashtable,但是要使用HashMap的话就要自己增加 同步处理了。 3允不允许null值 Hashtable中,key和value都不允许出现null值,否则 会抛 出NullPointerException异常。而在HashMap中,null可以作为键,这样的键只有一 个; 可以有一个或多个键所对应的值为null。当get()方法返回 null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap 中 不能由get()方法来判断HashMap中是否存在某个 键, 而应该用containsKey()方法来判断。 4遍历方式的内部实现上不同 Hashtable、HashMap都使用了 Iterator。而由于历史原因, Hashtable还使用了Enumeration的方式 。 5哈希值的使用不同 HashTable直接使用对象的hashCode。而HashMap重新计 算hash值。 6 内部实现方式的数组的初始大小和扩容的方式不一样 HashTable中的hash数组初始大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16, 而且 一定是2的指数。
学习目标:
先来看看构造方法 无参数构造方法
/**
* Constructs an empty list with an
initial capacity of ten.
*/
public ArrayList()
{ this.elementData
=
DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
这是无参数的构造方法,是对elementData(元素的数 组)进行赋值DEFAULTCAPACITY_EMPTY_ELEMENTDATA (空数组,我们暂时叫做默认空数组),明明是空数组,但 是注释确实创建容量是10。好吧继续往下看。
再来看带参数的构造方法
public ArrayList(int initialCapacity) { if
(initialCapacity > 0) {
//如果initialCapacity>0,创建
initialCapacity个元素的数组
this.elementData = new
Object[initialCapacity];
} else if (initialCapacity == 0) {
//等于0时,创建空数组
this.elementData =
EMPTY_ELEMENTDATA;
} else {
//否则直接抛出异常
throw new
IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
再看另一个构造方法
public ArrayList(Collection<? extends E>
c) {
elementData = c.toArray();
if ((size = elementData.length) != 0)
{
// c.toArray might (incorrectly)
not return Object[] (see 6260652)
if (elementData.getClass() !=
Object[].class)
elementData =
Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array. this.elementData =
EMPTY_ELEMENTDATA;
}
}
就是直接将集合转为数组赋值给elementData,同时对 size赋值,并且如果size不等于0时,c.toArray might (incorrectly)notreturn Object[](see 6260652)。我也是一脸懵 逼。等于0时,直接赋值空的数组。
我们接着看add方法,先看一个参数的
public boolean add(E e)
{ ensureCapacityInternal(size + 1);//
Increments modCount!!
elementData[size++] = e;
return true;
}
就是ensureCapacityInternal(size +1) 并且将e添加到 size++的位置,我们来看ensureCapacityInternal(size + 1) 方法。
private void ensureCapacityInternal(int
minCapacity) {
if (elementData ==
DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity =
Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
看这里
if (elementData ==
DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity =
Math.max(DEFAULT_CAPACITY, minCapacity);
}
还记得空参数的构造方法吗?DEFAULT_CAPACITY = 10。也就 是当空参数时创建ArrayList时,minCapacity与 DEFAULT_CAPACITY的最大值,显然创建无参数构造方法时 minCapacity = 0.这时结果 = 10,然后看 ensureExplicitCapacity(minCapacity)
private void ensureExplicitCapacity(int
minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length
> 0)
grow(minCapacity);
}
显然调用无参数构造方法时minCapacity - elementData.length>0是成立的,我们再看 grow(minCapacity)
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; int
newCapacity = oldCapacity +
(oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity =
hugeCapacity(minCapacity);
// minCapacity is usually close to size, so
this is a win:
elementData =
Arrays.copyOf(elementData, newCapacity);
}
oldCapacity是元素个数newCapacity是 oldCapacity+oldCapacity/2,即oldCapacity的1.5倍。当 1.5倍的元素个数小于minCapacity时newCapacity = minCapacity。显然创建无参数ArrayList就是这种情况,这就解决了开头的第一个问题。调用无参数构造方法创建的是10个元素的长度。 我们再看当1.5倍元素个数大于 MAX_ARRAY_SIZE时 newCapacity = hugeCapacity(minCapacity);
private static int hugeCapacity(int
minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE)
?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
到这里我们可以总结一下了: 无参构造方法调用add之后创建的是10个长度的数组。有参 数则直接创建指定长度的数组。扩容时,小于 MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8一次扩容1.5 倍,超 过则直接Integer.MAX_VALUE。
HashMap 实际上是一个“链表散列”的数据结构,即数 组和链表的结合体。它是基于哈希表的 Map 接口的非同 步实现。
例如我们以下图为例,看一下 HashMap的内部存储结 构:
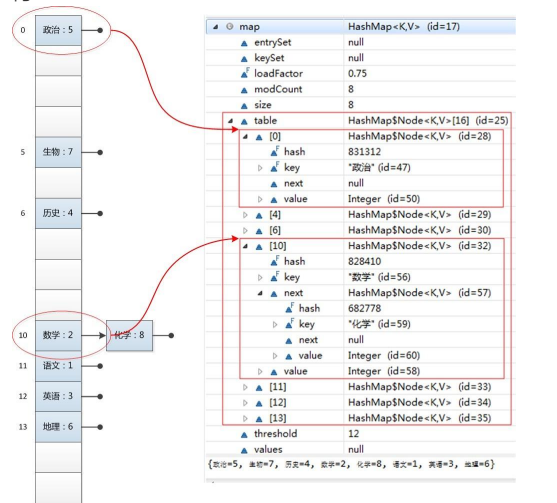
关于 HashMap 的存取过程,可参照下图:
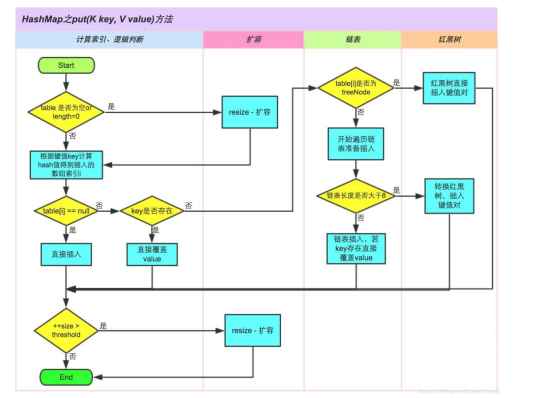
①.判断键值对数组table[i]是否为空或为null,否则执行 resize()进行扩容; ②.根据键值key计算hash值得到插入的数组索引i,如果 table[i]==null,直接新建节点添加,转向⑥,如果 table[i]不为空,转向③; ③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖 value,否则转向④,这里的相同指的是hashCode以及 equals; ④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树, 如果是红黑树,则直接在树中插入键值对,否则转向 ⑤; ⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转 换为红黑树,在红黑树中执行插入操作,否则进行链表的插入 操作;遍历过程中若发现key已经存在直接覆盖value即可; ⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大 容量threshold,如果超过,进行扩容。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。









