




![]()
![]()
| Note: SPE is now a part of imbalanced-ensemble [Doc, PyPI]. Try it for more methods and advanced features! |
 Imbalanced-Ensemble [PythonLib] 
|
 Imbalanced Learning [Awesome] 
|
 Machine Learning [Awesome] 
|
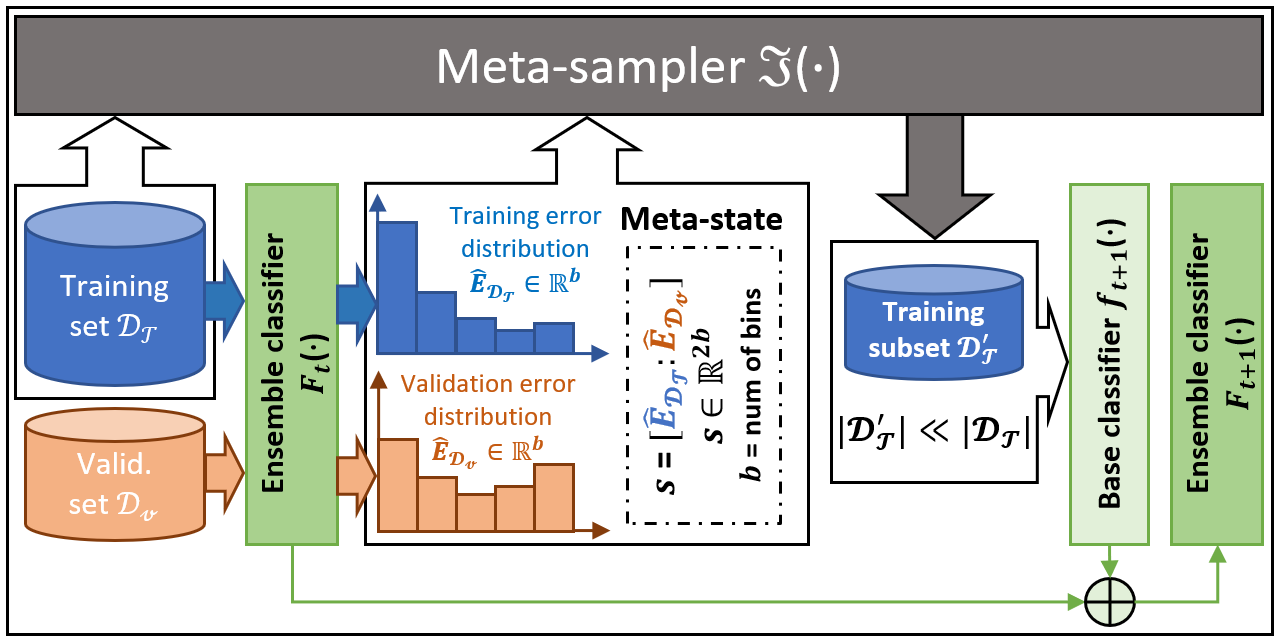 Meta-Sampler [NeurIPS] 
|
 Zhining Liu 💻 📖 💡 |
 Yuming Fu 💻 🐛 |
 Thúlio Costa 💻 🐛 |
 Neko Null 🚧 |
 lirenjieArthur 🐛 |
 AC手动机 🐛 |
 Carlo Moro 🤔 |