# EasyAnimate
**Repository Path**: Shexiaox/EasyAnimate
## Basic Information
- **Project Name**: EasyAnimate
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2024-06-10
- **Last Updated**: 2024-06-10
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# EasyAnimate | 高分辨率长视频生成的端到端解决方案
😊 EasyAnimate是一个用于生成高分辨率和长视频的端到端解决方案。我们可以训练基于转换器的扩散生成器,训练用于处理长视频的VAE,以及预处理元数据。
😊 我们基于类SORA结构与DIT,使用transformer进行作为扩散器进行视频与图片生成。我们基于motion module、u-vit和slice-vae构建了EasyAnimate,未来我们也会尝试更多的训练方案一提高效果。
😊 Welcome!
[](https://arxiv.org/abs/2405.18991)
[](https://easyanimate.github.io/)
[](https://modelscope.cn/studios/PAI/EasyAnimate/summary)
[](https://huggingface.co/spaces/alibaba-pai/EasyAnimate)
[English](./README.md) | 简体中文
# 目录
- [目录](#目录)
- [简介](#简介)
- [快速启动](#快速启动)
- [如何使用](#如何使用)
- [模型地址](#模型地址)
- [算法细节](#算法细节)
- [未来计划](#未来计划)
- [联系我们](#联系我们)
- [参考文献](#参考文献)
- [许可证](#许可证)
# 简介
EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI图片与视频、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的EasyAnimate模型直接进行预测,生成不同分辨率,6秒左右、fps24的视频(1 ~ 144帧, 未来会支持更长的视频),也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。
我们会逐渐支持从不同平台快速启动,请参阅 [快速启动](#快速启动)。
新特性:
- 更新到v2版本,最大支持144帧(768x768, 6s, 24fps)生成。[ 2024.05.26 ]
- 创建代码!现在支持 Windows 和 Linux。[ 2024.04.12 ]
功能概览:
- [数据预处理](#data-preprocess)
- [训练VAE](#vae-train)
- [训练DiT](#dit-train)
- [模型生成](#video-gen)
这些是我们的生成结果 [GALLERY](scripts/Result_Gallery.md) (点击下方的图片可查看视频):
[](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/v2/easyanimate.mp4)
我们的ui界面如下:

# 快速启动
### 1. 云使用: AliyunDSW/Docker
#### a. 通过阿里云 DSW
DSW 有免费 GPU 时间,用户可申请一次,申请后3个月内有效。
阿里云在[Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1)提供免费GPU时间,获取并在阿里云PAI-DSW中使用,5分钟内即可启动EasyAnimate
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate)
#### b. 通过docker
使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
EasyAnimateV2:
```
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git
# enter EasyAnimate's dir
cd EasyAnimate
# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-512x512.tar -O models/Diffusion_Transformer/EasyAnimateV2-XL-2-512x512.tar
cd models/Diffusion_Transformer/
tar -xvf EasyAnimateV2-XL-2-512x512.tar
cd ../../
```
(Obsolete) EasyAnimateV1:
```
# 拉取镜像
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# 进入镜像
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# clone 代码
git clone https://github.com/aigc-apps/EasyAnimate.git
# 进入EasyAnimate文件夹
cd EasyAnimate
# 下载权重
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors -O models/Motion_Module/easyanimate_v1_mm.safetensors
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors -O models/Personalized_Model/easyanimate_portrait.safetensors
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors -O models/Personalized_Model/easyanimate_portrait_lora.safetensors
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar -O models/Diffusion_Transformer/PixArt-XL-2-512x512.tar
cd models/Diffusion_Transformer/
tar -xvf PixArt-XL-2-512x512.tar
cd ../../
```
### 2. 本地安装: 环境检查/下载/安装
#### a. 环境检查
我们已验证EasyPhoto可在以下环境中执行:
Linux 的详细信息:
- 操作系统 Ubuntu 20.04, CentOS
- python: python3.10 & python3.11
- pytorch: torch2.2.0
- CUDA: 11.8
- CUDNN: 8+
- GPU: Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
我们需要大约 60GB 的可用磁盘空间,请检查!
#### b. 权重放置
我们最好将[权重](#model-zoo)按照指定路径进行放置:
EasyAnimateV2:
```
📦 models/
├── 📂 Diffusion_Transformer/
│ └── 📂 EasyAnimateV2-XL-2-512x512/
├── 📂 Personalized_Model/
│ └── your trained trainformer model / your trained lora model (for UI load)
```
(Obsolete) EasyAnimateV1:
```
📦 models/
├── 📂 Diffusion_Transformer/
│ └── 📂 PixArt-XL-2-512x512/
├── 📂 Motion_Module/
│ └── 📄 easyanimate_v1_mm.safetensors
├── 📂 Personalized_Model/
│ ├── 📄 easyanimate_portrait.safetensors
│ └── 📄 easyanimate_portrait_lora.safetensors
```
# 如何使用
1. 生成
#### a. 视频生成
##### i、运行python文件
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
- 步骤2:在predict_t2v.py文件中修改prompt、neg_prompt、guidance_scale和seed。
- 步骤3:运行predict_t2v.py文件,等待生成结果,结果保存在samples/easyanimate-videos文件夹中。
- 步骤4:如果想结合自己训练的其他backbone与Lora,则看情况修改predict_t2v.py中的predict_t2v.py和lora_path。
##### ii、通过ui界面
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
- 步骤2:运行app.py文件,进入gradio页面。
- 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。
### 2. 模型训练
一个完整的EasyAnimate训练链路应该包括数据预处理、Video VAE训练、Video DiT训练。其中Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。
a.数据预处理
我们给出了一个简单的demo通过图片数据训练lora模型,详情可以查看[wiki](https://github.com/aigc-apps/EasyAnimate/wiki/Training-Lora)。
一个完整的长视频切分、清洗、描述的数据预处理链路可以参考video caption部分的[README](easyanimate/video_caption/README.md)进行。
如果期望训练一个文生图视频的生成模型,您需要以这种格式排列数据集。
```
📦 project/
├── 📂 datasets/
│ ├── 📂 internal_datasets/
│ ├── 📂 videos/
│ │ ├── 📄 00000001.mp4
│ │ ├── 📄 00000001.jpg
│ │ └── 📄 .....
│ └── 📄 json_of_internal_datasets.json
```
json_of_internal_datasets.json是一个标准的json文件。json中的file_path可以被设置为相对路径,如下所示:
```json
[
{
"file_path": "videos/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "train/00000001.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]
```
你也可以将路径设置为绝对路径:
```json
[
{
"file_path": "/mnt/data/videos/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "/mnt/data/train/00000001.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]
```
b. Video VAE训练 (可选)
Video VAE训练是一个可选项,因为我们已经提供了训练好的Video VAE。
如果想要进行训练,可以参考video vae部分的[README](easyanimate/vae/README.md)进行。
c. Video DiT训练
如果数据预处理时,数据的格式为相对路径,则进入scripts/train_t2iv.sh进行如下设置。
```
export DATASET_NAME="datasets/internal_datasets/"
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
...
train_data_format="normal"
```
如果数据的格式为绝对路径,则进入scripts/train_t2iv.sh进行如下设置。
```
export DATASET_NAME=""
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
```
最后运行scripts/train_t2iv.sh。
```sh
sh scripts/train_t2iv.sh
```
(Obsolete) EasyAnimateV1:
如果你想训练EasyAnimateV1。请切换到git分支v1。
# 模型地址
EasyAnimateV2:
| 名称 | 种类 | 存储空间 | 下载地址 | Hugging Face | 描述 |
|--|--|--|--|--|--|
| EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-512x512.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-512x512)| 官方的512x512分辨率的重量。以144帧、每秒24帧进行训练 |
| EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV2-XL-2-768x768.tar) | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-768x768) | 官方的768x768分辨率的重量。以144帧、每秒24帧进行训练 |
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | [Download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimatev2_minimalism_lora.safetensors)| - | 使用特定类型的图像进行lora训练的结果。图片可从这里[下载](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/Minimalism.zip). |
(Obsolete) EasyAnimateV1:
### 1、运动权重
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
|--|--|--|--|--|
| easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 |
### 2、其他权重
| 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
|--|--|--|--|--|
| PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights |
| easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets |
| easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets |
# 算法细节
### 1. 数据预处理
**视频分割**
对于较长的视频分割,EasyAnimate使用PySceneDetect以识别视频内的场景变化并基于这些转换,根据一定的门限值来执行场景剪切,以确保视频片段的主题一致性。切割后,我们只保留长度在3到10秒之间的片段用于模型训练。
**视频清洗与描述**
参考SVD的数据准备流程,EasyAnimate提供了一条简单但有效的数据处理链路来进行高质量的数据筛选与打标。并且支持了分布式处理来提升数据预处理的速度,其整体流程如下:
- 时长过滤: 统计视频基本信息,来过滤时间短/分辨率低的低质量视频
- 美学过滤: 通过计算视频均匀4帧的美学得分均值,来过滤内容较差的视频(模糊、昏暗等)
- 文本过滤: 通过easyocr计算中间帧的文本占比,来过滤文本占比过大的视频
- 运动过滤: 计算帧间光流差异来过滤运动过慢或过快的视频。
- 文本描述: 通过videochat2和vila对视频帧进行recaption。PAI也在自研质量更高的视频recaption模型,将在第一时间放出供大家使用。
### 2. 模型结构
我们使用了[PixArt-alpha](https://github.com/PixArt-alpha/PixArt-alpha)作为基础模型,并在此基础上修改了VAE和DiT的模型结构来更好地支持视频的生成。EasyAnimate的整体结构如下:
下图概述了EasyAnimate的管道。它包括Text Encoder、Video VAE(视频编码器和视频解码器)和Diffusion Transformer(DiT)。T5 Encoder用作文本编码器。其他组件将在以下部分中详细说明。
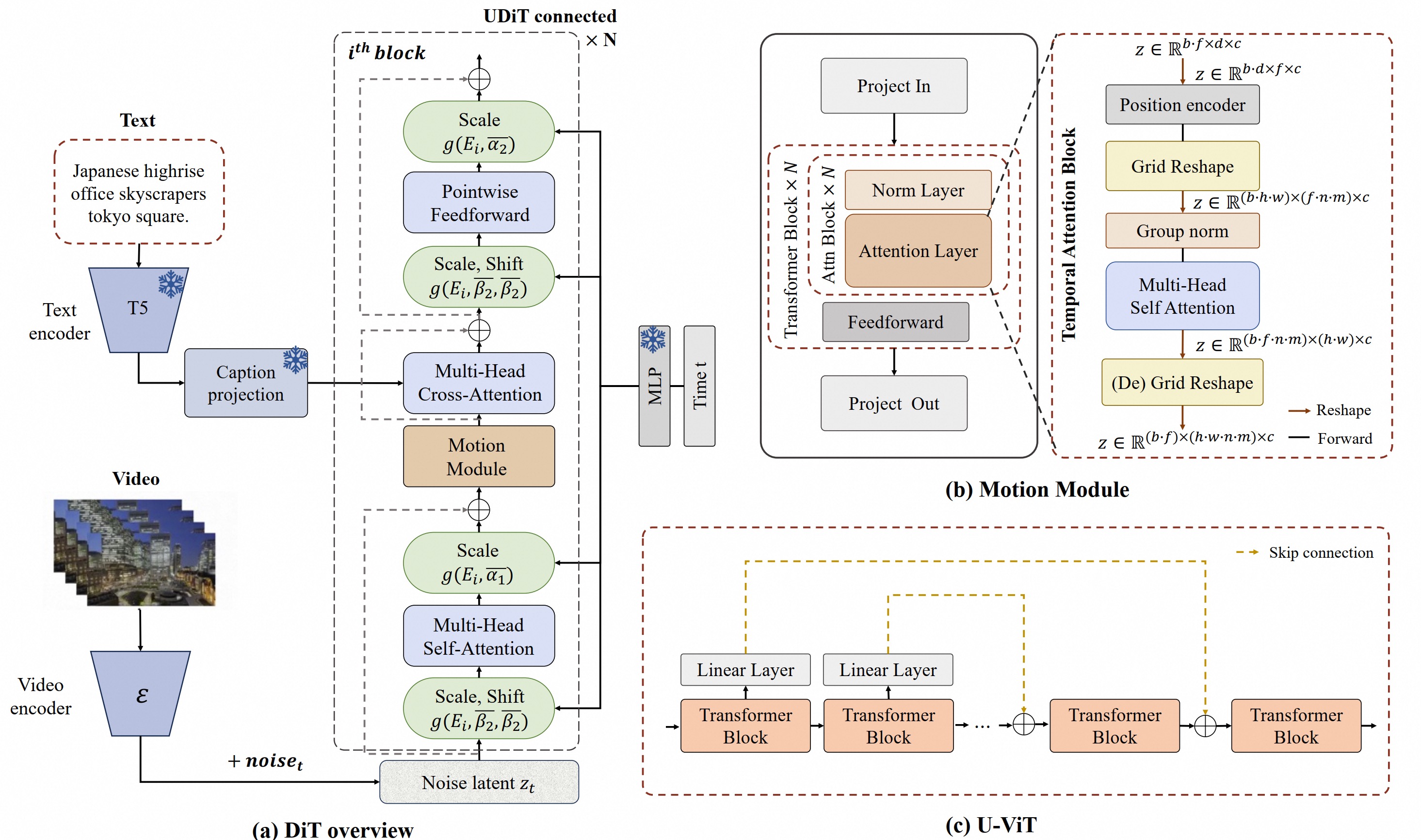 为了引入特征点在时间轴上的特征信息,EasyAnimate引入了运动模块(Motion Module),以实现从2D图像到3D视频的扩展。为了更好的生成效果,其联合图片和视频将Backbone连同Motion Module一起Finetune。在一个Pipeline中即实现了图片的生成,也实现了视频的生成。
另外,参考U-ViT,其将跳连接结构引入到EasyAnimate当中,通过引入浅层特征进一步优化深层特征,并且0初始化了一个全连接层给每一个跳连接结构,使其可以作为一个可插入模块应用到之前已经训练的还不错的DIT中。
同时,其提出了Slice VAE,用于解决MagViT在面对长、大视频时编解码上的显存困难,同时相比于MagViT在视频编解码阶段进行了时间维度更大的压缩。
更多细节可以看查看[arxiv](https://arxiv.org/abs/2405.18991)。
# 未来计划
- 支持更大分辨率的文视频生成模型。
- 支持视频inpaint模型。
# 联系我们
1. 扫描下方二维码或搜索群号:77450006752 来加入钉钉群。
2. 扫描下方二维码来加入微信群(如果二维码失效,可扫描最右边同学的微信,邀请您入群)
为了引入特征点在时间轴上的特征信息,EasyAnimate引入了运动模块(Motion Module),以实现从2D图像到3D视频的扩展。为了更好的生成效果,其联合图片和视频将Backbone连同Motion Module一起Finetune。在一个Pipeline中即实现了图片的生成,也实现了视频的生成。
另外,参考U-ViT,其将跳连接结构引入到EasyAnimate当中,通过引入浅层特征进一步优化深层特征,并且0初始化了一个全连接层给每一个跳连接结构,使其可以作为一个可插入模块应用到之前已经训练的还不错的DIT中。
同时,其提出了Slice VAE,用于解决MagViT在面对长、大视频时编解码上的显存困难,同时相比于MagViT在视频编解码阶段进行了时间维度更大的压缩。
更多细节可以看查看[arxiv](https://arxiv.org/abs/2405.18991)。
# 未来计划
- 支持更大分辨率的文视频生成模型。
- 支持视频inpaint模型。
# 联系我们
1. 扫描下方二维码或搜索群号:77450006752 来加入钉钉群。
2. 扫描下方二维码来加入微信群(如果二维码失效,可扫描最右边同学的微信,邀请您入群)


 # 参考文献
- magvit: https://github.com/google-research/magvit
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
- Open-Sora: https://github.com/hpcaitech/Open-Sora
- Animatediff: https://github.com/guoyww/AnimateDiff
# 许可证
本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
# 参考文献
- magvit: https://github.com/google-research/magvit
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
- Open-Sora: https://github.com/hpcaitech/Open-Sora
- Animatediff: https://github.com/guoyww/AnimateDiff
# 许可证
本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).