# ComfyUI-Diffusers-X-Adapter
**Repository Path**: analyzesystem/ComfyUI-Diffusers-X-Adapter
## Basic Information
- **Project Name**: ComfyUI-Diffusers-X-Adapter
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2024-03-19
- **Last Updated**: 2024-04-16
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# ComfyUI wrapper node for X-Adapter diffusers implementation.
This is meant for testing only, with the ability to use same models and python env as ComfyUI, it is NOT a proper ComfyUI implementation!
### I won't be bothering with backwards compability with this node, in many updates you will have to remake any existing nodes (or set widget values again)
# Known limitations:
- As this is only a wrapper, it's not compatible with anything else in ComfyUI, besides input preprocessing and being able to load and convert most models for the Diffusers pipeline
- Ohe ratio between 1.5 and SDXL resolution also has to be exactly 1:2
- Some ControlNets/LoRAs won't load, and results with some combos seem broken



# X-Adapter
This repository is the official implementation of [X-Adapter](https://arxiv.org/abs/2312.02238).
**[X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model](https://arxiv.org/abs/2312.02238)**
[Lingmin Ran](),
[Xiaodong Cun](https://vinthony.github.io/academic/),
[Jia-Wei Liu](https://jia-wei-liu.github.io/),
[Rui Zhao](https://ruizhaocv.github.io/),
[Song Zijie](),
[Xintao Wang](https://xinntao.github.io/),
[Jussi Keppo](https://www.jussikeppo.com/),
[Mike Zheng Shou](https://sites.google.com/view/showlab)
[](https://showlab.github.io/X-Adapter/)
[](https://arxiv.org/abs/2312.02238)

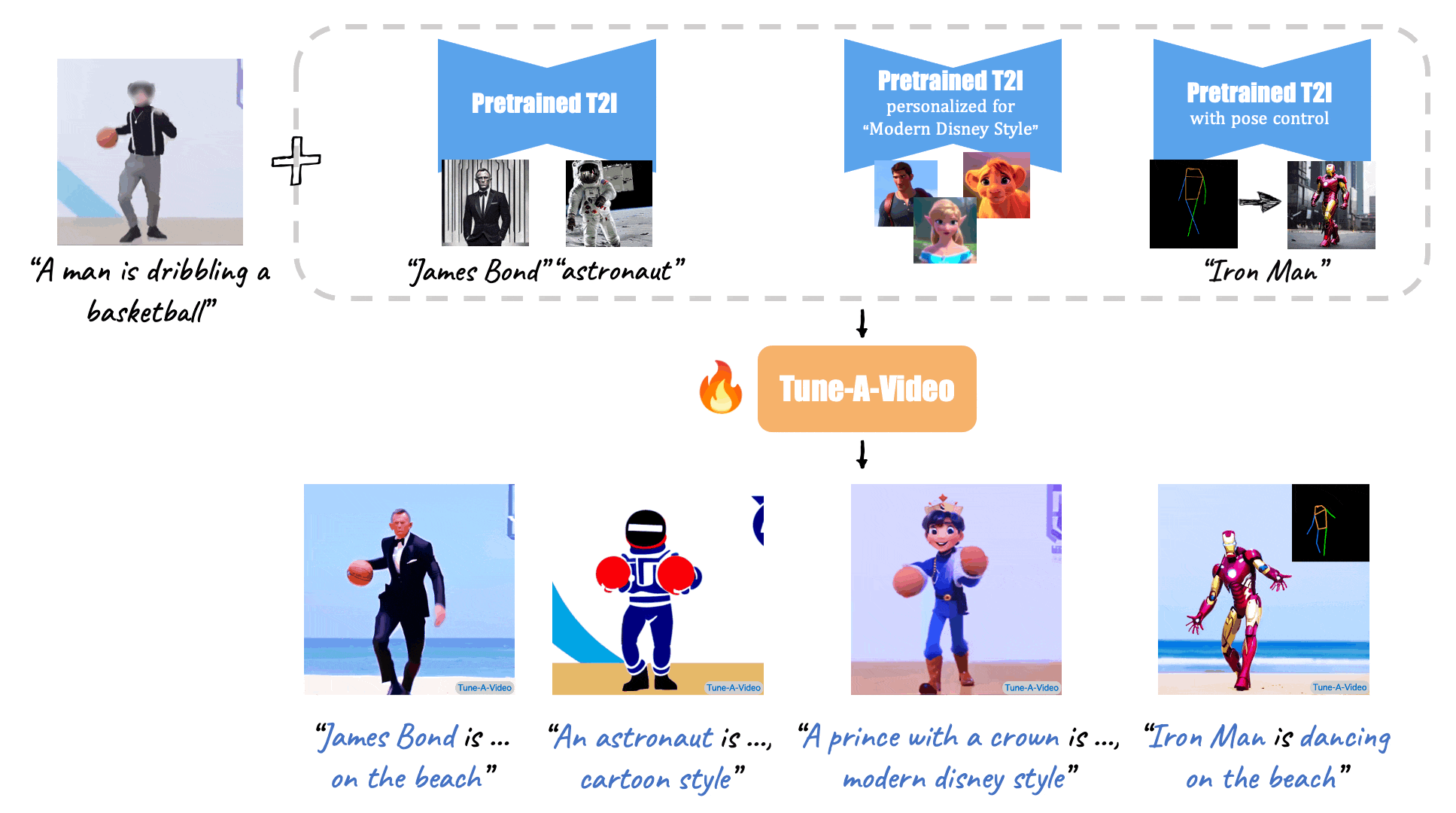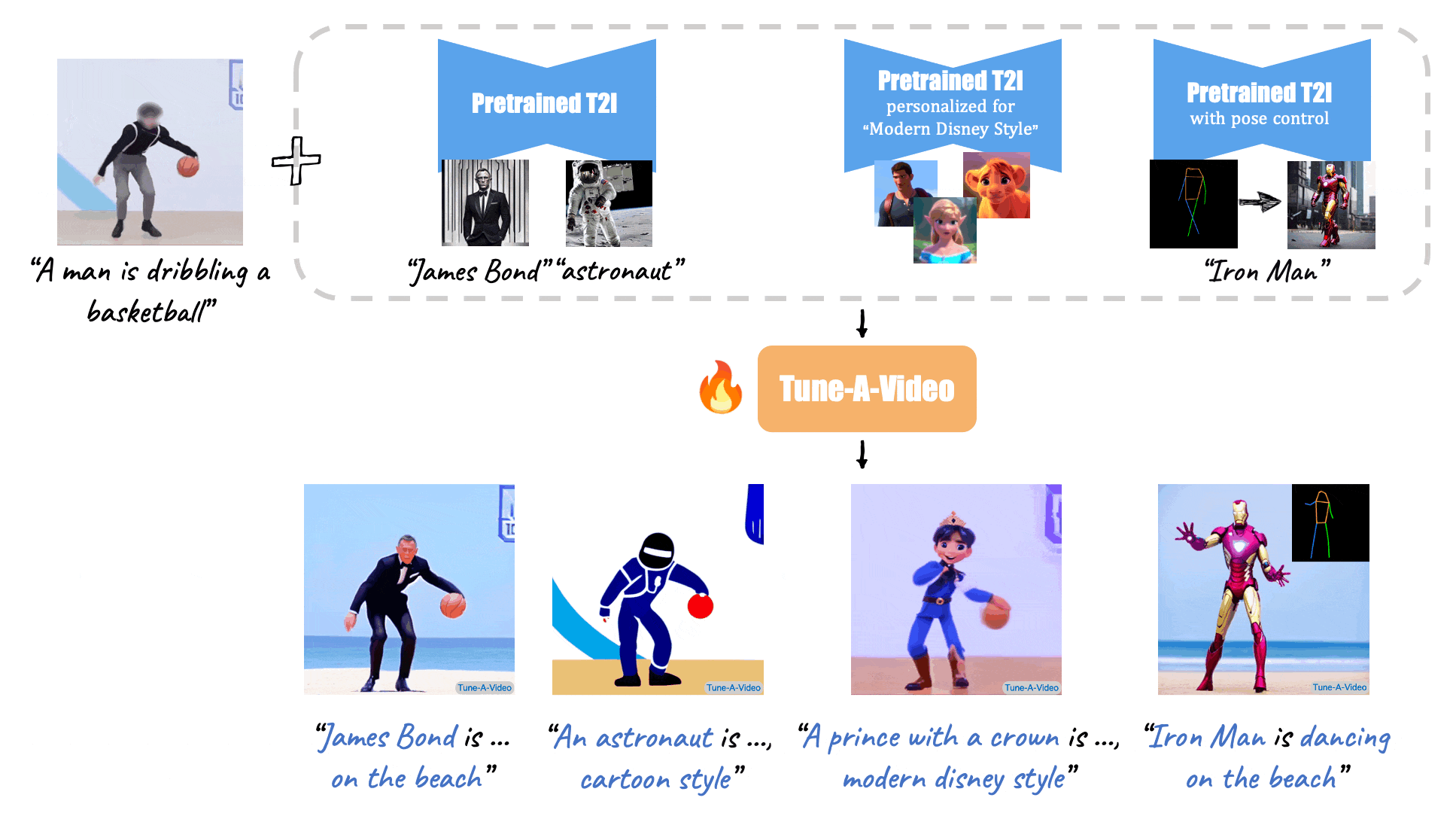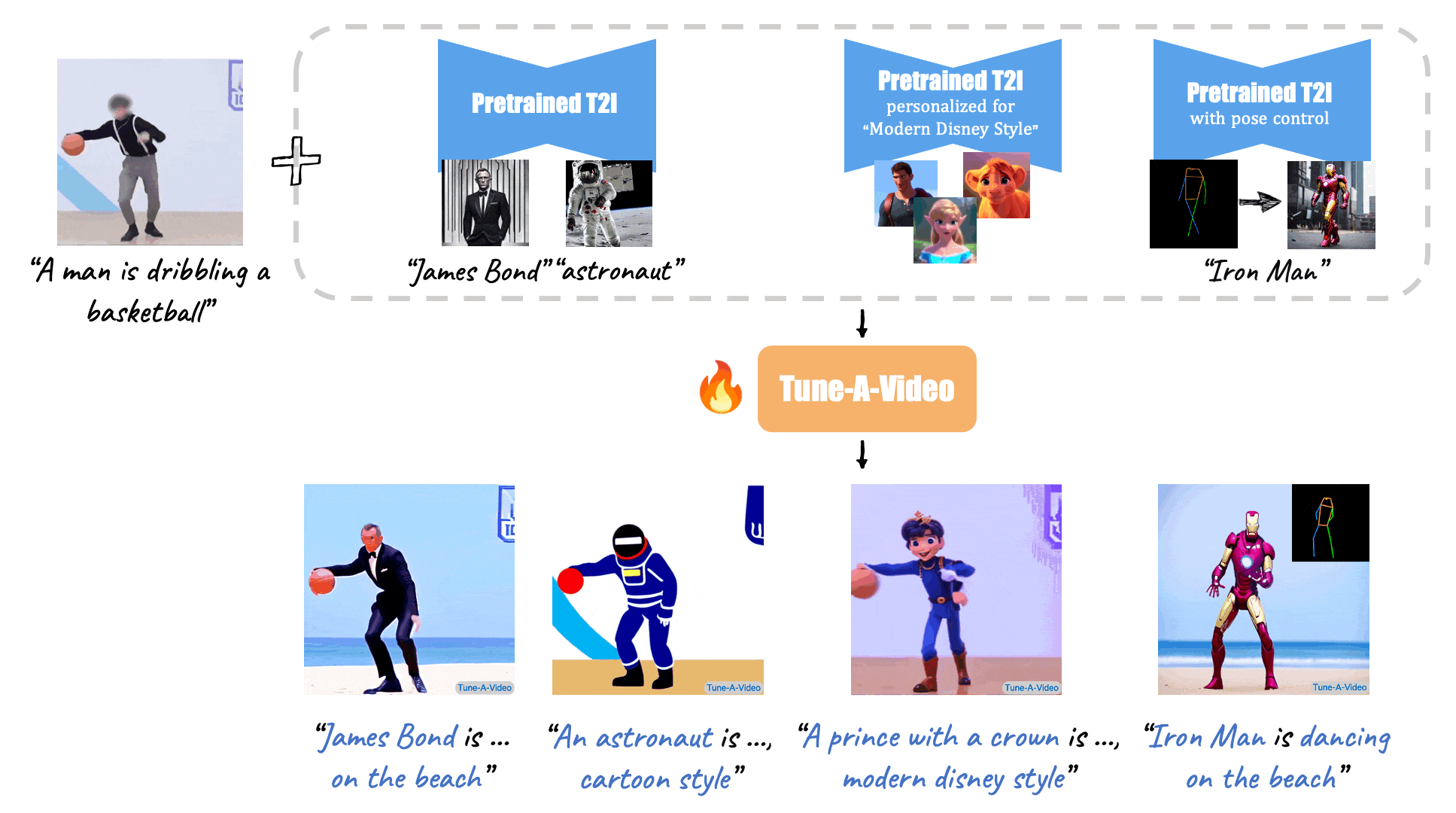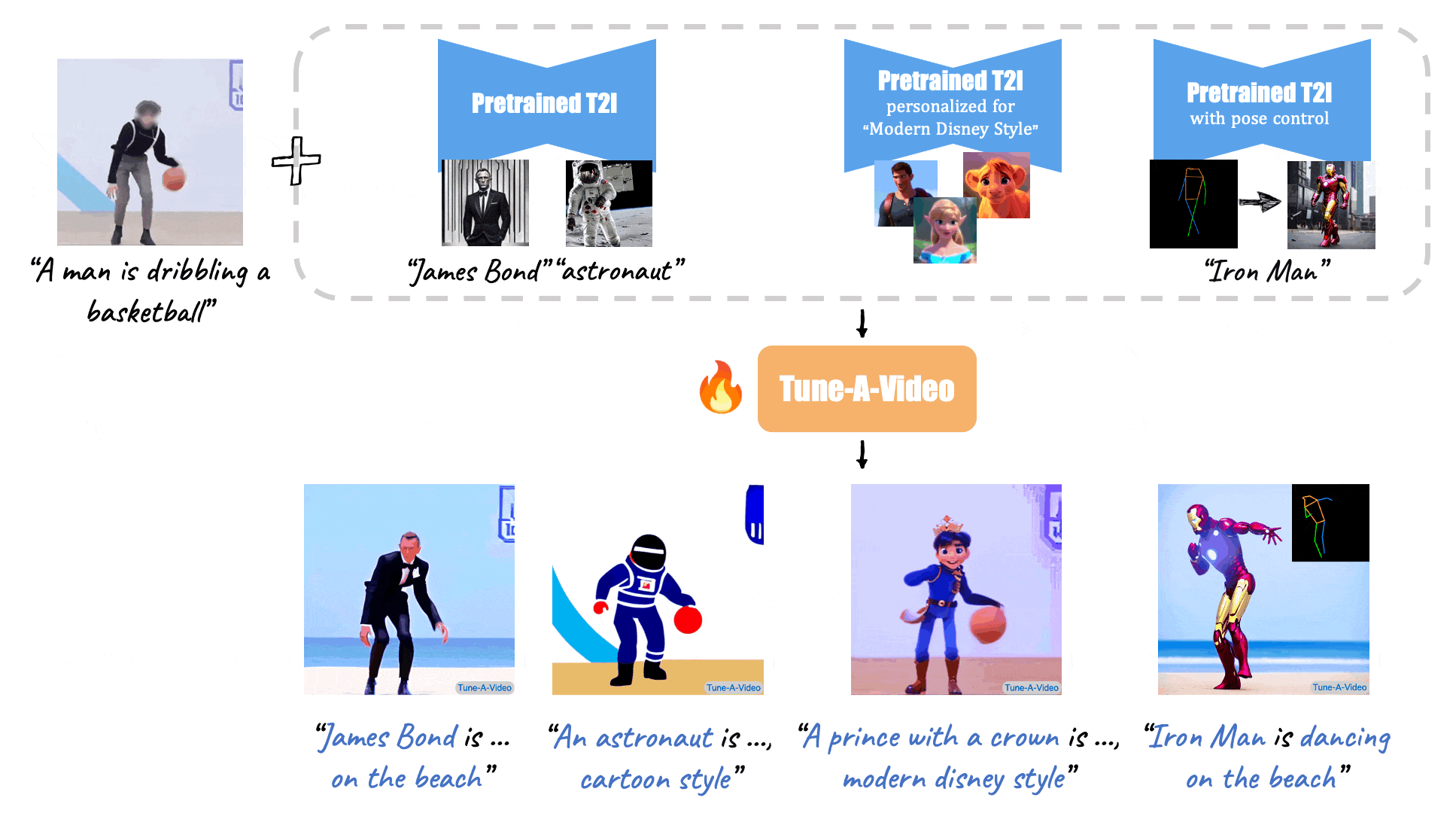
X-Adapter enable plugins pretrained on old version (e.g. SD1.5) directly work with the upgraded Model (e.g., SDXL) without further retraining.
[//]: # ()
[//]: # ( )
[//]: # (
)
[//]: # (
)
[//]: # (Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.)
[//]: # (
)
## Cite
If you find X-Adapter useful for your research and applications, please cite us using this BibTeX:
```bibtex
@article{ran2023xadapter,
title={X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model},
author={Lingmin Ran and Xiaodong Cun and Jia-Wei Liu and Rui Zhao and Song Zijie and Xintao Wang and Jussi Keppo and Mike Zheng Shou},
journal={arXiv preprint arXiv:2312.02238},
year={2023}
}
```