diff --git a/README.md b/README.md
index c507dfef8b4952b337ff57d78867150464c16606..14e06b081854e0b5e4166a74ef7790c11d60a35d 100644
--- a/README.md
+++ b/README.md
@@ -1,84 +1,114 @@
# CATLASS
-## 📌简介
+## 📌 简介
-CATLASS,中文名为昇腾算子模板库,是一个聚焦于提供高性能矩阵乘类算子基础模板的代码库。
+CATLASS(**CA**NN **T**emplates for **L**inear **A**lgebra **S**ubroutine**s**),中文名为昇腾算子模板库,是一个聚焦于提供高性能矩阵乘类算子基础模板的代码库。
通过抽象分层的方式将矩阵类算子代码模板化。算子计算逻辑可以进行白盒化组装,让算子代码可复用,可替换,可局部修改。针对昇腾硬件特点进行设计,可以支持复杂场景流水排布,如FA等。在上层代码逻辑共享的同时,可以支持底层硬件差异特化。
-本代码仓为CATLASS联创代码仓。结合昇腾生态力量,共同设计研发算子模板,并提供典型算子的高性能实现代码样例
+本代码仓为CATLASS联创代码仓。结合昇腾生态力量,共同设计研发算子模板,并提供典型算子的高性能实现代码样例。
-## 🧩模板分层设计
+## 🧩 模板分层设计
-
+
分层详细介绍和各层级api,见[api](docs/api.md)文档。
-## 📂目录结构说明
+## 📁 目录结构说明
+```bash
+catlass
+├── cmake # cmake工程文件
+├── docs # 文档
+├── examples # kernel使用样例
+├── include # 模板头文件
+├── scripts # 编译脚本
+└── tests # 测试用例
```
-├── docs // 文档
-├── examples // kernel使用样例
-├── include // 模板头文件
-└── scripts // 相关脚本
-```
-
-## 💻软件硬件配套说明
-
-硬件型号支持:
-- Atlas 800T A2 服务器
-- Atlas 200T A2 Box16服务器
+## 💻 软件硬件配套说明
-平台:aarch64/x86
+- 硬件平台:
+ - **CPU**: `aarch64`/`x86_64`
+ - **NPU**: `Atlas A2`系列产品
-配套软件:
+- 软件版本:
+ - `gcc >= 9.3`
+ - `cmake >= 3.15`
+ - `python >= 3.10`
-- gcc >= 9.3
-- cmake >= 3.15
-- python >= 3.10
-
-CANN版本要求:
+- CANN版本:
| CANN包类别 | 版本要求 | 获取方式 |
| ---------- | --------------------------- | -------------------------------------------------------------------------------------------------------------------- |
| 社区版 | 8.2.RC1.alpha002 及之后版本 | [社区CANN包下载地址](https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.2.RC1.alpha002) |
| 商用版 | 8.1.RC1及之后版本 | 请咨询对应Support/SupportE获取 |
-## 🚀快速上手
+- 对于某些调测工具,可能需要较以上版本更加新的CANN版本,可参考[调测工具文档](#toolbox)。
-详细请参考[quickstart](docs/quickstart.md)
-设置环境变量
+## 🚀 快速上手
-```
+以`00_basic_matmul`算子样例为例,快速上手CATLASS算子开发:
+
+1. 使能CANN环境变量
+
+```bash
# root用户安装(默认路径)
source /usr/local/Ascend/ascend-toolkit/set_env.sh
```
-执行一个样例matmul算子。
-在代码仓目录下,运行编译脚本。
+2. 编译算子样例
-```
+```bash
bash scripts/build.sh 00_basic_matmul
```
-切换到可执行文件的编译目录`build/bin`下,执行算子样例程序。
+3. 执行算子样例
+切换到可执行文件的编译目录`output/bin`下,执行算子样例程序。
-```
-cd build/bin
+```bash
+cd output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID(可选)
./00_basic_matmul 256 512 1024 0
```
-## 👥合作贡献者
+出现`Compare success.`打屏,说明算子运行成功,精度比较通过。
+
+## 📚 文档介绍
+
+### 📖 API文档
+
+- [api](./docs/api.md) - CATLASS通用矩阵乘法Gemm API的描述。
+- [dispatch_policies](./docs/dispatch_policies.md) - BlockMmad一个重要模板参数`DispatchPolicy`的描述。
+- [quickstart](./docs/quickstart.md) - 模板库的快速开始。
+- [swizzle_explanation](./docs/swizzle_explanation.md) - AI Core计算基本块的顺序之Swizzle策略的描述。
+
+### 🧰 调测工具文档
+
+我们已经在CATLASS示例工程中适配了大多数CANN提供的调测工具,开发算子时,可基于CATLASS示例工程进行初步开发调优,无需关注具体的工具适配操作,待算子基础功能、性能达到预期,再迁移到其他工程中。
+
+#### 🚗 功能调试
+
+- [msDebug](./docs/tools/msdebug.md) - 类gdb/lldb的调试工具msDebug
+ - ⚠️ **注意** 这个功能依赖于[8.2.RC1.alpha003](https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.2.RC1.alpha003)版本的社区版或`8.2.RC1`之后的商用版。
+- [printf](./docs/tools/print.md) - 在算子device代码进行打印调试
+ - ⚠️ **注意** 这个功能将在未来的`CANN 8.3`开始支持。
+
+#### ✈️ 性能调优
+
+- [msProf&Profiling](./docs/tools/performance_tools.md) - 性能调优工具`msProf`和`Profiling`
+ - [单算子性能分析:msProf](./docs/tools/performance_tools.md#用msProf进行单算子性能分析)
+ - [整网性能分析:Profiling](./docs/tools/performance_tools.md#用Profiling进行整网性能分析)
+
+## 👥 合作贡献者
-华南理工大学 陆璐教授团队
+[华南理工大学 陆璐教授团队](https://www2.scut.edu.cn/cs/2017/0629/c22284a328108/page.htm)
-## 🔒安全声明
+## 🔒 安全声明
[CATLASS仓库 安全声明](./SECURITYNOTE.md)
-## ©️版权声明
+## ©️ 版权声明
Copyright (c) 2025 Huawei Technologies Co., Ltd.
@@ -92,6 +122,6 @@ INCLUDING BUT NOT LIMITED TO NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE.
See LICENSE in the root of the software repository for the full text of the License.
-## 📜许可证
+## 📜 许可证
[CANN Open Software License Agreement Version 1.0](LICENSE)
diff --git a/docs/quickstart.md b/docs/quickstart.md
index 3988413a61968eb92c6c5bb23f365c39867025d1..c6715229b67f07f8a9da499c8ae923ad73d61d47 100644
--- a/docs/quickstart.md
+++ b/docs/quickstart.md
@@ -5,12 +5,12 @@
下载CANN开发套件包,点击[下载链接](https://www.hiascend.com/zh/developer/download/community/result?module=cann)选择对应的开发套件包`Ascend-cann-toolkit__linux-.run`。 CANN开发套件包依赖固件驱动,如需安装请查阅[安装NPU驱动固件](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/800alpha002/softwareinst/instg/instg_0005.html?Mode=PmIns&OS=Ubuntu&Software=cannToolKit)页面。
安装CANN开发套件包。以下为root用户默认路径安装演示。
-```
+```bash
chmod +x Ascend-cann-toolkit__linux-.run
./Ascend-cann-toolkit__linux-.run --install
```
设置环境变量
-```
+```bash
source /usr/local/Ascend/ascend-toolkit/set_env.sh
```
@@ -20,7 +20,7 @@ source /usr/local/Ascend/ascend-toolkit/set_env.sh
Kernel层模板由Block层组件构成。这里首先定义三个Block层组件。
``。
1. `BlockMmad_`为block层mmad计算接口,定义方式如下:
-```
+```c++
using DispatchPolicy = Catlass::Gemm::MmadAtlasA2Pingpong; //流水排布使用
using L1TileShape = Catlass::GemmShape<128, 256, 256>; // L1基本块
using L0TileShape = Catlass::GemmShape<128, 256, 64>; // L0基本块
@@ -36,21 +36,21 @@ using BlockMmad = Catlass::Gemm::Block::BlockMmad;
```
2. `BlockEpilogue_`为block层后处理,本文构建基础matmul,不涉及后处理,这里传入void。
-```
+```c++
using BlockEpilogue = void;
```
3. `BlockScheduler_`该模板类定义数据走位方式,提供计算offset的方法。此处使用定义好的GemmIdentityBlockSwizzle。参考[Swizzle策略说明](swizzle_explanation.md)文档了解更多swizzle信息。
-```
+```c++
using BlockScheduler = typename Catlass::Gemm::Block::GemmIdentityBlockSwizzle<>;
```
4. 基于上述组件即可完成BasicMatmul示例的Kernel层组装。
-```
+```c++
using MatmulKernel = Catlass::Gemm::Kernel::BasicMatmul;
```
### Device层算子定义
基于Kernel层组装的算子,完成核函数的编写。
1. 使用CATLASS_GLOBAL修饰符定义Matmul函数,并传入算子的类型参数。
-```
+```c++
template <
class LayoutA,
class LayoutB,
@@ -64,17 +64,17 @@ void BasicMatmul(
GM_ADDR gmC, LayoutC layoutC);
```
2. BasicMatmul的调用接口为`()`运算符,需要传入Params作为参数。
-```
+```c++
typename MatmulKernel::Params params{problemShape, gmA, layoutA, gmB, layoutB, gmC, layoutC};
```
3. 最后,实例化一个kernel,并执行该算子。
-```
+```c++
MatmulKernel matmul;
matmul(params);
```
### 算子调用
调用算子我们需要指定矩阵的输入输出的数据类型和数据排布信息,并使用`<<<>>>`的方式调用核函数。
-```
+```c++
BasicMatmul<<>>(
options.problemShape, deviceA, layoutA, deviceB, layoutB, deviceC, layoutC);
```
@@ -92,7 +92,7 @@ catlass_example_add_executable(
)
```
在项目目录下,调用`build.sh`,即可编译examples中的kernel代码。
-```
+```bash
# 编译examples内所有用例
bash scripts/build.sh catlass_examples
# 编译指定用例
@@ -106,7 +106,7 @@ cd output/bin
./00_basic_matmul 256 512 1024 0
```
执行结果如下,表明基于CATLASS编写的Kernel已经成功执行。
-```
+```bash
Compare success.
```
### 代码样例
diff --git a/docs/tools/msdebug.md b/docs/tools/msdebug.md
new file mode 100644
index 0000000000000000000000000000000000000000..ac07aa68a9aed54c60245a82f0ab0eaab1697705
--- /dev/null
+++ b/docs/tools/msdebug.md
@@ -0,0 +1,366 @@
+# 在CATLASS样例工程使用msDebug
+
+`msDebug`是用于调试在NPU侧运行的算子程序的一个工具,该工具向算子开发人员提供了在昇腾设备上调试算子的手段。调试手段包括了读取昇腾设备内存与寄存器、暂停与恢复程序运行状态等。
+
+- ⚠️ **注意** 这个功能依赖于[8.2.RC1.alpha003](https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.2.RC1.alpha003)版本的社区版或`8.2.RC1`之后的商用版。
+
+# 使用示例
+
+下面以对`00_basic_matmul`为例,进行msDebug调试的使用说明。
+
+## 使能驱动的调试功能
+
+参考[msDebug工具概述](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/82RC1alpha003/devaids/optool/atlasopdev_16_0062.html),以`debug`模式安装驱动,或在`full`模式安装的驱动下执行`echo 1 > /proc/debug_switch`打开调试通道。
+
+为了避免出现安全问题,请勿在生产环境启用调试通道!
+
+- 若出现以下问题,说明驱动版本较低,需更新驱动。
+
+```bash
+msdebug failed to initialize. please install HDK.
+[ERROR] error code: 0x20102
+terminate called after throwing an instance of 'MSDEBUG_ERROR_CODE'
+```
+
+## 编译运行
+
+1. 基于[快速上手](../../README.md#快速上手),打开工具的编译开关`--debug --msdebug`,使能`debug`与`msdebug`编译算子样例。
+
+```bash
+bash scripts/build.sh --debug --msdebug 00_basic_matmul
+```
+
+- `--debug`同时控制host与device侧代码的debug开关,`--msdebug`控制device侧代码的debug开关。
+- 若只增加`--debug`,只会启用host的调试功能,仅能用gdb/lldb调试host侧代码。
+
+2. 切换到可执行文件的编译目录 `output/bin` 下,使用`msdebug`执行算子样例程序。
+
+```bash
+cd output/bin
+# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID(可选)
+msdebug ./00_basic_matmul 256 512 1024 0
+```
+
+```bash
+msdebug ./00_basic_matmul 256 512 1024 0
+msdebug(MindStudio Debugger) is part of MindStudio Operator-dev Tools.
+The tool provides developers with a mechanism for debugging Ascend kernels running on actual hardware.
+This enables developers to debug Ascend kernels without being affected by potential changes brought by simulation and emulation environments.
+(msdebug) target create "./00_basic_matmul"
+Current executable set to '/home/catlass/output/bin/00_basic_matmul' (aarch64).
+(msdebug) settings set -- target.run-args "256" "512" "1024" "0"
+(msdebug)
+```
+
+## 命令行调试
+
+### 设置断点和程序执行
+
+通过命令`b basic_matmul.cpp:81`和`b basic_matmul.cpp:128`设置两个断点,再用`breakpoint list`查看已有断点。
+
+```bash
+(msdebug) b basic_matmul.cpp:81
+Breakpoint 1: where = 00_basic_matmul`Run(Options const&) + 416 at basic_matmul.cpp:81:18, address = 0x000000000019e8dc
+(msdebug) b basic_matmul.cpp:128
+Breakpoint 2: where = 00_basic_matmul`Run(Options const&) + 2816 at basic_matmul.cpp:138:39, address = 0x000000000019f23c
+(msdebug) breakpoint list
+Current breakpoints:
+1: file = 'basic_matmul.cpp', line = 81, exact_match = 0, locations = 1
+ 1.1: where = 00_basic_matmul`Run(Options const&) + 416 at basic_matmul.cpp:81:18, address = 00_basic_matmul[0x000000000019e8dc], unresolved, hit count = 0
+
+2: file = 'basic_matmul.cpp', line = 128, exact_match = 0, locations = 1
+ 2.1: where = 00_basic_matmul`Run(Options const&) + 2816 at basic_matmul.cpp:138:39, address = 00_basic_matmul[0x000000000019f23c], unresolved, hit count = 0
+
+(msdebug)
+```
+
+执行命令`r`,程序将开始运行直到第一个断点处,再执行命令`c`,程序将运行到下一个断点。需要注意的是,对于多核程序而言,算子程序通常会被下发至多个加速核并发运行,一旦某一个加速核命中了断点,会通过中断通知其他的加速核立即停下,因此不保证其他的加速核也一定同时在该断点停下,而且相同的断点也可能被其他的加速核再次命中,开发者可配合禁用/删除断点命令来防止加速核不停命中同一个断点的情况。
+
+```bash
+(msdebug) r
+Process 813993 launched: '/home/catlass/output/bin/00_basic_matmul' (aarch64)
+Process 813993 stopped
+* thread #1, name = '00_basic_matmul', stop reason = breakpoint 1.1
+ frame #0: 0x0000aaaaaac3e8dc 00_basic_matmul`Run(options=0x0000ffffffffe340) at basic_matmul.cpp:81:18
+ 78 ACL_CHECK(aclrtCreateStream(&stream));
+ 79
+ 80 uint32_t m = options.problemShape.m();
+-> 81 uint32_t n = options.problemShape.n();
+ 82 uint32_t k = options.problemShape.k();
+ 83
+ 84 size_t lenA = static_cast(m) * k;
+(msdebug) c
+Process 813993 resuming
+Process 813993 stopped
+* thread #1, name = '00_basic_matmul', stop reason = breakpoint 2.1
+ frame #0: 0x0000aaaaaac3f23c 00_basic_matmul`Run(options=0x0000ffffffffe340) at basic_matmul.cpp:138:39
+ 135 using MatmulKernel = Gemm::Kernel::BasicMatmul;
+ 136
+ 137 using MatmulAdapter = Gemm::Device::DeviceGemm;
+-> 138 MatmulKernel::Arguments arguments{options.problemShape, deviceA, deviceB, deviceC};
+ 139 MatmulAdapter matmul_op;
+ 140 matmul_op.CanImplement(arguments);
+ 141 size_t sizeWorkspace = matmul_op.GetWorkspaceSize(arguments);
+(msdebug) c
+Process 813993 resuming
+[Launch of Kernel _ZN7Catlass13KernelAdapterINS_4Gemm6Kernel11BasicMatmulINS1_5Blo on Device 0]
+Compare success.
+Process 813993 exited with status = 0 (0x00000000)
+(msdebug)
+```
+
+### 查看变量和内存
+
+如果想查看标量,通过`p`指令,可以直接查看当前n变量的值。
+
+```bash
+Process 814079 launched: '/home/catlass/output/bin/00_basic_matmul' (aarch64)
+Process 814079 stopped
+* thread #1, name = '00_basic_matmul', stop reason = breakpoint 1.1
+ frame #0: 0x0000aaaaaac3e8dc 00_basic_matmul`Run(options=0x0000ffffffffe340) at basic_matmul.cpp:81:18
+ 78 ACL_CHECK(aclrtCreateStream(&stream));
+ 79
+ 80 uint32_t m = options.problemShape.m();
+-> 81 uint32_t n = options.problemShape.n();
+ 82 uint32_t k = options.problemShape.k();
+ 83
+ 84 size_t lenA = static_cast(m) * k;
+(msdebug) p n
+(uint32_t) $0 = 0
+```
+
+如果想查看内存,先通过`p`指令,查看当前内存的信息。
+
+然后通过`x -m UB -f float32[] 65536 -c 4 -s 4`命令,可以打印accumulatorBuffer内存中的值,一次最多打印1024字节。
+
+```bash
+(msdebug) c
+Process 814339 resuming
+Process 814339 stopped
+[Switching to focus on Kernel _ZN7Catlass13KernelAdapterINS_4Gemm6Kernel12SplitkMatmulINS1_5Bl, CoreId 0, Type aiv]
+* thread #1, name = '09_splitk_matmu', stop reason = breakpoint 2.1
+ frame #0: 0x000000000000bf98 device_debugdata`_ZN7Catlass4Gemm6Kernel9ReduceAddINS_4Arch7AtlasA2EfDhLj8192EEclERKN7AscendC12GlobalTensorIDhEERKNS7_IfEEmj_mix_aiv(this=0x00000000001cf838, dst=0x00000000001cf930, src=0x00000000001cf908, elementCount=131072, splitkFactor=2) at splitk_matmul.hpp:136:19
+ 133
+ 134 AscendC::SetFlag(outputEventIds[bufferIndex]);
+ 135 AscendC::WaitFlag(outputEventIds[bufferIndex]);
+-> 136 Ub2Gm(dst[loopIdx * tileLen], outputBuffer[bufferIndex], actualTileLen);
+ 137 AscendC::SetFlag(outputEventIds[bufferIndex]);
+ 138
+ 139 bufferIndex = (bufferIndex + 1) % BUFFER_NUM;
+(msdebug) p outputBuffer
+(AscendC::LocalTensor<__fp16>[2]) $2 = {
+ [0] = {
+ AscendC::BaseLocalTensor<__fp16> = { # 内存、数据类型
+ address_ = (dataLen = 131072, bufferAddr = 65536, bufferHandle = "", logicPos = '\v') # 起始地址、数据长度
+ }
+ shapeInfo_ = {
+ shapeDim = '\x88'
+ originalShapeDim = '\xf8'
+ shape = {}
+ originalShape = {}
+ dataFormat = ND
+ }
+ }
+ [1] = {
+ AscendC::BaseLocalTensor<__fp16> = {
+ address_ = (dataLen = 49152, bufferAddr = 147456, bufferHandle = "", logicPos = '\v')
+ }
+ shapeInfo_ = {
+ shapeDim = '\x88'
+ originalShapeDim = '\xf8'
+ shape = {}
+ originalShape = {}
+ dataFormat = ND
+ }
+ }
+}
+(msdebug) x -m UB -f float16[] 65536 -c 4 -s 4 # 在UB内存中从65536的地址分打印4行4字节的fp16数据
+0x00010000: {355.5 188.75}
+0x00010004: {244.125 -364.75}
+0x00010008: {-104.875 -156}
+0x0001000c: {232 -100.75}
+(msdebug) x -m UB -f float16[] 65536 -c 4 -s 8 # 在UB内存中从65536的地址分打印4行8字节的fp1数据
+0x00010000: {355.5 188.75 244.125 -364.75}
+0x00010008: {-104.875 -156 232 -100.75}
+0x00010010: {-47.4062 105.875 -322.5 -265.75}
+0x00010018: {260 200.125 -139.25 -190.625}
+(msdebug)
+```
+
+如果想逐行调试,运行命令`n`,使程序运行至下一行
+
+```bash
+(msdebug) n
+Process 814339 stopped
+[Switching to focus on Kernel _ZN7Catlass13KernelAdapterINS_4Gemm6Kernel12SplitkMatmulINS1_5Bl, CoreId 0, Type aiv]
+* thread #1, name = '09_splitk_matmu', stop reason = step over
+ frame #0: 0x000000000000bfe4 device_debugdata`_ZN7Catlass4Gemm6Kernel9ReduceAddINS_4Arch7AtlasA2EfDhLj8192EEclERKN7AscendC12GlobalTensorIDhEERKNS7_IfEEmj_mix_aiv(this=0x00000000001cf838, dst=0x00000000001cf930, src=0x00000000001cf908, elementCount=131072, splitkFactor=2) at splitk_matmul.hpp:137:73
+ 134 AscendC::SetFlag(outputEventIds[bufferIndex]);
+ 135 AscendC::WaitFlag(outputEventIds[bufferIndex]);
+ 136 Ub2Gm(dst[loopIdx * tileLen], outputBuffer[bufferIndex], actualTileLen);
+-> 137 AscendC::SetFlag(outputEventIds[bufferIndex]);
+ 138
+ 139 bufferIndex = (bufferIndex + 1) % BUFFER_NUM;
+ 140 }
+(msdebug) n
+Process 814339 stopped
+[Switching to focus on Kernel _ZN7Catlass13KernelAdapterINS_4Gemm6Kernel12SplitkMatmulINS1_5Bl, CoreId 0, Type aiv]
+* thread #1, name = '09_splitk_matmu', stop reason = step over
+ frame #0: 0x000000000000c000 device_debugdata`_ZN7Catlass4Gemm6Kernel9ReduceAddINS_4Arch7AtlasA2EfDhLj8192EEclERKN7AscendC12GlobalTensorIDhEERKNS7_IfEEmj_mix_aiv(this=0x00000000001cf838, dst=0x00000000001cf930, src=0x00000000001cf908, elementCount=131072, splitkFactor=2) at splitk_matmul.hpp:139:28
+ 136 Ub2Gm(dst[loopIdx * tileLen], outputBuffer[bufferIndex], actualTileLen);
+ 137 AscendC::SetFlag(outputEventIds[bufferIndex]);
+ 138
+-> 139 bufferIndex = (bufferIndex + 1) % BUFFER_NUM;
+ 140 }
+ 141
+ 142 AscendC::WaitFlag(inputEventIds[0]);
+(msdebug) n
+Process 814339 stopped
+[Switching to focus on Kernel _ZN7Catlass13KernelAdapterINS_4Gemm6Kernel12SplitkMatmulINS1_5Bl, CoreId 0, Type aiv]
+* thread #1, name = '09_splitk_matmu', stop reason = step over
+ frame #0: 0x000000000000c014 device_debugdata`_ZN7Catlass4Gemm6Kernel9ReduceAddINS_4Arch7AtlasA2EfDhLj8192EEclERKN7AscendC12GlobalTensorIDhEERKNS7_IfEEmj_mix_aiv(this=0x00000000001cf838, dst=0x00000000001cf930, src=0x00000000001cf908, elementCount=131072, splitkFactor=2) at splitk_matmul.hpp:96:68
+ 93 AscendC::SetFlag(accumulatorEventIds[1]);
+ 94
+ 95 uint32_t loops = (elementCount + tileLen - 1) / tileLen;
+-> 96 for (uint32_t loopIdx = aivId; loopIdx < loops; loopIdx += aivNum) {
+ 97 uint32_t actualTileLen = tileLen;
+ 98 if (loopIdx == loops - 1) {
+ 99 actualTileLen = elementCount - loopIdx * tileLen;
+(msdebug)
+```
+
+通过`var`命令,可以查看当前栈帧的全部变量。
+
+```bash
+(msdebug) var
+(Catlass::Gemm::Kernel::ReduceAdd *__stack__) this = 0x00000000001cf838
+(const AscendC::GlobalTensor<__fp16> &__stack__) dst = 0x00000000001cf930: {
+ AscendC::BaseGlobalTensor<__fp16> = {
+ address_ = 0x000012c0c0094000
+ oriAddress_ = 0x000012c0c0094000
+ }
+ bufferSize_ = 1898896
+ shapeInfo_ = {
+ shapeDim = 'h'
+ originalShapeDim = '\xf9'
+ shape = {}
+ originalShape = {}
+ dataFormat = ND
+ }
+ cacheMode_ = CACHE_MODE_NORMAL
+}
+(const AscendC::GlobalTensor &__stack__) src = 0x00000000001cf908: {
+ AscendC::BaseGlobalTensor = {
+ address_ = 0x000012c041400000
+ oriAddress_ = 0x000012c041400000
+ }
+ bufferSize_ = 1898904
+ shapeInfo_ = {
+ shapeDim = 'H'
+ originalShapeDim = '\xf9'
+ shape = {}
+ originalShape = {}
+ dataFormat = ND
+ }
+ cacheMode_ = CACHE_MODE_NORMAL
+}
+(uint64_t) elementCount = 131072
+(uint32_t) splitkFactor = 2
+(const uint32_t) ELE_PER_VECOTR_BLOCK = 64
+(uint32_t) aivNum = 48
+(uint32_t) aivId = 26
+(uint64_t) taskPerAiv = 2752
+(uint32_t) tileLen = 2752
+(uint32_t) loops = 48
+(uint32_t) loopIdx = 26
+(msdebug)
+```
+
+### 退出调试
+
+调试完成后,通过命令`q`退出msdebug,若通过`Ctrl+C`等手段强行退出,则msdebug进程不会结束,仍在后台运行,此时可通过`ps -ef | grep msdebug`查找对应的进程pid,再用`kill -9 进程pid`杀掉对应进程即可。不能同时起多个msdebug进程进行调试。
+
+```bash
+(msdebug) q
+Quitting LLDB will kill one or more processes. Do you really want to proceed: [Y/n] y
+```
+
+### 常用命令表
+
+| 命令 | 命令缩写 | 作用 | 示例 |
+| ------ | ---------- | ------ | ------- |
+| breakpoint filename:lineNo | b | 增加断点 | b add\_custom.cpp:85
b my\_function |
+| run | r | 重新运行 | r |
+| continue | c | 继续运行 | c |
+| print | p | 打印变量| p zLocal |
+| frame variable | var | 打印当前帧所有变量 | var |
+| memory read | x | 读内存
-m 指定内存位置,支持GM/UB/L0A/L0B/L0C
-f 指定[字节转换格式](#附录1)
-s 指定每行打印字节数
-c 指定打印的行数 | x -m GM -f float16[] 1000-c 2 -s 128 |
+| register read | re r | 读取寄存器值
-a 读取所有寄存器值
\$REG\_NAME 读取指定名称的寄存器值 | register read -are r \$PC |
+| thread step-over | next
n | 在同一个调用栈中,移动到下一个可执行的代码行 | n |
+| ascend info devices | / | 查询device信息 | ascend info devices |
+| ascend info cores | / | 查询算子所运行的aicore相关信息 | ascend info cores |
+| ascend info tasks | / | 查询算子所运行的task相关信息 | ascend info tasks |
+| ascend info stream | / | 查询算子所运行的stream相关信息 | ascend info stream |
+| ascend info blocks | / | 查询算子所运行的block相关信息
可选参数: -d/–details显示所有blocks当前中断处代码 | ascend info blocks |
+| ascend aic core | / | 切换调试器所聚焦的cube核 | ascend aic 1 |
+| ascend aiv core | / | 切换调试器所聚焦的vector核 | ascend aiv 5 |
+| target modules addkernel.o | image addkernel.o | PyTorch框架拉起算子时,导入算子调试信息
(注:当程序执行run命令后再执行本命令导入调试信息,
则还需额外执行image load命令以使调试信息生效) | image addAddCustom\_xxx.o |
+| target modules load –f kernel.o –s address | image load -f kernel.o -s address | 在程序运行后,使导入的调试信息生效 | image load -f AddCustom\_xxx.o -s 0 |
+
+# 附录
+
+### msdebug支持的数据格式
+
+```bash
+Valid values are:
+"default"
+'B' or "boolean"
+'b' or "binary"
+'y' or "bytes"
+'Y' or "bytes with ASCII"
+'c' or "character"
+'C' or "printable character"
+'F' or "complex float"
+'s' or "c-string"
+'d' or "decimal"
+'E' or "enumeration"
+'x' or "hex"
+'X' or "uppercase hex"
+'f' or "float"
+"brain float16"
+'o' or "octal"
+'O' or "OSType"
+'U' or "unicode16"
+"unicode32"
+'u' or "unsigned decimal"
+'p' or "pointer"
+"char[]"
+"int8_t[]"
+"uint8_t[]"
+"int16_t[]"
+"uint16_t[]"
+"int32_t[]"
+"uint32_t[]"
+"int64_t[]"
+"uint64_t[]"
+"bfloat16[]"
+"float16[]"
+"float32[]"
+"float64[]"
+"uint128_t[]"
+'I' or "complex integer"
+'a' or "character array"
+'A' or "address"
+"hex float"
+'i' or "instruction"
+'v' or "void"
+'u' or "unicode8"
+```
+
+### 指定调试使用的NPU卡
+
+配置环境变量ASCEND_RT_VISIBLE_DEVICES为需要使用的NPU卡号,例如
+
+```bash
+export ASCEND_RT_VISIBLE_DEVICES=2
+```
diff --git a/docs/tools/performance_tools.md b/docs/tools/performance_tools.md
new file mode 100644
index 0000000000000000000000000000000000000000..278ec662be2393578d8488360ac5d515d36c9768
--- /dev/null
+++ b/docs/tools/performance_tools.md
@@ -0,0 +1,196 @@
+# 在CATLASS样例工程进行性能调优
+
+CANN对算子开发的两个场景——单算子与整网开发,分别提供了对应的性能调优工具:**msProf**和**Profiling**。
+
+## 性能调优工具简介
+
+### msProf简介
+
+[msProf](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/82RC1alpha003/devaids/optool/atlasopdev_16_0082.html)是单算子性能分析工具,对应的指令为`msprof op`或`msopprof`。
+
+msProf工具用于采集和分析运行在昇腾AI处理器上算子的关键性能指标,用户可根据输出的性能数据,快速定位算子的软、硬件性能瓶颈,提升算子性能的分析效率。
+
+当前支持基于不同运行模式(上板或仿真)和不同文件形式(可执行文件或算子二进制`.o`文件)进行性能数据的采集和自动解析。
+
+### Profiling简介
+
+[Profiling](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/82RC1alpha003/devaids/Profiling/atlasprofiling_16_0010.html)是整网性能分析工具,对应的指令为`msprof`。
+
+Profiling工具提供了AI任务运行性能数据、昇腾AI处理器系统数据等性能数据的采集和解析能力。
+
+其中,msprof采集通用命令是性能数据采集的基础,用于提供性能数据采集时的基本信息,包括参数说明、AI任务文件、数据存放路径、自定义环境变量等。
+
+## 用msProf进行单算子性能分析
+
+下面以`00_basic_matmul`为例,进行`msProf`的使用说明。
+
+### 上板性能采集
+
+通过上板性能采集,可以直接测定算子在NPU卡上的运行时间,可判断性能是否初步达到预期标准。
+
+#### msprof op使用示例
+
+1. 参考[快速上手](../../README.md#快速上手),编译算子样例。
+2. 使用`msprof op *可选参数* app [arguments]`格式调用msProf工具。
+
+```bash
+msprof op --application="./00_basic_matmul 256 512 1024 0"
+```
+
+常用参数如下:
+
+| 参数 | 是否必选 | 说明 | 取值 | 配套参数/注意事项 |
+| ---------------- | -------------- | -------------------------------------------- | ----------------------------- | ---------------------------- |
+| `--application` | 必选(二选一) | 指定可执行文件/执行指令 | 有效路径或命令 | 与 `--config` 互斥 |
+| `--config` | 必选(二选一) | 指定二进制文件 `.o` | 有效路径 | 与 `--application` 互斥 |
+| `--kernel-name` | 可选 | 指定采集的算子名称(支持模糊匹配和多个采集) | 例:`"conv*"` 或 `"add\|mul"` | 需配合 `--launch-count` 使用 |
+| `--launch-count` | 可选 | 设置最大采集算子数量 | 1~100 整数(默认 1) | 需配合 `--kernel-name` 使用 |
+| `--warm-up` | 可选 | 预热次数(解决芯片未提频问题) | 整数(默认 5) | 小 shape 场景建议提高到 30 |
+| `--output` | 可选 | 指定数据输出路径 | 有效路径(默认当前目录) | 需确保路径可写 |
+
+更多参数可参考[msProf工具概述](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/82RC1alpha003/devaids/optool/atlasopdev_16_0082.html)。
+
+- ⚠ 注意事项
+ - 工具默认会读取第一个算子的性能,使用example进行调测时可直接获取到结果;若接入其他工程,工程中可能存在其他算子(虽然只跑某一个算子的用例),所以性能分析时要通过--kernel-name指定算子名称的方式,否则读取不到结果。
+ - 上板调测可在非0卡进行调测,需要使用下面的命令进行环境变量的设定:
+
+```bash
+# 指定使用卡0
+export ASCEND_RT_VISIBLE_DEVICES=0
+msprof op ./00_basic_matmul 256 512 1024 0
+```
+
+#### 性能数据说明
+
+性能数据文件夹结构示例:
+
+```bash
+├──dump # 原始的性能数据,用户无需关注
+├──ArithmeticUtilization.csv # cube/vector指令cycle占比,建议优化算子逻辑,减少冗余计算指令
+├──L2Cache.csv # L2 Cache命中率,影响MTE2,建议合理规划数据搬运逻辑,增加命中率
+├──Memory.csv # UB,L1和主储存器读写带宽速率,单位GB/s
+├──MemoryL0.csv # L0A,L0B,和L0C读写带宽速率,单位GB/s
+├──MemoryUB.csv # Vector和Scalar到UB的读写带宽速率,单位GB/s
+├──OpBasicInfo.csv # 算子基础信息
+├──PipeUtilization.csv # pipe类指令耗时和占比,建议优化数据搬运逻辑,提高带宽利用率
+└──ResourceConflictRatio.csv # UB上的 bank group、bank conflict和资源冲突率在所有指令中的占比, 建议减少/避免对于同一个bank读写冲突或bank group的读读冲突
+```
+
+### 性能流水仿真
+
+通过仿真,可以获得**流水图**、**指令与代码行映射**、**代码热点图**、**内存热点图**等可视化数据,以便进一步分析优化算子计算瓶颈。
+
+#### msprof op simulator使用示例
+
+1. 编译脚本增加选项`--simulator`, 以`simulator`模式编译算子。
+
+```bash
+bash scripts/build.sh --simulator 00_basic_matmul
+```
+
+2. 编译完成后,根据提示,执行增加用于仿真的动态链接库的搜索路径
+
+```bash
+# 根据第1步的实际输出执行
+export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/...:$LD_LIBRARY_PATH
+```
+
+3. 切换到可执行文件的编译目录 `output/bin` 下, 使用`msprof op simulator`执行算子样例程序。
+
+```bash
+cd output/bin
+# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID(可选)
+msprof op simulator ./00_basic_matmul 256 512 1024 0
+```
+
+- ⚠ 注意事项
+ - 若需要查看**代码热点图**,需要在CMakeLists.txt中增加`add
+ _compile_options("SHELL:$<$:-Xaicore-start -g -Xaicore-end")`。
+ - 性能结果中有大量明显`Vector`操作(如`Add`、`Div`)映射为`Scalar`操作导致性能结果明显异常(`vector_ratio<10%`,`scalar>90%`),这是编译优化等级造成的,可在CMakeLists.txt中增加`add_compile_options($<$:"-Xaicore-start -O3 -Xaicore-end")`。
+ - 仿真只能在0卡运行,不能指定NPU卡号。
+
+#### 仿真数据说明
+
+```bash
+├──dump # 原始的性能数据,用户无需关注
+└──simulator # 算子基础信息
+ ├──core0.cubecore0
+ ├──...
+ ├──core23.cubecore0
+ ├──trace.json # Edge/Chrome Trace Viewer/Perfetto呈现文件
+ └──visualize_data.bin # MindStudio Insight呈现文件
+
+```
+
+#### 性能数据可视化查看
+
+- 数据可视化依赖[MindStudio Insight](https://www.hiascend.com/document/detail/zh/mindstudio/80RC1/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0002.html)工具,需要提前下载安装。
+
+##### 代码热点图
+
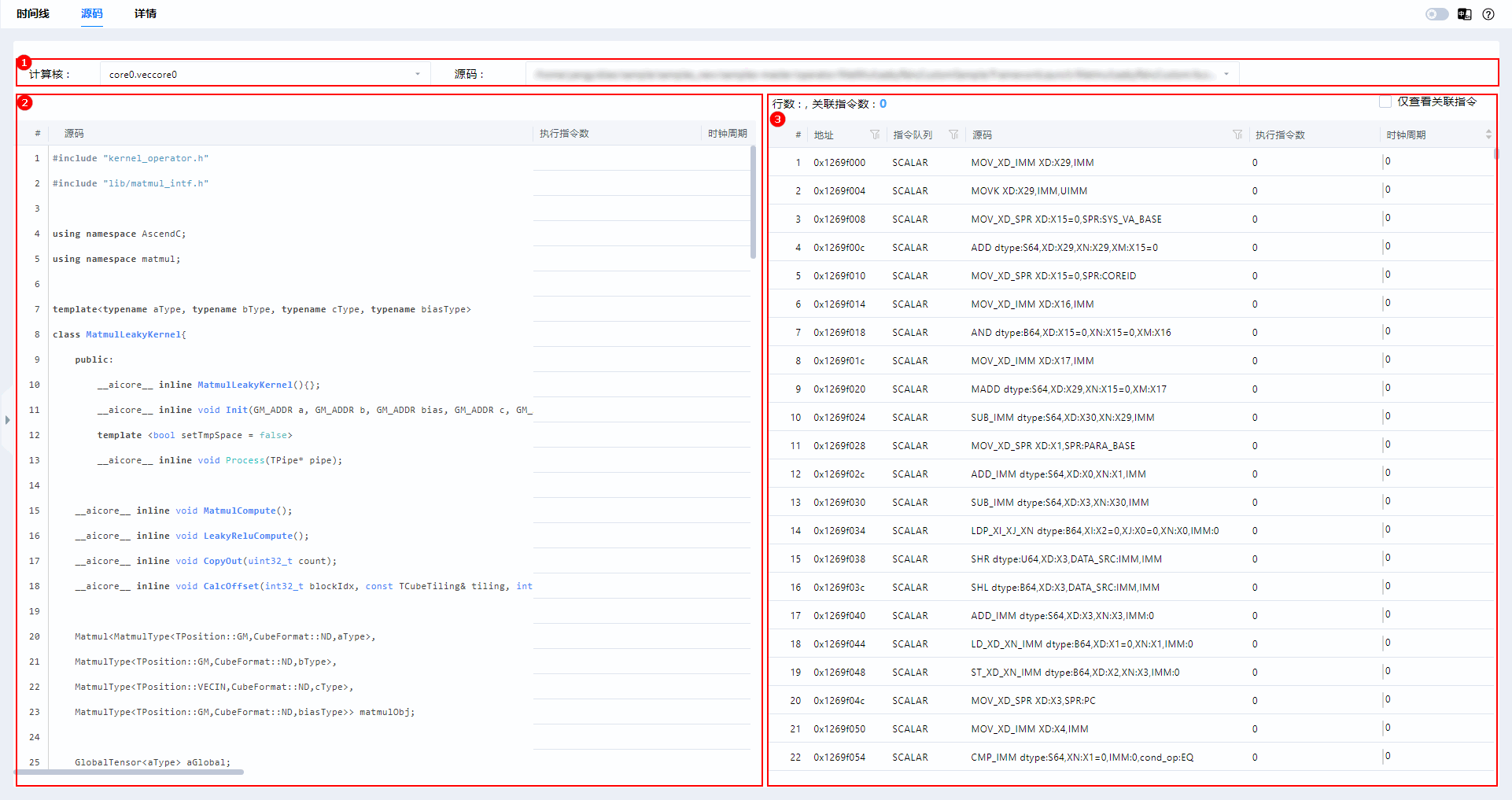
+获取仿真输出文件夹`simulator`下的`visualize_data.bin`,通过MindStudio Insight工具加载bin文件查看代码热点图。
+
+
+
+##### 指令流水图
+
+###### 使用Edge/Chrome Trace Viewer/Perfetto呈现
+
+根据浏览器,选择以下工具:
+
+- [Edge Trace Viewer](edge://tracing)(Edge浏览器)
+- [Chrome Trace Viewer](chrome://tracing)(Chrome浏览器/基于Chrome内核的浏览器)
+- [Perfetto](https://ui.perfetto.dev/)(通用)
+
+导入`trace.json`即可查看仿真指令流水图。
+
+###### 使用MindStudio Insight呈现
+
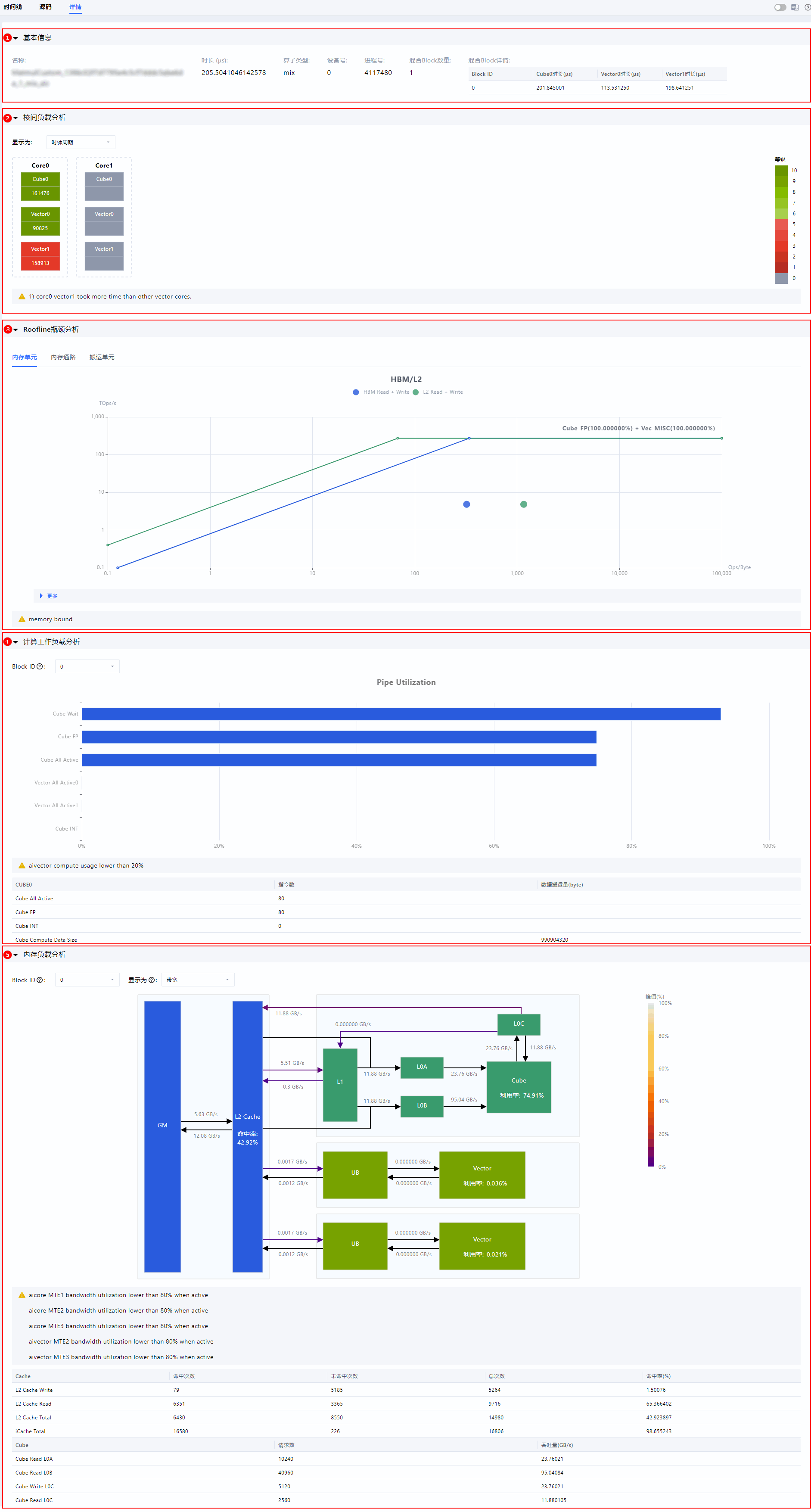
+获取仿真输出文件夹`simulator`下的`visualize_data.bin`。通过MindStudio Insight工具加载bin文件查看仿真流水图。
+
+
+
+### 用MindStudio Insight查看更多可视化数据
+
+msProf工具采集到的数据,可导入可视化工具[MindStudio Insight](https://www.hiascend.com/document/detail/zh/mindstudio/80RC1/GUI_baseddevelopmenttool/msascendinsightug/Insight_userguide_0002.html)中,以便进一步分析算子计算瓶颈。将`visualize_data.bin`导入工具内,即可可视化地分析算子性能。
+
+
+
+
+
+## 用Profiling进行整网性能分析
+
+虽然CATLASS只提供单算子的调用示例,但单算子调用示例也可使用Profiling工具进行性能分析。
+
+下面以`00_basic_matmul`为例,进行`Profiling`的使用说明。
+
+### msprof使用示例
+
+1. 基于[快速上手](../README.md#快速上手),打开工具的编译开关`--enable_profiling`, 使能`profiling api`编译算子样例。
+
+```bash
+bash scripts/build.sh --enable_profiling 00_basic_matmul
+```
+
+2. 切换到可执行文件的编译目录`output/bin`下,用`msprof`执行算子样例程序。
+
+```bash
+cd output/bin
+# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID(可选)
+msprof ./00_basic_matmul 256 512 1024 0
+```
+
+### 性能数据说明
+
+```bash
+├──aicore_time # 算子在AIcore中的计算时间
+├──memory_bound # 内存带宽
+├──mte2_ratio # MTE2搬运单元的时间比例
+├──mte2_time # MTE2搬运单元的时间
+├──mte3_ratio # MTE3搬运单元的时间比例
+├──mte3_time # MTE3搬运单元的时间
+├──scalar_ratio # Scalar计算单元的时间比例
+├──scalar_time # Scalar计算单元的时间
+├──vec_ratio # Vector计算单元的时间比例
+└──vec_time # Vector计算单元的时间
+```
\ No newline at end of file
diff --git a/docs/tools/print.md b/docs/tools/print.md
new file mode 100644
index 0000000000000000000000000000000000000000..031dcaba198d7c6df377eed39562bc24d8f5fa0c
--- /dev/null
+++ b/docs/tools/print.md
@@ -0,0 +1,92 @@
+# 在CATLASS样例工程进行设备侧打印
+
+提供设备侧打印函数`cce::printf`,用法与C标准库的printf一致。
+
+- 支持`cube/vector/mix`算子
+- 支持格式化字符串
+- 支持打印常见整型与浮点数、指针、字符
+
+ - ⚠️ **注意** 这个功能将在社区版未来的CANN 8.3开始支持,商用最新版现已支持。
+
+# 使用示例
+
+下面以对`09_splitk_matmul`为例,进行`设备侧打印`的使用说明。
+
+## 插入打印代码
+
+在想进行调试的代码段增加打印代码。
+
+```diff
+extern "C" __global__ __aicore__ void(...)
+{
+ // ...
+ uint32_t tileLen;
+ if (taskPerAiv > COMPUTE_LENGTH) {
+ tileLen = COMPUTE_LENGTH;
+ } else {
+ tileLen = taskPerAiv;
+ }
++ cce::printf("tileLen:%d\n", tileLen);
+ // ...
+}
+```
+
+## 编译运行
+
+1. 基于[快速上手](../../README.md#快速上手),打开工具的编译开关`--enable_print`, 使能设备侧打印特性编译算子样例。
+
+```bash
+bash scripts/build.sh --enable_print 09_splitk_matmul
+```
+
+2. 切换到可执行文件的编译目录`output/bin`下,直接执行算子样例程序。
+
+```bash
+cd output/bin
+# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID(可选)
+msdebug ./09_basic_matmul 256 512 1024 0
+```
+
+- ⚠ 注意事项
+ - 目前`设备侧打印`仅支持打印`GM`和`SB(Scalar Buffer)`上的数值。
+
+## 示例
+
+输出结果
+
+```bash
+./09_splitk_matmul 256 512 1024 0
+-----------------------------------------------------------------------------
+---------------------------------HiIPU Print---------------------------------
+-----------------------------------------------------------------------------
+==> Logical Block 0
+=> Physical Block
+
+=> Physical Block
+tileLen:2752
+
+=> Physical Block
+tileLen:2752
+
+==> Logical Block 1
+=> Physical Block
+
+=> Physical Block
+tileLen:2752
+
+=> Physical Block
+tileLen:2752
+
+... # 此处省略
+
+==> Logical Block 23
+=> Physical Block
+
+=> Physical Block
+tileLen:2752
+
+=> Physical Block
+tileLen:2752
+
+Compare success.
+```
diff --git a/docs/tutorials.md b/docs/tutorials.md
index b15a70eb89b3385f0d6f060295518d502f3caa6d..99b0bba97564dec61cd4152ade182534fd7828cb 100644
--- a/docs/tutorials.md
+++ b/docs/tutorials.md
@@ -19,15 +19,13 @@ Catlass算子模板库采用分层抽象的设计理念,通过分析硬件架
### 代码部署
配置环境变量:
-```
+```bash
source /usr/local/Ascend/ascend-toolkit/set_env.sh
-
```
git clone下载Catlass算子模板库源码
-```
+```bash
git clone https://gitee.com/ascend/catlass.git
-
```
需要依赖组件:
CANN 8.2.RC1.alpha002及之后版本
diff --git a/examples/00_basic_matmul/README.md b/examples/00_basic_matmul/README.md
index caa754080884a75375f002132738d6c23fbe96ec..b26593a8005f6cf9f0c8c25d9f276c47adacd1f8 100644
--- a/examples/00_basic_matmul/README.md
+++ b/examples/00_basic_matmul/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 00_basic_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./00_basic_matmul 256 512 1024 0
diff --git a/examples/01_batched_matmul/README.md b/examples/01_batched_matmul/README.md
index 88bebf9942582af52ad444d63290325577441624..1358056d7bc36e23cb7fcb36fd62ff8f0ce8314f 100644
--- a/examples/01_batched_matmul/README.md
+++ b/examples/01_batched_matmul/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 01_batched_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 batch轴|m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
# 注意!这里相比basicMatmul多一个batch轴的输入参数
diff --git a/examples/02_grouped_matmul_slice_m/README.md b/examples/02_grouped_matmul_slice_m/README.md
index 7287a943044ea3c9ab31e8a65dd98912d104a6d8..b904f7f606c3b8edb02931748b53ccef1fe0f817 100644
--- a/examples/02_grouped_matmul_slice_m/README.md
+++ b/examples/02_grouped_matmul_slice_m/README.md
@@ -19,7 +19,7 @@ example使用
```
# 编译指定用例
bash scripts/build.sh 02_grouped_matmul_slice_m
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名|group数量|矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./02_grouped_matmul_slice_m 128 512 1024 2048 0
diff --git a/examples/03_matmul_add/README.md b/examples/03_matmul_add/README.md
index abc7b03cf864d6b5372f8e26c89c2c9b6c4d8466..34837080b33ade6d7f836f930a71cb24213ade99 100644
--- a/examples/03_matmul_add/README.md
+++ b/examples/03_matmul_add/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 03_matmul_add
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./03_matmul_add 256 512 1024 0
diff --git a/examples/04_padding_matmul/README.md b/examples/04_padding_matmul/README.md
index 85bf38aa9df4f4972d7789b33faeec6512cb0d44..d81bc27f8f90d88d7f7d34ede4b707bd115d4648 100644
--- a/examples/04_padding_matmul/README.md
+++ b/examples/04_padding_matmul/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 04_padding_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./04_padding_matmul 256 512 1024 0
diff --git a/examples/05_grouped_matmul_slice_k/README.md b/examples/05_grouped_matmul_slice_k/README.md
index 5d5d2588442dd4c813a27c509e8dd2337662a7d8..ca70cb7cfab1f984cb88899eb77be373c161c4c9 100644
--- a/examples/05_grouped_matmul_slice_k/README.md
+++ b/examples/05_grouped_matmul_slice_k/README.md
@@ -14,7 +14,7 @@
```
# 编译指定用例
bash scripts/build.sh 05_grouped_matmul_slice_k
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 group数量|m轴|n轴|k轴|Device ID
./05_grouped_matmul_slice_k 128 512 1024 2048 0
```
diff --git a/examples/06_optimized_matmul/README.md b/examples/06_optimized_matmul/README.md
index 5317d3f8c43a7deeb4a49d142e8b874abddb7d0b..df57bca336c413a87f17dd34ccdd071816ab5b18 100644
--- a/examples/06_optimized_matmul/README.md
+++ b/examples/06_optimized_matmul/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 06_optimized_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./06_optimized_matmul 256 512 1024 0
diff --git a/examples/07_grouped_matmul_slice_m_per_token_dequant_moe/README.md b/examples/07_grouped_matmul_slice_m_per_token_dequant_moe/README.md
index 392326cebdf14fea6330a451793aea6ee7a32f00..f7ff5e0c78b4abe346fbef1229adfa60d60c406f 100644
--- a/examples/07_grouped_matmul_slice_m_per_token_dequant_moe/README.md
+++ b/examples/07_grouped_matmul_slice_m_per_token_dequant_moe/README.md
@@ -17,7 +17,7 @@ A/B矩阵为int8类型,scale为fp32,输出结果为fp16
```
# 编译指定用例
bash scripts/build.sh 07_grouped_matmul_slice_m_per_token_dequant_moe
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名|group数量|矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./07_grouped_matmul_slice_m_per_token_dequant_moe 128 512 1024 2048 0
diff --git a/examples/08_grouped_matmul/README.md b/examples/08_grouped_matmul/README.md
index ca4f0f20189b6a881231732df11407e0f8c08057..65f27655f95308a040f85ae1a4cc16473d1b5f8e 100644
--- a/examples/08_grouped_matmul/README.md
+++ b/examples/08_grouped_matmul/README.md
@@ -14,7 +14,7 @@
```
# 编译指定用例
bash scripts/build.sh 08_grouped_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 group数量|m轴|n轴|k轴|Device ID
./08_grouped_matmul 128 512 1024 2048 0
```
diff --git a/examples/09_splitk_matmul/README.md b/examples/09_splitk_matmul/README.md
index dac8319568b2c1105561c502e0d991f2e3485765..b18e31ad9ff5c7e6c9bc4fd3eb03dec70fdcb25b 100644
--- a/examples/09_splitk_matmul/README.md
+++ b/examples/09_splitk_matmul/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 09_splitk_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./09_splitk_matmul 256 512 1024 0
diff --git a/examples/10_grouped_matmul_slice_m_per_token_dequant/README.md b/examples/10_grouped_matmul_slice_m_per_token_dequant/README.md
index 91e9ce107846e7c3dd85fd80ce3ff0f890a0ef01..ef5ba18682a8d7fd1f62a242eee119eb9f67417b 100644
--- a/examples/10_grouped_matmul_slice_m_per_token_dequant/README.md
+++ b/examples/10_grouped_matmul_slice_m_per_token_dequant/README.md
@@ -15,7 +15,7 @@ A/B矩阵为int8类型,scale为bf16,输出结果为bf16
```
# 编译指定用例
bash scripts/build.sh 10_grouped_matmul_slice_m_per_token_dequant
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名|group数量|矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./10_grouped_matmul_slice_m_per_token_dequant 128 512 1024 2048 0
diff --git a/examples/11_grouped_matmul_slice_k_per_token_dequant/README.md b/examples/11_grouped_matmul_slice_k_per_token_dequant/README.md
index 6b109a848df504dc23ceaf0d464c7ce616d8f1c1..d0b5c011c69e127967044eecfa5898484ac8651f 100644
--- a/examples/11_grouped_matmul_slice_k_per_token_dequant/README.md
+++ b/examples/11_grouped_matmul_slice_k_per_token_dequant/README.md
@@ -15,7 +15,7 @@ A/B矩阵为int8类型,scale为bf16,输出结果为bf16
```
# 编译指定用例
bash scripts/build.sh 11_grouped_matmul_slice_k_per_token_dequant
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名|group数量|矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./11_grouped_matmul_slice_k_per_token_dequant 128 512 1024 2048 0
diff --git a/examples/12_quant_matmul/README.md b/examples/12_quant_matmul/README.md
index f3ec5413ba1b1cd4cca35e791d88ad5f89696b20..c68361698c84a3e192291f4a576a91c977be9302 100644
--- a/examples/12_quant_matmul/README.md
+++ b/examples/12_quant_matmul/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 12_quant_matmul
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./12_quant_matmul 256 512 1024 0
diff --git a/examples/13_basic_matmul_tla/README.md b/examples/13_basic_matmul_tla/README.md
index 59577771d98ff2d0a4ac6267df2e0d4323455332..cdad68c311101a581daee1adf17c713261faaadc 100644
--- a/examples/13_basic_matmul_tla/README.md
+++ b/examples/13_basic_matmul_tla/README.md
@@ -14,7 +14,7 @@
```
# 编译指定用例
bash scripts/build.sh 13_basic_matmul_tla
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./13_basic_matmul_tla 256 512 1024 0
diff --git a/examples/14_optimized_matmul_tla/README.md b/examples/14_optimized_matmul_tla/README.md
index 3b271948bb8e8d2b6948ee621f0eecdac4579716..890bfd096fd1c6276483ab7b355a91557a7a6100 100644
--- a/examples/14_optimized_matmul_tla/README.md
+++ b/examples/14_optimized_matmul_tla/README.md
@@ -14,7 +14,7 @@
```
# 编译指定用例
bash scripts/build.sh 14_optimized_matmul_tla
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./14_optimized_matmul_tla 256 512 1024 0
diff --git a/examples/15_gemm/README.md b/examples/15_gemm/README.md
index eedfeb62d3392ae5d265a95900ecee759b3c5e91..6414b0ab0ab7f9cec6cc06ef8596a301e19fdd99 100644
--- a/examples/15_gemm/README.md
+++ b/examples/15_gemm/README.md
@@ -10,7 +10,7 @@
- 获取代码之后编译相应的算子可执行文件,可参考[quickstart](../../docs/quickstart.md#算子编译)
- 执行算子
```
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./15_gemm 256 512 1024 0
diff --git a/examples/16_group_gemm/README.md b/examples/16_group_gemm/README.md
index 703f2eacc28c6b8c26d050224bb694f5003d5c9e..e275e0dc43ea52bcb4a42d85ab9173cf0abe7b83 100644
--- a/examples/16_group_gemm/README.md
+++ b/examples/16_group_gemm/README.md
@@ -10,7 +10,7 @@
- 获取代码之后编译相应的算子可执行文件,可参考[quickstart](../../docs/quickstart.md#算子编译)
- 执行算子
```
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵个数||矩阵m轴组|n轴组|k轴组|Device ID
# Device ID可选,默认为0
./16_group_gemm 3 "128,256,512" "256,512,128" "512,256,128" 0
diff --git a/examples/17_gemv_aiv/README.md b/examples/17_gemv_aiv/README.md
index d2135a3f524b76a279513c7be5fff5c991376605..72d7b8911a05a03e8a76fc9f0f57fb7b700a0164 100644
--- a/examples/17_gemv_aiv/README.md
+++ b/examples/17_gemv_aiv/README.md
@@ -10,7 +10,7 @@
- 获取代码之后编译相应的算子可执行文件,可参考[quickstart](../../docs/quickstart.md#算子编译)
- 执行算子
```
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|Device ID
# Device ID可选,默认为0
./17_gemv_aiv 256 512 0
diff --git a/examples/18_gemv_aic/README.md b/examples/18_gemv_aic/README.md
index ee07baa2711fcfeafcaa27320c8d1a597035c4c4..d8668134089b4a5cf5ab729420ae07f50cfef542 100644
--- a/examples/18_gemv_aic/README.md
+++ b/examples/18_gemv_aic/README.md
@@ -10,7 +10,7 @@
- 获取代码之后编译相应的算子可执行文件,可参考[quickstart](../../docs/quickstart.md#算子编译)
- 执行算子
```
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|Device ID
# Device ID可选,默认为0
./18_gemv_aic 256 512 0
diff --git a/examples/19_mla/README.md b/examples/19_mla/README.md
index 53946a4f09f167070fc8d5b3a474e3a353adae63..5eeff729e7f2910547e3a9894d232a40721cc1a7 100644
--- a/examples/19_mla/README.md
+++ b/examples/19_mla/README.md
@@ -36,7 +36,7 @@ python gen_data.py 1 1 128 16 16 128 half
```
第二步,执行算子,这里要注意的是执行算子的输入shape和上面第一步生成数据的shape一致。
```
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
./19_mla 1 1 128 16 16 128
# 此处的参数和生成数据的参数保持一致
# 完整参数为 batchSize, qSeqlen, kvSeqlen, qheadNum, numBlock, blockSize [--dtype DTYPE --datapath DATA_PATH --device DEVICE_ID],dtype默认为half, datapath默认为../../examples/19_mla/data, device默认为0。
diff --git a/examples/20_matmul_bias/README.md b/examples/20_matmul_bias/README.md
index aa565336607f39d0b21d99a3d6cc5f76e308e863..fa64779f2146e871a304f35bfea7b2ac829a61e3 100644
--- a/examples/20_matmul_bias/README.md
+++ b/examples/20_matmul_bias/README.md
@@ -12,7 +12,7 @@
```
# 编译指定用例
bash scripts/build.sh 20_matmul_bias
-# cd [代码仓路径]/build/bin
+# cd [代码仓路径]/output/bin
# 可执行文件名 |矩阵m轴|n轴|k轴|Device ID
# Device ID可选,默认为0
./20_matmul_bias 256 512 1024 0
diff --git a/scripts/build.sh b/scripts/build.sh
index f9d2a4f966e9c7b61307b8d215f3c160be389116..e1dac98bde10ba7dbd8a384c75988fa990906700 100755
--- a/scripts/build.sh
+++ b/scripts/build.sh
@@ -50,7 +50,7 @@ function show_help() {
echo " --debug Build in debug mode"
echo " --msdebug Enable msdebug support"
echo " --simulator Compile example in simulator mode"
- echo " --enable_msprof Enable msprofiling"
+ echo " --enable_profiling Enable profiling"
echo " -D