# Dynamic_obstacle_avoidance_unity
**Repository Path**: break0/Dynamic_obstacle_avoidance_unity
## Basic Information
- **Project Name**: Dynamic_obstacle_avoidance_unity
- **Description**: Unity drone learns how to avoid dynamic obstacles through Deep Reinforcement Learning
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2021-11-30
- **Last Updated**: 2021-11-30
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# Dynamic_obstacle_avoidance_unity
There are 2 goals for this project.
1. Drone avoids moving yellow ball by learning its velocity through DRL.
* Deep reinforcement learning was done using ppo with 7 coordinates(yellow ball's position, velocity and drone's position) input.
* Deep reinforcement learning was done using dqn with drone's 1st view image pixel only as input.
2. Leverage simulation to the real world by using both domain randomization and domain adaptation.
Currently, we have gone through the first part and results are as below.
## Result
### [Experiment 1-1-1. Coordinates as state input, both training and testing at no wind environment 0.99 gamma value ]
1. Performance : 98% Avoidance
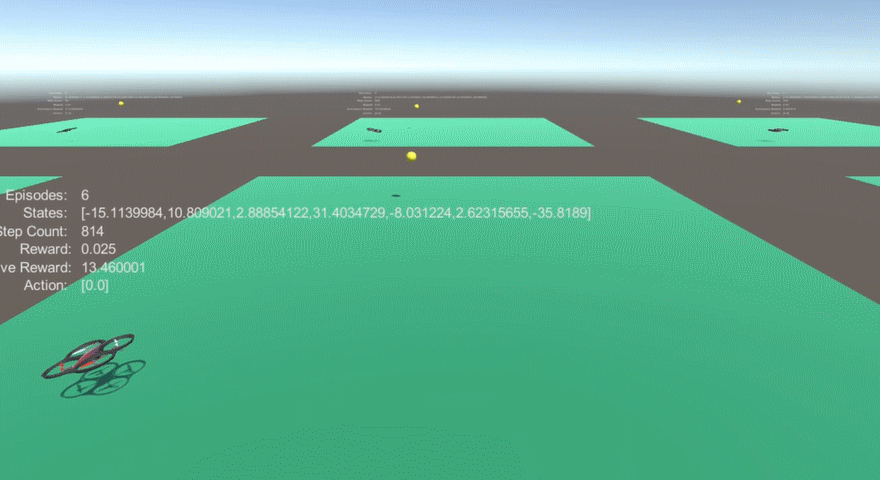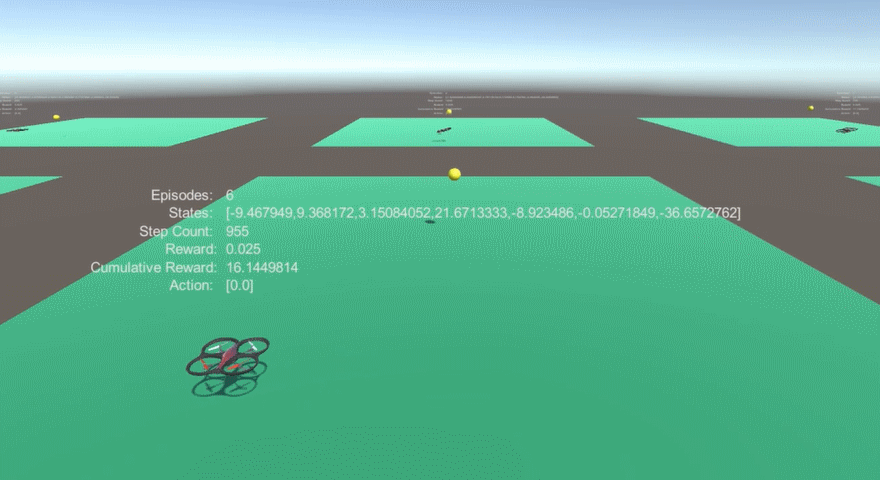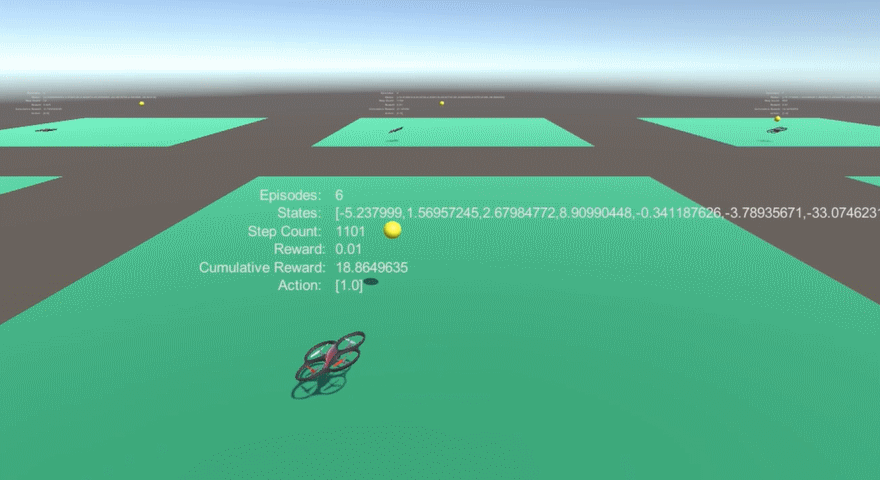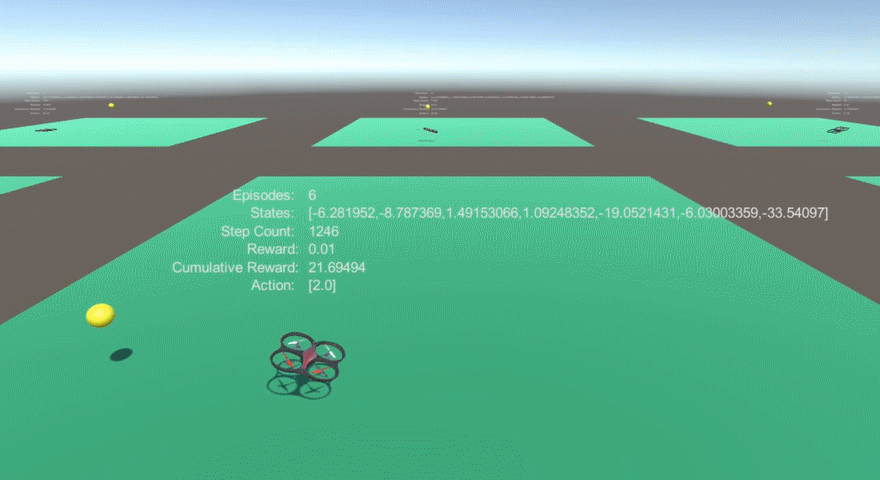 ### [Expriment 1-1-2. Coordinates as state input, training at no wind environment and testing at wind force affects only to yellow balls]
1. Performance : 99% Avoidance(x)--> 97% Avoidance(o)
* We concluded that first 99% result was just by luck. After, doing more trials performance converged to 97%.
* We concluded the reason why performance was tied with experiment 1-1-1. was because gamma value was 0.99. Ball reaches to drone after 60 frames. Since, gamma value is 0.99 drone's q-function is more affected by balls after 30 frames. Thus, drone can still avoid windy ball, even though it changes velocity after 30 frames.
### [Expriment 1-1-2. Coordinates as state input, training at no wind environment and testing at wind force affects only to yellow balls]
1. Performance : 99% Avoidance(x)--> 97% Avoidance(o)
* We concluded that first 99% result was just by luck. After, doing more trials performance converged to 97%.
* We concluded the reason why performance was tied with experiment 1-1-1. was because gamma value was 0.99. Ball reaches to drone after 60 frames. Since, gamma value is 0.99 drone's q-function is more affected by balls after 30 frames. Thus, drone can still avoid windy ball, even though it changes velocity after 30 frames.
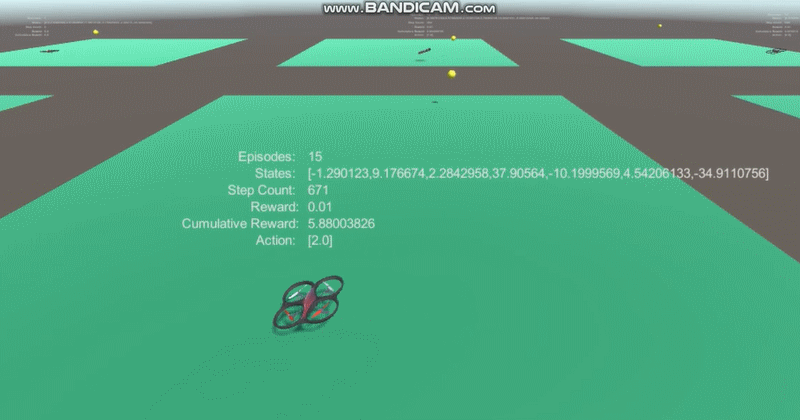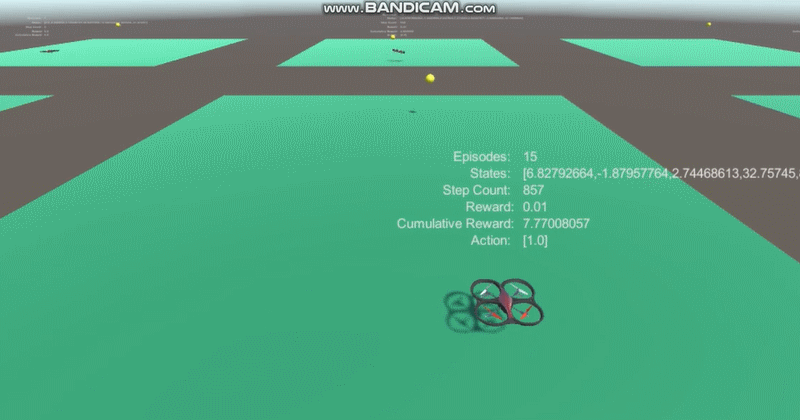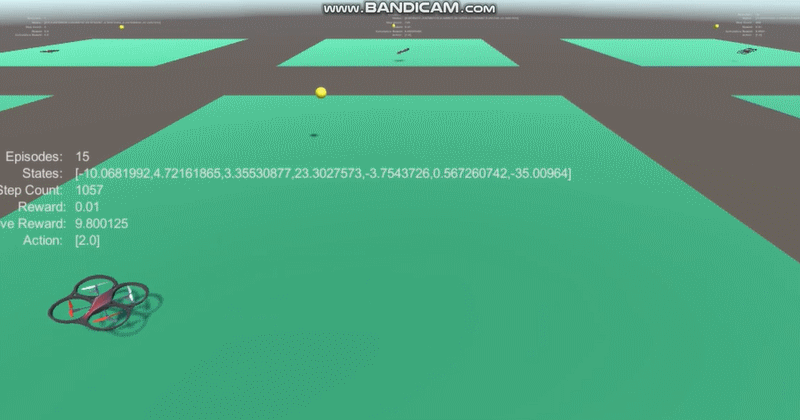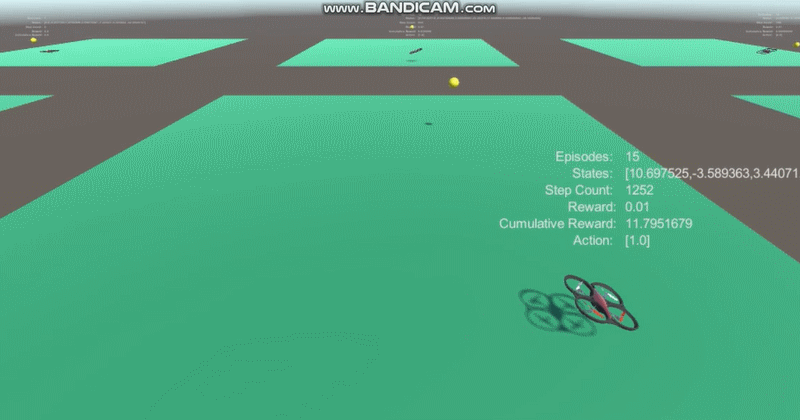 2. The average reward increases!
2. The average reward increases!
 ### [Experiment 1-2. Observation as state input, training at no wind environment, trained with 0.999 gamma value]
1. Performance : Avoided around 7/10 times. (We need to use cloud. Very slow training)
### [Experiment 1-2. Observation as state input, training at no wind environment, trained with 0.999 gamma value]
1. Performance : Avoided around 7/10 times. (We need to use cloud. Very slow training)
 2. The average reward increases!
2. The average reward increases!
