# DouZero
**Repository Path**: daochenzha/DouZero
## Basic Information
- **Project Name**: DouZero
- **Description**: [ICML2021] DouZero斗.地主AI:从零开始通过自我博弈强化学习来学打斗.地主
- **Primary Language**: Python
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: https://douzero.org/
- **GVP Project**: No
## Statistics
- **Stars**: 346
- **Forks**: 144
- **Created**: 2021-06-18
- **Last Updated**: 2026-06-03
## Categories & Tags
**Categories**: ai, games
**Tags**: None
## README
# [ICML 2021] DouZero: 从零开始通过自我博弈强化学习来学打斗地主
 [](https://github.com/kwai/DouZero/actions/workflows/python-package.yml)
[](https://badge.fury.io/py/douzero)
[](https://pepy.tech/project/douzero)
[](https://pepy.tech/project/douzero)
[](https://opensource.org/licenses/Apache-2.0)
[](https://colab.research.google.com/github/daochenzha/douzero-colab/blob/main/douzero-colab.ipynb)
[English README](README.md)
DouZero是一个为斗地主设计的强化学习框架。斗地主十分具有挑战性。它包含合作、竞争、非完全信息、庞大的状态空间。斗地主也有非常大的动作空间,并且每一步合法的牌型会非常不一样。DouZero由快手AI平台部开发。
* 在线演示: [https://www.douzero.org/](https://www.douzero.org/)
* :loudspeaker: 抢先体验叫牌版本(调试中): [https://www.douzero.org/bid](https://www.douzero.org/bid)
* 离线运行演示: [https://github.com/datamllab/rlcard-showdown](https://github.com/datamllab/rlcard-showdown)
* 论文: [https://arxiv.org/abs/2106.06135](https://arxiv.org/abs/2106.06135)
* 视频: [YouTube](https://youtu.be/inHIi8sej7Y)
* 论文: [https://arxiv.org/abs/2106.06135](https://arxiv.org/abs/2106.06135)
* 相关仓库: [RLCard Project](https://github.com/datamllab/rlcard)
* 相关资源: [Awesome-Game-AI](https://github.com/datamllab/awesome-game-ai)
* 由社区贡献者开发的非官方改进版: [[DouZero ResNet]](https://github.com/Vincentzyx/Douzero_Resnet) [[DouZero FullAuto]](https://github.com/Vincentzyx/DouZero_For_HLDDZ_FullAuto)
* 知乎:[https://zhuanlan.zhihu.com/p/526723604](https://zhuanlan.zhihu.com/p/526723604)
* 杂项资源:您听说过以数据为中心的人工智能吗?请查看我们的 [data-centric AI survey](https://arxiv.org/abs/2303.10158) 和 [awesome data-centric AI resources](https://github.com/daochenzha/data-centric-AI)!
**社区:**
* **Slack**: 加入 [DouZero](https://join.slack.com/t/douzero/shared_invite/zt-rg3rygcw-ouxxDk5o4O0bPZ23vpdwxA) 频道.
* **QQ群**: 加入我们的QQ群讨论。密码: douzeroqqgroup
* 一群:819204202
* 二群:954183174
* 三群:834954839
* 四群:211434658
* 五群:189203636
**最新动态:**
* 感谢[@Vincentzyx](https://github.com/Vincentzyx)实现了CPU训练。现在Windows用户也能用CPU训练了。
[](https://github.com/kwai/DouZero/actions/workflows/python-package.yml)
[](https://badge.fury.io/py/douzero)
[](https://pepy.tech/project/douzero)
[](https://pepy.tech/project/douzero)
[](https://opensource.org/licenses/Apache-2.0)
[](https://colab.research.google.com/github/daochenzha/douzero-colab/blob/main/douzero-colab.ipynb)
[English README](README.md)
DouZero是一个为斗地主设计的强化学习框架。斗地主十分具有挑战性。它包含合作、竞争、非完全信息、庞大的状态空间。斗地主也有非常大的动作空间,并且每一步合法的牌型会非常不一样。DouZero由快手AI平台部开发。
* 在线演示: [https://www.douzero.org/](https://www.douzero.org/)
* :loudspeaker: 抢先体验叫牌版本(调试中): [https://www.douzero.org/bid](https://www.douzero.org/bid)
* 离线运行演示: [https://github.com/datamllab/rlcard-showdown](https://github.com/datamllab/rlcard-showdown)
* 论文: [https://arxiv.org/abs/2106.06135](https://arxiv.org/abs/2106.06135)
* 视频: [YouTube](https://youtu.be/inHIi8sej7Y)
* 论文: [https://arxiv.org/abs/2106.06135](https://arxiv.org/abs/2106.06135)
* 相关仓库: [RLCard Project](https://github.com/datamllab/rlcard)
* 相关资源: [Awesome-Game-AI](https://github.com/datamllab/awesome-game-ai)
* 由社区贡献者开发的非官方改进版: [[DouZero ResNet]](https://github.com/Vincentzyx/Douzero_Resnet) [[DouZero FullAuto]](https://github.com/Vincentzyx/DouZero_For_HLDDZ_FullAuto)
* 知乎:[https://zhuanlan.zhihu.com/p/526723604](https://zhuanlan.zhihu.com/p/526723604)
* 杂项资源:您听说过以数据为中心的人工智能吗?请查看我们的 [data-centric AI survey](https://arxiv.org/abs/2303.10158) 和 [awesome data-centric AI resources](https://github.com/daochenzha/data-centric-AI)!
**社区:**
* **Slack**: 加入 [DouZero](https://join.slack.com/t/douzero/shared_invite/zt-rg3rygcw-ouxxDk5o4O0bPZ23vpdwxA) 频道.
* **QQ群**: 加入我们的QQ群讨论。密码: douzeroqqgroup
* 一群:819204202
* 二群:954183174
* 三群:834954839
* 四群:211434658
* 五群:189203636
**最新动态:**
* 感谢[@Vincentzyx](https://github.com/Vincentzyx)实现了CPU训练。现在Windows用户也能用CPU训练了。
 ## 引用
如果您用到我们的项目,请添加以下引用:
Zha, Daochen et al. “DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning.” ICML (2021).
```bibtex
@InProceedings{pmlr-v139-zha21a,
title = {DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning},
author = {Zha, Daochen and Xie, Jingru and Ma, Wenye and Zhang, Sheng and Lian, Xiangru and Hu, Xia and Liu, Ji},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {12333--12344},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/zha21a/zha21a.pdf},
url = {http://proceedings.mlr.press/v139/zha21a.html},
abstract = {Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the hope that this insight could motivate future work.}
}
```
## 为什么斗地主具有挑战性
除了非完全信息带来的挑战外,斗地主本身也包含巨大的状态和动作空间。具体来说,斗地主的动作空间大小高达10^4(详见[该表格](https://github.com/datamllab/rlcard#available-environments))。不幸的是,大部分强化学习算法都只能处理很小的动作空间。并且,斗地主的玩家需要在部分可观测的环境中,与其他玩家对抗或合作,例如:两个农民玩家需要作为一个团队对抗地主玩家。对对抗和合作同时进行建模一直以来是学术界的一个开放性问题。
在本研究工作中,我们提出了将深度蒙特卡洛(Deep Monte Carlo, DMC)与动作编码和并行演员(Parallel Actors)相结合的方法,为斗地主提供了一个简单而有效的解决方案,详见[我们的论文](https://arxiv.org/abs/2106.06135)。
## 安装
训练部分的代码是基于GPU设计的,因此如果想要训练模型,您需要先安装CUDA。安装步骤可以参考[官网教程](https://docs.nvidia.com/cuda/index.html#installation-guides)。对于评估部分,CUDA是可选项,您可以使用CPU进行评估。
首先,克隆本仓库(如果您访问Github较慢,国内用户可以使用[Gitee镜像](https://gitee.com/daochenzha/DouZero)):
```
git clone https://github.com/kwai/DouZero.git
```
确保您已经安装好Python 3.6及以上版本,然后安装依赖:
```
cd douzero
pip3 install -r requirements.txt
```
我们推荐通过以下命令安装稳定版本的Douzero:
```
pip3 install douzero
```
如果您访问较慢,国内用户可以通过清华镜像源安装:
```
pip3 install douzero -i https://pypi.tuna.tsinghua.edu.cn/simple
```
或是安装最新版本(可能不稳定):
```
pip3 install -e .
```
注意,Windows用户只能用CPU来模拟。关于为什么GPU会出问题,详见[Windows下的问题](README.zh-CN.md#Windows下的问题)。但Windows用户仍可以[在本地运行演示](https://github.com/datamllab/rlcard-showdown)。
## 训练
假定您至少拥有一块可用的GPU,运行
```
python3 train.py
```
这会使用一块GPU训练DouZero。如果需要用多个GPU训练Douzero,使用以下参数:
* `--gpu_devices`: 用作训练的GPU设备名
* `--num_actor_devices`: 被用来进行模拟(如自我对弈)的GPU数量
* `--num_actors`: 每个设备的演员进程数
* `--training_device`: 用来进行模型训练的设备
例如,如果我们拥有4块GPU,我们想用前3个GPU进行模拟,每个GPU拥有15个演员,而使用第四个GPU进行训练,我们可以运行以下命令:
```
python3 train.py --gpu_devices 0,1,2,3 --num_actor_devices 3 --num_actors 15 --training_device 3
```
如果用CPU进行训练和模拟(Windows用户只能用CPU进行模拟),用以下参数:
* `--training_device cpu`: 用CPU来训练
* `--actor_device_cpu`: 用CPU来模拟
例如,用以下命令完全在CPU上运行:
```
python3 train.py --actor_device_cpu --training_device cpu
```
以下命令仅仅用CPU来跑模拟:
```
python3 train.py --actor_device_cpu
```
其他定制化的训练配置可以参考以下可选项:
```
--xpid XPID 实验id(默认值:douzero)
--save_interval SAVE_INTERVAL
保存模型的时间间隔(以分钟为单位)
--objective {adp,wp} 使用ADP或者WP作为奖励(默认值:ADP)
--actor_device_cpu 用CPU进行模拟
--gpu_devices GPU_DEVICES
用作训练的GPU设备名
--num_actor_devices NUM_ACTOR_DEVICES
被用来进行模拟(如自我对弈)的GPU数量
--num_actors NUM_ACTORS
每个设备的演员进程数
--training_device TRAINING_DEVICE
用来进行模型训练的设备。`cpu`表示用CPU训练
--load_model 读取已有的模型
--disable_checkpoint 禁用保存检查点
--savedir SAVEDIR 实验数据存储跟路径
--total_frames TOTAL_FRAMES
Total environment frames to train for
--exp_epsilon EXP_EPSILON
探索概率
--batch_size BATCH_SIZE
训练批尺寸
--unroll_length UNROLL_LENGTH
展开长度(时间维度)
--num_buffers NUM_BUFFERS
共享内存缓冲区的数量
--num_threads NUM_THREADS
学习者线程数
--max_grad_norm MAX_GRAD_NORM
最大梯度范数
--learning_rate LEARNING_RATE
学习率
--alpha ALPHA RMSProp平滑常数
--momentum MOMENTUM RMSProp momentum
--epsilon EPSILON RMSProp epsilon
```
## 评估
评估可以使用GPU或CPU进行(GPU效率会高得多)。预训练模型可以通过[Google Drive](https://drive.google.com/drive/folders/1NmM2cXnI5CIWHaLJeoDZMiwt6lOTV_UB?usp=sharing)或[百度网盘](https://pan.baidu.com/s/18g-JUKad6D8rmBONXUDuOQ), 提取码: 4624 下载。将预训练权重放到`baselines/`目录下。模型性能通过自我对弈进行评估。我们提供了一些其他预训练模型和一些启发式方法作为基准:
* [random](douzero/evaluation/random_agent.py): 智能体随机出牌(均匀选择)
* [rlcard](douzero/evaluation/rlcard_agent.py): [RLCard](https://github.com/datamllab/rlcard)项目中的规则模型
* SL (`baselines/sl/`): 基于人类数据进行深度学习的预训练模型
* DouZero-ADP (`baselines/douzero_ADP/`): 以平均分数差异(Average Difference Points, ADP)为目标训练的Douzero智能体
* DouZero-WP (`baselines/douzero_WP/`): 以胜率(Winning Percentage, WP)为目标训练的Douzero智能体
### 第1步:生成评估数据
```
python3 generate_eval_data.py
```
以下为一些重要的超参数。
* `--output`: pickle数据存储路径
* `--num_games`: 生成数据的游戏局数,默认值 10000
## 第2步:自我对弈
```
python3 evaluate.py
```
以下为一些重要的超参数。
* `--landlord`: 扮演地主的智能体,可选值:random, rlcard或预训练模型的路径
* `--landlord_up`: 扮演地主上家的智能体,可选值:random, rlcard或预训练模型的路径
* `--landlord_down`: 扮演地主下家的智能体,可选值:random, rlcard或预训练模型的路径
* `--eval_data`: 包含评估数据的pickle文件
* `--num_workers`: 用多少个进程进行模拟
* `--gpu_device`: 用哪个GPU设备进行模拟。默认用CPU
例如,可以通过以下命令评估DouZero-ADP智能体作为地主对阵随机智能体
```
python3 evaluate.py --landlord baselines/douzero_ADP/landlord.ckpt --landlord_up random --landlord_down random
```
以下命令可以评估DouZero-ADP智能体作为农民对阵RLCard智能体
```
python3 evaluate.py --landlord rlcard --landlord_up baselines/douzero_ADP/landlord_up.ckpt --landlord_down baselines/douzero_ADP/landlord_down.ckpt
```
默认情况下,我们的模型会每半小时保存在`douzero_checkpoints/douzero`路径下。我们提供了一个脚本帮助您定位最近一次保存检查点。运行
```
sh get_most_recent.sh douzero_checkpoints/douzero/
```
之后您可以在`most_recent_model`路径下找到最近一次保存的模型。
## Windows下的问题
如果您使用的是Windows系统并用GPU进行模拟,您将可能遇到`operation not supported`错误。这是由于Windows系统不支持CUDA tensor上的多进程。但是,由于我们的代码是对GPU进行优化,有对CUDA tensor的大量操作。如果您有解决方案,请联系我们!
## 核心团队
* 算法:[Daochen Zha](https://github.com/daochenzha), [Jingru Xie](https://github.com/karoka), Wenye Ma, Sheng Zhang, [Xiangru Lian](https://xrlian.com/), Xia Hu, [Ji Liu](http://jiliu-ml.org/)
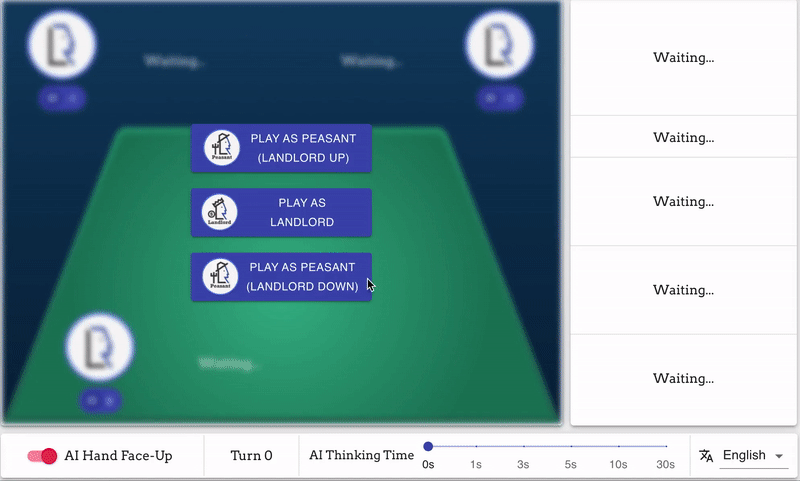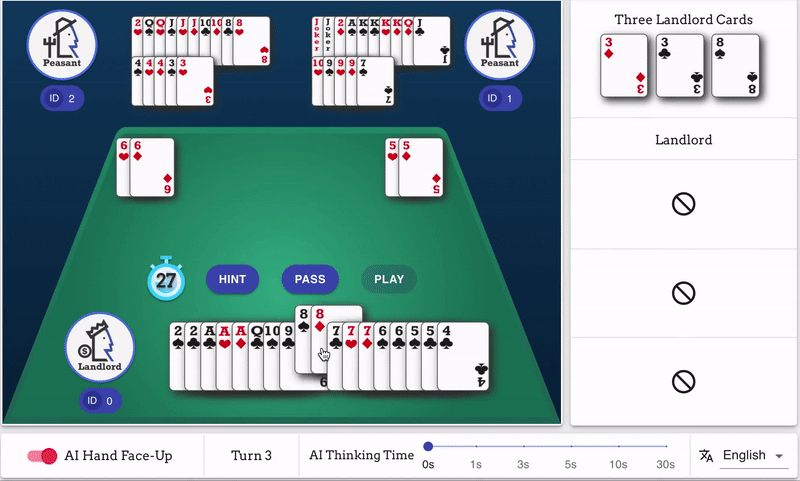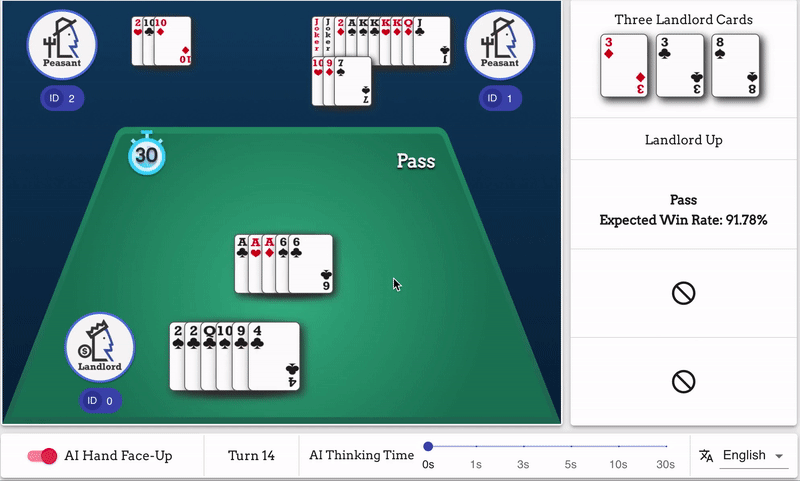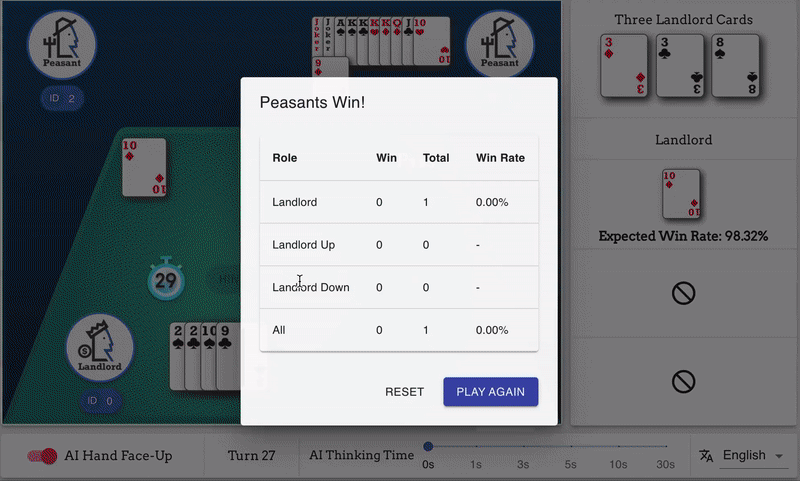
* GUI演示:[Songyi Huang](https://github.com/hsywhu)
* 社区贡献者: [@Vincentzyx](https://github.com/Vincentzyx)
## 鸣谢
* 本演示基于[RLCard-Showdown](https://github.com/datamllab/rlcard-showdown)项目
* 代码实现受到[TorchBeast](https://github.com/facebookresearch/torchbeast)项目的启发
## 引用
如果您用到我们的项目,请添加以下引用:
Zha, Daochen et al. “DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning.” ICML (2021).
```bibtex
@InProceedings{pmlr-v139-zha21a,
title = {DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning},
author = {Zha, Daochen and Xie, Jingru and Ma, Wenye and Zhang, Sheng and Lian, Xiangru and Hu, Xia and Liu, Ji},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
pages = {12333--12344},
year = {2021},
editor = {Meila, Marina and Zhang, Tong},
volume = {139},
series = {Proceedings of Machine Learning Research},
month = {18--24 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v139/zha21a/zha21a.pdf},
url = {http://proceedings.mlr.press/v139/zha21a.html},
abstract = {Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the hope that this insight could motivate future work.}
}
```
## 为什么斗地主具有挑战性
除了非完全信息带来的挑战外,斗地主本身也包含巨大的状态和动作空间。具体来说,斗地主的动作空间大小高达10^4(详见[该表格](https://github.com/datamllab/rlcard#available-environments))。不幸的是,大部分强化学习算法都只能处理很小的动作空间。并且,斗地主的玩家需要在部分可观测的环境中,与其他玩家对抗或合作,例如:两个农民玩家需要作为一个团队对抗地主玩家。对对抗和合作同时进行建模一直以来是学术界的一个开放性问题。
在本研究工作中,我们提出了将深度蒙特卡洛(Deep Monte Carlo, DMC)与动作编码和并行演员(Parallel Actors)相结合的方法,为斗地主提供了一个简单而有效的解决方案,详见[我们的论文](https://arxiv.org/abs/2106.06135)。
## 安装
训练部分的代码是基于GPU设计的,因此如果想要训练模型,您需要先安装CUDA。安装步骤可以参考[官网教程](https://docs.nvidia.com/cuda/index.html#installation-guides)。对于评估部分,CUDA是可选项,您可以使用CPU进行评估。
首先,克隆本仓库(如果您访问Github较慢,国内用户可以使用[Gitee镜像](https://gitee.com/daochenzha/DouZero)):
```
git clone https://github.com/kwai/DouZero.git
```
确保您已经安装好Python 3.6及以上版本,然后安装依赖:
```
cd douzero
pip3 install -r requirements.txt
```
我们推荐通过以下命令安装稳定版本的Douzero:
```
pip3 install douzero
```
如果您访问较慢,国内用户可以通过清华镜像源安装:
```
pip3 install douzero -i https://pypi.tuna.tsinghua.edu.cn/simple
```
或是安装最新版本(可能不稳定):
```
pip3 install -e .
```
注意,Windows用户只能用CPU来模拟。关于为什么GPU会出问题,详见[Windows下的问题](README.zh-CN.md#Windows下的问题)。但Windows用户仍可以[在本地运行演示](https://github.com/datamllab/rlcard-showdown)。
## 训练
假定您至少拥有一块可用的GPU,运行
```
python3 train.py
```
这会使用一块GPU训练DouZero。如果需要用多个GPU训练Douzero,使用以下参数:
* `--gpu_devices`: 用作训练的GPU设备名
* `--num_actor_devices`: 被用来进行模拟(如自我对弈)的GPU数量
* `--num_actors`: 每个设备的演员进程数
* `--training_device`: 用来进行模型训练的设备
例如,如果我们拥有4块GPU,我们想用前3个GPU进行模拟,每个GPU拥有15个演员,而使用第四个GPU进行训练,我们可以运行以下命令:
```
python3 train.py --gpu_devices 0,1,2,3 --num_actor_devices 3 --num_actors 15 --training_device 3
```
如果用CPU进行训练和模拟(Windows用户只能用CPU进行模拟),用以下参数:
* `--training_device cpu`: 用CPU来训练
* `--actor_device_cpu`: 用CPU来模拟
例如,用以下命令完全在CPU上运行:
```
python3 train.py --actor_device_cpu --training_device cpu
```
以下命令仅仅用CPU来跑模拟:
```
python3 train.py --actor_device_cpu
```
其他定制化的训练配置可以参考以下可选项:
```
--xpid XPID 实验id(默认值:douzero)
--save_interval SAVE_INTERVAL
保存模型的时间间隔(以分钟为单位)
--objective {adp,wp} 使用ADP或者WP作为奖励(默认值:ADP)
--actor_device_cpu 用CPU进行模拟
--gpu_devices GPU_DEVICES
用作训练的GPU设备名
--num_actor_devices NUM_ACTOR_DEVICES
被用来进行模拟(如自我对弈)的GPU数量
--num_actors NUM_ACTORS
每个设备的演员进程数
--training_device TRAINING_DEVICE
用来进行模型训练的设备。`cpu`表示用CPU训练
--load_model 读取已有的模型
--disable_checkpoint 禁用保存检查点
--savedir SAVEDIR 实验数据存储跟路径
--total_frames TOTAL_FRAMES
Total environment frames to train for
--exp_epsilon EXP_EPSILON
探索概率
--batch_size BATCH_SIZE
训练批尺寸
--unroll_length UNROLL_LENGTH
展开长度(时间维度)
--num_buffers NUM_BUFFERS
共享内存缓冲区的数量
--num_threads NUM_THREADS
学习者线程数
--max_grad_norm MAX_GRAD_NORM
最大梯度范数
--learning_rate LEARNING_RATE
学习率
--alpha ALPHA RMSProp平滑常数
--momentum MOMENTUM RMSProp momentum
--epsilon EPSILON RMSProp epsilon
```
## 评估
评估可以使用GPU或CPU进行(GPU效率会高得多)。预训练模型可以通过[Google Drive](https://drive.google.com/drive/folders/1NmM2cXnI5CIWHaLJeoDZMiwt6lOTV_UB?usp=sharing)或[百度网盘](https://pan.baidu.com/s/18g-JUKad6D8rmBONXUDuOQ), 提取码: 4624 下载。将预训练权重放到`baselines/`目录下。模型性能通过自我对弈进行评估。我们提供了一些其他预训练模型和一些启发式方法作为基准:
* [random](douzero/evaluation/random_agent.py): 智能体随机出牌(均匀选择)
* [rlcard](douzero/evaluation/rlcard_agent.py): [RLCard](https://github.com/datamllab/rlcard)项目中的规则模型
* SL (`baselines/sl/`): 基于人类数据进行深度学习的预训练模型
* DouZero-ADP (`baselines/douzero_ADP/`): 以平均分数差异(Average Difference Points, ADP)为目标训练的Douzero智能体
* DouZero-WP (`baselines/douzero_WP/`): 以胜率(Winning Percentage, WP)为目标训练的Douzero智能体
### 第1步:生成评估数据
```
python3 generate_eval_data.py
```
以下为一些重要的超参数。
* `--output`: pickle数据存储路径
* `--num_games`: 生成数据的游戏局数,默认值 10000
## 第2步:自我对弈
```
python3 evaluate.py
```
以下为一些重要的超参数。
* `--landlord`: 扮演地主的智能体,可选值:random, rlcard或预训练模型的路径
* `--landlord_up`: 扮演地主上家的智能体,可选值:random, rlcard或预训练模型的路径
* `--landlord_down`: 扮演地主下家的智能体,可选值:random, rlcard或预训练模型的路径
* `--eval_data`: 包含评估数据的pickle文件
* `--num_workers`: 用多少个进程进行模拟
* `--gpu_device`: 用哪个GPU设备进行模拟。默认用CPU
例如,可以通过以下命令评估DouZero-ADP智能体作为地主对阵随机智能体
```
python3 evaluate.py --landlord baselines/douzero_ADP/landlord.ckpt --landlord_up random --landlord_down random
```
以下命令可以评估DouZero-ADP智能体作为农民对阵RLCard智能体
```
python3 evaluate.py --landlord rlcard --landlord_up baselines/douzero_ADP/landlord_up.ckpt --landlord_down baselines/douzero_ADP/landlord_down.ckpt
```
默认情况下,我们的模型会每半小时保存在`douzero_checkpoints/douzero`路径下。我们提供了一个脚本帮助您定位最近一次保存检查点。运行
```
sh get_most_recent.sh douzero_checkpoints/douzero/
```
之后您可以在`most_recent_model`路径下找到最近一次保存的模型。
## Windows下的问题
如果您使用的是Windows系统并用GPU进行模拟,您将可能遇到`operation not supported`错误。这是由于Windows系统不支持CUDA tensor上的多进程。但是,由于我们的代码是对GPU进行优化,有对CUDA tensor的大量操作。如果您有解决方案,请联系我们!
## 核心团队
* 算法:[Daochen Zha](https://github.com/daochenzha), [Jingru Xie](https://github.com/karoka), Wenye Ma, Sheng Zhang, [Xiangru Lian](https://xrlian.com/), Xia Hu, [Ji Liu](http://jiliu-ml.org/)
* GUI演示:[Songyi Huang](https://github.com/hsywhu)
* 社区贡献者: [@Vincentzyx](https://github.com/Vincentzyx)
## 鸣谢
* 本演示基于[RLCard-Showdown](https://github.com/datamllab/rlcard-showdown)项目
* 代码实现受到[TorchBeast](https://github.com/facebookresearch/torchbeast)项目的启发