diff --git a/product/en/docs-uqbar/v2.0/toc.md b/product/en/docs-uqbar/v2.0/toc.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3a8c5aba681d451dc343f5a60e14f0ce993eaa8
--- /dev/null
+++ b/product/en/docs-uqbar/v2.0/toc.md
@@ -0,0 +1,65 @@
+
+
+
+# Uqbar Documentation 2.0.0
+
+## Documentation List
+
++ [About Uqbar](/overview.md)
++ [Release Note](/release-notes/release-note.md)
+ + [Uqbar 2.0.0](./release-notes/2.0.0.md)
++ [Uqbar Installation](/ptk-based-installation.md)
++ [Uqbar Management](/uqbar-management.md)
++ [Data Retention Policy](./retention-policy.md)
++ [Time-Series Table Management](/time-series-table-management.md)
++ [Time-Series Data Write](/data-write/data-write-introduction.md)
+ + [Time-Series Data Write Method](/data-write/data-writing-method/data-writing-method.md)
+ + [Using SQL Statements to Write Data](/data-write/data-writing-method/SQL-supported-for-importing-data-to-table.md)
+ + [Using Drivers to Write Data](/data-write/data-writing-method/driver-supported-for-importing-data-to-table.md)
+ + [Using Kafka to Write Data](/data-write/data-writing-method/Kafka-supported-for-importing-data-to-table.md)
+ + [Time-Series Data Write Model](/data-write/data-writing-model/data-writing-model.md)
+ + [Single-Field and Multi-Field Model](/data-write/data-writing-model/single-field-and-multiple-field-model.md)
+ + [Data Imported Out of Order](/data-write/data-writing-model/data-imported-out-of-order.md)
+ + [Data Imported Without the Time Field](/data-write/data-writing-model/data-imported-without-the-time-field.md)
++ [Data Compression](/data-compression.md)
++ [Data Deletion](/expired-deletion.md)
++ [Data Query](./query-data/query-data.md)
+ + [Aggregation Operator](./query-data/aggregation-operator/aggregation-operator.md)
+ + [time_bucket()](./query-data/aggregation-operator/time-bucket.md)
+ + [time_bucket_gapfill()](./query-data/aggregation-operator/time-bucket-gapfill.md)
+ + [histogram()](./query-data/aggregation-operator/histogram.md)
+ + [Selection Operator](./query-data/selection-operator/selection-operator.md)
+ + [first()/last()](./query-data/selection-operator/first-last.md)
+ + [Conversion Operator](./query-data/conversion-operator.md)
+ + [Join Query](./query-data/join-query.md)
+ + [LATERAL Keyword](./query-data/lateral-keyword.md)
+ + [Index](./query-data/index.md)
++ [Continuous Aggregation](./continuous-aggregation.md)
++ [Time-Series Views](/timeseries-views/timeseries-views.md)
+ + [timeseries_views.bgw_job](/timeseries-views/timeseries_views.bgw_job.md)
+ + [timeseries_views.compression_chunkgroup](/timeseries-views/timeseries_views.compression_chunkgroup.md)
+ + [timeseries_views.compression_table](/timeseries-views/timeseries_views.compression_table.md)
+ + [timeseries_views.continuous_aggregation](/timeseries-views/timeseries_views.continuous_aggregation.md)
+ + [timeseries_views.policies](/timeseries-views/timeseries_views.policies.md)
+ + [timeseries_views.tschunkgroup](/timeseries-views/timeseries_views.tschunkgroup.md)
+ + [timeseries_views.tstable](/timeseries-views/timeseries_views.tstable.md)
++ [Cluster Management](/cluster-management.md)
++ [Backup and Restoration](/backup-restore.md)
++ [Security](/security.md)
++ [GUC Parameters](/guc-parameters.md)
++ [SQL Syntax](/uqbar-sql-syntax/uqbar-sql-syntax.md)
+ + [ALTER CONTINUOUS AGGREGATION](/uqbar-sql-syntax/ALTER-CONTINUOUS-AGGREGATION.md)
+ + [ALTER TIMESERIES POLICY](/uqbar-sql-syntax/ALTER-TIMESERIES-POLICY.md)
+ + [ALTER TIMESERIES TABLE](/uqbar-sql-syntax/ALTER-TIMESERIES-TABLE.md)
+ + [COMPRESS TIMESERIES](/uqbar-sql-syntax/COMPRESS-TIMESERIES.md)
+ + [CREATE CONTINUOUS AGGREGATION](./uqbar-sql-syntax/CREATE-CONTINUOUS-AGGREGATION.md)
+ + [CREATE TIMESERIES POLICY](/uqbar-sql-syntax/CREATE-TIMESERIES-POLICY.md)
+ + [CREATE TIMESERIES TABLE](/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md)
+ + [DROP CONTINUOUS AGGREGATION](./uqbar-sql-syntax/DROP-CONTINUOUS-AGGREGATION.md)
+ + [DROP TIMESERIES POLICY](/uqbar-sql-syntax/DROP-TIMESERIES-POLICY.md)
+ + [DROP TIMESERIES TABLE](/uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md)
++ [Third Party Tools Support](/third-party-tools-support/third-party-tools-support.md)
+ + [Kafka](/third-party-tools-support/kafka.md)
+ + [Grafana](/third-party-tools-support/grafana.md)
+ + [Prometheus](./third-party-tools-support/prometheus.md)
++ [Glossary](/glossary.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v1.1/query-data.md b/product/zh/docs-uqbar/v1.1/query-data.md
index 6e09e58df6ac15b9cbfcab6e45c94931cfdc81ee..3776d1aeda9cb439116d7e05e5b7ff2155130043 100644
--- a/product/zh/docs-uqbar/v1.1/query-data.md
+++ b/product/zh/docs-uqbar/v1.1/query-data.md
@@ -28,7 +28,7 @@ Uqbar使用SQL作为查询语言,用户可以通过客户端或者不同的驱
### time_bucket()
-time_bucket时间范围对齐函数,用于将一个时间按照bucket_width对齐到一个时间点,方便后续对时间聚合。
+将时间序列数据按照指定的时间间隔分组,并对这些分组的数据进行聚合操作,如计算平均值、求和等。
#### 语法
@@ -88,15 +88,12 @@ Uqbar=# select time_bucket('2 minute',time) as bucket, sum(value) from t1 group
当前版本的Uqbar支持以下常用选择算子:
-| 函数 | 用途 |
-| ---------- | ------------- |
-| FIRST | 取最早的值 |
-| LAST | 取最晚的值 |
-| MAX | 取最大的值 |
-| MIN | 取最小的值 |
-| PERCENTILE | 计算百分位值 |
-| SAMPLE | 返回N个抽样 |
-| TOP | 取最大的N个值 |
+| 函数 | 用途 |
+| ----- | ---------- |
+| FIRST | 取最早的值 |
+| LAST | 取最晚的值 |
+| MAX | 取最大的值 |
+| MIN | 取最小的值 |
### first() / last()
@@ -167,6 +164,60 @@ shanghai | 29
支持时序表与关系表、时序表与时序表之间join查询。
+```sql
+Uqbar=# CREATE TABLE cpu_info (id int, arch text, cores int, speed float);
+
+Uqbar=# INSERT INTO cpu_info VALUES (1, 'aarch64', 8, 2000);
+Uqbar=# INSERT INTO cpu_info VALUES (2, 'x86_64', 8, 2200);
+Uqbar=# INSERT INTO cpu_info VALUES (3, 'aarch64', 16, 2000);
+Uqbar=# INSERT INTO cpu_info VALUES (4, 'x86_64', 16, 2200);
+
+Uqbar=# DROP TIMESERIES TABLE IF EXISTS cpu;
+Uqbar=# CREATE TIMESERIES TABLE cpu(time timestamp tstime, tags_id int tstag, usage float);
+
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-01 00:00:00', 1, 82);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-01 12:00:00', 1, 83);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-01 23:59:59', 1, 84);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 1, 92);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 12:00:00', 1, 93);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 23:59:59', 1, 94);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 2, 84);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 12:00:00', 2, 85);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 23:59:59', 2, 86);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 3, 93);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 3, 92);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 3, 91);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 5, 91);
+
+Uqbar=# SELECT cpu.time, cpu_info.arch, cpu_info.id, cpu_info.cores, cpu_info.speed FROM cpu LEFT JOIN cpu_info ON cpu.tags_id = cpu_info.id ORDER BY cpu.tags_id,cpu.time ASC;
+ time | arch | id | cores | speed
+---------------------+---------+----+-------+-------
+ 2023-05-01 00:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-01 12:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-01 23:59:59 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 00:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 12:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 23:59:59 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 00:00:00 | x86_64 | 2 | 8 | 2200
+ 2023-05-02 12:00:00 | x86_64 | 2 | 8 | 2200
+ 2023-05-02 23:59:59 | x86_64 | 2 | 8 | 2200
+ 2023-05-02 00:00:00 | aarch64 | 3 | 16 | 2000
+ 2023-05-02 00:00:00 | aarch64 | 3 | 16 | 2000
+ 2023-05-02 00:00:00 | aarch64 | 3 | 16 | 2000
+ 2023-05-02 00:00:00 | | | |
+(13 rows)
+
+Uqbar=# SELECT time_bucket('1 day',time) as bucket, cpu_info.id, avg(usage) FROM cpu LEFT JOIN cpu_info ON cpu.tags_id = cpu_info.id GROUP BY bucket,cpu_info.id ORDER BY cpu_info.id,bucket ASC;
+ bucket | id | avg
+---------------------+----+-----
+ 2023-05-01 00:00:00 | 1 | 83
+ 2023-05-02 00:00:00 | 1 | 93
+ 2023-05-02 00:00:00 | 2 | 85
+ 2023-05-02 00:00:00 | 3 | 92
+ 2023-05-02 00:00:00 | | 91
+(5 rows)
+```
+
## 索引
diff --git a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.bgw_job.md b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.bgw_job.md
index 757c760d2873ecd1ae0f8c59766d5082e3d77e8c..517b3457f7caf4daaef12c9e901500ae793bd2f3 100644
--- a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.bgw_job.md
+++ b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.bgw_job.md
@@ -9,7 +9,7 @@ date: 2022-11-24
Uqbar提供后台任务视图,供用户查看定期删除、压缩等后台任务的运行状况。timeseries_views这个schema下提供了bgw_job视图,供用户查看所有时序表策略。
-**表1** bgw_job视图属性:
+**表1** bgw_job视图属性
| 字段 | 类型 | 描述 |
| :------------ | :-------- | :----------------------------------------------------------- |
diff --git a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_chunkgroup.md b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_chunkgroup.md
index 89fe29aba128b5fe0b4d177713def10a214bfcfd..0078be4ee41ed3612594aea65b4ccb25d8ff3568 100644
--- a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_chunkgroup.md
+++ b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_chunkgroup.md
@@ -9,7 +9,7 @@ date: 2022-11-24
timeseries_views模式下的compression_chunkgroup视图,供用户查看所有时序表分片的压缩率。after_compression_size和compression_ratio仅在chunkgroup被压缩后非空。
-**表1** compression_chunkgroup视图属性:
+**表1** compression_chunkgroup视图属性
| 字段 | 类型 | 描述 |
| :---------------------- | :----- | :--------------------------------- |
diff --git a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_table.md b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_table.md
index ce4662f072cfe52d0d1de7565de068d3cbbc01cc..6473ad3f8c421b212bb2ab52426981ea287a55d7 100644
--- a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_table.md
+++ b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.compression_table.md
@@ -9,7 +9,7 @@ date: 2022-11-24
timeseries_views模式下的compression_table视图,供用户查看所有时序表的压缩率。after_compression_size和compression_ratio仅在时序表存在至少一个被压缩的chunkgroup时非空。当存在至少一个chunkGroup被压缩后,after_compression_size为未压缩的chunkGroup的before_compression_size与被压缩的chunkGroup的after_compression_size之和。
-**表1** compression_table视图属性:
+**表1** compression_table视图属性
| 字段 | 类型 | 描述 |
| :---------------------- | :----- | :----------------------------- |
diff --git a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.policies.md b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.policies.md
index 00a37eccd84860c4a848ee56a0dd3238ee6a895c..8258cca4f571c949a17e80e7178735238d2f7bb3 100644
--- a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.policies.md
+++ b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.policies.md
@@ -9,7 +9,7 @@ date: 2022-11-24
Uqbar支持查看指定数据库下的所有保留策略。timeseries_views这个schema下提供了policies视图,供用户查看所有时序表策略。
-**表1** policies视图属性:
+**表1** policies视图属性
| 字段 | 类型 | 描述 |
| :----------------- | :------- | :--------------------------------------------------------- |
diff --git a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tschunkgroup.md b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tschunkgroup.md
index 536fc8e878ae16bf6376ab9c5a2604bc3f1144a1..97c7111d958642238daacf36807a01908bcc0014 100644
--- a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tschunkgroup.md
+++ b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tschunkgroup.md
@@ -9,7 +9,7 @@ date: 2022-11-24
用户可查看一个时序表的ChunkGroup列表视图。时序表按照时间范围被拆分为多个分片组(ChunkGroup),以分片组为单位进行过期删除,以便于对时序数据进行高效过期删除。
-**表1** tschunkgroup视图属性:
+**表1** tschunkgroup视图属性
| 字段 | 类型 | 描述 |
| :----------------- | :------- | :--------------------------------------- |
diff --git a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tstable.md b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tstable.md
index 50ae8e712e9ec5152f1e4da190b87670f0b53002..c7d5cd6b03545547bbd7870fa6a46a1a0e52cc01 100644
--- a/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tstable.md
+++ b/product/zh/docs-uqbar/v1.1/timeseries-views/timeseries_views.tstable.md
@@ -9,7 +9,7 @@ date: 2022-11-24
用户可查看当前数据库下的所有时序表。
-**表1** tstable视图属性:
+**表1** tstable视图属性
| 字段 | 类型 | 描述 |
| :---------- | :----- | :--------------------- |
diff --git a/product/zh/docs-uqbar/v1.1/toc.md b/product/zh/docs-uqbar/v1.1/toc.md
index 8271e70e7e0d8c5ba18b0d0414948d2129344df1..c4a2e187748368e9d59565b4648a36a709ec32db 100644
--- a/product/zh/docs-uqbar/v1.1/toc.md
+++ b/product/zh/docs-uqbar/v1.1/toc.md
@@ -45,7 +45,7 @@
+ [DROP TIMESERIES TABLE](/uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md)
+ [first()/last()](/uqbar-sql-syntax/first-last.md)
+ [time_bucket](/uqbar-sql-syntax/time_bucket.md)
-+ [三方工具支持](/third-party-tools-support/third-party-tools-support.md)
++ [第三方工具支持](/third-party-tools-support/third-party-tools-support.md)
+ [Kafka](/third-party-tools-support/kafka.md)
+ [Grafana](/third-party-tools-support/grafana.md)
+ [术语](/glossary.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v1.1/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md b/product/zh/docs-uqbar/v1.1/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md
index 4710d500173c1b30e1f8d69dceb47b1c0f332288..ee960fb666e597b963546324128487d9c3e31804 100644
--- a/product/zh/docs-uqbar/v1.1/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md
+++ b/product/zh/docs-uqbar/v1.1/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md
@@ -15,7 +15,7 @@ date: 2022-11-22
- 必须要指定 TSTIME 和 TSTAG 列。
-- 只能有一列指定为 TSTIME 列,且数据类型只能为时间类型,包括 timestamp [without time zone]、timestamp with time zone。openGauss中的 date 类型,内部实际类型是 timestamp [without time zone],除了日期外同时也包含时间信息,TSTIME 也可以支持 date 类型。而 “date” 类型只包含日期信息,不包含时间信息,所以不支持。
+- 只能有一列指定为 TSTIME 列,且数据类型只能为时间类型,包括 timestamp [without time zone]、timestamp with time zone。
- 支持数量为 [1, 32] 的列指定为 TSTAG,只允许数据类型为字符串类型 ,包括 “char”、char(n)、character(n)、nchar(n)、bpchar(n)、varchar(n)、character varying(n)、nvarchar(n)、varchar2(n)、nvarchar2(n) 和 text,不支持 clob 和 name。
@@ -27,8 +27,6 @@ date: 2022-11-22
- TSTIME 不支持用户设置 default,系统默认设置 TSTIME 为当前时间。
-- Field 列允许用户设置 NOT NULL。
-
- Field 列不支持自定义的数据类型,由于列存数据类型的限制,支持的数据类型如下( DATE 和 DATEARRAY 中 DATE 类型指的是 “date” 而不是 date) :
BOOL、HLL、BYTEA、CHAR、INT8、INT2、INT4、INT1、NUMERIC、BPCHAR、VARCHAR、NVARCHAR2、SMALLDATETIME、TEXT、OID、FLOAT4、FLOAT8、ABSTIME、RELTIME、TINTERVAL、INET、DATE、TIME、TIMESTAMP、TIMESTAMPTZ、INTERVAL、TIMETZ、MONEY、CIDR、BIT、VARBIT、CLOB、BOOLARRAY、HLL_ARRAY、BYTEARRAY、CHARARRAY、INT8ARRAY、INT2ARRAY、INT4ARRAY、INT1ARRAY、NUMERICARRAY、BPCHARARRAY、VARCHARARRAY、NVARCHAR2ARRAY、SMALLDATETIMEARRAY、TEXTARRAY、FLOAT4ARRAY、FLOAT8ARRAY、ABSTIMEARRAY、RELTIMEARRAY、INTERVALARRAY、INETARRAY、DATEARRAY、TIMEARRAY、TIMESTAMPARRAY、TIMESTAMPTZARRAY、ARRAYINTERVAL、TIMETZARRAY、MONEYARRAY、CIDRARRAY、BITARRAY、VARBITARRAY
diff --git a/product/zh/docs-uqbar/v2.0/backup-restore.md b/product/zh/docs-uqbar/v2.0/backup-restore.md
new file mode 100644
index 0000000000000000000000000000000000000000..9cd9a22f9a218964f53841545423771974d0efde
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/backup-restore.md
@@ -0,0 +1,986 @@
+---
+title: 备份恢复
+summary: 备份恢复
+author: Guo Huan
+date: 2022-11-24
+---
+
+# 备份恢复
+
+时序数据库提供数据备份恢复的工具,通过数据备份达到容灾的目的。
+
+Uqbar支持物理备份及恢复;物理备份支持全量备份和增量备份两种模式。时序表支持物理备份。
+
+## gs_basebackup
+
+### 背景信息
+
+Uqbar部署成功后,在数据库运行的过程中,会遇到各种问题及异常状态。Uqbar提供了gs_basebackup工具做基础的物理备份。gs_basebackup的实现目标是对服务器数据库文件的二进制进行拷贝,其实现原理使用了复制协议。远程执行gs_basebackup时,需要使用系统管理员账户。gs_basebackup当前支持热备份模式和压缩格式备份模式。
+
+>  **说明**:
+>
+> - gs_basebackup仅支持主机和备机的全量备份,不支持增量。
+> - gs_basebackup当前支持热备份模式和压缩格式备份模式。
+> - 若打开增量检测点功能且打开双写,gs_basebackup也会备份双写文件。
+> - gs_basebackup在备份包含绝对路径的表空间时,如果在同一台机器上进行备份,可以通过tablespace-mapping重定向表空间路径,或使用归档模式进行备份。
+> - 若pg_xlog目录为软链接,备份时将不会建立软链接,会直接将数据备份到目的路径的pg_xlog目录下。
+> - 备份过程中收回用户备份权限,可能导致备份失败,或者备份数据不可用。
+> - 如果因为网络临时故障等原因导致Server端无法应答,gs_basebackup将在最长等待120秒后退出。
+
+### 前提条件
+
+- 可以正常连接Uqbar数据库。
+- 备份过程中用户权限没有被回收。
+- pg_hba.conf中需要配置允许复制链接,且该连接必须由一个系统管理员建立。
+- 如果xlog传输模式为stream模式,需要配置max_wal_senders的数量,至少有一个可用。
+- 如果xlog传输模式为fetch模式,有必要把wal_keep_segments参数设置得足够高,这样在备份末尾之前日志不会被移除。
+- 在进行还原时,需要保证各节点备份目录中存在备份文件,若备份文件丢失,则需要从其他节点进行拷贝。
+
+### 语法
+
+- 显示帮助信息
+
+ ```bash
+ gs_basebackup -? | --help
+ ```
+
+- 显示版本号信息
+
+ ```bash
+ gs_basebackup -V | --version
+ ```
+
+### 参数说明
+
+gs_basebackup参数可以分为如下几类:
+
+- -D directory
+
+ 备份文件输出的目录,必选项。
+
+- 常用参数:
+
+ - -c,--checkpoint=fast|spread
+
+ 设置检查点模式为fast或者spread(默认)。
+
+ - -l,--label=LABEL
+
+ 为备份设置标签。
+
+ - -P,--progress
+
+ 启用进展报告。
+
+ - -v, --verbose
+
+ 启用冗长模式。
+
+ - -V, --version
+
+ 打印版本后退出。
+
+ - -?,--help
+
+ 显示gs_basebackup命令行参数。
+
+ - -T,--tablespace-mapping=olddir=newdir
+
+ 在备份期间将目录olddir中的表空间重定位到newdir中。为使之有效,olddir必须正好匹配表空间所在的路径(但如果备份中没有包含olddir中的表空间也不是错误)。olddir和newdir必须是绝对路径。如果一个路径凑巧包含了一个=符号,可用反斜线对它转义。对于多个表空间可以多次使用这个选项。
+
+ - -F,--format=plain|tar
+
+ 设置输出格式为plain(默认)或者tar。没有设置该参数的情况下,默认--format=plain。plain格式把输出写成平面文件,使用和当前数据目录和表空间相同的布局。当集簇没有额外表空间时,整个数据库将被放在目标目录中。如果集簇包含额外的表空间,主数据目录将被放置在目标目录中,但是所有其他表空间将被放在它们位于服务器上的相同的绝对路径中。tar模式将输出写成目标目录中的 tar 文件。主数据目录将被写入到一个名为base.tar的文件中,并且其他表空间将被以其 OID 命名。生成的tar包,需要用gs_tar命令解压。
+
+ - -X, --xlog-method=fetch|stream
+
+ 设置xlog传输方式。没有设置该参数的情况下,默认--xlog-method=stream。在备份中包括所需的预写式日志文件(WAL文件)。这包括所有在备份期间产生的预写式日志。fetch方式在备份末尾收集预写式日志文件。因此,有必要把wal_keep_segments参数设置得足够高,这样在备份末尾之前日志不会被移除。如果在要传输日志时它已经被轮转,备份将失败并且是不可用的。stream方式在备份被创建时流传送预写式日志。这将开启一个到服务器的第二连接并且在运行备份时并行开始流传输预写式日志。因此,它将使用最多两个由max_wal_senders参数配置的连接。只要客户端能保持接收预写式日志,使用这种模式不需要在主控机上保存额外的预写式日志。
+
+ - -x,--xlog 使用这个选项等效于和方法fetch一起使用-X。
+
+ - -Z --compress=level
+
+ 启用对 tar 文件输出的 gzip 压缩,并且制定压缩级别(0 到 9,0 是不压缩,9 是最佳压缩)。只有使用 tar 格式时压缩才可用,并且会在所有tar文件名后面自动加上后缀.gz。
+
+ - -z
+
+ 启用对 tar 文件输出的 gzip 压缩,使用默认的压缩级别。只有使用 tar 格式时压缩才可用,并且会在所有tar文件名后面自动加上后缀.gz。
+
+ - -t,--rw-timeout
+
+ 设置备份期间checkpoint的时间限制,默认限制时间为120s。当数据库全量checkpoint耗时较长时,可以适当增大rw-timeout限制时间。
+
+- 连接参数
+
+ - -h, --host=HOSTNAME
+
+ 指定正在运行服务器的主机名或者Unix域套接字的路径。
+
+ - -p,--port=PORT
+
+ 指定数据库服务器的端口号。
+
+ 可以通过port参数修改默认端口号。
+
+ - -U,--username=USERNAME
+
+ 指定连接数据库的用户。
+
+ - -s, --status-interval=INTERVAL
+
+ 发送到服务器的状态包的时间(以秒为单位)。
+
+ - -w,--no-password
+
+ 不出现输入密码提示。
+
+ - -W, --password
+
+ 当使用-U参数连接本地数据库或者连接远端数据库时,可通过指定该选项出现输入密码提示。
+
+### 示例
+
+```bash
+gs_basebackup -D /home/test/trunk/install/data/backup -h 127.0.0.1 -p 21233
+INFO: The starting position of the xlog copy of the full build is: 0/1B800000. The slot minimum LSN is: 0/1B800000.
+```
+
+### 从备份文件恢复数据
+
+当数据库发生故障时需要从备份文件进行恢复。因为gs_basebackup是对数据库按二进制进行备份,因此恢复时可以直接拷贝替换原有的文件,或者直接在备份的库上启动数据库。
+
+>  **说明**:
+>
+> - 若当前数据库实例正在运行,直接从备份文件启动数据库可能会存在端口冲突,这时需要修改配置文件的port参数,或者在启动数据库时指定一下端口。
+> - 若当前备份文件为主备数据库,可能需要修改一下主备之间的复制连接。即配置文件postgresql.conf中的replconninfo1,replconninfo2等。
+> - 若配置文件postgresql.conf的参数data_directory打开且有配置,当使用备份目录启动数据库时候,data_directory和备份目录不同会导致启动失败。可以修改data_directory的值为新的数据目录,或者注释掉该参数。
+
+若要在原库的地方恢复数据库,参考步骤如下:
+
+1. 停止数据库服务器,具体操作请参见《管理指南》。
+2. 将原数据库和所有表空间复制到另外一个位置, 以备后面需要。
+3. 清理原库中的所有或部分文件。
+4. 使用数据库系统用户权限从备份中还原需要的数据库文件。
+5. 若数据库中存在链接文件,需要修改使其链接到正确的文件。
+6. 重启数据库服务器,并检查数据库内容,确保数据库已经恢复到所需的状态。
+
+>  **说明**:
+>
+> - 暂不支持备份文件增量恢复。
+> - 恢复后需要检查数据库中的链接文件是否链接到正确的文件。
+
+
+
+## gs_probackup
+
+### 背景信息
+
+gs_probackup是一个用于管理Uqbar数据库备份和恢复的工具。它对Uqbar实例进行定期备份,以便在数据库出现故障时能够恢复服务器。
+
+- 可用于备份单机数据库,也可对主机或者主节点数据库备机进行备份,为物理备份。
+- 可备份外部目录的内容,如脚本文件、配置文件、日志文件、dump文件等。
+- 支持增量备份、定期备份和远程备份。
+- 可设置备份的留存策略。
+
+### 前提条件
+
+- 可以正常连接Uqbar数据库。
+- 若要使用PTRACK增量备份,需在postgresql.conf中手动添加参数“enable_cbm_tracking = on”。
+- 为了防止xlog在传输结束前被清理,请适当调高postgresql.conf文件中wal_keep_segments的值。
+
+### 限制说明
+
+- 备份必须由运行数据库服务器的用户执行。
+- 备份和恢复的数据库服务器的主版本号必须相同。
+- 如果要通过ssh在远程模式下备份数据库,需要在本地和远程主机安装相同主版本的数据库,并通过ssh-copy-id remote_user@remote_host命令设置本地主机备份用户和远程主机数据库用户的无密码ssh连接。
+- 远程模式下只能执行add-instance、backup、restore子命令。
+- 使用restore子命令前,应先停止uqbar进程。
+- 当存在用户自定义表空间时,备份的时候要加上--external-dirs 参数,否则,该表空间不会被备份。
+- 当备份的规模比较大时,为了防止备份过程中timeout发生,请适当调整postgresql.conf文件的参数 session_timeout、wal_sender_timeout。并且在备份的命令行参数中适当调整参数--rw-timeout的值。
+- 恢复时,使用-T选项把备份中的外部目录重定向到新目录时,请同时指定参数--external-mapping。
+- 当使用远程备份时,请确保远程机器和备份机器的时钟同步,以防止使用--recovery-target-time恢复的场合,启动uqbar时有可能会失败。
+- 当远程备份有效时\(remote-proto=ssh\),请确保-h和--remote-host指定的是同一台机器。当远程备份无效时,如果指定了-h选项,请确保-h指定的是本机地址或本机主机名。
+- 当前暂不支持备份逻辑复制槽。
+
+### 命令说明
+
+- 打印gs_probackup版本。
+
+ ```bash
+ gs_probackup -V|--version
+ gs_probackup version
+ ```
+
+- 显示gs_probackup命令的摘要信息。如果指定了gs_probackup的子命令,则显示可用于此子命令的参数的详细信息。
+
+ ```bash
+ gs_probackup -?|--help
+ gs_probackup help [command]
+ ```
+
+- 初始化备份路径_backup-path_中的备份目录,该目录将存储已备份的内容。如果备份路径_backup-path_已存在,则_backup-path_必须为空目录。
+
+ ```bash
+ gs_probackup init -B backup-path [--help]
+ ```
+
+- 在备份路径_backup-path_内初始化一个新的备份实例,并生成pg_probackup.conf配置文件,该文件保存了指定数据目录_pgdata-path_的gs_probackup设置。
+
+ ```bash
+ gs_probackup add-instance -B backup-path -D pgdata-path --instance=instance_name
+ [-E external-directories-paths]
+ [remote_options]
+ [--help]
+ ```
+
+- 在备份路径_backup-path_内删除指定实例相关的备份内容。
+
+ ```bash
+ gs_probackup del-instance -B backup-path --instance=instance_name
+ [--help]
+ ```
+
+- 将指定的连接、压缩、日志等相关设置添加到pg_probackup.conf配置文件中,或修改已设置的值。不推荐手动编辑pg_probackup.conf配置文件。
+
+ ```bash
+ gs_probackup set-config -B backup-path --instance=instance_name
+ [-D pgdata-path] [-E external-directories-paths] [--archive-timeout=timeout]
+ [--retention-redundancy=retention-redundancy] [--retention-window=retention-window] [--wal-depth=wal-depth]
+ [--compress-algorithm=compress-algorithm] [--compress-level=compress-level]
+ [-d dbname] [-h hostname] [-p port] [-U username]
+ [logging_options] [remote_options]
+ [--help]
+ ```
+
+- 将备份相关设置添加到backup.control配置文件中,或修改已设置的值。
+
+ ```bash
+ gs_probackup set-backup -B backup-path --instance=instance_name -i backup-id
+ [--note=text] [pinning_options]
+ [--help]
+ ```
+
+- 显示位于备份目录中的pg_probackup.conf配置文件的内容。可以通过指定--format=json选项,以json格式显示。默认情况下,显示为纯文本格式。
+
+ ```bash
+ gs_probackup show-config -B backup-path --instance=instance_name
+ [--format=plain|json]
+ [--help]
+ ```
+
+- 显示备份目录的内容。如果指定了instance_name和backup_id,则显示该备份的详细信息。可以通过指定--format=json选项,以json格式显示。默认情况下,备份目录的内容显示为纯文本格式。
+
+ ```bash
+ gs_probackup show -B backup-path
+ [--instance=instance_name [-i backup-id]] [--archive] [--format=plain|json]
+ [--help]
+ ```
+
+- 创建指定实例的备份。
+
+ ```bash
+ gs_probackup backup -B backup-path --instance=instance_name -b backup-mode
+ [-D pgdata-path] [-C] [-S slot-name] [--temp-slot] [--backup-pg-log] [-j threads_num] [--progress]
+ [--no-validate] [--skip-block-validation] [-E external-directories-paths] [--no-sync] [--note=text]
+ [--archive-timeout=timeout] [-t rwtimeout]
+ [logging_options] [retention_options] [compression_options]
+ [connection_options] [remote_options] [pinning_options]
+ [--help]
+ ```
+
+- 从备份目录_backup-path_中的备份副本恢复指定实例。如果指定了恢复目标选项,gs_probackup将查找最近的备份并将其还原到指定的恢复目标。否则,使用最近一次备份。
+
+ ```bash
+ gs_probackup restore -B backup-path --instance=instance_name
+ [-D pgdata-path] [-i backup_id] [-j threads_num] [--progress] [--force] [--no-sync] [--no-validate] [--skip-block-validation]
+ [--external-mapping=OLDDIR=NEWDIR] [-T OLDDIR=NEWDIR] [--skip-external-dirs] [-I incremental_mode]
+ [recovery_options] [remote_options] [logging_options]
+ [--help]
+ ```
+
+- 将指定的增量备份与其父完全备份之间的所有增量备份合并到父完全备份。父完全备份将接收所有合并的数据,而已合并的增量备份将作为冗余被删除。
+
+ ```bash
+ gs_probackup merge -B backup-path --instance=instance_name -i backup_id
+ [-j threads_num] [--progress] [logging_options]
+ [--help]
+ ```
+
+- 删除指定备份,或删除不满足当前保留策略的备份。
+
+ ```bash
+ gs_probackup delete -B backup-path --instance=instance_name
+ [-i backup-id | --delete-expired | --merge-expired | --status=backup_status]
+ [--delete-wal] [-j threads_num] [--progress]
+ [--retention-redundancy=retention-redundancy] [--retention-window=retention-window]
+ [--wal-depth=wal-depth] [--dry-run]
+ [logging_options]
+ [--help]
+ ```
+
+- 验证恢复数据库所需的所有文件是否存在且未损坏。如果未指定_instance_name_,gs_probackup将验证备份目录中的所有可用备份。如果指定_instance_name_而不指定任何附加选项,gs_probackup将验证此备份实例的所有可用备份。如果指定了_instance_name_并且指定_backup-id_或恢复目标相关选项,gs_probackup将检查是否可以使用这些选项恢复数据库。
+
+ ```bash
+ gs_probackup validate -B backup-path
+ [--instance=instance_name] [-i backup-id]
+ [-j threads_num] [--progress] [--skip-block-validation]
+ [--recovery-target-time=time | --recovery-target-xid=xid | --recovery-target-lsn=lsn | --recovery-target-name=target-name]
+ [--recovery-target-inclusive=boolean]
+ [logging_options]
+ [--help]
+ ```
+
+### 参数说明
+
+#### 通用参数
+
+- command
+
+ gs_probackup除version和help以外的子命令:init、add-instance、del-instance、set-config、set-backup、show-config、show、backup、restore、merge、delete、validate。
+
+- -?, --help
+
+ 显示gs_probackup命令行参数的帮助信息,然后退出。
+
+ 子命令中只能使用-help,不能使用-?。
+
+- -V, --version
+
+ 打印gs_probackup版本,然后退出。
+
+- -B *backup-path*, --backup-path=*backup-path*
+
+ 备份的路径。
+
+ 系统环境变量:$BACKUP_PATH
+
+- -D *pgdata-path*, --pgdata=*pgdata-path*
+
+ 数据目录的路径。
+
+ 系统环境变量:$PGDATA
+
+- --instance=*instance_name*
+
+ 实例名。
+
+- -i *backup-id*, --backup-id=*backup-id*
+
+ 备份的唯一标识。
+
+- --format=*format*
+
+ 指定显示备份信息的格式,支持plain和json格式。
+
+ 默认值:plain
+
+- --status=*backup_status*
+
+ 删除指定状态的所有备份,包含以下状态:
+
+ - OK:备份已完成且有效。
+ - DONE:备份已完成但未经过验证。
+ - RUNNING:备份正在进行中。
+ - MERGING:备份正在合并中。
+ - DELETING:备份正在删除中。
+ - CORRUPT:部分备份文件已损坏。
+ - ERROR:由于意外错误,备份失败。
+ - ORPHAN:由于其父备份之一已损坏或丢失,备份无效。
+
+- -j *threads_num*, --threads=*threads_num*
+
+ 设置备份、还原、合并进程的并行线程数。
+
+- --archive
+
+ 显示WAL归档信息。
+
+- --progress
+
+ 显示进度。
+
+- --note=*text*
+
+ 给备份添加note。
+
+#### 备份相关参数
+
+- -b *backup-mode*, --backup-mode=*backup-mode*
+
+ 指定备份模式,支持FULL和PTRACK。
+
+ FULL:创建全量备份,全量备份包含所有数据文件。
+
+ PTRACK:创建PTRACK增量备份。
+
+- -C, --smooth-checkpoint
+
+ 将检查点在一段时间内展开。默认情况下,gs_probackup会尝试尽快完成检查点。
+
+- -S *slot-name*, --slot=*slot-name*
+
+ 指定WAL流处理的复制slot。
+
+- --temp-slot
+
+ 在备份的实例中为WAL流处理创建一个临时物理复制slot,它确保在备份过程中,所有所需的WAL段仍然是可用的。
+
+ 默认的slot名为pg_probackup_slot,可通过选项--slot/-S更改。
+
+- --backup-pg-log
+
+ 将日志目录包含到备份中。此目录通常包含日志消息。默认情况下包含日志目录,但不包含日志文件。如果修改了默认的日志路径,需要备份日志文件时可使用-E参数进行备份,使用方法见下文。
+
+- -E *external-directories-paths*, --external-dirs=*external-directories-paths*
+
+ 将指定的目录包含到备份中。此选项对于备份位于数据目录外部的脚本、sql转储和配置文件很有用。如果要备份多个外部目录,请在Unix上用冒号分隔它们的路径。
+
+ 例如:-E /tmp/dir1:/tmp/dir2
+
+- --skip-block-validation
+
+ 关闭块级校验,加快备份速度。
+
+- --no-validate
+
+ 在完成备份后跳过自动验证。
+
+- --no-sync
+
+ 不将备份文件同步到磁盘。
+
+- --archive-timeout=*timeout*
+
+ 以秒为单位设置流式处理的超时时间。
+
+ 默认值:300
+
+- -t rwtimeout
+
+ 以秒为单位的连接的超时时间。
+
+ 默认值: 120
+
+#### 恢复相关参数
+
+- -I, --incremental-mode=none|checksum|lsn
+
+ 若PGDATA中可用的有效页没有修改,则重新使用它们。
+
+ 默认值:none
+
+- --external-mapping=*OLDDIR=NEWDIR*
+
+ 在恢复时,将包含在备份中的外部目录从_OLDDIR_重新定位到_NEWDIR_目录。_OLDDIR_和_NEWDIR_都必须是绝对路径。如果路径中包含“=”,则使用反斜杠转义。此选项可为多个目录多次指定。
+
+- -T *OLDDIR=NEWDIR*, --tablespace-mapping=*OLDDIR=NEWDIR*
+
+ 在恢复时,将表空间从_OLDDIR_重新定位到_NEWDIR_目录。_OLDDIR_和_NEWDIR_必须都是绝对路径。如果路径中包含“=”,则使用反斜杠转义。多个表空间可以多次指定此选项。此选项必须和--external-mapping一起使用。
+
+- --skip-external-dirs
+
+ 跳过备份中包含的使用-external-dirs选项指定的外部目录。这些目录的内容将不会被恢复。
+
+- --skip-block-validation
+
+ 跳过块级校验,以加快验证速度。在恢复之前的自动验证期间,将仅做文件级别的校验。
+
+- --no-validate
+
+ 跳过备份验证。
+
+- --force
+
+ 允许忽略备份的无效状态。如果出于某种原因需要从损坏的或无效的备份中恢复数据,可以使用此标志。请谨慎使用。
+
+#### 恢复目标相关参数(recovery_options)
+
+>  **说明**: 当前不支持配置连续的WAL归档的PITR,因而使用这些参数会有一定限制,具体如下描述。 如果需要使用持续归档的WAL日志进行PITR恢复,请按照下面描述的步骤:
+>
+> 1. 将物理备份的文件替换目标数据库目录。
+> 2. 删除数据库目录下pg_xlog/中的所有文件。
+> 3. 将归档的WAL日志文件复制到pg_xlog文件中(此步骤可以省略,通过配置recovery.conf恢复命令文件中的restore_command项替代)。
+> 4. 在数据库目录下创建恢复命令文件recovery.conf,指定数据库恢复的程度。
+> 5. 启动数据库。
+> 6. 连接数据库,查看是否恢复到希望预期的状态。若已经恢复到预期状态,通过pg_xlog_replay_resume()指令使主节点对外提供服务。
+
+- --recovery-target-lsn=*lsn*
+
+ 指定要恢复到的lsn,当前只能指定备份的stop lsn。
+
+- --recovery-target-name=*target-name*
+
+ 指定要将数据恢复到的已命名的保存点,保存点可以通过查看备份中recovery-name字段得到。
+
+- --recovery-target-time=*time*
+
+ 指定要恢复到的时间,当前只能指定备份中的recovery-time。
+
+- --recovery-target-xid=*xid*
+
+ 指定要恢复到的事务ID,当前只能指定备份中的recovery-xid。
+
+- --recovery-target-inclusive=*boolean*
+
+ 当该参数指定为true时,恢复目标将包括指定的内容。
+
+ 当该参数指定为false时,恢复目标将不包括指定的内容。
+
+ 该参数必须和--recovery-target-name、--recovery-target-time、--recovery-target-lsn或--recovery-target-xid一起使用。
+
+#### 留存相关参数(retention_options)
+
+>  **说明**: 可以和backup和delete命令一起使用这些参数。
+
+- --retention-redundancy=*retention-redundancy*
+
+ 指定在数据目录中留存的完整备份数。必须为正整数。0表示禁用此设置。
+
+ 默认值:0
+
+- --retention-window=*retention-window*
+
+ 指定留存的天数。必须为正整数。0表示禁用此设置。
+
+ 默认值:0
+
+- --wal-depth=*wal-depth*
+
+ 每个时间轴上必须留存的执行PITR能力的最新有效备份数。必须为正整数。0表示禁用此设置。
+
+ 默认值:0
+
+- --delete-wal
+
+ 从任何现有的备份中删除不需要的WAL文件。
+
+- --delete-expired
+
+ 删除不符合pg_probackup.conf配置文件中定义的留存策略的备份。
+
+- --merge-expired
+
+ 将满足留存策略要求的最旧的增量备份与其已过期的父备份合并。
+
+- --dry-run
+
+ 显示所有可用备份的当前状态,不删除或合并过期备份。
+
+#### 固定备份相关参数(pinning_options)
+
+>  **说明**: 如果要将某些备份从已建立的留存策略中排除,可以和backup和set-backup命令一起使用这些参数。
+
+- --ttl=*interval*
+
+ 指定从恢复时间开始计算,备份要固定的时间量。必须为正整数。0表示取消备份固定。
+
+ 支持的单位:ms、 s、 min、 h、 d(默认为s)。
+
+ 例如:-ttl=30d。
+
+- --expire-time=*time*
+
+ 指定备份固定失效的时间戳。必须是ISO-8601标准的时间戳。
+
+ 例如:--expire-time='2020-01-01 00:00:00+03'
+
+#### 日志相关参数(logging_options)
+
+日志级别:verbose、log、info、warning、error和off。
+
+- --log-level-console=*log-level-console*
+
+ 设置要发送到控制台的日志级别。每个级别都包含其后的所有级别。级别越高,发送的消息越少。指定off级别表示禁用控制台日志记录。
+
+ 默认值:info
+
+- --log-level-file=*log-level-file*
+
+ 设置要发送到日志文件的日志级别。每个级别都包含其后的所有级别。级别越高,发送的消息越少。指定off级别表示禁用日志文件记录。
+
+ 默认值:off
+
+- --log-filename=*log-filename*
+
+ 指定要创建的日志文件的文件名。文件名可以使用strftime模式,因此可以使用%-escapes指定随时间变化的文件名。
+
+ 例如,如果指定了“pg_probackup-%u.log”模式,则pg_probackup为每周的每一天生成单独的日志文件,其中%u替换为相应的十进制数字,即pg_probackup-1.log表示星期一;pg_probackup-2.log表示星期二,以此类推。
+
+ 如果指定了--log-level-file参数启用日志文件记录,则该参数有效。
+
+ 默认值:“pg_probackup.log”
+
+- --error-log-filename=*error-log-filename*
+
+ 指定仅用于error日志的日志文件名。指定方式与--log-filename参数相同。
+
+ 此参数用于故障排除和监视。
+
+- --log-directory=*log-directory*
+
+ 指定创建日志文件的目录。必须是绝对路径。此目录会在写入第一条日志时创建。
+
+ 默认值:$BACKUP_PATH/log
+
+- --log-rotation-size=*log-rotation-size*
+
+ 指定单个日志文件的最大大小。如果达到此值,则启动gs_probackup命令后,日志文件将循环,但help和version命令除外。0表示禁用基于文件大小的循环。
+
+ 支持的单位:KB、MB、GB、TB(默认为KB)。
+
+ 默认值:0
+
+- --log-rotation-age=*log-rotation-age*
+
+ 单个日志文件的最大生命周期。如果达到此值,则启动gs_probackup命令后,日志文件将循环,但help和version命令除外。$BACKUP_PATH/log/log_rotation目录下保存最后一次创建日志文件的时间。0表示禁用基于时间的循环。
+
+ 支持的单位:ms、 s、 min、 h、 d(默认为min)。
+
+ 默认值:0
+
+#### 连接相关参数(connection_options)
+
+>  **说明**: 可以和backup命令一起使用这些参数。
+
+- -d *dbname*, --pgdatabase=*dbname*
+
+ 指定要连接的数据库名称。该连接仅用于管理备份进程,因此您可以连接到任何现有的数据库。如果命令行、PGDATABASE环境变量或pg_probackup.conf配置文件中没有指定此参数,则gs_probackup会尝试从PGUSER环境变量中获取该值。如果未设置PGUSER变量,则从当前用户名获取。
+
+ 系统环境变量:$PGDATABASE
+
+- -h *hostname*, --pghost=*hostname*
+
+ 指定运行服务器的系统的主机名。如果该值以斜杠开头,则被用作到Unix域套接字的路径。
+
+ 系统环境变量:$PGHOST
+
+ 默认值:local socket
+
+- -p *port*, --pgport=_p_*ort*
+
+ 指定服务器正在侦听连接的TCP端口或本地Unix域套接字文件扩展名。
+
+ 系统环境变量:$PGPORT
+
+ 默认值:5432
+
+- -U *username*, --pguser=*username*
+
+ 指定所连接主机的用户名。
+
+ 系统环境变量:$PGUSER
+
+- -w, --no-password
+
+ 不出现输入密码提示。如果主机要求密码认证并且密码没有通过其它形式给出,则连接尝试将会失败。 该选项在批量工作和不存在用户输入密码的脚本中很有帮助。
+
+- -W *password*, --password=*password*
+
+ 指定用户连接的密码。如果主机的认证策略是trust,则不会对系统管理员进行密码验证,即无需输入-W选项;如果没有-W选项,并且不是系统管理员,则会提示用户输入密码。
+
+#### 压缩相关参数(compression_options)
+
+>  **说明**: 可以和backup命令一起使用这些参数。
+
+- --compress-algorithm=*compress-algorithm*
+
+ 指定用于压缩数据文件的算法。
+
+ 取值包括zlib、pglz和none。如果设置为zlib或pglz,此选项将启用压缩。默认情况下,压缩功能处于关闭状态。
+
+ 默认值:none
+
+- --compress-level=*compress-level*
+
+ 指定压缩级别。取值范围: 0~9
+
+ - 0表示无压缩。
+ - 1表示压缩比最小,处理速度最快。
+ - 9表示压缩比最大,处理速度最慢。
+ - 可与--compress-algorithm选项一起使用。
+
+ 默认值:1
+
+- --compress
+
+ 以--compress-algorithm=zlib和--compress-level=1进行压缩。
+
+#### 远程模式相关参数(remote_options)
+
+>  **说明**: 通过SSH远程运行gs_probackup操作的相关参数。可以和add-instance、set-config、backup、restore命令一起使用这些参数。
+
+- --remote-proto=*protocol*
+
+ 指定用于远程操作的协议。目前只支持SSH协议。取值包括:
+
+ ssh:通过SSH启用远程备份模式。这是默认值。
+
+ none:显式禁用远程模式。
+
+ 如果指定了-remote-host参数,可以省略此参数。
+
+- --remote-host=*destination*
+
+ 指定要连接的远程主机的IP地址或主机名。
+
+- --remote-port=*port*
+
+ 指定要连接的远程主机的端口号。
+
+ 默认值:22
+
+- --remote-user=*username*
+
+ 指定SSH连接的远程主机用户。如果省略此参数,则使用当前发起SSH连接的用户。
+
+ 默认值:当前用户
+
+- --remote-path=*path*
+
+ 指定gs_probackup在远程系统的安装目录。
+
+ 默认值:当前路径
+
+- --remote-libpath=*libpath*
+
+ 指定gs_probackup在远程系统安装的lib库目录。
+
+- --ssh-options=*ssh_options*
+
+ 指定SSH命令行参数的字符串。
+
+ 例如:--ssh-options='-c cipher_spec -F configfile'
+
+ >  **说明**:
+ >
+ > - 如果因为网络临时故障等原因导致server端无应答,gs_probackup将在等待archive-timeout(默认300秒)后退出。
+ >
+ > - 如果备机lsn与主机有差别时,数据库会不停地刷以下log信息,此时应重新build备机。
+ >
+ > ```bash
+ > LOG: walsender thread shut down
+ > LOG: walsender thread started
+ > LOG: received wal replication command: IDENTIFY_VERSION
+ > LOG: received wal replication command: IDENTIFY_MODE
+ > LOG: received wal replication command: IDENTIFY_SYSTEM
+ > LOG: received wal replication command: IDENTIFY_CONSISTENCE 0/D0002D8
+ > LOG: remote request lsn/crc: [xxxxx] local max lsn/crc: [xxxxx]
+ > ```
+
+### 备份流程
+
+1. 初始化备份目录。在指定的目录下创建backups/和wal/子目录,分别用于存放备份文件和WAL文件。
+
+ ```bash
+ gs_probackup init -B backup_dir
+ ```
+
+2. 添加一个新的备份实例。gs_probackup可以在同一个备份目录下存放多个数据库实例的备份。
+
+ ```bash
+ gs_probackup add-instance -B backup_dir -D data_dir --instance instance_name
+ ```
+
+3. 创建指定实例的备份。在进行增量备份之前,必须至少创建一次全量备份。
+
+ ```bash
+ gs_probackup backup -B backup_dir --instance instance_name -b backup_mode
+ ```
+
+4. 从指定实例的备份中恢复数据。
+
+ ```bash
+ gs_probackup restore -B backup_dir --instance instance_name -D pgdata-path -i backup_id
+ ```
+
+### 故障处理
+
+| 问题描述 | 原因和解决方案 |
+| :----------------------------------------------------------- | :----------------------------------------------------------- |
+| ERROR: query failed: ERROR: canceling statement due to conflict with recovery(错误:查询失败:由于与恢复操作冲突,正在取消语句命令) | 原因:在备机上执行的操作正在访问存储行,主机上更改或者删除了对应的行,并将xlog在备机上重放,迫使备机上操作取消。
解决方案:
1. 适当增加如下配置参数的值
max_standby_archive_delay
max_standby_streaming_delay
2. 增加如下配置
hot_standby_feedback = on |
+
+### 示例
+
+以下为全量备份和增量备份示例,备份目录为/opt/uqbar/backup_dir。
+
+1. 初始化备份目录。在指定的备份目录/opt/uqbar/backup_dir下创建backups/和wal/子目录,分别用于存放备份文件和WAL文件。
+
+ ```bash
+ [ommdoc@hostname]$ gs_probackup init -B /opt/uqbar/backup_dir
+ INFO: Backup catalog '/opt/uqbar/backup_dir' successfully inited
+ ```
+
+2. 添加一个新的备份实例instance1(用户需自定义实例名称)。gs_probackup可以在同一个备份目录下存放多个数据库实例的备份。
+
+ ```bash
+ [ommdoc@hostname]$ gs_probackup add-instance -B /opt/uqbar/backup_dir -D /opt/uqbar/data --instance instance1
+ INFO: Instance 'instance1' successfully inited
+ ```
+
+3. 创建指定实例的全量备份。
+
+ **注意**:如果提示数据库无法连接,请执行如下命令建立数据库连接后再执行全量备份。例如执行如下命令连接到postgres数据库,且端口号为28000。
+
+ ```bash
+ [ommdoc@hostname]$ gs_probackup set-config --instance=instance1 -B /opt/uqbar/backup_dir -d postgres -p 28000
+ ```
+
+ ```bash
+ [ommdoc@hostname]$ gs_probackup backup -B /opt/uqbar/backup_dir --instance instance1 -b FULL
+ INFO: Backup start, gs_probackup version: 2.4.2, instance: instance1, backup ID: RGOZF6, backup mode: FULL, wal mode: STREAM, remote: false, compress-algorithm: none, compress-level: 1
+ LOG: Backup destination is initialized
+ LOG: This openGauss instance was initialized with data block checksums. Data block corruption will be detected
+ LOG: Database backup start
+ LOG: started streaming WAL at 0/CA000000 (timeline 1)
+ INFO: Cannot parse path "base"
+ [2022-08-16 13:04:18]: check identify system success
+ [2022-08-16 13:04:18]: send START_REPLICATION 0/CA000000 success
+ [2022-08-16 13:04:18]: keepalive message is received
+ [2022-08-16 13:04:18]: keepalive message is received
+ INFO: PGDATA size: 1320MB
+ INFO: Start transferring data files
+ LOG: Creating page header map "/opt/uqbar/backup_dir/backups/instance1/RGOZF6/page_header_map"
+ INFO: Data files are transferred, time elapsed: 2s
+ INFO: wait for pg_stop_backup()
+ INFO: pg_stop backup() successfully executed
+ LOG: stop_lsn: 0/CA0001E8
+ LOG: Looking for LSN 0/CA0001E8 in segment: 0000000100000000000000CA
+ LOG: Found WAL segment: /opt/uqbar/backup_dir/backups/instance1/RGOZF6/database/pg_xlog/0000000100000000000000CA
+ LOG: Thread [0]: Opening WAL segment "/opt/uqbar/backup_dir/backups/instance1/RGOZF6/database/pg_xlog/0000000100000000000000CA"
+ LOG: Found LSN: 0/CA0001E8
+ LOG: finished streaming WAL at 0/CB000000 (timeline 1)
+ LOG: Getting the Recovery Time from WAL
+ LOG: Thread [0]: Opening WAL segment "/opt/uqbar/backup_dir/backups/instance1/RGOZF6/database/pg_xlog/0000000100000000000000CA"
+ INFO: Syncing backup files to disk
+ INFO: Backup files are synced, time elapsed: 1s
+ INFO: Validating backup RGOZF6
+ INFO: Backup RGOZF6 data files are valid
+ INFO: Backup RGOZF6 resident size: 1337MB
+ INFO: Backup RGOZF6 completed
+ ```
+
+4. 登录数据库,创建表warehouse_t1。
+
+ ```sql
+ [ommdoc@hostname]$ gsql -d postgres -p 28000
+ gsql ((Uqbar 1.1.0 build 62408a0f) compiled at 2022-06-30 15:06:56 commit 0 last mr )
+ Non-SSL connection (SSL connection is recommended when requiring high-security)
+ Type "help" for help.
+
+ Uqbar=# CREATE TABLE warehouse_t1
+ (
+ W_WAREHOUSE_SK INTEGER NOT NULL,
+ W_WAREHOUSE_ID CHAR(16) NOT NULL,
+ W_WAREHOUSE_NAME VARCHAR(20) ,
+ W_WAREHOUSE_SQ_FT INTEGER Uqbar-# ,
+ W_STREET_NUMBER CHAR(10) ,
+ W_STREET_NAME VARCHAR(60) ,
+ W_STREET_TYPE CHAR(15) ,
+ W_Uqbar(# SUITE_NUMBER CHAR(10) ,
+ W_CITY VARCHAR(60) ,
+ W_COUNTY VARCHAR(30) ,
+ W_STATE CHAR(2) Uqbar(# ,
+ W_ZIP CHAR(10) ,
+ W_COUNTRY VARCHAR(20) Uqbar(# ,
+ W_GMT_OFFSET DECIMAL(5,2)
+ );
+ CREATE TABLE
+ Uqbar=#
+ ```
+
+5. 创建指定实例的增量备份。
+
+ **注意**:创建增量备份前,需在postgresql.conf中手动添加参数“enable_cbm_tracking = on”,并重启数据库确保参数生效。
+
+ ```bash
+ [ommdoc@hostname]$ gs_probackup backup -B /opt/uqbar/backup_dir --instance instance1 -b PTRACK
+ INFO: Backup start, gs_probackup version: 2.4.2, instance: instance1, backup ID: RGOZKI, backup mode: PTRACK, wal mode: STREAM, remote: false, compress-algorithm: none, compress-level: 1
+ LOG: Backup destination is initialized
+ LOG: This openGauss instance was initialized with data block checksums. Data block corruption will be detected
+ LOG: Database backup start
+ LOG: Latest valid FULL backup: RGOZF6
+ INFO: Parent backup: RGOZF6
+ LOG: started streaming WAL at 0/CC000000 (timeline 1)
+ INFO: Cannot parse path "base"
+ [2022-08-16 13:07:30]: check identify system success
+ [2022-08-16 13:07:30]: send START_REPLICATION 0/CC000000 success
+ [2022-08-16 13:07:30]: keepalive message is received
+ [2022-08-16 13:07:30]: keepalive message is received
+ INFO: PGDATA size: 1320MB
+ LOG: Current tli: 1
+ LOG: Parent start_lsn: 0/CA000028
+ LOG: start_lsn: 0/CC000028
+ INFO: Extracting pagemap of changed blocks
+ INFO: change bitmap start lsn location is 0/CA000028
+ INFO: change bitmap end lsn location is 00000000/CC000028
+ INFO: Pagemap successfully extracted, time elapsed: 0 sec
+ INFO: Start transferring data files
+ LOG: Creating page header map "/opt/uqbar/backup_dir/backups/instance1/RGOZKI/page_header_map"
+ INFO: Data files are transferred, time elapsed: 0
+ INFO: wait for pg_stop_backup()
+ INFO: pg_stop backup() successfully executed
+ LOG: stop_lsn: 0/CC0001E8
+ LOG: Looking for LSN 0/CC0001E8 in segment: 0000000100000000000000CC
+ LOG: Found WAL segment: /opt/uqbar/backup_dir/backups/instance1/RGOZKI/database/pg_xlog/0000000100000000000000CC
+ LOG: Thread [0]: Opening WAL segment "/opt/uqbar/backup_dir/backups/instance1/RGOZKI/database/pg_xlog/0000000100000000000000CC"
+ LOG: Found LSN: 0/CC0001E8
+ LOG: finished streaming WAL at 0/CD000000 (timeline 1)
+ LOG: Getting the Recovery Time from WAL
+ LOG: Thread [0]: Opening WAL segment "/opt/uqbar/backup_dir/backups/instance1/RGOZKI/database/pg_xlog/0000000100000000000000CC"
+ INFO: Syncing backup files to disk
+ INFO: Backup files are synced, time elapsed: 0
+ INFO: Validating backup RGOZKI
+ INFO: Backup RGOZKI data files are valid
+ INFO: Backup RGOZKI resident size: 273MB
+ INFO: Backup RGOZKI completed
+ ```
+
+6. 删除数据库目录。
+
+ ```bash
+ [ommdoc@hostname]$ gs_ctl stop -D /opt/uqbar/data
+ [2022-08-16 13:27:04.642][766772][][gs_ctl]: gs_ctl stopped ,datadir is /opt/uqbar/data
+ waiting for server to shut down.............. done
+ server stopped
+ [ommdoc@hostname]$ rm -rf /opt/uqbar/data
+ ```
+
+7. 恢复数据库。
+
+ ```bash
+ [ommdoc@uqbar-kernel-0003 data]$ gs_probackup restore -B /opt/uqbar/backup_dir --instance instance1 -D /opt/uqbar/data -i RGOZF6
+ LOG: Restore begin.
+ LOG: there is no file tablespace_map
+ LOG: check tablespace directories of backup RGOZF6
+ LOG: check external directories of backup RGOZF6
+ WARNING: Process 719280 which used backup RGOZF6 no longer exists
+ INFO: Validating backup RGOZF6
+ INFO: Backup RGOZF6 data files are valid
+ LOG: Thread [1]: Opening WAL segment "/opt/uqbar/backup_dir/backups/instance1/RGOZF6/database/pg_xlog/0000000100000000000000CA"
+ INFO: Backup RGOZF6 WAL segments are valid
+ INFO: Backup RGOZF6 is valid.
+ INFO: Restoring the database from backup at 2022-08-16 13:04:18+08
+ LOG: there is no file tablespace_map
+ LOG: Restore directories and symlinks...
+ INFO: Start restoring backup files. PGDATA size: 1336MB
+ LOG: Start thread 1
+ INFO: Backup files are restored. Transfered bytes: 1336MB, time elapsed: 0
+ INFO: Restore incremental ratio (less is better): 100% (1336MB/1336MB)
+ INFO: Syncing restored files to disk
+ INFO: Restored backup files are synced, time elapsed: 8s
+ INFO: Restore of backup RGOZF6 completed.
+ [ommdoc@hostname]$ gs_om -t restart
+ Stopping cluster.
+ =========================================
+ Successfully stopped cluster.
+ =========================================
+ End stop cluster.
+ Starting cluster.
+ =========================================
+ [SUCCESS] uqbar-kernel-0003
+ 2022-08-16 13:34:10.277 [unknown] [unknown] localhost 70371578937360 0[0:0#0] 0 [BACKEND] WARNING: could not create any HA TCP/IP sockets
+ 2022-08-16 13:34:10.277 [unknown] [unknown] localhost 70371578937360 0[0:0#0] 0 [BACKEND] WARNING: could not create any HA TCP/IP sockets
+ 2022-08-16 13:34:10.282 [unknown] [unknown] localhost 70371578937360 0[0:0#0] 0 [BACKEND] WARNING: No explicit IP is configured for listen_addresses GUC.
+ =========================================
+ Successfully started.
+ ```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/cluster-management.md b/product/zh/docs-uqbar/v2.0/cluster-management.md
new file mode 100644
index 0000000000000000000000000000000000000000..c75858d80282ebb42321ff21a37605204ee98603
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/cluster-management.md
@@ -0,0 +1,130 @@
+---
+title: 集群管理
+summary: 集群管理
+author: Guo Huan
+date: 2022-11-24
+---
+
+# 集群管理
+
+Uqbar提供集群管理能力,支持主备高可用,当部分节点故障时,系统能够自动监测并切换到正常节点,保证系统可用性SLA达到99.95%。
+
+## 操作场景
+
+Uqbar在运行过程中,数据库管理员可能需要手工对数据库节点做主备切换。例如发现数据库节点主备failover后需要恢复原有的主备角色,或怀疑硬件故障需要手动进行主备切换。级联备机不能直接转换为主机,只能先通过switchover或者failover成为备机,然后再切换为主机。
+
+>  **说明:**
+>
+> - 主备切换为维护操作,确保Uqbar状态正常,所有业务结束后,再进行切换操作。
+> - 在开启极致RTO时,不支持级联备机。级联备机因为极致RTO开启情况下,备机不支持连接无法同步数据。
+
+
+
+## 操作步骤
+
+1. 以操作系统用户omm登录数据库任意节点,执行如下命令,查看主备情况。
+
+ ```bash
+ gs_om -t status --detail
+ ```
+
+2. 以操作系统用户omm登录准备切换为主节点的备节点,执行如下命令。
+
+ ```bash
+ gs_ctl switchover -D /home/omm/cluster/dn1/
+ ```
+
+ /home/omm/cluster/dn1/为备数据库节点的数据目录。
+
+ >  **须知:** 对于同一数据库,上一次主备切换未完成,不能执行下一次切换。对于业务正在操作时,发起switchover,可能主机的线程无法停止导致switchover显示超时,实际后台仍然在运行,等主机线程停止后,switchover即可完成。比如在主机删除一个大的分区表时,可能无法响应switchover发起的信号。
+
+3. switchover成功后,执行如下命令记录当前主备机器信息。
+
+ ```bash
+ gs_om -t refreshconf
+ ```
+
+
+
+## 示例
+
+将数据库节点备实例切换为主实例。
+
+1. 查询数据库状态。
+
+ ```bash
+ gs_om -t status --detail
+ [ Cluster State ]
+
+ cluster_state : Normal
+ redistributing : No
+ current_az : AZ_ALL
+
+ [ Datanode State ]
+
+ node node_ip port instance state
+ --------------------------------------------------------------------------------------------------
+ 1 pekpopgsci00235 10.244.62.204 5432 6001 /home/omm/cluster/dn1/ P Primary Normal
+ 2 pekpopgsci00238 10.244.61.81 5432 6002 /home/omm/cluster/dn1/ S Standby Normal
+ ```
+
+2. 登录备节点,进行主备切换。另外,switchover级联备机后,级联备机切换为备机,原备机将为级联备。
+
+ ```bash
+ gs_ctl switchover -D /home/omm/cluster/dn1/
+ [2020-06-17 14:28:01.730][24438][][gs_ctl]: gs_ctl switchover ,datadir is -D "/home/omm/cluster/dn1"
+ [2020-06-17 14:28:01.730][24438][][gs_ctl]: switchover term (1)
+ [2020-06-17 14:28:01.768][24438][][gs_ctl]: waiting for server to switchover............
+ [2020-06-17 14:28:11.175][24438][][gs_ctl]: done
+ [2020-06-17 14:28:11.175][24438][][gs_ctl]: switchover completed (/home/omm/cluster/dn1)
+ ```
+
+3. 保存数据库主备机器信息。
+
+ ```bash
+ gs_om -t refreshconf
+ Generating dynamic configuration file for all nodes.
+ Successfully generated dynamic configuration file.
+ ```
+
+
+
+## 异常处理
+
+异常判断标准如下:
+
+- 业务压力下,主备实例切换时间长,这种情况不需要处理。
+
+- 其他备机正在build的情况下,主机需要发送日志到备机后,才能降备,导致主备切换时间长。这种情况不需要处理,但应尽量避免build过程中进行主备切换。
+
+- 切换过程中,因网络故障、磁盘满等原因造成主备实例连接断开,出现双主现象时,此时请参考如下步骤修复。
+
+ >  **警告:** 出现双主状态后,请按如下步骤恢复成正常的主备状态。否则可能会造成数据丢失。
+
+1. 执行以下命令查询数据库当前的实例状态。
+
+ ```bash
+ gs_om -t status --detail
+ ```
+
+ 若查询结果显示两个实例的状态都为Primary,这种状态为异常状态。
+
+2. 确定降为备机的节点,在节点上执行如下命令关闭服务。
+
+ ```bash
+ gs_ctl stop -D /home/omm/cluster/dn1/
+ ```
+
+3. 执行以下命令,以standby模式启动备节点。
+
+ ```bash
+ gs_ctl start -D /home/omm/cluster/dn1/ -M standby
+ ```
+
+4. 保存数据库主备机器信息。
+
+ ```bash
+ gs_om -t refreshconf
+ ```
+
+5. 查看数据库状态,确认实例状态恢复。
diff --git a/product/zh/docs-uqbar/v2.0/continuous-aggregation.md b/product/zh/docs-uqbar/v2.0/continuous-aggregation.md
new file mode 100644
index 0000000000000000000000000000000000000000..4e36a56fc810ec0b4e05c2057725878527b6f97f
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/continuous-aggregation.md
@@ -0,0 +1,16 @@
+---
+title: 持续聚合
+summary: 持续聚合
+author: Guo Huan
+date: 2022-11x
+---
+
+# 持续聚合
+
+持续聚合(Continuous Aggregation)用于预先计算和聚合数据。持续聚合功能通过定义和调度周期性运行的查询,在数据库上生成聚合结果,并将其存储在一个时序表中。
+
+持续聚合的主要作用包括:
+
+- 实时聚合:通过后台计算聚合结果,使得查询可以立即获取到预先计算好的聚合数据,从而无需每次查询进行全量计算,大大提高了查询性能,并减少查询响应时间。
+- 数据降采样:持续聚合可以将高分辨率的时间序列数据降采样为较低分辨率的聚合数据。通过定义适当的时间间隔和聚合函数,可以将数据的频率降低,减少存储成本,提升查询效率。
+- 数据摘要:通过选取合适的聚合函数,如SUM、AVG、MIN、MAX等,可以生成数据的摘要信息。这些预先计算的摘要信息对于生成报告,或快速检索聚合数据非常有用,并且无需执行复杂的计算。
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-compression.md b/product/zh/docs-uqbar/v2.0/data-compression.md
new file mode 100644
index 0000000000000000000000000000000000000000..0146148a157fbaab0a482bb9b63e144e1fd1a9df
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-compression.md
@@ -0,0 +1,102 @@
+---
+title: 数据压缩
+summary: 数据压缩
+author: Zhang Cuiping
+date: 2022-11-22
+---
+
+# 数据压缩
+
+Uqbar时序数据库支持自动和手动压缩数据,以减少数据存储成本并提升查找效率。
+
+## 自动压缩
+
+后台按照设定的压缩延迟时间,自动对时序数据执行压缩,以节省存储空间。压缩的时间延迟可以通过 guc 参数 uqbar.timeseries_compression_delay 设置。
+
+### 语法格式
+
+自动压缩会根据设定的延迟自动触发,无需用户执行。
+
+### 注意事项
+
+- 压缩以 chunkgroup 为粒度进行,即一个 chunkgroup 内的所有 chunk 一起执行压缩操作。
+- 达到设置的压缩间隔后,数据压缩还需要满足以下条件:
+ - chunkgroup 的结束时间早于当前系统时间
+ - chunkgroup 内超过 uqbar.timeseries_compression_delay 的间隔没有数据写入
+ - 当前版本压缩成功后, chunkgroup 不支持再写入数据
+
+### 示例
+
+假设前置条件:chunkGroupDuration = 1 week,假设当前时间为2022-7-7 09:55:00
+
+1. 设置自动压缩延迟为 1 min,即 uqbar.timeseries_compression_delay = 60;
+
+2. 写入数据,保证分片内的所有数据都小于当前时间;
+
+ ```sql
+ INSERT INTO weather SELECT '2022-07-01 00:00:00'::timestamp, 'beijing', 'park', generate_series(1, 2000);
+ ```
+
+3. 查看chunk属性,找到建立的分片;
+
+ ```sql
+ SELECT * FROM timeseries_catalog.tschunk;
+ ```
+
+4. 两分钟以后再次查看chunk属性,确认其是否已经被压缩。
+
+## 手动压缩
+
+支持用户手动触发压缩,用户可以通过执行压缩命令,对时序表或时序表内的某个chunkgroup进行压缩。
+
+### 语法格式
+
+```sql
+COMPRESS TIMESERIES table_name [ PARTITION chunkgroupname ]
+```
+
+### 注意事项
+
+- 当前版本不支持对压缩后的chunkgroup再写入数据
+- 不指定 Partition 参数表示对时序表所有的 chunkgroup 执行压缩;指定 Partition 会对指定的 chunkgroup 执行压缩
+
+### 示例
+
+```sql
+Uqbar=# COMPRESS TIMESERIES weather PARTITION chunkgroup_1;
+COMPRESSED
+Uqbar=# COMPRESS TIMESERIES weather;
+COMPRESSED
+```
+
+## 压缩率视图
+
+系统内置 timeseries_views.compression_table 和 timeseries_views.compression_chunkgroup 两个视图,可以按照表和chunkgroup维度展示压缩前后的数据量、压缩率等数据。关于这两个视图的详细信息,参考[timeseries_views.compression_table](./timeseries-views/timeseries_views.compression_table.md)、[timeseries_views.compression_chunkgroup](./timeseries-views/timeseries_views.compression_chunkgroup.md)。
+
+### 语法格式
+
+```sql
+SELECT * FROM timeseries_views.compression_table;
+SELECT * FROM timeseries_views.compression_chunkgroup;
+```
+
+### 示例
+
+```sql
+--查看时序表weather的压缩率
+Uqbar=# SELECT tablename, before_compression_size, after_compression_size, compression_rate FROM timeseries_views.compression_table WHERE tablename = 'weather';
+ tablename | before_compression_size | after_compression_size | compression_ratio
+------------------------+-------------------------+--------------------+------------
+ weather | 1746534 | 1483457 | 1.17
+
+(1 rows)
+
+--查看时序表weather的分片压缩率
+Uqbar=# SELECT tablename, chunkgroupname, before_compression_size, after_compression_size, compression_ratio FROM timeseries_views.compression_chunkgroup WHERE tablename = 'weather';
+ tablename | chunkgroupname | before_compression_size | after_compression_size | compression_ratio
+--------------------+--------------------+---------------- --------+---------------------+------------
+ weather | p_1_1 | 387564 | 328576 | 1.17
+ weather | p_1_2 | 417829 | 358273 | 1.16
+
+(2 rows)
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-write-introduction.md b/product/zh/docs-uqbar/v2.0/data-write/data-write-introduction.md
new file mode 100644
index 0000000000000000000000000000000000000000..fce426d9902054935e5e5560246a07bff3e5b716
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-write-introduction.md
@@ -0,0 +1,15 @@
+---
+title: 时序数据写入
+summary: 时序数据写入
+author: zhang cuiping
+date: 2022-11-12
+---
+
+# 时序数据写入
+
+本节主要介绍时序表接入方式、时序表写入模型以及时序数据写入性能指标。
+
+Uqbar支持标准SQL写入时序表、支持通过驱动写入时序数据,也可从Kafka消费数据。Uqbar时序数据写入模型包括单值模型和多值模型、允许乱序写入和无时间值写入等三种。
+
++ **[时序数据接入方式](./data-writing-method/data-writing-method.md)**
++ **[时序数据写入模型](./data-writing-model/data-writing-model.md)**
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/Kafka-supported-for-importing-data-to-table.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/Kafka-supported-for-importing-data-to-table.md
new file mode 100644
index 0000000000000000000000000000000000000000..9505f4f27769359dd53e2d95a63111291a649b01
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/Kafka-supported-for-importing-data-to-table.md
@@ -0,0 +1,237 @@
+---
+title: 支持从Kafka写入时序表
+summary: 支持从Kafka写入时序表
+author: Zhang Cuiping
+date: 2022-11-12
+---
+
+# 支持从Kafka写入时序表
+
+传感器或监控数据支持从Kafka写入时序表。Kafka和Uqbar可通过Kafka JDBC Connector进行连接。该连接器负责从Kafka读取数据,然后将消息中的SQL发送到Uqbar执行并记录失败消费结果,维护消息消费位置。向数据库插入数据需要使用批量插入模式。
+
+
+
+## 安装流程
+
+### 下载Kafka
+
+访问 [Kafka官网](https://kafka.apache.org/downloads) 下载Kafka软件包,下载完成后解压。
+
+
+
+### 下载数据库驱动
+
+下载对应数据库的JDBC驱动,以openGauss为例。访问[openGauss官网](https://www.opengauss.org/zh/download/)下载对应操作系统的JDBC驱动。
+
+
+
+下载完成后解压,得到相应的JAR包。
+
+
+
+复制JAR包到kafka路径下,例如/kafka_2.12-3.2.1/libs。
+
+### 下载Kafka JDBC Connector
+
+可通过访问[https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc?_ga=2.140576818.1269349503.1660542741-1354758524.1659497119](https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc?_ga=2.140576818.1269349503.1660542741-1354758524.1659497119),点击“Download”下载Kafka JDBC Connector。
+
+
+
+下载完成后解压到任意目录供后续使用。
+
+### 修改配置文件
+
+#### server.properties
+
+编辑kafka目录下的 `config/server.properties` 文件。
+
+```
+listeners=PLAINTEXT://0.0.0.0:9092
+advertised.listeners=PLAINTEXT://your.host.name:9092
+```
+
+修改或添加 `listeners=PLAINTEXT://0.0.0.0:9092` ,否则将无法监听外网请求。
+
+修改或添加 `advertised.listeners=PLAINTEXT://your.host.name:9092` ,*your.host.name*为本机的IP地址,否则外部网络将无法访问您的kafka。
+
+#### connect-distributed.properties
+
+编辑kafka目录下的 `config/connect-distributed.properties` 文件。
+
+```
+plugin.path=/usr/local/Cellar/confluentinc-kafka-connect-jdbc-10.5.2
+```
+
+`plugin.path`存放confluentinc-kafka-connect-jdbc文件夹的位置。如`plugin.path=/usr/local/Cellar/confluentinc-kafka-connect-jdbc-10.5.2`。
+
+## 启动Kafka
+
+1. 打开cmd/terminal并进入kafka目录,例如/kafka_2.12-3.2.1。
+
+ ```
+ cd /usr/local/Cellar/kafka_2.12-3.2.1
+ ```
+
+2. 启动zookeeper。
+
+ ```
+ sh bin/zookeeper-server-start.sh config/zookeeper.properties
+ ```
+
+3. 启动Kafka。
+
+ ```
+ sh bin/kafka-server-start.sh config/server.properties
+ ```
+
+4. 输入jps查看zookeeper和kafka启动情况。
+
+ ```
+ 81243 QuorumPeerMain #Zookeeper
+ 30701 Launcher
+ 81598 Kafka # Kafka
+ ```
+
+5. 启动Kafka Connect Worker。
+
+ ```bash
+ sh bin/connect-distributed.sh config/connect-distributed.properties
+ ```
+
+ 如果显示如下回显信息,表示启动成功。
+
+ 
+
+ 通过jps可以查看到ConnectDistributed进程运行。
+
+ ```bash
+ 83931 ConnectDistributed
+ ```
+
+6. 启动JDBC Connector。
+
+ - 方式一:启动JDBC Connector
+
+ 通过终端或cmd 启动JDBC Connector。
+
+ ```
+ curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
+ "name":"connector-name",
+ "config":{
+ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
+ "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB",
+ "connection.user":"user",
+ "connection.password":"password",
+ "topics":"test_topic",
+ "insert.mode": "insert",
+ "table.name.format":"table_name_${topic}",
+ "auto.create":true,
+ "dialect.name": "PostgreSqlDatabaseDialect"
+ }
+ }'
+ ```
+
+ - 方式二:创建json文件配置 JDBC Connector。
+
+ 创建名为`test.json`的json文件,内容如下:
+
+ ```
+ {
+ "name":"connector-name",
+ "config":{
+ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
+ "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB",
+ "connection.user":"user",
+ "connection.password":"password",
+ "topics":"test_topic",
+ "insert.mode": "insert",
+ "table.name.format":"table_name_${topic}",
+ "auto.create":true,
+ "dialect.name": "PostgreSqlDatabaseDialect"
+ }
+ }
+ ```
+
+ 在终端或cmd启动Kafka。
+
+ ```
+ curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d @test.json
+ ```
+
+ - 方式三:使用Postman等接口测试工具
+
+ 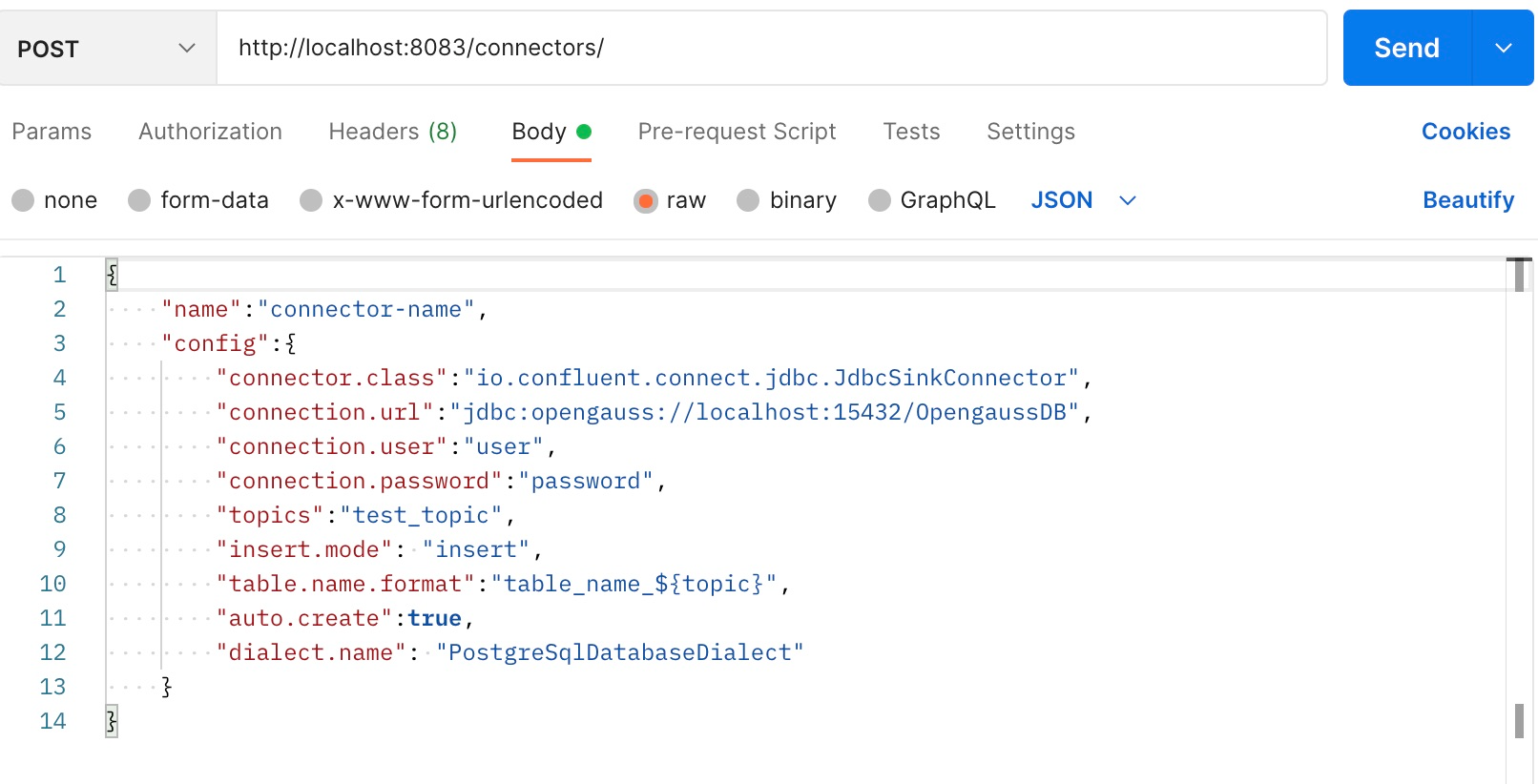
+
+ 设置好参数后发送post请求。
+
+ 显示类似如下的消息表示Connector启动成功。
+
+ ```
+ {
+ "name": "connector-name",
+ "config": {
+ "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
+ "connection.url": "jdbc:opengauss://localhost:15432/sink",
+ "connection.user": "user1",
+ "connection.password": "Enmo@123",
+ "topics": "test",
+ "insert.mode": "insert",
+ "table.name.format": "tableName_${topic}",
+ "auto.create": "true",
+ "dialect.name": "PostgreSqlDatabaseDialect",
+ "name": "connector-name"
+ },
+ "tasks": [],
+ "type": "sink"
+ }
+ ```
+
+## 数据写入示例
+
+一个JDBC Connector,至少需要包含如下参数:
+
+```
+"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
+"connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB",
+"connection.user":"user",
+"connection.password":"password",
+"topics":"test",
+"table.name.format":"tableName"
+```
+
+假设要写入数据库的数据表结构以及配置如下:
+
+```
+CREATE TABLE "test" (
+ "id" INT NOT NULL,
+ "longitude" REAL NULL,
+ "latitude" REAL NULL,
+ "temperature" REAL NULL,
+ "humidity" REAL NULL,
+ "time" TIME NULL,
+ "string_time" TEXT NULL,
+ "randomString" TEXT NULL
+);
+```
+
+```
+curl -X POST http://localhost:8083/connectors -H "Content-Type:application/json" -d '{
+ "name":"connector-name",
+ "config":{
+ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
+ "connection.url":"jdbc:opengauss://localhost:15432/sink",
+ "connection.user":"user1",
+ "connection.password":"password",
+ "topics":"topic",
+ "table.name.format":"test"
+ }
+}'
+```
+
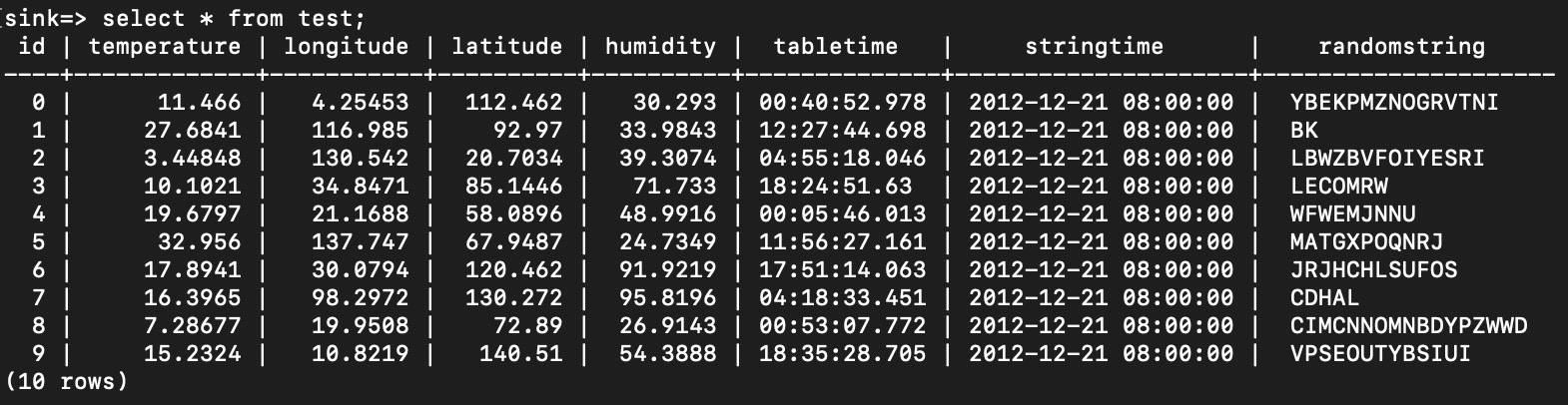
+在source端发送数据,启动JDBC Connector。如果终端或cmd显示如下信息,表示Kafka启动成功。
+
+
+
+在数据库中查询,可以发现数据已保存到表中。
+
+
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/SQL-supported-for-importing-data-to-table.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/SQL-supported-for-importing-data-to-table.md
new file mode 100644
index 0000000000000000000000000000000000000000..6729ab63cf0b592ad0695bd146a89692069a5e8f
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/SQL-supported-for-importing-data-to-table.md
@@ -0,0 +1,44 @@
+---
+title: 支持标准SQL写入时序表
+summary: 支持标准SQL写入时序表
+author: Zhang Cuiping
+date: 2022-11-12
+---
+
+# 支持标准SQL写入时序表
+
+传感器或监控数据支持使用标准SQL写入时序表。一次可插入单条或多条数据。写入数据前请先创建时序表,或确保系统已存在时序表。
+
+## 注意事项
+
+- 支持不带时间值插入。
+- 支持乱序插入(本版本支持未压缩chunk的乱序写入)。
+- tstime列不能写入NULL值。
+- tstag不能写入NULL值。
+
+## 语法格式
+
+- 插入单条数据
+
+ ```sql
+ INSERT INTO table_name[(targelist)] VALUES(value_list);
+ ```
+
+- 插入多条数据
+
+ ```sql
+ INSERT INTO table_name[(targelist)] VALUES(value_list)[, (value_list)]...;
+ ```
+
+## 示例
+
+```sql
+MogDB=# INSERT INTO weather(time, city, location, temperature) VALUES('2022-07-06 00:00:00','beijing', 'gongyuan', 29.1);
+INSERT 0 1
+MogDB=# INSERT INTO weather(time, city, location, temperature) VALUES('2022-07-06 00:00:00','beijing', 'chaoyang', 29.1), ('2022-7-6 00:00:00','shanghao', 'gongyuan', 29.2);
+INSERT 0 2
+```
+
+## 相关页面
+
+[INSERT](../../uqbar-sql-syntax/INSERT.md)、[COPY](../../uqbar-sql-syntax/COPY.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/data-writing-method.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/data-writing-method.md
new file mode 100644
index 0000000000000000000000000000000000000000..98b78347db6166dab67adf7f0b0010350ca05568
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/data-writing-method.md
@@ -0,0 +1,12 @@
+---
+title: 时序数据接入方式
+summary: 时序数据接入方式
+author: Guo Huan
+date: 2023-06-08
+---
+
+# 时序数据接入方式
+
++ **[支持标准SQL写入时序表](./SQL-supported-for-importing-data-to-table.md)**
++ **[通过驱动写入时序数据](./driver-supported-for-importing-data-to-table.md)**
++ **[从Kafka消费数据](./Kafka-supported-for-importing-data-to-table.md)**
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/driver-supported-for-importing-data-to-table.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/driver-supported-for-importing-data-to-table.md
new file mode 100644
index 0000000000000000000000000000000000000000..c51aaa9a35fda35b64d4263864efdb0d472e3762
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-method/driver-supported-for-importing-data-to-table.md
@@ -0,0 +1,73 @@
+---
+title: 支持驱动写入时序表
+summary: 支持驱动写入时序表
+author: Zhang Cuiping
+date: 2022-11-12
+---
+
+# 支持驱动写入时序表
+
+传感器或监控数据支持使用Libpq、JDBC、ODBC、GO以及Python驱动使用COPY语法写入时序表。一次可插入单条或多条数据。写入数据前请先创建时序表,或确保系统已存在时序表。
+
+## 注意事项
+
+- 支持Libpq、JDBC和GO的prepare和COPY语义,向时序表插入数据。
+- 支持ODBC的prepare语义,向时序表插入数据。
+
+## 语法格式
+
+- Libpq 驱动
+
+ ```
+ PQprepare
+ PQexecPrepared
+ PQputCopyData
+ ```
+
+- JDBC 驱动
+
+ ```sql
+ java.sql.PreparedStatement
+ CopyManager
+ ```
+
+- ODBC 驱动
+
+ ```
+ SQLPrepare
+ SQLExecute
+ --不支持COPY
+ ```
+
+- GO 驱动
+
+ ```
+ Prepare()
+ Exec()
+ ```
+
+## 示例
+
+- JDBC prepare接口:[https://docs.mogdb.io/zh/mogdb/v3.0/5-java-sql-PreparedStatement](https://docs.mogdb.io/zh/mogdb/v3.0/5-java-sql-PreparedStatement)
+
+ JDBC prepare示例:[https://docs.mogdb.io/zh/mogdb/v3.0/7-running-sql-statements](https://docs.mogdb.io/zh/mogdb/v3.0/7-running-sql-statements)
+
+- JDBC COPY接口:[https://docs.mogdb.io/zh/mogdb/v3.0/14-CopyManager](https://docs.mogdb.io/zh/mogdb/v3.0/14-CopyManager)
+
+ JDBC COPY示例(非官方):[https://blog.csdn.net/ifenggege/article/details/108905808](https://blog.csdn.net/ifenggege/article/details/108905808)
+
+- Libpq prepare接口:[https://docs.mogdb.io/zh/mogdb/v3.0/11-PQprepare](https://docs.mogdb.io/zh/mogdb/v3.0/11-PQprepare)
+
+ Libpq prepare示例(非官方):[https://www.cnblogs.com/gaojian/p/3140491.html](https://www.cnblogs.com/gaojian/p/3140491.html)
+
+- Libpq COPY接口(非官方):[http://www.postgres.cn/docs/10/libpq-copy.html](http://www.postgres.cn/docs/10/libpq-copy.html)
+
+ Libpq COPY示例(非官方):[https://blog.csdn.net/liufeng1980423/article/details/108254469](https://blog.csdn.net/liufeng1980423/article/details/108254469)
+
+- GO prepare示例(非官方):[https://vimsky.com/examples/usage/golang_database_sql_DB_Prepare.html](https://vimsky.com/examples/usage/golang_database_sql_DB_Prepare.html)
+
+- GO COPY示例(非官方):[https://pkg.go.dev/github.com/lib/pq#section-readme](https://pkg.go.dev/github.com/lib/pq#section-readme)
+
+## 相关页面
+
+[COPY](../../uqbar-sql-syntax/COPY.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-imported-out-of-order.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-imported-out-of-order.md
new file mode 100644
index 0000000000000000000000000000000000000000..16152f719c8d6fa47a3d9d8dd6b5c747dffa379e
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-imported-out-of-order.md
@@ -0,0 +1,29 @@
+---
+title: 乱序写入
+summary: 乱序写入
+author: Zhang Cuiping
+date: 2021-11-23
+---
+
+# 乱序写入
+
+Uqbar支持数据乱序写入。通常情况下上报到Uqbar的数据是按照时间顺序有序排列的,也就是后写入的数据time列的值大于先写入的数据。但是由于各种原因,例如网络或者消息队列的问题,可能导致后写入的数据time列的值小于先写入的数据,这种现象称为乱序。时序数据库中的乱序,通常是针对同一个采集器而言,即相同标签集的数据。
+
+**说明**:Uqbar支持未压缩数据的乱序写入,暂不支持压缩后数据的乱序写入。
+
+## 语法格式
+
+```
+INSERT INTO table VALUES [, ...];
+```
+
+## 示例
+
+```sql
+Uqbar=# CREATE TIMESERIES TABLE weather(time timestamp TSTIME, city text TSTAG, location text TSTAG, temperature float) POLICY default_policy;
+CREATE TIMESERIES TABLE
+Uqbar=# INSERT INTO weather VALUES('2022-06-18 00:00:00', 'beijing', 'park', 36);
+INSERT 0 1
+Uqbar=# INSERT INTO weather VALUES('2022-06-17 12:00:00', 'beijing', 'park', 30);
+INSERT 0 1
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-imported-without-the-time-field.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-imported-without-the-time-field.md
new file mode 100644
index 0000000000000000000000000000000000000000..1cab06f57b35a2f6c93848ed0dd81dae68a8e60b
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-imported-without-the-time-field.md
@@ -0,0 +1,25 @@
+---
+title: 无时间值写入
+summary: 无时间值写入
+author: Zhang Cuiping
+date: 2021-11-23
+---
+
+# 无时间值写入
+
+Uqbar支持无时间值的时序数据写入,对无时间值的时序数据以服务端系统时间作为time列的值。当插入语法中没有指定插入时间时,数据库使用插入时的数据库时间补录time列。
+
+默认timestamp的精度为ms(秒级单位小数点后6位),用户也可以使用如now()::timestamp(x)这样的语法指定小数点后保留几位。(timestamp(3) 表示小数点后保留3位)。
+
+## 语法格式
+
+```
+INSERT INTO table VALUES [, ...];
+```
+
+## 示例
+
+```sql
+Uqbar=# INSERT INTO weather(city, location, temperature) VALUES('beijing', 'chaoyang', 29.1);
+INSERT 0 1
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-writing-model.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-writing-model.md
new file mode 100644
index 0000000000000000000000000000000000000000..87a24391a43001230309d1f596691b73a0522581
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/data-writing-model.md
@@ -0,0 +1,12 @@
+---
+title: 时序数据写入模型
+summary: 时序数写入模型
+author: Guo Huan
+date: 2023-06-08
+---
+
+# 时序数据写入模型
+
++ **[单值模型和多值模型](./single-field-and-multiple-field-model.md)**
++ **[乱序写入](./data-imported-out-of-order.md)**
++ **[无时间值写入](./data-imported-without-the-time-field.md)**
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/single-field-and-multiple-field-model.md b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/single-field-and-multiple-field-model.md
new file mode 100644
index 0000000000000000000000000000000000000000..945a1a01692716cce4858d87b7df36b0a1b9fa2f
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/data-write/data-writing-model/single-field-and-multiple-field-model.md
@@ -0,0 +1,51 @@
+---
+title: 单值模型和多值模型
+summary: 单值模型和多值模型
+author: Zhang Cuiping
+date: 2021-11-23
+---
+
+# 单值模型和多值模型
+
+Uqbar支持单值和多值模型写入。单值模型指创建时序表时,只有一个非TSTIME非TSTAG的字段列,多值模型指创建时序表时有多个非TSTIME非TSTAG的字段列。
+
+## 语法格式
+
+语法格式支持[INSERT](../../uqbar-sql-syntax/INSERT.md)和[COPY](../../uqbar-sql-syntax/COPY.md)。
+
+```
+INSERT INTO table_name[(targelist)] VALUES(value_list)[, (value_list)]...;
+```
+
+```
+COPY table_name [ ( column_name [, ...] ) ]
+ FROM { 'filename' | STDIN }
+ [ [ USING ] DELIMITERS 'delimiters' ]
+ [ WITHOUT ESCAPING ]
+ [ LOG ERRORS ]
+ [ REJECT LIMIT 'limit' ]
+ [ WITH ( option [, ...] ) ]
+ | copy_option
+ | TRANSFORM ( { column_name [ data_type ] [ AS transform_expr ] } [, ...] )
+ | FIXED FORMATTER ( { column_name( offset, length ) } [, ...] ) [ ( option [, ...] ) | copy_option [ ...] ] ];
+```
+
+## 示例
+
+- 单值模型表创建和插入
+
+ ```sql
+ MogDB=# CREATE TIMESERIES TABLE weather(time timestamp TSTIME, city text TSTAG, location text TSTAG, temperature float) POLICY default_policy;
+ CREATE TIMESERIES TABLE
+ MogDB=# INSERT INTO weather VALUES('2022-06-18 00:00:00', 'beijing', 'park', 36);
+ INSERT 0 1
+ ```
+
+- 多值模型表创建和插入
+
+ ```sql
+ MogDB=# CREATE TIMESERIES TABLE weather(time timestamp TSTIME, city text TSTAG, location text TSTAG, temperature float, humidity float) POLICY default_policy;
+ CREATE TIMESERIES TABLE
+ MogDB=# INSERT INTO weather VALUES('2022-06-18 00:00:00', 'beijing', 'park', 36, 2.1);
+ INSERT 0 1
+ ```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/expired-deletion.md b/product/zh/docs-uqbar/v2.0/expired-deletion.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d8653077292ce46fa5a3cea3cc121f7fe19ec0a
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/expired-deletion.md
@@ -0,0 +1,43 @@
+---
+title: 数据删除
+summary: 数据删除
+author: Guo Huan
+date: 2022-11-23
+---
+
+# 数据删除
+
+时序数据通常具有一定的时效性,数据操作基本集中在最新的数据上。用户可以通过配置数据保留策略,自动删除超过保留期限的数据。另外,用户也可以通过调用删除接口手动执行数据删除。
+
+
+
+## 自动删除数据
+
+在创建时序表的时候确定了时序表的数据保留策略,当时序表内数据所在的 chunkgroup 的右边界早于当前时间减去数据保留时长,系统会后台自动删除整个chunkgroup 内的数据。
+
+
+
+## 手动删除数据
+
+通过调用函数进行手动数据删除。
+
+### 示例
+
+```sql
+SELECT * FROM timeseries_catalog.drop_ts_outdate_cg(‘weather’, now());
+SELECT * FROM timeseries_catalog.drop_ts_outdate_cg(‘public.weather’, now()+ ‘1 h’::interval);
+NOTICE: timeseries table weather outdate boundary is 2022-10-31 12:58:01.641916+08
+NOTICE: chunkgroup 24773 boundary is 2022-07-27 04:00:00+08
+NOTICE: chunkgroup 24773 with boundary(2022-07-27 04:00:00+08) is out of date.
+NOTICE: drop chunkgroup 24773 of rel 24760
+NOTICE: chunkgroup 24780 boundary is 2025-10-18 09:00:00+08
+NOTICE: chunkgroup 24787 boundary is 2025-10-18 11:00:00+08
+NOTICE: chunkgroup 24794 boundary is 2025-10-18 12:00:00+08
+NOTICE: chunkgroup 24801 boundary is 2030-07-28 06:00:00+08
+```
+
+手动删除函数的第一个参数用于指定时序表,第二个参数指定触发数据删除的时间。调用过期删除函数,会立即触发一次自动删除动作,自动删除以函数的第二个参数作为当前系统时间进行数据过期检查。
+
+函数执行时会输出提示信息展示时序表每个chunkgroup的过期边界,还会输出信息展示被删除的chunkgroup信息。
+
+如果时序表中数据设置的保留策略是永久保留,无法通过调用删除函数进行手动删除。
diff --git a/product/zh/docs-uqbar/v2.0/glossary.md b/product/zh/docs-uqbar/v2.0/glossary.md
new file mode 100644
index 0000000000000000000000000000000000000000..106b9f16ae39639eb5a1a009e337fb3a435e1e52
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/glossary.md
@@ -0,0 +1,28 @@
+---
+title: 术语表
+summary: 术语表
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# 术语表
+
+**表 1** 术语表
+
+| 术语 | 解释说明 |
+| ---------------------------------- | ------------------------------------------------------------ |
+| 标签(Tags) | 监控指标对应的元数据,一般用于描述数据来源。 |
+| 标签集合(Tagset) | 一组“Tagkey=TagValue”的集合,可唯一确定一个设备。 |
+| 采集指标(Field) | 时序数据中的采集指标,如温度、CPU使用率等,通常随着时间不断变化 |
+| 持续聚合(Continuous Aggregation) | 时序场景下对时序数据进行周期性的降采样查询,并存储查询结果。用户需要查询降采样结果时,可以直接从 CA 执行结果中获取,而不需要对原始时序数据再进行聚合运算,提高了查询效率。 |
+| 单值和多值模型 | 单值模型,指的是每一条数据中采集指标只有一个,即一行数据中只有一个 Field列。多值模型,指的是每一条数据中采集指标有多个,即一行数据中有多个 Field列。 |
+| 分片(Chunk) | 管理分片组下部分设备的时序数据,为实际存储时序数据的单元。 |
+| 分片组(ChunkGroup) | 为了便于对时序数据进行高效过期删除,通常将时序表按照时间范围拆分为多个分片组,以分片组为单位进行过期删除。分片组是逻辑单位,实际由多个分片构成。 |
+| 监控指标项(Metrics/Fields) | 监控指标项,如CPU利用率,闲置内存等。 |
+| 监控指标值(Point/Data) | 监控指标项在不同时间点产生的值。 |
+| 降采样 | 时序场景下的降采样一般是指将一段时间内的多条时序数据聚合为一条数据,例如采集器上报的原始数据是一秒一条,将每一小时数据的平均值计算出来作为降采样后的数据,降采样后的数据精度变为小时级。 |
+| 乱序写入 | 指后写入的数据的时间值小于先写入的数据的时间值。时序场景下的乱序写入,通常是针对 TagSet 相同的数据而言,即针对一个采集设备。同一个采集设备上报的数据是按照时间有序的,但是由于网络或其他原因,可能出现数据可能乱序,即同一个采集设备后到达的数据的时间值小于先到达数据的时间值。有一些时序数据库,如 InfluxDB 中同一个 TagSet 出现多条时间值相同的数据,如果有多条会出现数据覆盖,即后写入的数据会覆盖先写入的数据,查询时只会展示最后写入的那条数据。Uqbar 中允许同一个 TagSet 出现时间值相同的数据,时间值相同的多条数据查询时都会展示。 |
+| 时间序列(Time Series) | 一台设备的一个监控指标项,随时间产生的多个指标值,又叫时间线。 |
+| 时序表(Table) | 存储时序数据的接口表,用户通过时序表写入及查询时序数据。时序表按照时间范围分为多个分片组,每个分片组由多个分片组成。可以把时序表当做二级分区表的父表。 |
+| 数据保留策略(Retention Policy) | 用于定义时序数据的存放规则和保留时间的策略。 |
+| 无时间值写入 | 写入数据没有指定 time 列的值。 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/guc-parameters.md b/product/zh/docs-uqbar/v2.0/guc-parameters.md
new file mode 100644
index 0000000000000000000000000000000000000000..f8a41dc2906dcfb9679c67625069b62d77df73a0
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/guc-parameters.md
@@ -0,0 +1,74 @@
+---
+title: GUC参数
+summary: GUC参数
+author: Guo Huan
+date: 2023-06-08
+---
+
+# GUC参数
+
+## uqbar.timeseries_compression_delay
+
+**参数说明**:表示compression delay的时长。
+
+该参数属于SIGHUP类型参数,单位为秒。
+
+**默认值**:7200
+
+## uqbar.plan_recycle_threshold
+
+**参数说明**:计划回收生阈值。
+
+该参数属于SIGHUP类型参数。
+
+**默认值**:10
+
+## uqbar.plan_recycle_size_limit
+
+**参数说明**:计划回收可使用的最大空间大小。
+
+该参数属于SIGHUP类型参数。
+
+**默认值**:128MB
+
+**取值范围**:16MB - 10GB
+
+## fast_extend_for_prepared_values_batch
+
+**参数说明**:Page扩展优化开关。
+
+该参数属于USERSET类型参数。
+
+**默认值**:on
+
+## bypass_for_prepared_values_batch
+
+**参数说明**:Insert路径优化,减少执行的调用栈开关。
+
+该参数属于USERSET类型参数。
+
+**默认值**:on
+
+## enable_ts_xact
+
+**参数说明**:时序数据WAL不实时落盘开关。
+
+该参数属于SIGHUP类型参数
+
+**默认值**:on
+
+## uqbar.timeseries_auto_parallelize
+
+**参数说明**:自动开启并行查询开关。
+
+该参数属于SIGHUP类型参数。
+
+**默认值**:off
+
+## uqbar.timeseries_parallel_num
+
+**参数说明**:自动并行时的并行数量。
+
+该参数属于SIGHUP类型参数。
+
+**默认值**:4
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/overview.md b/product/zh/docs-uqbar/v2.0/overview.md
new file mode 100644
index 0000000000000000000000000000000000000000..922770502cca1ae787115bfc8bd1b8c835855b8a
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/overview.md
@@ -0,0 +1,72 @@
+---
+title: Uqbar简介
+summary: Uqbar简介
+author: Guo Huan
+date: 2022-11-23
+---
+
+# Uqbar超融合时序数据库
+
+## 产品简介
+
+Uqbar是在openGauss内核基础上开发的时序数据库,同时支持关系模型和时序模型,具备高性能、低成本、稳定可靠和开放易用等优点,是专为物联网场景设计的超融合时序数据库。Uqbar可以用于管理海量时序数据,也可以用于OLTP场景管理关系数据,还支持跨时序数据和关系数据的复杂关联查询,为物联网场景提供一站式数据解决方案。
+
+
+
+## 客户价值
+
+### 超融合
+
+Uqbar提供超融合一站式数据处理能力,满足物联网场景的多模数据管理要求。
+
+- **同时支持关系模型和时序模型**:物联网场景存在传感器元数据,以及传感器监控数据两类数据的管理需求,传统方案需要分别使用一套数据库系统来管理,增加购买和维护成本。使用Uqbar超融合时序数据库,可以在一个数据库内同时管理传感器元数据及监控时序数据。
+
+- **跨关系数据和时序数据的复杂关联查询**:通过一个SQL语句即可完成跨关系数据和时序数据的复杂关联查询,能够支撑丰富的时序数据分析查询需求,同时还能有效降低上层分析平台的业务复杂度,提升查询分析效率。
+
+### 极致性价比
+
+Uqbar提供业界领先的性能及成本能力,满足物联网场景的海量数据管理要求。
+
+- **海量传感器持续大压力写入**:通过NUMA优化、智能数据分区、执行计划复用、数据页快速扩展等技术优化,高并发场景下单节点写入性能可达300万 points/s,超行业标杆20%以上。
+
+- **海量数据高性能聚合分析查询**:通过列式存储引擎、向量化查询引擎、并行查询等技术,优化海量数据聚合分析查询性能,平均毫秒级响应时间,超行业标杆30%以上。
+
+- **多维组合查询**:通过倒排索引能力,支持多维度的任意组合查询,多维查询性能超其他同类产品3倍以上。
+
+- **极致数据压缩率**:通过列式存储及时序专用压缩算法,典型场景下提供10倍以上的数据压缩率,降低存储成本的同时提升查询效率。
+
+- **海量传感器指标管理**:单节点支持千万级传感器指标的管理。
+
+### 安全可靠
+
+Uqbar提供完善的高可用及安全防护能力,满足物联网场景的安全可靠及合规要求。
+
+- **主备高可用**:提供主备集群能力,并内置高可用组件,支持自动故障检测及故障倒换,持续保证业务连续性。
+
+- **数据一致性保证**:针对关系数据提供完整的事务ACID保证,针对时序数据提供可定义一致性级别能力。
+
+- **完善的数据安全防护体系**:支持细粒度权限管理、通信加密、操作审计、备份恢复等功能,在事前、事中、事后提供全方位安全防护能力。
+
+### 开放易用
+
+Uqbar提供丰富的生态对接及运维管理工具,满足物联网场景的简单易用要求。
+
+- **支持多种接入方式**:提供 C/C++、Java、Go 等多种语言的客户端驱动,简化应用程序开发,同时还支持从 Kafka 消费数据。
+
+- **标准SQL**:支持通过标准SQL写入和查询数据,几乎没有学习成本。
+
+- **数据可视化**:支持与Grafana无缝集成,方便通过Grafana进行时序数据可视化洞察。
+
+- **图形化管理工具**:提供图形化的数据库运维管理工具,支持自动化安装部署、数据库监控、备份恢复管理、告警管理等功能,提升数据库运维管理效率。
+
+
+
+## 应用场景
+
+### 物联网场景
+
+利用Uqbar的超融合、极致性价比、安全可靠和开放易用能力,满足物联网场景对海量传感器监控数据的低成本存储、高性能写入、复杂分析查询,以及系统持续高可用的需求。
+
+### 智能运维场景
+
+利用Uqbar的强大查询能力,支持多维度任意组合查询,跨关系表和时序表的关联分析查询,以及极致的查询性能,满足海量数据复杂分析查询需求。
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/ptk-based-installation.md b/product/zh/docs-uqbar/v2.0/ptk-based-installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..008e227464f6666fed574d619da4e7c7f2dbafe6
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/ptk-based-installation.md
@@ -0,0 +1,196 @@
+---
+title: PTK方式安装
+summary: PTK方式安装
+author: Yao Qian
+date: 2022-06-02
+---
+
+# PTK方式安装
+
+本文介绍如何使用PTK安装 Uqbar 数据库。
+
+PTK (Provisioning Toolkit)是一款针对 Uqbar 数据库开发的软件安装和运维工具,旨在帮助用户更便捷地安装部署 Uqbar 数据库。
+
+可执行如下命令查看PTK支持安装 Uqbar 的操作系统。
+
+```bash
+[root@hostname]# ptk candidate os
+ id | os | tested version(s)
+-----+-------------------------------------+----------------------------
+ 1 | CentOS 7 (x86_64) | 7.6.1810 (Core)
+ 2 | openEuler 20 (x86_64) | 20.03 LTS
+ 3 | openEuler 20 (arm64) | 20.03 LTS
+ 4 | openEuler 22 (x86_64) | 22.03 LTS
+ 5 | openEuler 22 (arm64) | 22.03 LTS
+ 6 | Kylin V10 (x86_64) | V10 (Tercel)
+ 7 | Kylin V10 (arm64) | V10 (Tercel)
+ 8 | UOS 20 A (x86_64) | 1002a/1020a/1050a
+ 9 | UOS 20 A (arm64) | 1050a (kongzi)
+ 10 | Ubuntu 20 (x86_64) | 20.04.3 LTS (Focal Fossa)
+ 11 | CentOS 8 (arm64) | 8.0.1905 (Core)
+ 12 | CentOS 8 (x86_64) | 8.0.1905 (Core)
+ 13 | Red Hat Enterprise Linux 7 (x86_64) | 7.5 (Maipo)
+ 14 | Red Hat Enterprise Linux 8 (x86_64) | 8.5 (Ootpa)
+ 15 | EulerOS 2 (x86_64) | 2.0 (SP3)
+ 16 | EulerOS 2 (arm64) | 2.0 (SP3)
+ 18 | SLES 12SP5 (x86_64) | 12SP5
+ 19 | Oracle Linux 7 (x86_64) | 7.9 (Maipo)
+ 20 | Oracle Linux 8 (x86_64) | 8.6 (Ootpa)
+ 21 | Rocky Linux 8 (x86_64) | 8.5 (Green Obsidian)
+ 22 | NeoKylin V7 (x86_64) | V7Update6
+ 23 | UOS 20 D/E (x86_64) | 1040d (fou)
+ 24 | UOS 20 D/E (arm64) | 1040d (fou)
+ 25 | Ubuntu 22 (x86_64) | 22.04 (Jammy Jellyfish)
+```
+
+> **注意**:
+>
+> - PTK工具本身可以在多种操作系统中运行,支持Linux,macOS,Windows,但是由于 Uqbar 目前仅支持在Linux 系统中运行,因此需确保要运行Uqbar 数据库的服务器为 Linux 操作系统。
+> - 需要使用PTK v0.5 或以上版本安装Uqbar,否则安装可能失败。
+
+## 安装准备
+
+有关环境要求和操作系统配置详情,请参见MogDB的[环境要求](https://docs.mogdb.io/en/mogdb/v3.1/environment-requirement)和[操作系统配置](https://docs.mogdb.io/en/mogdb/v3.1/os-configuration)等相关章节。
+
+## 下载安装 PTK
+
+有关PTK安装,请访问[安装PTK](https://docs.mogdb.io/zh/ptk/latest/install)。
+
+## 通过PTK安装Uqbar
+
+### 准备拓扑配置文件
+
+PTK安装需要用户提供配置文件config.yaml,PTK支持单节点安装以及多节点安装。下面以单节点安装和一主一备节点安装为例。
+
+**单节点安装**
+
+```yaml
+# config.yaml
+global:
+ cluster_name: uqbar1
+ user: omm
+ group: omm
+ base_dir: /opt/uqbar
+db_servers:
+ - host: 127.0.0.1
+ db_port: 26000
+```
+
+如果全部使用默认值,则PTK 执行以下操作:
+
+* 在本机安装数据库;
+* 运行数据库的操作系统用户为omm ,用户组名称也是omm,该用户没有默认密码;
+* 数据库安装在 /opt/uqbar目录下,在该目录下会创建4个目录:app, data, log, tool,分别用于存储数据库软件、数据文件、数据库日志和数据库相关工具;
+* 数据库监听端口为26000;
+
+**主备节点安装**
+
+```yaml
+# config.yaml
+global:
+ cluster_name: uqbar_cluster1
+ user: omm
+ group: omm
+ base_dir: /opt/uqbar
+db_servers:
+ - host: 192.168.0.1
+ db_port: 26000
+ role: primary
+ ssh_option:
+ port: 22
+ user: root
+ password: [此处填写SSH登录密码]
+ - host: 192.168.0.2
+ db_port: 26000
+ role: standby
+ ssh_option:
+ port: 22
+ user: root
+ password: [此处填写SSH登录密码]
+```
+
+### 检查本机系统
+
+```shell
+ptk checkos -f config.yaml
+```
+
+确保输出的检查结果均为 `OK` 或者 `Warning` ,如果有 `Abnormal` 或 `ExecuteError`出现,需用户根据日志提示先修正系统参数。
+
+### 执行安装
+
+PTK 支持自定义安装包,用户需要手工下载安装包,指定安装。例如执行以下命令,将使用当前目录下的该安装包进行数据库安装。安装过程中会提示用户输入数据库初始用户的密码,请用户自行记录并安全保存。PTK 自动完成所有安装操作后,会启动数据库实例。
+
+```shell
+ptk install -f config.yaml --pkg ./Uqbar-1.1.0-openEuler-arm64.tar.gz
+```
+
+安装成功后,也可以通过 `ptk ls` 来查看安装的实例信息。
+
+```bash
+[root@hostname]# ptk ls
+ cluster_name | instances | user | data_dir | db_version
+---------------+--------------------+------+-----------------+--------------
+ uqbar1 | 172.16.0.127:26000 | omm | /opt/uqbar/data | Uqbar-1.1.0
+```
+
+### 访问数据库
+
+```shell
+su - omm
+gsql -d postgres -p 26000
+```
+
+## 通过PTK卸载Uqbar
+
+> **注意**:数据库卸载后无法恢复,请谨慎操作。
+
+执行如下命令卸载数据库:
+
+```bash
+ptk uninstall (-f CONFIG.YAML|--name CLUSTER_NAME)
+```
+
+在卸载前,PTK 会交互式的询问用户,以确认要删除的数据库信息,确认是否要连带删除系统用户,以及确认是否要连带删除数据库数据。请在回答每一个问题时,确认你的回答,避免由于误操作导致不可恢复的数据丢失!
+
+在 PTK 执行数据库卸载操作时,如果用户指定了删除数据目录,PTK 仅会删除数据目录,不会删除数据目录所在的父目录,需用户手动清理父目录。
+
+卸载成功后,将提示如下信息:
+
+```bash
+[root@hostname]# ptk uninstall -n uqbar1
+=============================
+global:
+ cluster_name: uqbar1
+ user: omm
+ group: omm
+ app_dir: /opt/uqbar/app
+ data_dir: /opt/uqbar/data
+ log_dir: /opt/uqbar/log
+ tool_dir: /opt/uqbar/tool
+ tmp_dir: /opt/uqbar/tmp
+db_servers:
+- host: 172.16.0.127
+ db_port: 26000
+ role: primary
+ az_name: AZ1
+ az_priority: 1
+
+=============================
+Do you really want to uninstall this cluster? Please confirm carefully[Y|Yes](default=N) y
+Do you want to delete db data '/opt/uqbar/data'?[Y|Yes](default=N) y
+Do you want to delete user 'omm'?[Y|Yes](default=N) y
+INFO[2022-07-08T10:27:42.820] check db dirs owner host=172.16.0.127
+INFO[2022-07-08T10:27:42.828] clean crontab host=172.16.0.127
+INFO[2022-07-08T10:27:42.894] kill omm's processes host=172.16.0.127
+INFO[2022-07-08T10:27:42.970] remove files /opt/uqbar/app,/opt/uqbar/tool,/opt/uqbar/cm,/opt/uqbar/tmp,/opt/uqbar/data,/opt/uqbar/log host=172.16.0.127
+INFO[2022-07-08T10:27:43.073] delete os user omm host=172.16.0.127
+INFO[2022-07-08T10:27:43.213] clearing /etc/cron.allow host=172.16.0.127
+INFO[2022-07-08T10:27:43.217] clearing /etc/security/limits.conf host=172.16.0.127
+```
+
+> **注意**:使用配置文件来卸载的前提是配置文件还存在。使用集群名称来指定的前提是 `ptk ls` 可以正常查询到该集群。
+
+## 相关页面
+
+有关PTK工具详细使用手册,请访问[关于PTK](https://docs.mogdb.io/zh/ptk/latest/overview)。
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/aggregation-operator.md b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/aggregation-operator.md
new file mode 100644
index 0000000000000000000000000000000000000000..d542aa85505a8062e155515b9f8158d655566ec3
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/aggregation-operator.md
@@ -0,0 +1,25 @@
+---
+title: 聚合类算子
+summary: 聚合类算子
+author: zhang cuiping
+date: 2023-04-12
+---
+
+# 聚合类算子
+
+当前版本的Uqbar支持以下常用聚合算子:
+
+| 聚合函数 | 用途 | 参考链接 |
+| ------------------- | -------------------------- | ------------------------------------------------------------ |
+| count | 统计数量 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| distinct | 去重 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| avg | 平均值 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| median | 求中位数 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| mode() within group | 求最大频次数 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| stddev | 求标准差 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| sum | 求和 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| time_bucket | 时间对齐 | [time_bucket](./time-bucket.md) |
+| time_bucket_gapfill | 对数据缺失的时间段进行填值 | [time_bucket_gapfill](./time-bucket-gapfill.md) |
+| sum...over... | 累积和 | [Session性能诊断 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/4-session-performance-diagnosis#特性描述) |
+| avg...over | 移动平均 | [高级分析函数支持 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/6-support-for-advanced-analysis-functions#特性描述) |
+| histogram | 分析时间序列数据的分布情况 | [histogram](./histogram.md) |
diff --git a/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/histogram.md b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/histogram.md
new file mode 100644
index 0000000000000000000000000000000000000000..d51e958f7cd70e7c2529a4585ab5ed6bfb0702d1
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/histogram.md
@@ -0,0 +1,56 @@
+---
+title: histogram
+summary: histogram
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# histogram()
+
+## 功能描述
+
+用于生成直方图/柱状图(histogram)数据来分析时间序列数据的分布情况。可以帮助理解时间序列数据的值在给定范围内的分布情况,以及发现异常值或数据倾斜。
+
+## 语法格式
+
+```sql
+SELECT histogram(column,min,max,num_buckets) FROM your_table;
+```
+
+## 参数说明
+
+- column:时序表中要生成直方图的列名。
+
+- min:直方图的范围的下限(包含)。
+
+- max:直方图的范围的上限(不包含)。
+
+- nbuckets:指定生成的直方图中的桶(buckets)数量。
+
+ 计算直方图时,将min-max均分为nbuckets个子区间(左闭右开),小于min的值单独划分为一个区间,大于等于max的值单独划分为一个区间,实际上桶的数量为nbuckets+2。直方图的计算结果为column值落在每一个区间的数量。
+
+histogram函数的作用:
+
+- 分布分析:通过生成直方图,可以了解时序数据的值在给定范围内的分布情况。每个桶表示一个值范围,并计算在该范围内的数据点数量。这有助于发现数据的分布模式、峰值和异常值。
+- 数据倾斜检测:直方图可以帮助识别时序数据中是否存在数据倾斜。如果某个桶的数量明显高于其他桶,表示该值范围内的数据点较多,可能存在数据倾斜或异常情况。
+- 数据划分:通过将时序数据划分为多个桶,可以将数据进行粗粒度的分区或分组。这有助于更好地理解数据集的组成和分布,以及在查询和分析过程中提供更高效的聚合计算。
+
+## 示例
+
+以下示例介绍如何使用histogram函数生成直方图数据:
+
+```sql
+Uqbar=# select city, histogram(temperature, -10,30, 4) from weather group by city;
+ city | histogram
+------------+------------------------------
+ chengdu | {0,30,45,55,185,50}
+ jinan | {20,30,40,60,175,40}
+ beijing | {10,20,60,70,170,35}
+(3 row)
+```
+
+该查询会对weather表中的temperature列生成6个桶的直方图数据,并按照 city 进行分组。例如查询输出的第一行展示 city = ‘chengdu’的数据的直方图,以图表的方式展示如下。
+
+
+
+通过使用histogram函数,您可以对时序数据进行分布分析,发现异常值或数据倾斜,并在数据分析过程中提供更多见解和洞察。
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/time-bucket-gapfill.md b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/time-bucket-gapfill.md
new file mode 100644
index 0000000000000000000000000000000000000000..e464419069f47283e7e8206c6b15f94b81d1a6d1
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/time-bucket-gapfill.md
@@ -0,0 +1,150 @@
+---
+title: time_bucket_gapfill
+summary: time_bucket_gapfill
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# time_bucket_gapfill()
+
+## 功能描述
+
+time_bucket_gapfill 在time_bucket 的基础上增加了对数据缺失的时间段进行填值的功能。
+
+## 语法格式
+
+```
+time_bucket_gapfill(bucket_width, time, start_time , finish_time)
+```
+
+## 参数说明
+
+| 参数名 | 类型 | 属性 | 释义 |
+| ------------ | --------- | ---- | ------------------------------------------------------------ |
+| bucket_width | TEXT | 必选 | 对齐的时间间隔。只能使用'正整数+时间标识'的方式,时间标识包括: interval 支持的所有单位,包括'microsecond,millisecond,second,minute,hour,day,week,month,year,decade,century,millennium' 及这些单位的复数形式,如 years, months,days 等和简写形式,如 y, m, d 等。 |
+| time | TIMESTAMP | 必选 | 需要对齐的时间。 |
+| start_time | TIMESTAMP | 可选 | 需要gapfill的开始的时间(比方结果集中没有某个时间,但是需要查询结果中有这个时间)。如果不指定此参数需要在where条件中指定。 |
+| finish_time | TIMESTAMP | 可选 | 需要gapfill的结束的时间(比方结果集中没有某个时间,但是需要查询结果中有这个时间)。如果不指定此参数需要在where条件中指定。 |
+
+举例:
+
+系统中有6条时序数据,时间格式中缺省年月日信息。
+
+| time | 00:00:00 | 00:01:00 | 00:15:00 | 00:36:00 | 00:45:00 | 01:06:00 |
+| ----- | -------- | -------- | -------- | -------- | -------- | -------- |
+| value | 30 | 31 | 32 | 33 | NULL | 34 |
+
+对以上数据计算按照 10min 一个窗口计算平均值,结果如下:
+
+| time | 00:00:00 | 00:10:00 | | 00:30:00 | 00:40:00 | | 01:00:00 |
+| ---- | -------- | -------- | ---- | -------- | -------- | ---- | -------- |
+| avg | 30.5 | 32 | | 33 | NULL | | 34 |
+
+由于其中一些时间窗口内没有时序数据上报,时间窗口内无聚合结果。time_bucket_gapfill 的作用是按照一定规则对这些时间窗口填值,从而生成时间窗口内的聚合结果。
+
+系统提供了一些填值函数与 time_bucket_gapfill 一起使用,用于按照指定规则对缺少值进行填充。
+
+- **locf(value[, prev, treat_null_as_missing])**
+
+ 与time_bucket_gapfill一起使用,使用上一个窗口的值进行填充。
+
+ | 参数名 | 类型 | 属性 | 释义 |
+ | --------------------- | ---------- | ---- | ------------------------------------------ |
+ | value | ANY | 必选 | 需要填充的值表达式。 |
+ | prev | EXPRESSION | 可选 | 如果没有找到前一个值,则使用此表达式寻值。 |
+ | treat_null_as_missing | BOOLEAN | 可选 | 不向后携带空值。默认值false。 |
+
+ 例如事件窗口 00:20:00 填充值是上一个窗口 00:10:00 聚合结果 32。
+
+ | time | 00:00:00 | 00:10:00 | 00:20:00 | 00:30:00 | 00:40:00 | 00:50:00 | 01:00:00 |
+ | ---- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
+ | avg | 30.5 | 32 | 32 | 33 | NULL | NULL | 34 |
+
+ 当我们在locf函数中设置了参数treat_null_as_missing => true后,会将null当作缺失的值进行填充。
+
+ | time | 00:00:00 | 00:10:00 | 00:20:00 | 00:30:00 | 00:40:00 | 00:50:00 | 01:00:00 |
+ | ---- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
+ | avg | 30.5 | 32 | 32 | 33 | 33 | 33 | 34 |
+
+- **interpolate(value[, prev[, next]])**
+
+ 对缺失数据线性插值填充,即取上一个窗口和下一个窗口的平均值,如果上一个窗口和下一个窗口不存在,则值取为空。
+
+ | 参数名 | 类型 | 属性 | 释义 |
+ | ------ | ---------- | ---- | ---------------------------------------------------------- |
+ | value | ANY | 必选 | 需要填充的值表达式。 |
+ | prev | EXPRESSION | 可选 | 如果没有计算插值的前序值,那么使用此表达式寻值代替前序值。 |
+ | next | EXPRESSION | 可选 | 如果没有计算插值的后序值,那么使用此表达式寻值代替后序值。 |
+
+ 举例:
+
+ 00:20:00 窗口的填充值为 00:10:00 窗口和 00:30:00 窗口聚合值的平均值。
+
+ | time | 00:00:00 | 00:10:00 | 00:20:00 | 00:30:00 | 00:40:00 | 00:50:00 | 01:00:00 |
+ | ---- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
+ | avg | 30.5 | 32 | 32.5 | 33 | NULL | NULL | 34 |
+
+## 约束
+
+- 在同一级查询中只能有一个time_bucket_gapfill函数。
+
+- 使用插值函数必须在函数参数或where条件中指定 start_time 和 finish_time。
+
+- start_time <= finish_time。
+
+- 返回结果自动按 time列 升序排列。
+
+## 示例
+
+创建持续聚合,目标时序表有time_bucket_gapfill()函数列,创建失败。
+
+1. 创建源时序表。
+
+ ```sql
+ CREATE TIMESERIES TABLE t_uqbar_ca_create_case0008_1(time timestamp TSTIME, city text TSTAG, temperature float);
+ insert into t_uqbar_ca_create_case0008_1 values ('2023-02-14 06:00:00','beijing',14.4);
+ select * from timeseries_views.tstable;
+ ```
+
+2. 创建持续聚合,目标时序表有time_bucket_gapfill()函数列,失败。
+
+ ```sql
+ CREATE CONTINUOUS AGGREGATION IF NOT EXISTS agg_ca_create_case0008_1 EVERY '1 year' START_OFFSET '10 year' END_OFFSET '1h' AS
+ SELECT time_bucket_gapfill('1 h',time) as bucket,city,avg(temperature)
+ FROM t_uqbar_ca_create_case0027_1 GROUP BY bucket,city ORDER BY bucket;
+ ```
+
+3. 查询不到持续聚合元数据。
+
+ ```sql
+ select ca_schema,ca_name,resample_time,resample_interval,start_offset,end_offset,query from timeseries_catalog.continuous_aggregation;
+ select * from timeseries_views.continuous_aggregation;
+ ```
+
+4. 查询不到目标时序表信息。
+
+ - 查询时序表元数据,查询失败。
+
+ ```sql
+ select timecol,tagcol from timeseries_catalog.tstable;
+ select tablename,timecolname,tagcol,tspolicy from timeseries_views.tstable;
+ select * from agg_ca_create_case0027_1;
+ ```
+
+ - 查询目标表的列字段信息,查询失败。
+
+ ```sql
+ SELECT col_description(a.attrelid,a.attnum) as comment,format_type(a.atttypid,a.atttypmod) as type,a.attname as name, a.attnotnull as notnull
+ FROM pg_class as c,pg_attribute as a
+ where c.relname = 'agg_ca_create_case0027_1' and a.attrelid = c.oid and a.attnum>0;
+ ```
+
+ - 查询后台任务视图,没有目标表任务。
+
+ ```sql
+ select * from timeseries_catalog.bgw_job;
+ select * from timeseries_views.bgw_job;
+ SELECT ca.ca_name, ca.resample_interval, job.interval ,as job_interval
+ FROM timeseries_catalog.continuous_aggregation AS ca LEFT JOIN
+ pg_job AS job ON ca.job_id = job.job_id WHERE ca.ca_name = 'agg_ca_create_case0027_1';
+ ```
diff --git a/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/time-bucket.md b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/time-bucket.md
new file mode 100644
index 0000000000000000000000000000000000000000..33f322dbfd407af0e9f11f61e82c73b18427d8ff
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/aggregation-operator/time-bucket.md
@@ -0,0 +1,64 @@
+---
+title: dsscmd
+summary: dsscmd
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# time_bucket()
+
+## 功能描述
+
+将时间序列数据按照指定的时间间隔分组,并对这些分组的数据进行聚合操作,如计算平均值、求和等。
+
+## 语法格式
+
+```sql
+time_bucket(bucket_width, time,[offset | origin])
+```
+
+## 参数说明
+
+| 参数名 | 类型 | 属性 | 释义 |
+| ------------ | --------- | ---- | ------------------------------------------------------------ |
+| bucket_width | TEXT | 必选 | 对齐的时间间隔。只能使用'正整数+时间标识'的方式,时间标识包括interval类型支持的所有单位,包括'microsecond,millisecond,second,minute,hour,day,week,month,year,decade,century,millennium' 及这些单位的复数形式,如years、months、days等和简写形式,如y、m、d等。 |
+| time | TIMESTAMP | 必选 | 需要对齐的时间。 |
+| offset | INTERVAL | 可选 | 使用这个值调整对齐窗口位置,如果是正值,时间窗口整体向将来移动,如果是负值,窗口位置向过去移动。相当于将默认的origin移动offset的位置。 |
+| origin | TIMESTAMP | 可选 | 对齐的base,默认从’2001-1-1 00:00:00’对齐;此参数与offset互斥。 |
+
+## 约束
+
+使用time_bucket时,由于offset与origin是互斥的参数,所以time_bucket的第三个参数可能是offset(interval 类型),也可能是origin(timestamp 类型)。为了方便区分是offset还是origin使用时,如果使用offset或者origin需要显式指定第三个参数的类型,如:
+
+```sql
+select time_bucket('5minute',time,'2001-1-1 00:00:00'::timestamp) as bucket ,count(temperature) from weather group by bucket order by bucket asc;
+```
+
+或者
+
+```sql
+select time_bucket('1minute',time,'1minute'::interval) as bucket ,count(temperature) from weather group by bucket order by bucket asc;
+```
+
+## 示例
+
+```sql
+Uqbar=# select * from t1 order by time;
+ time | id | value
+------------------------+----+-------
+ 2022-06-02 00:01:00+08 | 1 | 9
+ 2022-06-02 00:04:00+08 | 1 | 11
+ 2022-06-02 00:06:00+08 | 1 | 10
+ 2022-06-02 00:07:00+08 | 1 | 11
+ 2022-06-02 00:15:00+08 | 1 | 12
+(5 rows)
+
+Uqbar=# select time_bucket('2 minute',time) as bucket, sum(value) from t1 group by bucket order by bucket;
+ bucket | sum
+------------------------------------+-----
+ 2022-06-02 00:00:00+08 | 9
+ 2022-06-02 00:04:00+08 | 11
+ 2022-06-02 00:06:00+08 | 21
+ 2022-06-02 00:14:00+08 | 12
+(4 rows)
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/query-data/conversion-operator.md b/product/zh/docs-uqbar/v2.0/query-data/conversion-operator.md
new file mode 100644
index 0000000000000000000000000000000000000000..989c81f3d5930e3b01071a55214a214399ead33e
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/conversion-operator.md
@@ -0,0 +1,30 @@
+---
+title: 转换类算子
+summary: 转换类算子
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# 转换类算子
+
+当前版本的Uqbar支持以下常用转换算子:
+
+| 函数 | 用途 | 参考链接 |
+| ----- | ------------ | ------------------------------------------------------------ |
+| ABS | 求绝对值 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| ACOS | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| ASIN | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| ATAN | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| ATAN2 | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| CEIL | 向上取整 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| COS | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| EXP | 求指数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| FLOOR | 向下取整 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| LN | 对数函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| LOG | 对数函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| POW | 乘方运算 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| ROUND | 四舍五入运算 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| SIN | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| SQRT | 求平方根 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| TAN | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
+| COT | 三角函数 | [数字操作函数和操作符 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/mathematical-functions-and-operators#数字操作函数) |
diff --git a/product/zh/docs-uqbar/v2.0/query-data/index.md b/product/zh/docs-uqbar/v2.0/query-data/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..2e708e0b46db757218b84f0281ec32788f7af832
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/index.md
@@ -0,0 +1,79 @@
+---
+title: 索引
+summary: 索引
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# 索引
+
+在时序表上支持索引相关功能,以便用户根据实际需求使用索引提升查询性能。时序表上支持的索引类型包括Btree和Gin,不支持创建部分索引,Btree可以支持唯一索引。时序表上索引默认是LOCAL索引,不支持创建GLOBAL索引。在时序表执行数据删除时,对应分区上的索引也会一起删除。
+
+## 创建索引
+
+语法和分区表创建索引语法基本相同,但不支持创建GLOBAL索引。
+
+```sql
+CREATE [ UNIQUE ] INDEX [ [schema_name.]index_name ] ON table_name [ USING method ]
+ ( {{ column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS LAST ] }[, ...] )
+ [ LOCAL [ ( { PARTITION index_partition_name | SUBPARTITION index_subpartition_name [ TABLESPACE index_partition_tablespace ] } [, ...] ) ] ]
+ [ INCLUDE ( column_name [, ...] )]
+ [ WITH ( { storage_parameter = value } [, ...] ) ]
+ [ TABLESPACE tablespace_name ];
+```
+
+## 修改索引
+
+- 重命名表索引的名称
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name RENAME TO new_name;
+ ```
+
+- 修改表索引的存储参数
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name SET ( {storage_parameter = value} [, ... ] );
+ ```
+
+- 设置表索引或索引分区不可用
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name [ MODIFY PARTITION index_partition_name ] UNUSABLE;
+ ```
+
+- 重置索引的一个或多个索引方法特定的存储参数为缺省值。与SET一样,可能需要使用REINDEX来完全更新索引。
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name RESET ( { storage_parameter } [, …] );
+ ```
+
+- 重建表或者索引分区上的索引。
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name REBUILD [ PARTITION index_partition_name ];
+ ```
+
+- 重命名索引分区
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name RENAME PARTITION index_partition_name TO new_index_partition_name;
+ ```
+
+- 修改索引分区的所属表空间
+
+ ```sql
+ ALTER INDEX [ IF EXISTS ] index_name MOVE PARTITION index_partition_name TABLESPACE new_tablespace;
+ ```
+
+## 删除索引
+
+```sql
+DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] index_name [, ...] [ CASCADE | RESTRICT ];
+```
+
+## 重建索引
+
+```sql
+REINDEX { INDEX| [INTERNAL] TABLE} name PARTITION partition_name [ FORCE ];
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/query-data/join-query.md b/product/zh/docs-uqbar/v2.0/query-data/join-query.md
new file mode 100644
index 0000000000000000000000000000000000000000..af9ed41ef32186b6fad078d6e575b19b677e2735
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/join-query.md
@@ -0,0 +1,64 @@
+---
+title: Join查询
+summary: Join查询
+author: Guo Huan
+date: 2022-11-24
+---
+
+# Join查询
+
+支持时序表与关系表、时序表与时序表之间join查询。
+
+```sql
+Uqbar=# CREATE TABLE cpu_info (id int, arch text, cores int, speed float);
+
+Uqbar=# INSERT INTO cpu_info VALUES (1, 'aarch64', 8, 2000);
+Uqbar=# INSERT INTO cpu_info VALUES (2, 'x86_64', 8, 2200);
+Uqbar=# INSERT INTO cpu_info VALUES (3, 'aarch64', 16, 2000);
+Uqbar=# INSERT INTO cpu_info VALUES (4, 'x86_64', 16, 2200);
+
+Uqbar=# DROP TIMESERIES TABLE IF EXISTS cpu;
+Uqbar=# CREATE TIMESERIES TABLE cpu(time timestamp tstime, tags_id int tstag, usage float);
+
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-01 00:00:00', 1, 82);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-01 12:00:00', 1, 83);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-01 23:59:59', 1, 84);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 1, 92);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 12:00:00', 1, 93);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 23:59:59', 1, 94);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 2, 84);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 12:00:00', 2, 85);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 23:59:59', 2, 86);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 3, 93);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 3, 92);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 3, 91);
+Uqbar=# INSERT INTO cpu VALUES ('2023-05-02 00:00:00', 5, 91);
+
+Uqbar=# SELECT cpu.time, cpu_info.arch, cpu_info.id, cpu_info.cores, cpu_info.speed FROM cpu LEFT JOIN cpu_info ON cpu.tags_id = cpu_info.id ORDER BY cpu.tags_id,cpu.time ASC;
+ time | arch | id | cores | speed
+---------------------+---------+----+-------+-------
+ 2023-05-01 00:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-01 12:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-01 23:59:59 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 00:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 12:00:00 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 23:59:59 | aarch64 | 1 | 8 | 2000
+ 2023-05-02 00:00:00 | x86_64 | 2 | 8 | 2200
+ 2023-05-02 12:00:00 | x86_64 | 2 | 8 | 2200
+ 2023-05-02 23:59:59 | x86_64 | 2 | 8 | 2200
+ 2023-05-02 00:00:00 | aarch64 | 3 | 16 | 2000
+ 2023-05-02 00:00:00 | aarch64 | 3 | 16 | 2000
+ 2023-05-02 00:00:00 | aarch64 | 3 | 16 | 2000
+ 2023-05-02 00:00:00 | | | |
+(13 rows)
+
+Uqbar=# SELECT time_bucket('1 day',time) as bucket, cpu_info.id, avg(usage) FROM cpu LEFT JOIN cpu_info ON cpu.tags_id = cpu_info.id GROUP BY bucket,cpu_info.id ORDER BY cpu_info.id,bucket ASC;
+ bucket | id | avg
+---------------------+----+-----
+ 2023-05-01 00:00:00 | 1 | 83
+ 2023-05-02 00:00:00 | 1 | 93
+ 2023-05-02 00:00:00 | 2 | 85
+ 2023-05-02 00:00:00 | 3 | 92
+ 2023-05-02 00:00:00 | | 91
+(5 rows)
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/query-data/lateral-keyword.md b/product/zh/docs-uqbar/v2.0/query-data/lateral-keyword.md
new file mode 100644
index 0000000000000000000000000000000000000000..54d0cf7228c4074557b8ea57f1bf00f7411ac0b2
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/lateral-keyword.md
@@ -0,0 +1,58 @@
+---
+title: LATERAL关键字
+summary: LATERAL关键字
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# LATERAL关键字
+
+LATERAL 关键字用于在查询中引用先前表达式的结果。它可以与子查询或函数一起使用,并允许在查询中使用先前的表达式结果作为后续表达式的输入。
+
+LATERAL关键字的作用:
+
+- 依赖关联子查询:使用`LATERAL`关键字,可以在查询中引用先前的表达式,从而创建依赖关联的子查询。即可以在子查询中访问先前的表达式的结果,并在查询中使用该结果作为后续表达式的输入。
+- 动态列计算:`LATERAL`关键字可以用于动态计算列的值。例如,在查询中使用`LATERAL`来计算每行的列值,这些列的计算依赖于先前的表达式结果或其他表中的数据。
+- 减少查询次数:通过使用`LATERAL`关键字可以避免多次执行重复的子查询。子查询可以引用外部查询的表达式结果,从而在查询执行过程中减少查询次数,提高性能。
+
+```sql
+Uqbar=# CREATE TABLE t_product AS
+ SELECT id AS product_id,
+ id * 10 * random() AS price,
+ 'product ' || id AS product
+ FROM generate_series(1, 1000) AS id;
+
+Uqbar=# CREATE TABLE t_wishlist
+(
+ wishlist_id int,
+ username text,
+ desired_price numeric
+);
+
+Uqbar=# INSERT INTO t_wishlist VALUES
+ (1, 'hans', '450'),
+ (2, 'joe', '60'),
+ (3, 'jane', '1500');
+
+Uqbar=# SELECT *
+FROM t_wishlist AS w,
+ LATERAL (SELECT *
+ FROM t_product AS p
+ WHERE p.price < w.desired_price
+ ORDER BY p.price DESC
+ LIMIT 3
+ ) AS x
+ORDER BY wishlist_id, price DESC;Uqbar-# Uqbar-# Uqbar(# Uqbar(# Uqbar(# Uqbar(# Uqbar(# Uqbar-#
+ wishlist_id | username | desired_price | product_id | price | product
+-------------+----------+---------------+------------+------------------+-------------
+ 1 | hans | 450 | 268 | 447.912638001144 | product 268
+ 1 | hans | 450 | 445 | 440.73279609438 | product 445
+ 1 | hans | 450 | 90 | 436.825405899435 | product 90
+ 2 | joe | 60 | 122 | 57.7194433659315 | product 122
+ 2 | joe | 60 | 50 | 55.5128382984549 | product 50
+ 2 | joe | 60 | 9 | 55.1704007294029 | product 9
+ 3 | jane | 1500 | 168 | 1498.51569615304 | product 168
+ 3 | jane | 1500 | 774 | 1496.66411731392 | product 774
+ 3 | jane | 1500 | 420 | 1494.14442060515 | product 420
+(9 rows)
+```
diff --git a/product/zh/docs-uqbar/v2.0/query-data/query-data.md b/product/zh/docs-uqbar/v2.0/query-data/query-data.md
new file mode 100644
index 0000000000000000000000000000000000000000..7fa6178aa8b94bf816aad83866be108a4b2e2bb3
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/query-data.md
@@ -0,0 +1,17 @@
+---
+title: 数据查询
+summary: 数据查询
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# 数据查询
+
+Uqbar使用SQL作为查询语言,用户可以通过客户端或者不同的驱动连接到Uqbar执行数据查询。为支持用户不同的数据分析需求,Uqbar提供了丰富的查询算子。
+
+- **[聚合类算子](./aggregation-operator/aggregation-operator.md)**
+- **[选择类算子](./selection-operator/selection-operator.md)**
+- **[转换类算子](./conversion-operator.md)**
+- **[Join查询](./join-query.md)**
+- **[LATERAL关键字](./lateral-keyword.md)**
+- **[索引](./index.md)**
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/query-data/selection-operator/first-last.md b/product/zh/docs-uqbar/v2.0/query-data/selection-operator/first-last.md
new file mode 100644
index 0000000000000000000000000000000000000000..58e5771946523019c4ef4b1e794180cbee6a9ebd
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/selection-operator/first-last.md
@@ -0,0 +1,45 @@
+---
+title: first/last
+summary: first/last
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# first()/last()
+
+## 功能描述
+
+使用cmp_col列做比较,返回时间最早或最晚的value指定的列的值。时序的first/last算子在timeseries_catalog这个schema下,区别于public中的first/last。
+
+## 语法格式
+
+```sql
+select city_name,timeseries_catalog.first(temp_c,time) from weather_metrics group by city_name;
+select city_name,timeseries_catalog.last(temp_c,time) from weather_metrics group by city_name;
+timeseries_catalog.first(value, cmp_col)
+timeseries_catalog.last(value, cmp_col)
+```
+
+## 参数说明
+
+| 参数名 | 类型 | 属性 | 释义 |
+| ------- | ------------------------ | ---- | ------ |
+| value | ANY | 必选 | 返回值 |
+| cmp_col | TIMESTAMP or TIMESTAMPTZ | 必选 | 比较值 |
+
+## 约束
+
+当表存在多条记录的cmp_col列最小值/最大值相同时,返回这些记录中第一条/最后一条的value。
+
+当cmp_col列为常量时,时序first/last算子的效果等同于public中的first/last算子, 返回所有记录中的第一条/最后一条的value值。
+
+## 示例
+
+```sql
+Uqbar=# select city_name,timeseries_catalog.first(temp_c,time) from weather_metrics group by city_name;
+ city_name | first
+---------------+-------
+beijing | 30
+shanghai | 29
+(2 row)
+```
diff --git a/product/zh/docs-uqbar/v2.0/query-data/selection-operator/selection-operator.md b/product/zh/docs-uqbar/v2.0/query-data/selection-operator/selection-operator.md
new file mode 100644
index 0000000000000000000000000000000000000000..3d3625b5d8154e988539bdec4fc013121511a743
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/query-data/selection-operator/selection-operator.md
@@ -0,0 +1,17 @@
+---
+title: 选择类算子
+summary: 选择类算子
+author: zhang cuiping
+date: 2023-04-07
+---
+
+# 选择类算子
+
+Uqbar当前版本支持以下常用选择类算子:
+
+| 函数 | 用途 | 参考链接 |
+| ----- | ---------- | ------------------------------------------------------------ |
+| first | 取最早的值 | [first() / last()](./first-last.md) |
+| last | 取最晚的值 | [first() / last()](./first-last.md) |
+| max | 取最大的值 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
+| min | 取最小的值 | [聚集函数 \| MogDB Docs](https://docs.mogdb.io/zh/mogdb/v5.0/aggregate-functions) |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/release-notes/2.0.0.md b/product/zh/docs-uqbar/v2.0/release-notes/2.0.0.md
new file mode 100644
index 0000000000000000000000000000000000000000..db7b20f8a8c89ca9859f5bcfd1499b247c2a7439
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/release-notes/2.0.0.md
@@ -0,0 +1,65 @@
+---
+title: Uqbar 2.0.0
+summary: Uqbar 2.0.0
+author: Guo Huan
+date: 2022-12-08
+---
+
+# Uqbar 2.0.0
+
+## 版本说明
+
+Uqbar 2.0.0 是 Uqbar时序数据库发布的第二个版本,版本发布于2023年6月30日。作为Uqbar时序数据库的第一个LTS版本,2.0.0版本在时序基础功能上做了增强,同时优化写入性能和压缩率,并修复了 1.1.0 版本中的一些缺陷。
+
+
+
+## 基础功能
+
+- 时序策略
+- 时序表
+- 数据压缩
+- 过期删除
+- 查询算子
+- 高可用
+- 备份与恢复
+- 支持 Grafana
+- 支持 Kafka
+- 运维工具支持
+
+
+
+## 新增功能
+
+- 持续聚合(Continuous Aggregation)
+- 支持 Prometheus
+- 查询算子 time_bucket_gapfill
+- 查询算子 histogram
+- 时序表功能增强
+- LATERAL语法
+- 写入性能优化
+- 压缩率优化
+
+
+
+## 缺陷修复
+
+数据过期删除偶现 coredump 问题。
+
+copy 数据过程中内存占用过高,疑似内存泄露问题。
+
+guc 参数 timeseries_compression_delay 重新设置后,数据库 reload 出现 coredump 问题。
+
+
+
+## 兼容性
+
+本版本支持以下操作系统及CPU架构组合:
+
+| 操作系统 | CPU架构 |
+| :-------------------- | :------------------------------------------- |
+| CentOS 7.x | X86_64 (Intel,AMD,海光,兆芯) |
+| Redhat 7.x | X86_64 (Intel,AMD,海光,兆芯) |
+| openEuler 20.03LTS | ARM(鲲鹏)、X86_64 (Intel,AMD,海光,兆芯) |
+| 银河麒麟V10 | ARM(鲲鹏)、X86_64 (Intel,AMD,海光,兆芯) |
+| 统信UOS V20-D / V20-E | ARM(鲲鹏)、X86_64 (Intel,AMD,海光,兆芯) |
+| 统信UOS V20-A | X86_64 (Intel,AMD,海光,兆芯) |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/release-notes/release-note.md b/product/zh/docs-uqbar/v2.0/release-notes/release-note.md
new file mode 100644
index 0000000000000000000000000000000000000000..25e4e07213290c915ed5e3a3ad4f67c43117d75d
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/release-notes/release-note.md
@@ -0,0 +1,12 @@
+---
+title: 发行说明
+summary: 发行说明
+author: Guo Huan
+date: 2022-11-22
+---
+
+# 发行说明
+
+| 版本 | 发布日期 | 说明 |
+| ------------------- | ------------- | ------------------------------------------------------------ |
+| [2.0.0](./2.0.0.md) | 2023年6月30日 | Uqbar 2.0.0继承了Uqbar1.1.0的功能,新增了持续聚合功能、Prometheus第三方工具使用说明、聚合类算子相关函数(包括time_bucket_gapfill和histogram)以及LATERAL语法。同时,增强了时序表功能,对写入性能和压缩率进行了优化。 |
diff --git a/product/zh/docs-uqbar/v2.0/retention-policy.md b/product/zh/docs-uqbar/v2.0/retention-policy.md
new file mode 100644
index 0000000000000000000000000000000000000000..7cb7b000c4e0dd94e222f44c28812d71da118ecd
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/retention-policy.md
@@ -0,0 +1,184 @@
+---
+title: 数据保留策略
+summary: 数据保留策略
+author: Guo Huan
+date: 2022-11-23
+---
+
+# 数据保留策略
+
+数据保留策略(Retention Policy)用于管理时序数据的生命周期。时序表使用的数据保留策略决定了时序表中数据的保留时长,超过保留时长的数据会被自动删除。
+
+数据保留策略归属于某个 database,同一个 database 下可以创建多个保留策略,并指定其中一个为默认策略。用户创建时序表时,如果没有显式指定数据保留策略,则会使用该 database 下的默认数据保留策略。
+
+
+
+## 创建数据保留策略
+
+用于在当前 database 下创建一个新的数据保留策略。
+
+数据保留策略包含两个参数:
+
+- duration: 数据保留时间,必选参数。例如设置为 1week,则一周以前的数据会被自动删除。
+
+- chunkGroupDuration: 数据分区粒度,可选参数。时序表中的数据会按照时序表设置的chunkGroupDuration进行分区;对于超出保留时长的数据,也会按照 ChunkGroupDuration 粒度进行删除。如未指定该参数,系统会按照 duration自动指定chunkGroupDuration。
+
+### 语法描述
+
+```sql
+CREATE TIMESERIES POLICY [ IF NOT EXISTS ] policy_name WITH (option = value, [...] )
+```
+
+其中option包含:
+
+- duration:时序数据保留时间,超出这个时间的历史数据自动删除,删除以Chunk Group粒度为单位。取值范围 >= 1h。特殊值0表示数据永久保留,此时时间单位支持second、minute、hour、day、week、month、year。
+
+- chunkGroupDuration:指定时序表的Chunk Group时间跨度,不支持设为特殊值0。
+
+ 如果未指定本参数,系统自动根据duration参数设置合适的Chunk Group Duration参数,规则如下
+
+ - duration < 2天,chunkGroupDuration设置为1小时。chunkGroup 时间对齐到一小时,即chunkGroup的起止时间应该是整点,如 '2020-07-10 00:00:00'、'2020-07-10 01:00:00',而不会出现 '2020-07-10 00:10:00'、'2020-07-10 00:10:10' 这样的时间点。
+ - duration <= 6个月,chunkGroupDuration设置为1天。chunkGroup对齐到天,如 '2020-07-10 00:00:00'、'2020-07-11 00:00:00';
+ - duration > 6个月,chunkGroupDuration设置为7天。chunkGroup对齐到周,即chunkGroup的起始时间对齐到当周的周一。
+ - duration > 3 年,chunkGroupDuration设置为 1个月。chunkGroup对齐到月,即chunkGroup的起始时间对齐到当月的一号。
+
+duration和chunkGroupDuration数字部分的上限为231。
+
+每个 database 下有一个名为 ‘infinity’的默认的数据保留策略,默认策略的 duration=’0s’,表示数据永远不删除,chunkGroupDuration=’1month’。
+
+### 约束
+
+- 新建的数据保留策略名称不能与已存在的保留策略重名。
+
+- duration不能小于chunkGroupDuration。
+
+- duration和chunkGroupDuration格式为'数字+时间单位'。输入的数字如果不是整数,系统会对其向上取整,例如1.2 week会取整为2 weeks。
+
+- duration和chunkGroupDuration不支持负数,duration和chunkGroupDuration支持的最小时间单位是1 hour,如果设置的值小于1 hour 会自动设置为 1 hour。
+
+- duration和chunkGroupDuration支持设置的单位包括:小时(hour)、天(day)、周(week)、月(month)、年(year),不支持其他时间单位。
+
+- 每种时间单位的取值范围限制如下:
+
+ | 单位 | 下限 | 上限 |
+ | ---- | ---- | ---------- |
+ | 年 | 0 | 296533 |
+ | 月 | 0 | 3558399 |
+ | 周 | 0 | 15250284 |
+ | 天 | 0 | 106751991 |
+ | 小时 | 0 | 2147483647 |
+
+### 示例
+
+```sql
+Uqbar=# CREATE TIMESERIES POLICY policy_test WITH (duration = '2 years', chunkGroupDuration='7 days');
+CREATE POLICY
+```
+
+
+
+## 修改数据保留策略
+
+用于修改已存在的数据保留策略。
+
+### 语法描述
+
+```sql
+ALTER TIMESERIES POLICY [IF EXISTS] policy_name actions
+```
+
+其中action包含:
+
+- RENAME TO policy_name,用于修改数据保留策略名,其中 policy_name 用于指定修改后的策略名
+
+- SET (option = value, [...]) ,用于修改数据保留策略的参数
+
+其中option包含:
+
+- { duration, chunkGroupDuration }
+
+### 约束
+
+- 修改后的 duration 和 chunkGroupDuration 需满足新建数据保留策略的约束
+
+### 示例
+
+```sql
+Uqbar=# ALTER TIMESERIES POLICY policy_test SET( chunkGroupDuration='1 month');
+ALTER POLICY
+Uqbar=# ALTER TIMESERIES POLICY policy_test RENAME TO policy_1;
+ALTER POLICY
+```
+
+
+
+## 删除数据保留策略
+
+用于删除已存在的数据保留策略。
+
+### 语法描述
+
+```sql
+DROP TIMESERIES POLICY [IF EXISTS] policy_name
+```
+
+可以用于删除一个或多个timeseries policy。
+
+如果没有IF EXISTS选项,且被删除的策略列表中中有不存在的策略,则执行报错,给出对应的错误提示,不执行任何策略的删除。
+
+如果含有IF EXISTS选项,且被删除的策略列表中有不存在的策略,则执行跳过不存在的策略,并给出对应的提示信息,存在的策略执行删除操作。
+
+### 约束
+
+- 如果数据保留策略正在被时序表使用,无法删除。
+
+- 数据库下的默认策略不能被删除。
+
+### 示例
+
+```sql
+Uqbar=# DROP TIMESERIES POLICY policy1;
+DROP POLICY
+```
+
+
+
+## 设置默认策略
+
+用于修改当前 database 下的默认数据保留策略。
+
+### 语法描述
+
+```sql
+ALTER TIMESERIES POLICY policy_name DEFAULT;
+```
+
+### 示例
+
+```sql
+Uqbar=# ALTER TIMESERIES POLICY policy1 DEFAULT;
+ALTER TIMESERIES POLICY
+```
+
+
+
+## 查询数据保留策略
+
+通过 timeseries_views.policies 视图展示当前已存在的数据保留策略。视图属性参见[timeseries_views.policies](./timeseries-views/timeseries_views.policies.md)。
+
+### 语法描述
+
+```sql
+SELECT * FROM timeseries_views.policies;
+```
+
+### 示例
+
+```sql
+Uqbar=# SELECT * FROM timeseries_views.policies;
+ policyname | duration | chunkgroupduration | default
+------------+----------+--------------------+---------
+ infinity | 00:00:00 | 1 mon | t
+
+(2 rows)
+```
diff --git a/product/zh/docs-uqbar/v2.0/security.md b/product/zh/docs-uqbar/v2.0/security.md
new file mode 100644
index 0000000000000000000000000000000000000000..bcec7e4fc5962ef143ac5caee6e9b225eec86aad
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/security.md
@@ -0,0 +1,29 @@
+---
+title: 安全性
+summary: 安全性
+author: Guo Huan
+date: 2022-11-24
+---
+
+# 安全性
+
+Uqbar时序数据库提供用户管理、认证鉴权、连接加密传输等基本安全能力。
+
+## 三权分立
+
+为了避免系统管理员拥有过度集中的权利带来高风险,可以设置三权分立。将系统管理员的部分权限分立给安全管理员和审计管理员,形成系统管理员、安全管理员和审计管理员三权分立。
+
+- 三权分立后,系统管理员只会对自己作为所有者的对象有权限。
+- 三权分立后,安全管理员拥有创建角色和用户的权限
+- 三权分立后,审计管理员拥有查看和维护数据库审计日志的权限。
+
+## 认证鉴权方式
+
+- 基于主机的认证:服务器端根据客户端的IP地址、用户名及要访问的数据库来查看配置文件从而判断用户是否通过认证。
+- 口令认证:包括远程连接的加密口令认证和本地连接的非加密口令认证。
+- SSL加密:使用OpenSSL(开源安全通信库)提供服务器端和客户端安全连接的环境。
+
+## 加密传输方式
+
+- 支持使用SSL进行安全的TCP/IP连接。
+- 支持使用SSH隧道进行安全的TCP/IP连接。
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/third-party-tools-support/grafana.md b/product/zh/docs-uqbar/v2.0/third-party-tools-support/grafana.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5a0fa0e7e24af3b1063c6230f1ac66d4fadaaf0
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/third-party-tools-support/grafana.md
@@ -0,0 +1,85 @@
+---
+title: Grafana连接时序数据库(MD5模式)
+summary: Grafana连接时序数据库(MD5模式)
+author: Guo Huan
+date: 2023-06-08
+---
+
+# Grafana连接时序数据库(MD5模式)
+
+1. 数据库密码认证方式必须为MD5。
+
+2. 安装grafana。
+
+ ```bash
+ docker run -d -p 3000: 3000 --name grafana grafana/grafana
+ ```
+
+3. 创建测试表并插入数据。
+
+ ```sql
+ CREATE TIMESERIES POLICY IF NOT EXISTS tsbs_policy WITH(duration = '1 year', chunkgroupduration = '1 day');
+ CREATE TIMESERIES TABLE cpu(
+ time timestamp TSTIME,
+ hostname text TSTAG,
+ region text TSTAG,
+ datacenter text TSTAG,
+ rack text TSTAG,
+ os text TSTAG,
+ arch text TSTAG,
+ team text TSTAG,
+ service text TSTAG,
+ service_version text TSTAG,
+ service_environment text TSTAG,
+ usage_user float,
+ usage_system float,
+ usage_idle float,
+ usage_nice float,
+ usage_iowait float,
+ usage_irq float,
+ usage_softirq float,
+ usage_steal float,
+ usage_guest float,
+ usage_guest_nice float
+ ) POLICY tsbs_policy;
+ CREATE INDEX ON cpu USING btree(hostname, time desc) LOCAL;
+ ```
+
+4. 配置Grafana。
+
+ a. 增加数据源。
+
+ 
+
+ 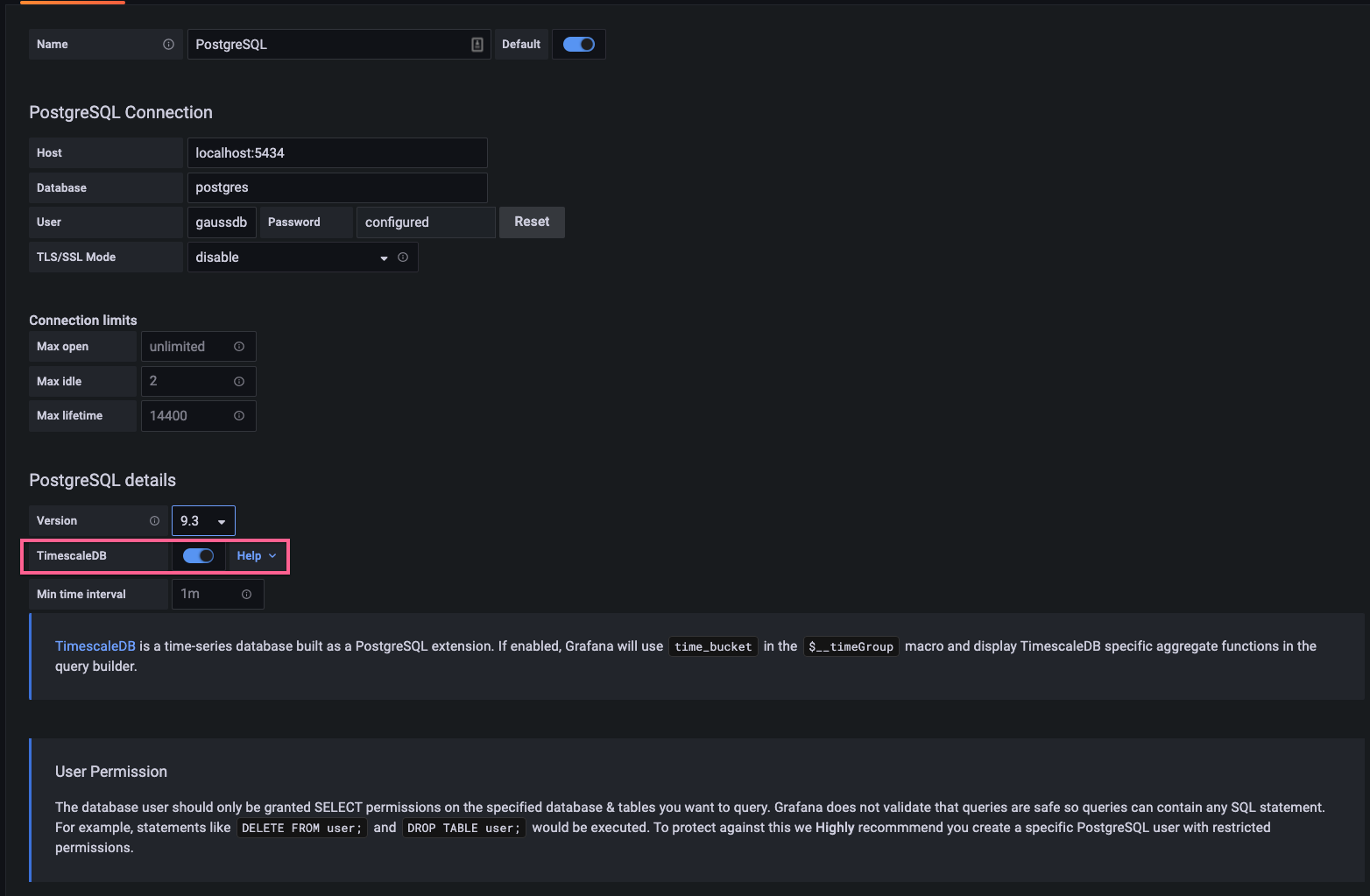
+
+ b. 增加dashboard。
+
+ 
+
+ 点击 “Add a new panel”,Data source 选择数据源。
+
+ 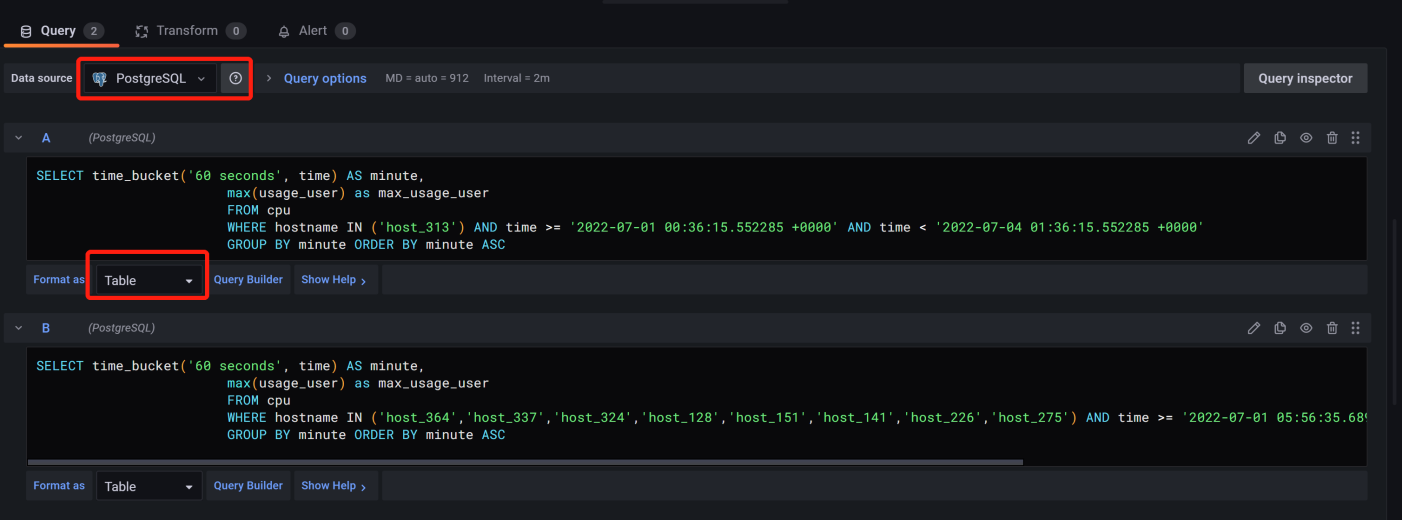
+
+ c. 保证生成的SQL可以运行。
+
+ ```sql
+ SELECT
+ time_bucket('60 seconds', time) AS minute,
+ max(usage_user) AS max_usage_user
+ FROM cpu
+ WHERE
+ hostname IN ('host_313') AND time >= '2022-01-01 00:36:15.552285 +0000' AND time < '2022-07-04 01:36:15.552285 +000' GROUP BY minute ORDER BY minute ASC;
+
+ SELECT
+ time_bucket('60 seconds', time) AS minute,
+ max(usage_user) AS max_usage_user
+ FROM cpu
+ WHERE
+ hostname IN ('host_364', 'host_337', 'host_128', 'host_151', 'host_141', 'host_226', 'host_275') AND time >= '2022-07-01 05:56:35.685235 +0000' AND time <= '2022-07-05 00:23:44.331213 +0000'
+ GROUP BY minute ORDER BY minute ASC;
+ ```
+
+ d. 查看执行结果。
+
+ 
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/third-party-tools-support/kafka.md b/product/zh/docs-uqbar/v2.0/third-party-tools-support/kafka.md
new file mode 100644
index 0000000000000000000000000000000000000000..1b230f37077c4578b7964501684f957b1d361ca6
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/third-party-tools-support/kafka.md
@@ -0,0 +1,10 @@
+---
+title: Kafka
+summary: Kafka
+author: Guo Huan
+date: 2023-06-08
+---
+
+# Kafka
+
+详情请参阅[从Kafka消费数据](../data-write/data-writing-method/Kafka-supported-for-importing-data-to-table.md)。
diff --git a/product/zh/docs-uqbar/v2.0/third-party-tools-support/prometheus.md b/product/zh/docs-uqbar/v2.0/third-party-tools-support/prometheus.md
new file mode 100644
index 0000000000000000000000000000000000000000..5231a088a50197569aa01e949cc5245d6454e37c
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/third-party-tools-support/prometheus.md
@@ -0,0 +1,154 @@
+---
+title: Prometheus使用说明
+summary: Prometheus使用说明
+author: Guo Huan
+date: 2023-06-08
+---
+
+# Prometheus使用说明
+
+## 概述
+
+监控数据支持从Prometheus写入时序表。uqbar-prometheus-adapter为联系Prometheus与Uqbar之间的中间件,基于Prometheus对remote storage支持,外部如Grafana的PromSQL查询请求,监控设备上采集到的数据写入请求,会被中间件uqbar-prometheus-adapter转换为向Uqbar执行的SQL语句,将监控数据写入数据库或从数据库获取查询结果返回给Prometheus。
+
+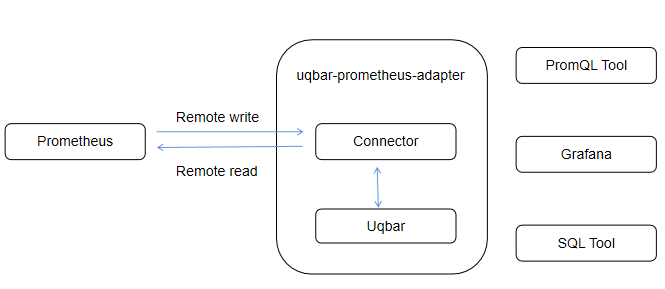
+
+## 安装流程
+
+访问 [https://prometheus.io/download/](https://prometheus.io/download/) 下载Prometheus。
+
+
+
+## 修改Prometheus配置文件
+
+设置配置文件prometheus.yaml,增加远端存储配置项,最简配置如下:
+
+```
+global:
+scrape_interval: 15s
+evaluation_interval: 15s
+alerting:
+alertmanagers:
+ - static_configs:
+ - targets:
+rule_files:
+scrape_configs:
+ - job_name: "prometheus"
+scheme : "http"
+static_configs:
+ - targets: [ "localhost:9090"]
+remote_write:
+ - url: " http://localhost:9201/write"
+remote_read:
+ - url: "http://localhost:9201/read "
+read_recent: true
+```
+
+上述配置为不使用TLS,不做auth校验,对于使用TLS示例如下:
+
+```
+global:
+scrape_interval: 15s
+evaluation_interval: 15s
+alerting:
+alertmanagers:
+- static_configs:
+- targets:
+rule_files:
+scrape_configs:
+- job_name: "prometheus"
+scheme : "http"
+static_configs:
+- targets: [ "localhost:9090"]
+remote_write:
+- url: " https://localhost:9201/write"
+basic_auth:
+username: "hello"
+password: "world"
+# =====================
+# authorization:
+# type: "Bearer"
+# credentials: "QWxhZGRpbjpvcGVuIHNlc2FtZQ"
+# =====================
+tls_config:
+ca_file: "xx/ca.crt"
+cert_file: "xx/server.pem"
+key_file: "xx/server.key"
+remote_read:
+- url: "https://localhost:9201/read"
+read_recent: true
+basic_auth:
+username: "hello"
+password: "world"
+# =====================
+# authorization:
+# type: "Bearer"
+# credentials: "QWxhZGRpbjpvcGVuIHNlc2FtZQ"
+# =====================
+tls_config:
+ca_file: "xx/ca.crt"
+cert_file: "xx/server.pem"
+key_file: "xx/server.key"
+```
+
+请注意remote_read与_remote_write中url参数为https才会使得Prometheus的tsdb组件向remote storage发送https请求,故使用TLS请将url参数设置正确,否则可能会出现向HTTPS服务器发送HTTP请求而无法服务的问题。
+
+## 启动Prometheus
+
+启动参数示例如下:
+
+```
+nohup ./prometheus --config.file=prometheus.yml &
+```
+
+uqbar-prometheus-adapter自身也存在可配置参数,可以在启动服务时通过--xx=xx指定,具体参数与作用见下表。
+
+| 参数名 | 描述 |
+| -------------------------- | ------------------------------------------------------------ |
+| config | 配置文件路径 |
+| web-auth-username | basic auth的用户名 |
+| web-auth-password | basic auth的密码 |
+| web-auth-password-file | 使用文件存储basic auth密码的文件路径 |
+| web-auth-bearer-token | bearer token |
+| web-auth-bearer-token-file | 使用文件存储bearer token的文件路径 |
+| web-listen-address | web服务监听的地址,默认使用9201端口 |
+| auth-tls-cert-file | TLS 证书文件 |
+| auth-tls-key-file | TLS key文件 |
+| pg-commit-secs | 每隔多少秒写一次数据库,默认15 |
+| pg-commit-rows | 每积累多少行写一次数据库 |
+| pg-threads | 向数据库写入的协程数 |
+| parser-threads | 解析prometheus的metrics数据协程数 |
+| db-connurl | 数据库连接字符串,不为空直接使用;为空程序使用其他db参数自行构造 |
+| db-app-name | 连接app name |
+| db-ssl-mode | ssl 模式默认allow |
+| db-conn-timeout | 超时时间 |
+| db-user | 用户名 |
+| db-password | 密码 |
+| db-host | 数据库host |
+| db-port | 数据库服务端口 |
+| db-database | database名 |
+| db-ssl-cert | 与数据库连接使用的ssl 证书文件 |
+| db-ssl-key | 与数据库连接使用的ssl key文件 |
+| db-ssl-ca | 与数据库连接使用的CA文件 |
+
+最简启动命令如:
+
+```
+./uqbar-prometheus-adapter --db-host="localhost" --db-user=world --db-password="Test@123" --db-port=17680 --db-database="postgres"
+```
+
+本工具也支持使用配置文件启动,使用方法为**--config=xx.yaml**
+
+配置文件使用yaml格式,但要求为扁平化层级结构,所有参数都处于同一层级。命令行指定参数与配置文件指定参数重复无法启动并提示。
+
+## 连接 Uqbar 时序数据库
+
+1. 配置Prometheus监控任务与远端存储。
+
+2. 启动uqbar-prometheus-adapter工具,数据库密码认证方式必须为MD5。
+
+3. 数据成功写入Uqbar。
+
+4. 可通过Prometheus web UI 查询已写入数据([http://localhost:9090/graph](http://localhost:9090/graph))。
+
+ 
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/third-party-tools-support/third-party-tools-support.md b/product/zh/docs-uqbar/v2.0/third-party-tools-support/third-party-tools-support.md
new file mode 100644
index 0000000000000000000000000000000000000000..4e8afd55eb67c9fd6739c555999acee9ce2cc242
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/third-party-tools-support/third-party-tools-support.md
@@ -0,0 +1,12 @@
+---
+title: 三方工具支持
+summary: 三方工具支持
+author: Guo Huan
+date: 2023-06-10
+---
+
+# 第三方工具支持
+
++ **[Kafka](./kafka.md)**
++ **[Grafana](./grafana.md)**
++ **[Prometheus](./prometheus.md)**
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/time-series-table-management.md b/product/zh/docs-uqbar/v2.0/time-series-table-management.md
new file mode 100644
index 0000000000000000000000000000000000000000..99d918cdbecc6487af7b776cb5bee6d8317d24c0
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/time-series-table-management.md
@@ -0,0 +1,97 @@
+---
+title: 时序表管理
+summary: 时序表管理
+author: zhang cuiping
+date: 2022-12-02
+---
+
+# 时序表管理
+
+时序表是时序数据的载体,与关系表在关系模型中的意义相同。使用时先创建数据库,再创建时序表,然后才能写入或查询时序数据。
+
+本章节主要介绍时序表管理,包括时序表的创建、修改、删除,以及查看当前 database 下的时序表视图。
+
+
+
+## 创建时序表
+
+用于在当前 database 下创建一个新的时序表。
+
+创建时序表语法如下:
+
+```sql
+CREATE TIMESERIES TABLE [ IF NOT EXISTS ] table_name
+( column_name data_type [ tslabel ] [ DEFAULT default_expr ] [, ...] [ COLLATE collation ] )
+[ POLICY policy_name ]
+[ TABLESPACE tablespace_name ];
+```
+
+更多信息请参见[CREATE TIMESERIES TABLE](./uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md)。
+
+
+
+## 修改时序表
+
+用于修改一张已存在的时序表。可修改内容包括时序表的列名、列默认值、时序表的数据保留策略、所有者,以及时序表的表空间。
+
+修改时序表的语法如下:
+
+```sql
+ALTER TIMESERIES TABLE [ IF EXISTS ] tablename_name actions
+```
+
+更多信息请参见[ALTER TIMESERIES TABLE](./uqbar-sql-syntax/ALTER-TIMESERIES-TABLE.md)。
+
+
+
+## 删除时序表
+
+用于删除一张或多张已存在的时序表。
+
+删除时序表语法如下:
+
+```sql
+DROP TIMESERIES TABLE [ IF EXISTS ] table_name [, table1_name ...];
+```
+
+更多信息请参见[DROP TIMESERIES TABLE](./uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md)。
+
+
+
+## 时序表视图
+
+为方便用户使用,系统定义了一组时序表相关的视图。
+
+timeseries_views.tstable,详细内容参见[timeseries_views.tstable](./timeseries-views/timeseries_views.tstable.md)。
+
+用于展示当前 database 下的所有时序表。
+
+使用示例:
+
+```sql
+--查看schema为timeseries_views下的所有时序表。
+Uqbar=# SELECT * FROM timeseries_views.tstable;
+ schemaname | tablename | timecolname | tagcol | tspolicy
+------------+-----------+-------------+-----------------+----------
+ public | weather | time | {city,location} | infinity
+(1 rows)
+```
+
+timeseries_views.tschunkgroup,详细内容参见[timeseries_views.tschunkgroup](./timeseries-views/timeseries_views.tschunkgroup.md)。
+
+用于展示当前 database 下所有时序表的 chunkgroup。
+
+使用示例:
+
+```sql
+--查看时序表weather的ChunkGroup视图。
+Uqbar=# SELECT tablename, chunkgroupname, chunkgroupduration, start_time, end_time FROM timeseries_views.tschunkgroup WHERE tablename= 'weather';
+ tablename | chunkgroupname | chunkgroupduration | start_time | end_time
+--------------------+--------------------+----------------------+----------------------+----------------
+ weather | p_1_1 | 7 days | 2022-6-16 00:00:00 | 2022-6-23 00:00:00
+ weather | p_1_2 | 7 days | 2022-6-16 00:00:00 | 2022-6-23 00:00:00
+ weather | p_2_1 | 7 days | 2022-6-23 00:00:00 | 2022-6-30 00:00:00
+ weather | p_2_2 | 7 days | 2022-6-23 00:00:00 | 2022-6-30 00:00:00
+
+(4 rows)
+```
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries-views.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries-views.md
new file mode 100644
index 0000000000000000000000000000000000000000..273219492889633966c2561c26254462ec94af4e
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries-views.md
@@ -0,0 +1,16 @@
+---
+title: 时序视图
+summary: 时序视图
+author: Guo Huan
+date: 2023-06-08
+---
+
+# 时序视图
+
++ **[timeseries_views.bgw_job](./timeseries_views.bgw_job.md)**
++ **[timeseries_views.compression_chunkgroup](./timeseries_views.compression_chunkgroup.md)**
++ **[timeseries_views.compression_table](./timeseries_views.compression_table.md)**
++ **[timeseries_views.continuous_aggregation](./timeseries_views.continuous_aggregation.md)**
++ **[timeseries_views.policies](./timeseries_views.policies.md)**
++ **[timeseries_views.tschunkgroup](./timeseries_views.tschunkgroup.md)**
++ **[timeseries_views.tstable](./timeseries_views.tstable.md)**
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.bgw_job.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.bgw_job.md
new file mode 100644
index 0000000000000000000000000000000000000000..517b3457f7caf4daaef12c9e901500ae793bd2f3
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.bgw_job.md
@@ -0,0 +1,23 @@
+---
+title: timeseries_views.bgw_job
+summary: timeseries_views.bgw_job
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.bgw_job
+
+Uqbar提供后台任务视图,供用户查看定期删除、压缩等后台任务的运行状况。timeseries_views这个schema下提供了bgw_job视图,供用户查看所有时序表策略。
+
+**表1** bgw_job视图属性
+
+| 字段 | 类型 | 描述 |
+| :------------ | :-------- | :----------------------------------------------------------- |
+| objname | name | 任务所属的时序表的名字 |
+| type | name | 任务的类型(r = retension, c = compression, s = continuous aggregation) |
+| status | name | 当前任务的执行状态。(running, finished, failed, disable) |
+| interval | text | 用来计算下次作业运行时间的时间表达式,可以是interval表达式,也可以是sysdate加上一个numeric值(例如:sysdate+1.0/24)。如果为空值或字符串"null"表示只执行一次,执行后Job状态STATUS变成’d’不再执行。 |
+| next_run_date | timestamp | 任务下次执行的时间,精确到毫秒 |
+| last_run_date | timestamp | 任务上次执行的时间,精确到毫秒 |
+| last_end_date | timestamp | 任务上次结束的时间,精确到毫秒 |
+| failure_count | smallint | 失败计数,任务连续失败16次后不再执行 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.compression_chunkgroup.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.compression_chunkgroup.md
new file mode 100644
index 0000000000000000000000000000000000000000..0078be4ee41ed3612594aea65b4ccb25d8ff3568
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.compression_chunkgroup.md
@@ -0,0 +1,21 @@
+---
+title: timeseries_views.compression_chunkgroup
+summary: timeseries_views.compression_chunkgroup
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.compression_chunkgroup
+
+timeseries_views模式下的compression_chunkgroup视图,供用户查看所有时序表分片的压缩率。after_compression_size和compression_ratio仅在chunkgroup被压缩后非空。
+
+**表1** compression_chunkgroup视图属性
+
+| 字段 | 类型 | 描述 |
+| :---------------------- | :----- | :--------------------------------- |
+| schemaname | name | 时序表的模式名。 |
+| tablename | name | 时序表的表名。 |
+| chunkgroupname | name | 时序表的分片名。 |
+| before_compression_size | bigint | 时序表分片组压缩前大小,单位为KB。 |
+| after_compression_size | bigint | 时序表分片组压缩后大小,单位为KB。 |
+| compression_ratio | float | 时序表分片组的压缩率。 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.compression_table.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.compression_table.md
new file mode 100644
index 0000000000000000000000000000000000000000..6473ad3f8c421b212bb2ab52426981ea287a55d7
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.compression_table.md
@@ -0,0 +1,20 @@
+---
+title: timeseries_views.compression_table
+summary: timeseries_views.compression_table
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.compression_table
+
+timeseries_views模式下的compression_table视图,供用户查看所有时序表的压缩率。after_compression_size和compression_ratio仅在时序表存在至少一个被压缩的chunkgroup时非空。当存在至少一个chunkGroup被压缩后,after_compression_size为未压缩的chunkGroup的before_compression_size与被压缩的chunkGroup的after_compression_size之和。
+
+**表1** compression_table视图属性
+
+| 字段 | 类型 | 描述 |
+| :---------------------- | :----- | :----------------------------- |
+| schemaname | name | 时序表的模式名。 |
+| tablename | name | 时序表的表名。 |
+| before_compression_size | bigint | 时序表压缩前大小, 单位为KB。 |
+| after_compression_size | bigint | 时序表压缩后大小, 单位为KB。 |
+| compression_ratio | float | 时序表压缩率(保留两位小数)。 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.continuous_aggregation.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.continuous_aggregation.md
new file mode 100644
index 0000000000000000000000000000000000000000..df15c50c01cf0866bc4cca9dd95f4d52d227794a
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.continuous_aggregation.md
@@ -0,0 +1,25 @@
+---
+title: timeseries_views.continuous_aggregation
+summary: timeseries_views.continuous_aggregation
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.continuous_aggregation
+
+timeseries_views.continuous_aggregation视图提供持续聚合的信息。
+
+**表1** timeseries_views.continuous_aggregation视图字段
+
+| 名称 | 类型 | 描述 |
+| ----------------- | --------------------------- | ------------------------------------------------------------ |
+| schema | name | 持续聚合所属schema |
+| caname | name | 持续聚合的名字 |
+| resample_interval | text | 持续聚合自动重采样的间隔 |
+| job_id | bigint | 持续聚合后台任务的job_id |
+| status | name | 持续聚合后台任务当前任务状态(running,finished,failed,disable) |
+| last_run_date | timestamp without time zone | 持续聚合后台任务的上次执行时间 |
+| next_run_date | timestamp without time zone | 持续聚合后台任务的下次执行时间 |
+| query | text | 持续聚合采样时使用的query语句 |
+| failure_count | smallint | 失败计数,持续聚合任务连续失败16次后不再执行 |
+| failure_msg | text | 持续聚合后台任务最近一次失败信息,若无失败信息,为空 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.policies.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.policies.md
new file mode 100644
index 0000000000000000000000000000000000000000..8258cca4f571c949a17e80e7178735238d2f7bb3
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.policies.md
@@ -0,0 +1,19 @@
+---
+title: timeseries_views.policies
+summary: timeseries_views.policies
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.policies
+
+Uqbar支持查看指定数据库下的所有保留策略。timeseries_views这个schema下提供了policies视图,供用户查看所有时序表策略。
+
+**表1** policies视图属性
+
+| 字段 | 类型 | 描述 |
+| :----------------- | :------- | :--------------------------------------------------------- |
+| policyname | name | 时序策略名 |
+| duration | interval | 时序表数据的保留时长,特殊值00:00:00表示时序表数据永久保留 |
+| chunkGroupDuration | interval | 时序表的时间分组跨度 |
+| default | bool | 时序策略是否为默认策略 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.tschunkgroup.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.tschunkgroup.md
new file mode 100644
index 0000000000000000000000000000000000000000..97c7111d958642238daacf36807a01908bcc0014
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.tschunkgroup.md
@@ -0,0 +1,22 @@
+---
+title: timeseries_views.tschunkgroup
+summary: timeseries_views.tschunkgroup
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.tschunkgroup
+
+用户可查看一个时序表的ChunkGroup列表视图。时序表按照时间范围被拆分为多个分片组(ChunkGroup),以分片组为单位进行过期删除,以便于对时序数据进行高效过期删除。
+
+**表1** tschunkgroup视图属性
+
+| 字段 | 类型 | 描述 |
+| :----------------- | :------- | :--------------------------------------- |
+| schemaname | name | 时序表的模式名。 |
+| tablename | name | 时序表的表名。 |
+| chunkGroupName | name | 时序表分片组名。 |
+| chunkGroupDuration | interval | 时序表分片的时间跨度。 |
+| start_time | text | 时序表分片组时间范围的左边界(包含)。 |
+| end_time | text | 时序表分片组时间范围的右边界(不包含)。 |
+| compressed | bool | 时序表分片组是否被压缩。 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.tstable.md b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.tstable.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7d5cd6b03545547bbd7870fa6a46a1a0e52cc01
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/timeseries-views/timeseries_views.tstable.md
@@ -0,0 +1,20 @@
+---
+title: timeseries_views.tstable
+summary: timeseries_views.tstable
+author: Guo Huan
+date: 2022-11-24
+---
+
+# timeseries_views.tstable
+
+用户可查看当前数据库下的所有时序表。
+
+**表1** tstable视图属性
+
+| 字段 | 类型 | 描述 |
+| :---------- | :----- | :--------------------- |
+| schemaname | name | 时序表的模式名。 |
+| tablename | name | 时序表的表名。 |
+| timecolname | name | 时序表中时间列的列名。 |
+| tagcol | name[] | 时序表中tag列的列名。 |
+| tspolicy | name | 时序表数据表的策略名。 |
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/toc.md b/product/zh/docs-uqbar/v2.0/toc.md
new file mode 100644
index 0000000000000000000000000000000000000000..76d3feb6c8b92b400a4616456447f672f513306d
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/toc.md
@@ -0,0 +1,65 @@
+
+
+
+# Uqbar Documentation 2.0.0
+
+## Documentation List
+
++ [Uqbar简介](/overview.md)
++ [发行说明](./release-notes/release-note.md)
+ + [Uqbar 2.0.0](./release-notes/2.0.0.md)
++ [Uqbar安装](/ptk-based-installation.md)
++ [Uqbar管理](/uqbar-management.md)
++ [数据保留策略](/retention-policy.md)
++ [时序表管理](/time-series-table-management.md)
++ [时序数据写入](/data-write/data-write-introduction.md)
+ + [时序数据接入方式](/data-write/data-writing-method/data-writing-method.md)
+ + [支持标准SQL写入时序表](/data-write/data-writing-method/SQL-supported-for-importing-data-to-table.md)
+ + [通过驱动写入时序数据](/data-write/data-writing-method/driver-supported-for-importing-data-to-table.md)
+ + [从Kafka消费数据](/data-write/data-writing-method/Kafka-supported-for-importing-data-to-table.md)
+ + [时序数据写入模型](/data-write/data-writing-model/data-writing-model.md)
+ + [单值模型和多值模型](/data-write/data-writing-model/single-field-and-multiple-field-model.md)
+ + [乱序写入](/data-write/data-writing-model/data-imported-out-of-order.md)
+ + [无时间值写入](/data-write/data-writing-model/data-imported-without-the-time-field.md)
++ [数据压缩](/data-compression.md)
++ [数据删除](/expired-deletion.md)
++ [数据查询](./query-data/query-data.md)
+ + [聚合类算子](./query-data/aggregation-operator/aggregation-operator.md)
+ + [time_bucket()](./query-data/aggregation-operator/time-bucket.md)
+ + [time_bucket_gapfill()](./query-data/aggregation-operator/time-bucket-gapfill.md)
+ + [histogram()](./query-data/aggregation-operator/histogram.md)
+ + [选择类算子](./query-data/selection-operator/selection-operator.md)
+ + [first()/last()](./query-data/selection-operator/first-last.md)
+ + [转换类算子](./query-data/conversion-operator.md)
+ + [Join查询](./query-data/join-query.md)
+ + [LATERAL关键字](./query-data/lateral-keyword.md)
+ + [索引](./query-data/index.md)
++ [持续聚合](./continuous-aggregation.md)
++ [时序视图](/timeseries-views/timeseries-views.md)
+ + [timeseries_views.bgw_job](/timeseries-views/timeseries_views.bgw_job.md)
+ + [timeseries_views.compression_chunkgroup](/timeseries-views/timeseries_views.compression_chunkgroup.md)
+ + [timeseries_views.compression_table](/timeseries-views/timeseries_views.compression_table.md)
+ + [timeseries_views.continuous_aggregation](/timeseries-views/timeseries_views.continuous_aggregation.md)
+ + [timeseries_views.policies](/timeseries-views/timeseries_views.policies.md)
+ + [timeseries_views.tschunkgroup](/timeseries-views/timeseries_views.tschunkgroup.md)
+ + [timeseries_views.tstable](/timeseries-views/timeseries_views.tstable.md)
++ [集群管理](/cluster-management.md)
++ [备份恢复](/backup-restore.md)
++ [安全性](/security.md)
++ [GUC参数](/guc-parameters.md)
++ [SQL语法参考](./uqbar-sql-syntax/uqbar-sql-syntax.md)
+ + [ALTER CONTINUOUS AGGREGATION](/uqbar-sql-syntax/ALTER-CONTINUOUS-AGGREGATION.md)
+ + [ALTER TIMESERIES POLICY](/uqbar-sql-syntax/ALTER-TIMESERIES-POLICY.md)
+ + [ALTER TIMESERIES TABLE](/uqbar-sql-syntax/ALTER-TIMESERIES-TABLE.md)
+ + [COMPRESS TIMESERIES](/uqbar-sql-syntax/COMPRESS-TIMESERIES.md)
+ + [CREATE CONTINUOUS AGGREGATION](./uqbar-sql-syntax/CREATE-CONTINUOUS-AGGREGATION.md)
+ + [CREATE TIMESERIES POLICY](/uqbar-sql-syntax/CREATE-TIMESERIES-POLICY.md)
+ + [CREATE TIMESERIES TABLE](/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md)
+ + [DROP CONTINUOUS AGGREGATION](./uqbar-sql-syntax/DROP-CONTINUOUS-AGGREGATION.md)
+ + [DROP TIMESERIES POLICY](/uqbar-sql-syntax/DROP-TIMESERIES-POLICY.md)
+ + [DROP TIMESERIES TABLE](/uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md)
++ [第三方工具支持](/third-party-tools-support/third-party-tools-support.md)
+ + [Kafka](./third-party-tools-support/kafka.md)
+ + [Grafana](./third-party-tools-support/grafana.md)
+ + [Prometheus](./third-party-tools-support/prometheus.md)
++ [术语](/glossary.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-management.md b/product/zh/docs-uqbar/v2.0/uqbar-management.md
new file mode 100644
index 0000000000000000000000000000000000000000..e6d6c3e27f88f62ea4db30922c5474d71f3ac317
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-management.md
@@ -0,0 +1,97 @@
+---
+title: 管理Uqbar
+summary: 管理Uqbar
+author: Zhang Cuiping
+date: 2022-12-02
+---
+
+# 管理Uqbar
+
+通过PTK安装Uqbar数据库后,用户可对数据库进行相关操作,包括启动、停止、重启数据库以及查看数据库状态。
+
+> 说明:下面以集群uqbar110为例。
+
+## 启动数据库集群
+
+在安装完数据库集群后,PTK 默认会将数据库集群启动。
+
+此外,可通过 `cluster start` 指令启动集群,需指定集群的集群名称。
+
+```shell
+# ptk cluster -n uqbar110 start
+INFO[2022-12-02T10:22:56.957] operation: start
+INFO[2022-12-02T10:22:56.957] ========================================
+INFO[2022-12-02T10:22:56.957] start db [172.16.0.127:27009] ...
+INFO[2022-12-02T10:22:58.058] start db [172.16.0.127:27009] successfully
+INFO[2022-12-02T10:22:58.203] ========================================
+INFO[2022-12-02T10:22:58.203] start cluster successfully
+```
+
+同时,PTK 默认会启动集群内所有实例,PTK 也支持指定单个实例启动,需指定实例的IP:
+
+```shell
+# ptk cluster -n uqbar110 start -H 192.168.122.101
+```
+
+## 停止数据库集群
+
+如果想要停止数据库集群,可以通过 `cluster stop` 指令,默认会停止集群内所有实例:
+
+```bash
+# ptk cluster -n uqbar110 stop
+INFO[2022-12-02T10:16:28.092] operation: stop
+INFO[2022-12-02T10:16:28.092] ========================================
+INFO[2022-12-02T10:16:28.092] stop db [172.16.0.127:27009] ...
+INFO[2022-12-02T10:16:29.157] stop db [172.16.0.127:27009] successfully
+INFO[2022-12-02T10:16:29.157] ========================================
+INFO[2022-12-02T10:16:29.158] stop successfully
+```
+
+如果想要停止集群内某个实例,可通过 `-H` 指定实例的IP,例如:
+
+```bash
+ptk cluster -n uqbar110 stop -H 192.168.122.101
+```
+
+## 重启数据库集群
+
+重启集群的操作,本质上是先停止数据库,再启动数据库的组合操作。
+
+可通过 `cluster restart` 指令来实现:
+
+```shell
+# ptk cluster -n uqbar110 restart
+INFO[2022-12-02T10:01:09.013] operation: stop
+INFO[2022-12-02T10:01:09.014] ========================================
+INFO[2022-12-02T10:01:09.014] stop db [172.16.0.127:27009] ...
+INFO[2022-12-02T10:01:10.079] stop db [172.16.0.127:27009] successfully
+INFO[2022-12-02T10:01:10.079] ========================================
+INFO[2022-12-02T10:01:10.079] stop successfully
+
+INFO[2022-12-02T10:01:10.080] operation: start
+INFO[2022-12-02T10:01:10.080] ========================================
+INFO[2022-12-02T10:01:10.080] start db [172.16.0.127:27009] ...
+INFO[2022-12-02T10:01:11.185] start db [172.16.0.127:27009] successfully
+INFO[2022-12-02T10:01:11.329] ========================================
+INFO[2022-12-02T10:01:11.329] start cluster successfully
+```
+
+## 查看数据库状态
+
+可通过-n指定集群名称或通过-f指定配置文件来查看数据库状态:
+
+**注意**:如果通过配置文件查询数据库状态,需要在配置文件所在目录下执行查询命令。
+
+```bash
+[root@hostname]# ptk cluster status -n uqbar110
+[ Cluster State ]
+database_version : Uqbar-Uqbar
+cluster_name : uqbar110
+cluster_state : Normal
+current_az : AZ_ALL
+
+[ Datanode State ]
+ id | ip | port | user | instance | db_role | state
+-------+--------------+-------+-------+----------+---------+---------
+ 6001 | 172.16.0.245 | 27000 | omm01 | dn_6001 | Normal | Normal
+```
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-CONTINUOUS-AGGREGATION.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-CONTINUOUS-AGGREGATION.md
new file mode 100644
index 0000000000000000000000000000000000000000..5cc37a6fd9fdbab8cdec53d1cbc905335b49fb37
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-CONTINUOUS-AGGREGATION.md
@@ -0,0 +1,62 @@
+---
+title: ALTER CONTINUOUS AGGREGATION
+summary: ALTER CONTINUOUS AGGREGATION
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# ALTER CONTINUOUS AGGREGATION
+
+## 功能描述
+
+修改当前数据库中已存在的一个持续聚合。
+
+## 语法格式
+
+```
+ALTER CONTINUOUS AGGREGATION [IF EXISTS] conagg_name action
+```
+
+其中action为:
+
+```
+ALTER EVERY TO new_resample_interval
+| ALTER START_OFFSET TO new_start_offset
+| ALTER END_OFFSET TO new_end_offset
+```
+
+## 参数说明
+
+- **conagg_name**
+
+ 修改的持续聚合名,可包含schema部分。
+
+ > **注意**:不支持指定tablespace部分。
+
+- **new_resample_interval**
+
+ 持续聚合新的重采样间隔。
+
+ > **说明**:修改重采样间隔,将以当前时间+新的重采样间隔并以新的重采样间隔时间单位向前对齐作为后台任务的下一次启动时间。若新的重采样间隔为'0s',则持续聚合后台任务的下次启动时间将被更新为'infinity'(timestamp类型的最大值,代表后台任务暂停启动)。并以持续聚合原resample_time-原持续聚合重采样间隔+新持续聚合采样间隔作为持续聚合新的resample_time。
+
+- **new_start_offset**
+
+ 持续聚合新的采样窗口开始偏移。
+
+- **new_end_offset**
+
+ 持续聚合新的采样窗口结束偏移。
+
+ > **注意**:每次仅能修改一项参数。且新的参数值必须满足创建持续聚合时的约束条件。
+
+## 示例
+
+```sql
+Uqbar=# ALTER CONTINUOUS aggregation IF EXISTS weather_ca ALTER EVERY
+TO '1 hour';
+ALTER CONTINUOUS AGGREGATION
+```
+
+## 相关页面
+
+[CREATE CONTINUOUS AGGREGATION](./CREATE-CONTINUOUS-AGGREGATION.md),[DROP CONTINUOUS AGGREGATION](./DROP-CONTINUOUS-AGGREGATION.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-TIMESERIES-POLICY.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-TIMESERIES-POLICY.md
new file mode 100644
index 0000000000000000000000000000000000000000..d974b206cbd12093c6dbba149a71eeb70c9e603a
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-TIMESERIES-POLICY.md
@@ -0,0 +1,47 @@
+---
+title: ALTER TIMESERIES POLICY
+summary: ALTER TIMESERIES POLICY
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# ALTER TIMESERIES POLICY
+
+## 功能描述
+
+用于修改已存在的数据保留策略。
+
+## 注意事项
+
+- 修改后的 duration 和 chunkGroupDuration 需满足新建数据保留策略的约束
+
+## 语法格式
+
+```
+ALTER TIMESERIES POLICY [IF EXISTS] policy_name actions
+```
+
+其中action包含:
+
+- RENAME TO policy_name,用于修改数据保留策略名,其中 policy_name 用于指定修改后的策略名
+- SET (option = value, [...]) ,用于修改数据保留策略的参数
+- DEFAULT,用于设置默认策略
+
+其中option包含:
+
+- { duration, chunkGroupDuration }
+
+## 示例
+
+```sql
+Uqbar=# ALTER TIMESERIES POLICY policy_test SET( chunkGroupDuration='1 month');
+ALTER POLICY
+Uqbar=# ALTER TIMESERIES POLICY policy_test RENAME TO policy_1;
+ALTER POLICY
+Uqbar=# ALTER TIMESERIES POLICY policy1 DEFAULT;
+ALTER TIMESERIES POLICY
+```
+
+## 相关链接
+
+[CREATE TIMESERIES POLICY](./CREATE-TIMESERIES-POLICY.md),[DROP TIMESERIES POLICY](./DROP-TIMESERIES-POLICY.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-TIMESERIES-TABLE.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-TIMESERIES-TABLE.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb7fa439fcf5f30c69ae39966d3fc869faf093d1
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/ALTER-TIMESERIES-TABLE.md
@@ -0,0 +1,72 @@
+---
+title: ALTER TIMESERIES TABLE
+summary: ALTER TIMESERIES TABLE
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# ALTER TIMESERIES TABLE
+
+## 功能描述
+
+修改时序表,包括修改表的列名、列默认值、数据保留策略以及所有者,同时可设置时序表所属的表空间。
+
+## 注意事项
+
+- 除了语法中明确支持的可修改项,不支持修改其他选项。
+- 同时只能修改一个选项。
+- 时序表不支持重命名表名,执行 rename 会提示错误。
+
+## 语法格式
+
+修改时序表。
+
+```
+ALTER TIMESERIES TABLE [ IF EXISTS ] tablename_name actions
+```
+
+- 其中action包含:
+
+ ```
+ | column_clause
+ | ALTER POLICY TO policy_name
+ | OWNER TO new_owner
+ | SET SCHEMA new_schema
+ ```
+
+- 其中column_clause包含:
+
+ ```
+ | RENAME [ COLUMN ] column_name TO new_column_name
+ | ALTER [ COLUMN ] column_name { SET DEFAULT expression | DROP DEFAULT }
+ ```
+
+## 参数说明
+
+- **table_name**
+
+ 指定时序表的名称。
+
+- **policy_name**
+
+ 指定时序表的策略名。系统为每个数据库提供一个默认策略,用户也可以重新设置某个策略为默认策略,创建时序表时如果未指定具体策略,则使用所属数据库的默认数据保留策略。
+
+- **new_owner**
+
+ 指定时序表的所有者。
+
+- **new_schema**
+
+ 指定时序表所属的模式。
+
+## 示例
+
+```sql
+--修改时序表的所有者为user1。
+Uqbar=#ALTER TIMESERIES TABLE weather owner TO user1;
+ALTER TIMESERIES TABLE
+```
+
+## 相关链接
+
+[CREATE TIMESERIES TABLE](./CREATE-TIMESERIES-TABLE.md),[DROP TIMESERIES TABLE](./DROP-TIMESERIES-TABLE.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/COMPRESS-TIMESERIES.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/COMPRESS-TIMESERIES.md
new file mode 100644
index 0000000000000000000000000000000000000000..774f298bf23e8f21e3e7aa63ba9edca5edf65f4d
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/COMPRESS-TIMESERIES.md
@@ -0,0 +1,32 @@
+---
+title: COMPRESS TIMESERIES
+summary: COMPRESS TIMESERIES
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# COMPRESS TIMESERIES
+
+## 功能描述
+
+用于对时序表或时序表内的某个chunkgroup进行压缩。
+
+## 注意事项
+
+- 当前版本不支持对压缩后的chunkgroup再写入数据
+- 不指定 Partition 参数表示对时序表所有的 chunkgroup 执行压缩;指定 Partition 会对指定的 chunkgroup 执行压缩
+
+## 语法格式
+
+```
+COMPRESS TIMESERIES table_name [ PARTITION chunkgroupname ]
+```
+
+## 示例
+
+```sql
+Uqbar=# COMPRESS TIMESERIES weather PARTITION chunkgroup_1;
+COMPRESSED
+Uqbar=# COMPRESS TIMESERIES weather;
+COMPRESSED
+```
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-CONTINUOUS-AGGREGATION.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-CONTINUOUS-AGGREGATION.md
new file mode 100644
index 0000000000000000000000000000000000000000..1ab629e09e1ac082da271a9d5ba27e6c9ca72858
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-CONTINUOUS-AGGREGATION.md
@@ -0,0 +1,130 @@
+---
+title: CREATE CONTINUOUS AGGREGATION
+summary: CREATE CONTINUOUS AGGREGATION
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# CREATE CONTINUOUS AGGREGATION
+
+## 功能描述
+
+在当前数据库中创建一个新的持续聚合。
+
+## 语法格式
+
+```
+CREATE CONTINUOUS AGGREGATION [ IF
+NOT EXISTS ] conagg_name [ TABLESPACE tablespace_name ]
+EVERY resample_interval
+[ START_OFFSET end_offset]
+[ END_OFFSET start_offset ]
+AS ;
+```
+
+其中select_query为:
+
+```
+SELECT time_bucket(,) as
+bucket,[grouping_exprs], FROM
+source_timeseries_table
+[WHERE ...]
+GROUP BY bucket,[grouping_exprs],[optional_grouping_exprs]
+[HAVING ...]
+```
+
+## 参数说明
+
+- **conagg_name**
+
+ 持续聚合名,可包含schema_name,不包含schema_name时以默认schema作为schema_name,将以此持续聚合名作为持续聚合目标表的表名,若该表不存在则会自动创建目标表。
+
+ > **说明**:目标表也是时序表,该时序表使用默认policy。可在创建持续聚合后使用更新时序表保留策略语法替换policy。
+
+ > **注意**:存在与持续聚合名相同的表将导致创建失败。
+
+- **tablespace_name**
+
+ 指定持续聚合所属表空间,可选参数。持续聚合目标表也使用此表空间。
+
+- **resample_interval**
+
+ 持续聚合自动重采样的时间间隔。
+
+ > **注意**:最小值为1s,最大为INTERVAL类型的最大值。若设置为0则持续聚合的下次启动时间为infinity(timestamp类型的最大值),表示不会启动。
+
+- **start_offset**
+
+ 聚合数据窗口开始时间距离采样时间的偏移,即resample_time(持续聚合重采样时间)-start_offset并按照time_bucket的宽度向前对齐(对齐时间基准点为2001-01-01 00:00:00)作为采样窗口开始时间。默认值resample_interval。
+
+ > **注意**:start_offset仅作用于持续聚合创建后的第一次运行,第一次运行后,以上次聚合窗口结束时间作为下一次聚合窗口开始时间。
+
+- **end_offset**
+
+ 聚合数据窗口结束时间距离采样时间的偏移,即resample_time - end_offset并按照time_bucket宽度向前对齐作为采样窗口结束时间,默认0s。
+
+ > **说明**: resample_interval,start_offset,end_offset只能使用'数字 时间单位'的格式。若数字部分不是整数则会自动进行向上取整,例如1.5day会取整为2day,-1.1day会取整为-1day(resample_interval不支持负值)。支持的时间单位包括:second,minute,hour,day,week,month,year。
+
+ > **注意**:约束条件start_offset-end_offset>=resample_interval,保证两次聚合中间没有数据遗漏。start_offset-end_offset>=bucket_width,隐含约束bucket_width不能等于0,因此start_offset和end_offset不能相等。start_offset-end_offset>0,保证采样窗口开始时间小于采样窗口结束时间。start_offset和end_offset可以为负值,表示聚合未来数据。
+
+- **selecrt_query**
+
+ 持续聚合要执行的聚合查询语句。其包含的参数说明如下。
+
+ - **time_bucket**
+
+ select_query必须包含且只能包含一个time_bucket函数,time_bucket的相关使用方式请参考[time_bucket](../query-data/aggregation-operator/time-bucket.md)章节。
+
+ - **grouping_exprs**
+
+ GROUY BY字句中除time_bucket函数生成列外,在targetlist中出现的列,可为空。当为空时持续聚合目标表中将出现一列默认值为空的extra_tag列。
+
+ - **option_grouping_expes**
+
+ 仅出现在GROUP BY子句但未出现在targetlist中的列,可为空。
+
+ > **注意**:在GROUP BY中除了time_bucket之外只支持TAG列,或者由包含未出现在GROUP BY子句中的tag的表达式产生的目标列。
+
+ - **source_timeseries_table**
+
+ 持续聚合源表,必须是单个时序表,不能是SELECT语句。
+
+ - **aggregation_functions**
+
+ 聚合函数,例如avg,min,max等。
+
+## 示例
+
+```sql
+Uqbar=# CREATE TIMESERIES TABLE weather(time timestamp tstime,city text
+tstag,temperature float);
+CREATE TIMESERIES TABLE
+Uqbar=# CREATE CONTINUOUS aggregation IF NOT EXISTS weather_ca
+EVERY '1 hour'
+START_OFFSET '2 day'
+END_OFFSET '1 day'
+AS
+SELECT time_bucket('1 hour', time) as bucket, province, city,
+avg(temperature)
+FROM weather
+GROUP BY bucket, province, city ORDER BY bucket;
+CREATE CONTINUOUS AGGRETATION
+```
+
+## 建议
+
+- 持续聚合不适用于数据写入一段时间后仍然进行变更的场景。
+
+- 当前版本持续聚合写入目标表的数据无法更改,若已聚合范围内的数据发生变化且确需刷新持续聚合,则可创建新的持续聚合,并设置start_offset使持续聚合后台任务初次运行时聚合范围覆盖发生变化数据的时间范围。
+
+- 持续聚合的目标表仍为时序表,可对其再创建持续聚合。
+
+- 当time_bucket的bucket_width会自动向上取整,尽量避免'1.5 day'这样的写法,而替换为'36 hour'。
+
+- 估算某个时间范围内数据从开始写入到写入/修改结束的时间并以此值作为参考设置end_offset,可尽量避免持续聚合写入后出现聚合结果与新的数据不匹配。
+
+- 由于目标表也是时序表,分区压缩后将导致持续聚合后台任务无法向目标表写入包含压缩分区范围的数据。可在创建持续聚合前以重采样间隔的值为参考更新uqbar.timeseries_compression_delay参数,使目标表上的自动压缩后台任务启动间隔大于持续聚合后台任务启动间隔,避免此问题。
+
+## 相关页面
+
+[ALTER CONTINUOUS AGGREGATION](./ALTER-CONTINUOUS-AGGREGATION.md),[DROP CONTINUOUS AGGREGATION](./DROP-CONTINUOUS-AGGREGATION.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-TIMESERIES-POLICY.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-TIMESERIES-POLICY.md
new file mode 100644
index 0000000000000000000000000000000000000000..e51a9d27e0dc9c1a39257b46109460dc783305a7
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-TIMESERIES-POLICY.md
@@ -0,0 +1,68 @@
+---
+title: CREATE TIMESERIES POLICY
+summary: CREATE TIMESERIES POLICY
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# CREATE TIMESERIES POLICY
+
+## 功能描述
+
+用于在当前 database 下创建一个新的数据保留策略。
+
+## 注意事项
+
+- 新建的数据保留策略名称不能与已存在的保留策略重名。
+
+- duration不能小于chunkGroupDuration。
+
+- duration和chunkGroupDuration格式为'数字+时间单位'。输入的数字如果不是整数,系统会对其向上取整,例如1.2 week会取整为2 weeks。
+
+- duration和chunkGroupDuration不支持负数,duration和chunkGroupDuration支持的最小时间单位是1 hour,如果设置的值小于1 hour 会自动设置为 1 hour。
+
+- duration和chunkGroupDuration支持设置的单位包括:小时(hour)、天(day)、周(week)、月(month)、年(year),不支持其他时间单位。
+
+- 每种时间单位的取值范围限制如下:
+
+ | 单位 | 下限 | 上限 |
+ | :--- | :--- | :--------- |
+ | 年 | 0 | 296533 |
+ | 月 | 0 | 3558399 |
+ | 周 | 0 | 15250284 |
+ | 天 | 0 | 106751991 |
+ | 小时 | 0 | 2147483647 |
+
+## 语法格式
+
+```
+CREATE TIMESERIES POLICY [ IF NOT EXISTS ] policy_name WITH (option = value, [...] )
+```
+
+其中option包含:
+
+- duration:时序数据保留时间,超出这个时间的历史数据自动删除,删除以Chunk Group粒度为单位。取值范围 >= 1h。特殊值0表示数据永久保留,此时时间单位支持second、minute、hour、day、week、month、year。
+
+- chunkGroupDuration:指定时序表的Chunk Group时间跨度,不支持设为特殊值0。
+
+ 如果未指定本参数,系统自动根据duration参数设置合适的Chunk Group Duration参数,规则如下
+
+ - duration < 2天,chunkGroupDuration设置为1小时。chunkGroup 时间对齐到一小时,即chunkGroup的起止时间应该是整点,如 '2020-07-10 00:00:00'、'2020-07-10 01:00:00',而不会出现 '2020-07-10 00:10:00'、'2020-07-10 00:10:10' 这样的时间点。
+ - duration <= 6个月,chunkGroupDuration设置为1天。chunkGroup对齐到天,如 '2020-07-10 00:00:00'、'2020-07-11 00:00:00';
+ - duration > 6个月,chunkGroupDuration设置为7天。chunkGroup对齐到周,即chunkGroup的起始时间对齐到当周的周一。
+ - duration > 3 年,chunkGroupDuration设置为 1个月。chunkGroup对齐到月,即chunkGroup的起始时间对齐到当月的一号。
+
+duration和chunkGroupDuration数字部分的上限为231。
+
+每个 database 下有一个名为 ‘infinity’的默认的数据保留策略,默认策略的 duration=’0s’,表示数据永远不删除,chunkGroupDuration=’1month’。
+
+## 示例
+
+```sql
+Uqbar=# CREATE TIMESERIES POLICY policy_test WITH (duration = '2 years', chunkGroupDuration='7 days');
+CREATE POLICY
+```
+
+## 相关链接
+
+[ALTER TIMESERIES POLICY](./ALTER-TIMESERIES-POLICY.md),[DROP TIMESERIES POLICY](./DROP-TIMESERIES-POLICY.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md
new file mode 100644
index 0000000000000000000000000000000000000000..86420679a64cf7702c8a7c17de9a405aaadc4231
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/CREATE-TIMESERIES-TABLE.md
@@ -0,0 +1,79 @@
+---
+title: CREATE TIMESERIES TABLE
+summary: CREATE TIMESERIES TABLE
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# CREATE TIMESERIES TABLE
+
+## 功能描述
+
+在当前数据库中创建一个新的空白时序表,该时序表由命令执行者所有。
+
+## 注意事项
+
+- 必须要指定 TSTIME 和 TSTAG 列。
+
+- 只能有一列指定为 TSTIME 列,且数据类型只能为时间类型,包括 timestamp [without time zone]、timestamp with time zone。
+
+- 支持数量为 [1, 32] 的列指定为 TSTAG,支持整数类型和字符串类型 ,整数类型包括 int2、int4、int8;字符串类型包括 “char”、char(n)、character(n)、nchar(n)、bpchar(n)、varchar(n)、character varying(n)、nvarchar(n)、varchar2(n)、nvarchar2(n) 和 text。
+
+- 至少有一列不是 TSTIME 和 TSTAG。
+
+- 表名小于等于63个字符。
+
+- 一个时序表最多指定一个数据保留策略。
+
+- TSTIME 不支持用户设置 default,系统默认设置 TSTIME 为当前时间。
+
+- Field 列允许用户设置 NOT NULL。
+
+- Field 列不支持自定义的数据类型,由于列存数据类型的限制,支持的数据类型如下( DATE 和 DATEARRAY 中 DATE 类型指的是 “date” 而不是 date) :
+
+ BOOL、HLL、BYTEA、CHAR、INT8、INT2、INT4、INT1、NUMERIC、BPCHAR、VARCHAR、NVARCHAR2、SMALLDATETIME、TEXT、OID、FLOAT4、FLOAT8、ABSTIME、RELTIME、TINTERVAL、INET、DATE、TIME、TIMESTAMP、TIMESTAMPTZ、INTERVAL、TIMETZ、MONEY、CIDR、BIT、VARBIT、CLOB、BOOLARRAY、HLL_ARRAY、BYTEARRAY、CHARARRAY、INT8ARRAY、INT2ARRAY、INT4ARRAY、INT1ARRAY、NUMERICARRAY、BPCHARARRAY、VARCHARARRAY、NVARCHAR2ARRAY、SMALLDATETIMEARRAY、TEXTARRAY、FLOAT4ARRAY、FLOAT8ARRAY、ABSTIMEARRAY、RELTIMEARRAY、INTERVALARRAY、INETARRAY、DATEARRAY、TIMEARRAY、TIMESTAMPARRAY、TIMESTAMPTZARRAY、ARRAYINTERVAL、TIMETZARRAY、MONEYARRAY、CIDRARRAY、BITARRAY、VARBITARRAY
+
+## 语法格式
+
+创建时序表。
+
+```
+CREATE TIMESERIES TABLE [ IF NOT EXISTS ] table_name
+( column_name data_type [ tslabel ] [ DEFAULT default_expr ] [, ...] [ COLLATE collation ] )
+[ POLICY policy_name ]
+[ TABLESPACE tablespace_name ];
+```
+
+## 参数说明
+
+- **table_name**
+
+ 指定时序表的名称。
+
+- **tslabel**
+
+ 在创建时序数据库时,可以指定时序表的列数据类型,即将 tslabel 指定为TSTIME或TSTAG。TSTIME标识时序表的时间列。TSTAG标识时序表的标签列。
+
+- **default_expr**
+
+ 指定某列的默认值。
+
+- **policy_name**
+
+ 指定时序表的策略名。系统为每个数据库提供一个默认策略,用户也可以重新设置某个策略为默认策略,创建时序表时如果未指定具体策略,则使用所属数据库的默认数据保留策略。
+
+- **tablespace_name**
+
+ 指定时序表所属的表空间名称。
+
+## 示例
+
+```sql
+--创建简单的时序表。
+Uqbar=# CREATE TIMESERIES TABLE weather(time timestamp TSTIME, city text TSTAG, location text TSTAG, temperature float) POLICY infinity;
+CREATE TIMESERIES TABLE
+```
+
+## 相关链接
+
+[ALTER TIMESERIES TABLE](./ALTER-TIMESERIES-TABLE.md),[DROP TIMESERIES TABLE](./DROP-TIMESERIES-TABLE.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-CONTINUOUS-AGGREGATION.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-CONTINUOUS-AGGREGATION.md
new file mode 100644
index 0000000000000000000000000000000000000000..23011396cb3ce4e85e13ff365f59519ab6058b15
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-CONTINUOUS-AGGREGATION.md
@@ -0,0 +1,43 @@
+---
+title: DROP CONTINUOUS AGGREGATION
+summary: DROP CONTINUOUS AGGREGATION
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# DROP CONTINUOUS AGGREGATION
+
+## 功能描述
+
+删除当前数据库中已存在的一个持续聚合。
+
+## 语法格式
+
+```
+DROP CONTINUOUS AGGREGATION [IF EXISTS] conagg_name [, conagg_names]
+```
+
+## 参数说明
+
+- **conagg_name**
+
+ 修改的持续聚合名,可包含schema部分。
+
+ > **注意**:不支持指定tablespace部分。
+
+- **conagg_names**
+
+ 删除持续聚合支持一次删除多个持续聚合。
+
+ > **说明**:删除持续聚合不会删除目标表。
+
+## 示例
+
+```sql
+Uqbar=# DROP CONTINUOUS AGGREGATION weather_ca;
+DROP CONTINUOUS AGGRETATION
+```
+
+## 相关页面
+
+[CREATE CONTINUOUS AGGREGATION](./CREATE-CONTINUOUS-AGGREGATION.md),[ALTER CONTINUOUS AGGREGATION](./ALTER-CONTINUOUS-AGGREGATION.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-TIMESERIES-POLICY.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-TIMESERIES-POLICY.md
new file mode 100644
index 0000000000000000000000000000000000000000..b74e43500e9bb50372540299dff086895357efdf
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-TIMESERIES-POLICY.md
@@ -0,0 +1,40 @@
+---
+title: DROP TIMESERIES POLICY
+summary: DROP TIMESERIES POLICY
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# DROP TIMESERIES POLICY
+
+## 功能描述
+
+用于删除已存在的数据保留策略。
+
+## 注意事项
+
+- 如果数据保留策略正在被时序表使用,无法删除。
+- 数据库下的默认策略不能被删除。
+
+## 语法格式
+
+```
+DROP TIMESERIES POLICY [IF EXISTS] policy_name
+```
+
+可以用于删除一个或多个timeseries policy。
+
+如果没有IF EXISTS选项,且被删除的策略列表中中有不存在的策略,则执行报错,给出对应的错误提示,不执行任何策略的删除。
+
+如果含有IF EXISTS选项,且被删除的策略列表中有不存在的策略,则执行跳过不存在的策略,并给出对应的提示信息,存在的策略执行删除操作。
+
+## 示例
+
+```sql
+Uqbar=# DROP TIMESERIES POLICY policy1;
+DROP POLICY
+```
+
+## 相关链接
+
+[CREATE TIMESERIES POLICY](./CREATE-TIMESERIES-POLICY.md),[ALTER TIMESERIES POLICY](./ALTER-TIMESERIES-POLICY.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md
new file mode 100644
index 0000000000000000000000000000000000000000..428d6d85ea44817b3f17786b276e56c1c0e0eece
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/DROP-TIMESERIES-TABLE.md
@@ -0,0 +1,42 @@
+---
+title: DROP TIMESERIES TABLE
+summary: DROP TIMESERIES TABLE
+author: zhang cuiping
+date: 2022-11-22
+---
+
+# DROP TIMESERIES TABLE
+
+## 功能描述
+
+用户可删除一张或多张时序表。执行删除命令后,表的数据和元数据也会删除。
+
+## 语法格式
+
+删除时序表。
+
+```
+DROP TIMESERIES TABLE [ IF EXISTS ] table_name [, table1_name ...];
+```
+
+## 参数说明
+
+- **IF EXISTS**
+
+ 如果指定的表不存在,则发出一个notice而不是抛出一个错误。
+
+- **table_name**
+
+ 指定要删除的时序表的名称。
+
+## 示例
+
+```sql
+--删除时序表weather。
+Uqbar=#DROP TIMESERIES TABLE weather;
+DROP TIMESERIES TABLE
+```
+
+## 相关链接
+
+[CREATE TIMESERIES TABLE](./CREATE-TIMESERIES-TABLE.md),[ALTER TIMESERIES TABLE](./ALTER-TIMESERIES-TABLE.md)
\ No newline at end of file
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/first-last.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/first-last.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e0c4877c6f1c8bd93b4cff098810f751ec6e871
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/first-last.md
@@ -0,0 +1,45 @@
+---
+title: first()/last()
+summary: first()/last()
+author: Guo Huan
+date: 2023-06-08
+---
+
+# first()/last()
+
+## 功能描述
+
+使用cmp_col列做比较,返回时间最早或最晚的value指定的列的值。时序的first/last算子在timeseries_catalog这个schema下,区别于public中的first/last。
+
+## 注意事项
+
+当表存在多条记录的cmp_col列最小值/最大值相同时,返回这些记录中第一条/最后一条的value。
+
+当cmp_col列为常量时,时序first/last算子的效果等同于public中的first/last算子, 返回所有记录中的第一条/最后一条的value值。
+
+## 语法格式
+
+```
+select city_name,timeseries_catalog.first(temp_c,time) from weather_metrics group by city_name;
+select city_name,timeseries_catalog.last(temp_c,time) from weather_metrics group by city_name;
+timeseries_catalog.first(value, cmp_col)
+timeseries_catalog.last(value, cmp_col)
+```
+
+## 参数说明
+
+| 参数名 | 类型 | 属性 | 释义 |
+| :------ | :----------------------- | :--- | :----- |
+| value | ANY | 必选 | 返回值 |
+| cmp_col | TIMESTAMP or TIMESTAMPTZ | 必选 | 比较值 |
+
+## 示例
+
+```sql
+Uqbar=# select city_name,timeseries_catalog.first(temp_c,time) from weather_metrics group by city_name;
+ city_name | first
+---------------+-------
+beijing | 30
+shanghai | 29
+(2 row)
+```
diff --git a/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/uqbar-sql-syntax.md b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/uqbar-sql-syntax.md
new file mode 100644
index 0000000000000000000000000000000000000000..06a1c986483a975900ae1747583a56c150496c2d
--- /dev/null
+++ b/product/zh/docs-uqbar/v2.0/uqbar-sql-syntax/uqbar-sql-syntax.md
@@ -0,0 +1,21 @@
+---
+title: SQL语法参考
+summary: SQL语法参考
+author: Guo Huan
+date: 2023-06-08
+---
+
+# SQL语法参考
+
++ **[ALTER CONTINUOUS AGGREGATION](./ALTER-CONTINUOUS-AGGREGATION.md)**
++ **[ALTER TIMESERIES POLICY](./ALTER-TIMESERIES-POLICY.md)**
++ **[ALTER TIMESERIES TABLE](./ALTER-TIMESERIES-TABLE.md)**
++ **[COMPRESS TIMESERIES](/uqbar-sql-syntax/COMPRESS-TIMESERIES.md)**
++ **[CREATE CONTINUOUS AGGREGATION](./CREATE-CONTINUOUS-AGGREGATION.md)**
++ **[CREATE TIMESERIES POLICY](./CREATE-TIMESERIES-POLICY.md)**
++ **[CREATE TIMESERIES TABLE](./CREATE-TIMESERIES-TABLE.md)**
++ **[DROP CONTINUOUS AGGREGATION](./DROP-CONTINUOUS-AGGREGATION.md)**
++ **[DROP TIMESERIES POLICY](./DROP-TIMESERIES-POLICY.md)**
++ **[DROP TIMESERIES TABLE](./DROP-TIMESERIES-TABLE.md)**
+
+其他相关语法请参阅MogDB 3.0.0中的[SQL语法介绍](https://docs.mogdb.io/zh/mogdb/v5.0/ABORT)。
\ No newline at end of file
diff --git a/src/utils/version_config.js b/src/utils/version_config.js
index a48c8961a82c209f3c6620595a52387a43d4c82a..2412caa8b649026710b1f9aea096e6ea7091e927 100644
--- a/src/utils/version_config.js
+++ b/src/utils/version_config.js
@@ -149,8 +149,13 @@ const allProductVersions = {
}
},
uqbar: {
- latestVersion: 'v1.1',
+ latestVersion: 'v2.0',
versions: {
+ 'v2.0': {
+ value: 'v2.0',
+ label: 'v2.0-beta',
+ disabled: false
+ },
'v1.1': {
value: 'v1.1',
label: 'v1.1',