# 爬虫学习
**Repository Path**: eternidad33/ScrapyDemo
## Basic Information
- **Project Name**: 爬虫学习
- **Description**: 🕷️ 中国大学MOOC嵩天老师的课程《Python网络爬虫与信息提取 》学习笔记
- **Primary Language**: Python
- **License**: Apache-2.0
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 1
- **Forks**: 1
- **Created**: 2020-05-14
- **Last Updated**: 2025-05-18
## Categories & Tags
**Categories**: Uncategorized
**Tags**: Python, Spider
## README
[toc]
# 爬虫学习笔记
推荐课程[《Python网络爬虫与信息提取 》](https://www.icourse163.org/course/0809BIT021A-1001870001)
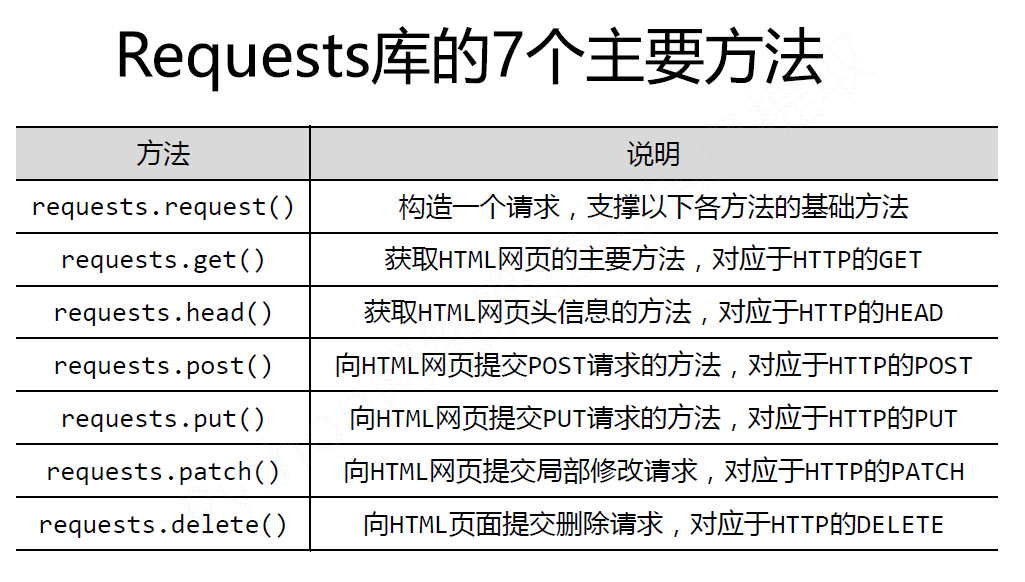
## Requests库
```python
import requests
r = requests.get('http://www.baidu.com')
print('状态码:', r.status_code)
# 更改字符编码
r.encoding = 'utf-8'
print('显示文本:\n' + r.text)
```
`requests.get(url)`返回Response类型对象
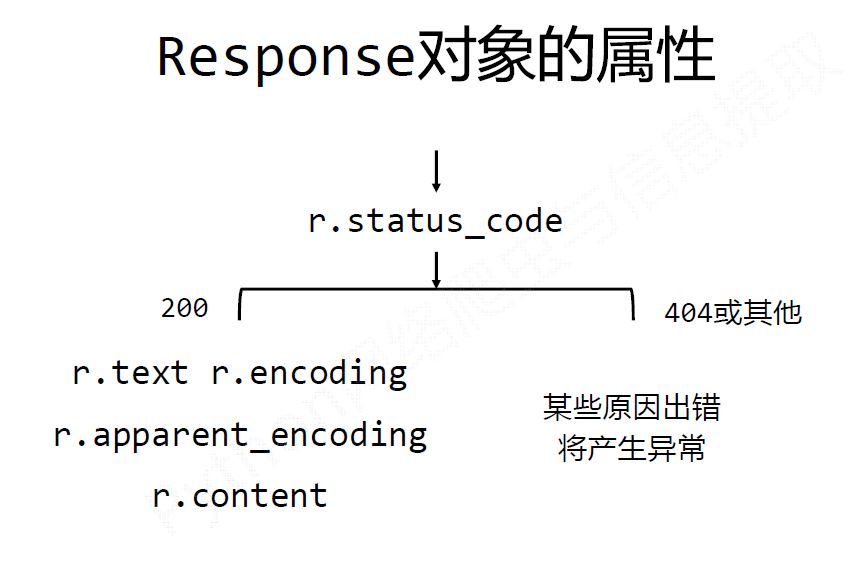
`r.apparent_encoding`根据网页内容分析出来的编码方式

假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段
需求:用户修改了UserName,其他不变
- 采用PATCH,仅向URL提交UserName的局部更新请求
- 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
PATCH的最主要好处:节省网络带宽
通过 https://www.jd.com/robots.txt 访问京东的Robots协议
```text
User-agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /
```
robots协议一定要放在网站的根目录下,基本格式:
```text
User-agent: *
Disallow: /
```
> *代表所有,/代表根目录
## BeautifulSoup库
Beautiful Soup库是解析、遍历、维护“标签树”的功能库
`BeautifulSoup(r.text, 'html.parser')`使用HTML解析器解析r.text
BeautifulSoup类的基本元素
| 基本元素 | 说明 |
| --------------- | ------------------------------------------------------- |
| Tag | 标签,最基本的信息组织单元,分别用<>和标明开头和结尾 |
| Name | 标签的名字,\…\
的名字是'p',格式:.name |
| Attributes | 标签的属性,字典形式组织,格式:.attrs |
| NavigableString | 标签内非属性字符串,<>…中字符串,格式:.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
标签树的下行遍历
| 属性 | 说明 |
| ------------ | ------------------------------------------------------- |
| .contents | 子节点的列表,将所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
标签树的上行遍历
| 属性 | 说明 |
| ------------ | -------------------------------------------------- |
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
标签树的平行遍历
| 属性 | 说明 |
| ------------------ | ---------------------------------------------------- |
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
信息标记的三种形式:XML,JSON,YAML
XML实例
```xml
Tian
Song
中关村南大街5号
北京市
100081
Computer SystemSecurity
```
JSON实例
```json
{
“firstName” : “Tian” ,
“lastName” : “Song” ,
“address” : {
“streetAddr” : “中关村南大街5号” ,
“city” : “北京市” ,
“zipcode” : “100081”
} ,
“prof” : [ “Computer System” , “Security” ]
}
```
YAML
```yaml
firstName: Tian
lastName: Song
address:
streetAddr: 中关村南大街5号
city: 北京市
zipcode: 100081
prof:
‐Computer System
‐Security
```
三种格式的对比
| 格式 | 特点 | 用途 |
| ---- | ------------------------------------------ | ------------------------------------ |
| XML | 最早的通用信息标记语言,可扩展性好,但繁琐 | Internet上的信息交互与传递 |
| JSON | 信息有类型,适合程序处理(js),较XML简洁 | 移动应用云端和节点的信息通信,无注释 |
| YAML | 信息无类型,文本信息比例最高,可读性好 | 各类系统的配置文件,有注释易读 |
`<>.find_all(name, attrs, recursive, string, **kwargs)`
- name : 对标签名称的检索字符串
- attrs: 对标签属性值的检索字符串,可标注属性检索
- recursive: 是否对子孙全部检索,默认True
- string: <>…中字符串区域的检索字符串
`(..) `等价于`.find_all(..)`
`soup(..) `等价于`soup.find_all(..)`
| 方法 | 说明 |
| --------------------------- | ----------------------------------------------------- |
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |
从最好大学网爬取大学排名
1. 从网络上获取大学排名网页内容,`getHTMLText()`
2. 提取网页内容中信息到合适的数据结构,`fillUnivList()`
3. 利用数据结构展示并输出结果,`printUnivList()`
> 打印时采用中文字符的空格填充chr(12288)
## 正则表达式
常用操作符
| 操作符 | 说明 | 实例 |
| ------ | -------------------------------- | --------------------------------------- |
| `.` | . 表示任何单个字符 | |
| `[]` | 字符集,对单个字符给出取值范围` | 表示a、b、c,[a‐z]表示a到z单个字符 |
| `[^]` | 非字符集,对单个字符给出排除范围 | `[\^abc]`表示非a或b或c的单个字符 |
| `*` | 前一个字符0次或无限次扩展 | `abc\*` 表示ab、abc、abcc、abccc等 |
| `+` | 前一个字符1次或无限次扩展 | `abc+ `表示abc、abcc、abccc等 |
| `?` | 前一个字符0次或1次扩展 | `abc? `表示ab、abc |
| `|` | 左右表达式任意一个 | `abc\|def `表示abc、def |
| `{m}` | 扩展前一个字符m次 | `ab{2}c`表示abbc |
| `{m,n}` | 扩展前一个字符m至n次(含n) | `ab{1,2}c`表示abc、abbc |
| `^` | 匹配字符串开头 | `^abc`表示abc且在一个字符串的开头 |
| `$ ` | 匹配字符串结尾 | `abc$`表示abc且在一个字符串的结尾 |
| `( ) ` | 分组标记,内部只能使用`|`操作符 | `(abc)`表示abc,`(abc|def)`表示abc、def |
| `\d` | 数字,等价于[0‐9] | |
| `\w ` | 单词字符,等价于[A‐Za‐z0‐9_] | |
经典正则表达式实例

IP地址的精确写法
0‐99: `[1‐9]?\d`
100‐199: `1\d{2}`
200‐249: `2[0‐4]\d`
250‐255: `25[0‐5]`
`(([1‐9]?\d|1\d{2}|2[0‐4]\d|25[0‐5]).){3}([1‐9]?\d|1\d{2}|2[0‐4]\d|25[0‐5])`
Re库
re库采用raw string类型表示正则表达式,表示为:`r’text’`
> 建议:当正则表达式包含转义符时,使用raw string
| 函数 | 说明 |
| ------------- | ------------------------------------------------------------ |
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
`re.search(pattern, string, flags=0)`在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
- flags : 正则表达式使用时的控制标记
` re.match(pattern, string, flags=0)`从一个字符串的开始位置起匹配正则表达式,返回match对象
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
- flags : 正则表达式使用时的控制标记
` re.findall(pattern, string, flags=0)`搜索字符串,以列表类型返回全部能匹配的子串
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
- flags : 正则表达式使用时的控制标记
`re.split(pattern, string, maxsplit=0, flags=0)`将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
- maxsplit: 最大分割数,剩余部分作为最后一个元素输出
- flags : 正则表达式使用时的控制标记
`re.finditer(pattern, string, flags=0)`搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
- flags : 正则表达式使用时的控制标记
`re.sub(pattern, repl, string, count=0, flags=0)`在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
- pattern : 正则表达式的字符串或原生字符串表示
- repl : 替换匹配字符串的字符串
- string : 待匹配字符串
- count : 匹配的最大替换次数
- flags : 正则表达式使用时的控制标记
`regex = re.compile(pattern, flags=0)`将正则表达式的字符串形式编译成正则表达式对象
- pattern : 正则表达式的字符串或原生字符串表示
- flags : 正则表达式使用时的控制标记
Re库的另一种等价用法
| 函数 | 说明 |
| ------------------ | ------------------------------------------------------------ |
| `regex.search()` | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| `regex.match()` | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| `regex.findall()` | 搜索字符串,以列表类型返回全部能匹配的子串 |
| `regex.split()` | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| `regex.finditer()` | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| `regex.sub()` | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
Re库的Match对象
Match对象是一次匹配的结果,包含匹配的很多信息
```python
In[43]: match=re.match(r'[A-Z]+', 'Start HBU河北大学简称HBU')
In[44]: type(match)
Out[44]: re.Match
```
**Match对象的属性**
| 属性 | 说明 |
| --------- | ------------------------------------ |
| `.string` | 待匹配的文本 |
| `.re` | 匹配时使用的patter对象(正则表达式) |
| `.pos` | 正则表达式搜索文本的开始位置 |
| `.endpos` | 正则表达式搜索文本的结束位置 |
**Match对象的方法**
| 方法 | 说明 |
| ----------- | -------------------------------- |
| `.group(0)` | 获得匹配后的字符串 |
| `.start()` | 匹配字符串在原始字符串的开始位置 |
| `.end()` | 匹配字符串在原始字符串的结束位置 |
| `.span() ` | 返回`(.start(), .end())` |
最小匹配操作符
| 操作符 | 说明 |
| -------- | ------------------------------------- |
| `*?` | 前一个字符0次或无限次扩展,最小匹配 |
| `+?` | 前一个字符1次或无限次扩展,最小匹配 |
| `??` | 前一个字符0次或1次扩展,最小匹配 |
| `{m,n}?` | 扩展前一个字符m至n次(含n),最小匹配 |

## Scrapy框架
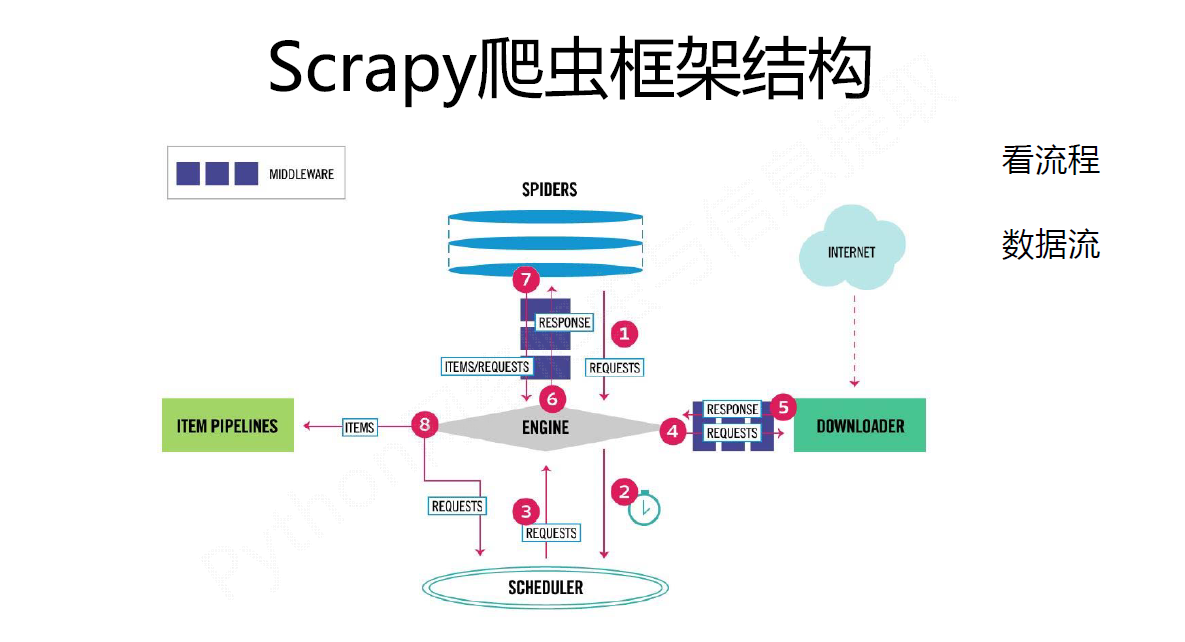
1. Engine从Spider处获得爬取请求(Request)
2. Engine将爬取请求转发给Scheduler,用于调度
3. Engine从Scheduler处获得下一个要爬取的请求
4. Engine将爬取请求通过中间件发送给Downloader
5. 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6. Engine将收到的响应通过中间件发送给Spider处理
7. Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8. Engine将爬取项发送给Item Pipeline(框架出口)
9. Engine将爬取请求发送给Scheduler
Engine控制各模块数据流,不间断从Scheduler处获得爬取请求,直至请求为空。
数据流的出入口
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
用户只需编写(配置)Spider和Item Pipeline
Engine
1. 控制所有模块之间的数据流
2. 根据条件触发事件
不需要用户修改
Downloader
根据请求下载网页
不需要用户修改
Scheduler
对所有爬取请求进行调度管理
不需要用户修改
Downloader Middleware
目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
用户可以编写配置代码
Spider
1. 解析Downloader返回的响应(Response)
2. 产生爬取项(scraped item)
3. 产生额外的爬取请求(Request)
需要用户编写配置代码
Item Pipelines
1. 以流水线方式处理Spider产生的爬取项
2. 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
3. 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
需要用户编写配置代码
Spider Middleware
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
用户可以编写配置代码
requests 和 Scrapy的异同
相同点:
1. 两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
2. 两者可用性都好,文档丰富,入门简单
3. 两者都没有处理js、提交表单、应对验证码等功能(可扩展)
不同点:
| requests | Scrapy |
| ------------------------ | -------------------------- |
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
Scrapy常用命令
| 命令 | 说明 | 格式 |
| ------------ | ------------------ | -------------------------------------------- |
| startproject | 创建一个新工程 | `scrapy startproject [dir]` |
| genspider | 创建一个爬虫 | `scrapy genspider [options] ` |
| settings | 获得爬虫配置信息 | `scrapy settings [options]` |
| crawl | 运行一个爬虫 | `scrapy crawl ` |
| list | 列出工程中所有爬虫 | `scrapy list` |
| shell | 启动URL调试命令行 | `scrapy shell [url]` |
生成的工程目录
```powershell
PS E:\scrapyDemo> tree /f
卷 软件 的文件夹 PATH 列表
卷序列号为 54DD-69A2
E:.
│ scrapy.cfg ------------------->>部署Scrapy爬虫的配置文件
│
└─scrapyDemo ------------>>Scrapy框架的用户自定义Python代码
│ items.py -------------->>Items代码模板(继承类)
│ middlewares.py ------->>Middlewares代码模板(继承类)
│ pipelines.py --------->>Pipelines代码模板(继承类)
│ settings.py -------->>Scrapy爬虫的配置文件
│ __init__.py --------->>初始化脚本
│
├─spiders -------------->>Spiders代码模板目录(继承类)
│ │ firstSpider.py ------>>生成的爬虫
│ │ __init__.py ------>>初始文件,无需修改
│ │
│ └─__pycache__ -------->>缓存目录,无需修改
│ firstSpider.cpython-37.pyc
│ __init__.cpython-37.pyc
│
└─__pycache__ ----------->>缓存目录,无需修改
settings.cpython-37.pyc
__init__.cpython-37.pyc
```
Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline
步骤4:优化配置策略
Scrapy爬虫的数据类型
1. Request类
Request对象表示一个HTTP请求,由Spider生成,由Downloader执行
2. Response类
Response对象表示一个HTTP响应,由Downloader生成,由Spider处理
3. Item类
Item对象表示一个从HTML页面中提取的信息内容,由Spider生成,由Item Pipeline处理,Item类似字典类型,可以按照字典类型操作
Scrapy爬虫支持多种HTML信息提取方法:
- Beautiful Soup
- lxml
- re
- XPath Selector
- CSS Selector