# fastautoaugment_jsh
**Repository Path**: greitzmann/fastautoaugment_jsh
## Basic Information
- **Project Name**: fastautoaugment_jsh
- **Description**: Unofficial and Partial Implementation of Fast AutoAugment in Pytorch
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2021-01-27
- **Last Updated**: 2021-01-27
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# Fast AutoAugment Implementation in Pytorch
Unofficial and Partial implementation of Fast AutoAugment in Pytorch.
## Summary
- Fast AutoAugment (hereafter FAA) finds the optimal set of data augmentation operations via density matching using Bayesian optimization.
- FAA delivers comparable performance to AutoAugment but in a much shorter period of time.
- Unlike AutoAugment that discretizes the search space, FAA can handle continuous search space directly.
## Getting Started
```bash
$ git clone https://github.com/junkwhinger/fastautoaugment_jsh.git
cd fastautoaugment_jsh
```
### Install dependencies
```bash
pip install -r requirements.txt
```
### Training
You can train or test the model with the baseline or optimal augmentation policies found by FAA with the following commands.
#### Test Only
```bash
# Baseline
python train.py --model_dir experiments/baseline --eval_only
# Fast AutoAugment
python train.py --model_dir experiments/fastautoaugment --eval_only
```
#### Training + Evaluation
```bash
# Baseline
python train.py --model_dir experiments/baseline
# Fast AutoAugment
python train.py --model_dir experiments/fastautoaugment
```
### Fast AutoAugment
You can run Fast AutoAugment with the following commands. It takes time.
- train_mode: train models on D_Ms for 5 splits (takes roughly 4.5 hours)
- bayesian_mode: run bayesian optimiazation with HyperOpt to find the optimal policy (takes 3 hours)
- merge: aggregates the trials and combines the best policies from the splits. Writes the result as a file `optimal_policy.json`. To use the policy for training, please copy this file into your `experiments/fastautoaugment` folder.
```bash
# Train models on D_Ms & Bayesian Optimization & Merge
python search_fastautoaugment.py --train_mode --bayesian_mode
# Bayesian Optimization & Merge
python search_fastautoaugment.py --bayesian_mode
# Merge only
python search_fastautoaugment.py
```
### Checkpoints
Here are the checkpoints I made during the replication of the paper.
- for training and testing (baseline / fastautoaugment)
- `experiments/baseline/best_model.torch`: a trained model for Baseline at epoch 200
- `experiments/baseline/params.json`: a hyper-parameter set for Baseline
- `experiments/baseline/train.log`: a training log for Baseline
- for FAA policy searching
- `fastautoaugment/k0_t0_trials.pkl`: a pickled trial log for 0th split and 0th search width
- `fastautoaugment/model_k_0.torch`: a model file that trained on D_M[0]
- `fastautoaugment/optimal_policy.json`: an optimal policy json file from the search
- `fastautoaugment/params.json`: a hyper-parameter set for FAA
- `fastautoaugment/train.log`: a training log for FAA
## Search Strategy
### Terminology
- Operation 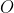 : an augmentation function (e.g. Cutout)
- Probability
: an augmentation function (e.g. Cutout)
- Probability 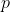 : (attribute of an operation) the chance that the operation is turned on. This value ranges from 0 to 1, 0 being always off, 1 always on.
- Magnitude
: (attribute of an operation) the chance that the operation is turned on. This value ranges from 0 to 1, 0 being always off, 1 always on.
- Magnitude 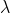 : (attribute of an operation) the amount that the operation transforms a given image. This value ranges from 0 to 1, and gets adjusted according to the corresponding range of its operation. For example,
: (attribute of an operation) the amount that the operation transforms a given image. This value ranges from 0 to 1, and gets adjusted according to the corresponding range of its operation. For example,  for Rotate means Rotate -30 degree.
- Sub-policy
for Rotate means Rotate -30 degree.
- Sub-policy 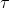 : a random sequence of operations. The length of a sub-policy is determined by Search Width(
: a random sequence of operations. The length of a sub-policy is determined by Search Width( ). For example, a sub-policy that has Cutout and Rotate transforms a given image in 4 ways.
- Policy
). For example, a sub-policy that has Cutout and Rotate transforms a given image in 4 ways.
- Policy  : a set of sub-policies. FAA aims to find
: a set of sub-policies. FAA aims to find  that contains
that contains  from
from 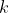 th split of the train dataset.
### Search Space
- FAA attempts to find the probability and magnitude for the following 16 augmentation operations.
- ShearX, ShearY, TranslateX, TranslateY,
Rotate, AutoContrast, Invert, Equalize,
Solarize, Posterize, Contrast, Color,
Brightness, Sharpness, Cutout, Sample Pairing
### Algorithm
- Inputs
-
th split of the train dataset.
### Search Space
- FAA attempts to find the probability and magnitude for the following 16 augmentation operations.
- ShearX, ShearY, TranslateX, TranslateY,
Rotate, AutoContrast, Invert, Equalize,
Solarize, Posterize, Contrast, Color,
Brightness, Sharpness, Cutout, Sample Pairing
### Algorithm
- Inputs
- 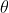 : network to train
-
: network to train
-  : train dataset that contains 42675 images from cifar10.
-
: train dataset that contains 42675 images from cifar10.
- 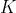 : the number of cross validation folds.
: the number of cross validation folds.  in FAA.
-
in FAA.
- 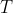 : search width. in FAA.
-
: search width. in FAA.
- 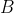 : search depth.
: search depth.  in FAA.
-
in FAA.
- 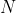 : the number of top policies to keep.
: the number of top policies to keep.  in FAA.
- Step 1: Shuffle
- Split into sets of
in FAA.
- Step 1: Shuffle
- Split into sets of  and
and 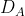 using the target labels.
- Step 2: Train
- Train on each . FAA implemented Step 2 in parallel. In my implementation, it is done sequentially in a for loop.
- Each model is trained from scratch without data augmentation.
- I added `TF.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))`.
- Step 3: Explore-and-Exploit
- Find the optimal set of sub-policies and probabilities and magnitudes of their operations.
FAA employs HyperOpt for this step. I saved the sub-policies and their corresponding validation error on augmented in `Trials` for Step 4.
- Step 4. Merge
- Select top policies for each split. Combined the top policies into the final set policies that are used for re-training on
using the target labels.
- Step 2: Train
- Train on each . FAA implemented Step 2 in parallel. In my implementation, it is done sequentially in a for loop.
- Each model is trained from scratch without data augmentation.
- I added `TF.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))`.
- Step 3: Explore-and-Exploit
- Find the optimal set of sub-policies and probabilities and magnitudes of their operations.
FAA employs HyperOpt for this step. I saved the sub-policies and their corresponding validation error on augmented in `Trials` for Step 4.
- Step 4. Merge
- Select top policies for each split. Combined the top policies into the final set policies that are used for re-training on
## Results
### CIFAR-10 Test Error (%)
Search: 7.5 GPU Hours on a single Tesla V100 16GB Memory machine
(FAA in paper took 3.5 GPU Hours)
| Model(CIFAR-10) | Baseline(paper) | Baseline(mine) | FAA(paper/direct) | FAA(mine/direct) |
| ---------------- | --------------- | -------------- | ----------------- | ---------------- |
| Wide-ResNet-40-2 | 5.3 | 5.6 | 3.7 | 5.5 |
### Evaluation & Interpretation
- Failed to replicate the Baseline performance of the paper despite the same hyper-parameter set I tried to follow.
- During debugging the original code, I found some discrepancies regarding the dataset size that could have caused the issue (covered in-depth in ETC).
- Revision needed on `train.py` and `model/data_loader.py`.
- Failed to replicate Fast AutoAugment performance. The improvement on Test Error that I gained via FAA (-0.1) is much smaller than the paper's result(-1.6).
- Revision needed on `search_fastautoaugment.py`.
- The optimal policies I found appear to have a storng tendency to keep the given images unchanged as much as possible.
- The red dots mark the points with the lowest validation error.
- Brightness, Contrast, Color, Sharpness values (magnitudes) are around 0.5 which are converted around 1 that returns the original image.
- TranslateX, TranslateY are given high probabilties, yet they have values around 0.5, making the resulting transformation very subtle.
- AutoContrast, Invert, Solarize are given near zero probabilities.
- I chose a uniform distribution between 0 and 1 for the probability and magnitude for the following operations. I wonder if a distribution that excludes regions that barely changes images would lead to a different result. (e.g. Rotate between -30 ~ -10 and +10 ~ 30)

## Discrepencies between Paper and my Implementation
- I did not include SamplePairing from the set of augmentation operations to optimize.
- I did not use GradualWarmupScheduler for training on .
(I did for training Baseline and FAA final model)
- I did not use parallel or distributed training using ray or horovod.
## ETC
- Testing: FAA official implementation `python train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10`
- It runs validation steps with the same 16 images every 10th epoch (AutoAugment set 7,325 images aside for validation).
- The images used in the validation phase are augmented with the optimal policies, unlike my previous expectation that we do NOT augment the validation dataset for a normal training loop.
- The image batches loaded from validloader are as follows:
- 
- On FAA paper, Algorithm 1 decribed on page 5 can be somewhat misleading.
- 
- For the number of search width , we select top policies in . Hence with and , we end up with 20(2x10) top policies each split. However, on page 6, the paper says "Select the top N best policies for each split". Either one of these explanations should be corrected.
## Contact for Issues
- Junsik Hwang, junsik.whang@gmail.com
## References & Opensources
1. Fast AutoAugment
- Paper: https://arxiv.org/abs/1905.00397
- Codes: https://github.com/kakaobrain/fast-autoaugment
- GradualWarmupScheduler: https://github.com/ildoonet/pytorch-gradual-warmup-lr
2. AutoAugment
- Paper: https://arxiv.org/abs/1805.09501
- Codes:https://github.com/tensorflow/models/tree/master/research/autoaugment
3. Wide Residual Network
- Paper: https://arxiv.org/pdf/1605.07146v2.pdf
- Codes: https://github.com/meliketoy/wide-resnet.pytorch
4. HyperOpt
- Official Documentation: [http://hyperopt.github.io/hyperopt/](http://hyperopt.github.io/hyperopt/)
- Tutorials: https://medium.com/district-data-labs/parameter-tuning-with-hyperopt-faa86acdfdce
5. FloydHub (Cloud GPU)
- Website: [http://floydhub.com/](http://floydhub.com/)