# MoLE
**Repository Path**: guizhiyu/MoLE
## Basic Information
- **Project Name**: MoLE
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: MIT
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-07-03
- **Last Updated**: 2025-07-03
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# MoLE
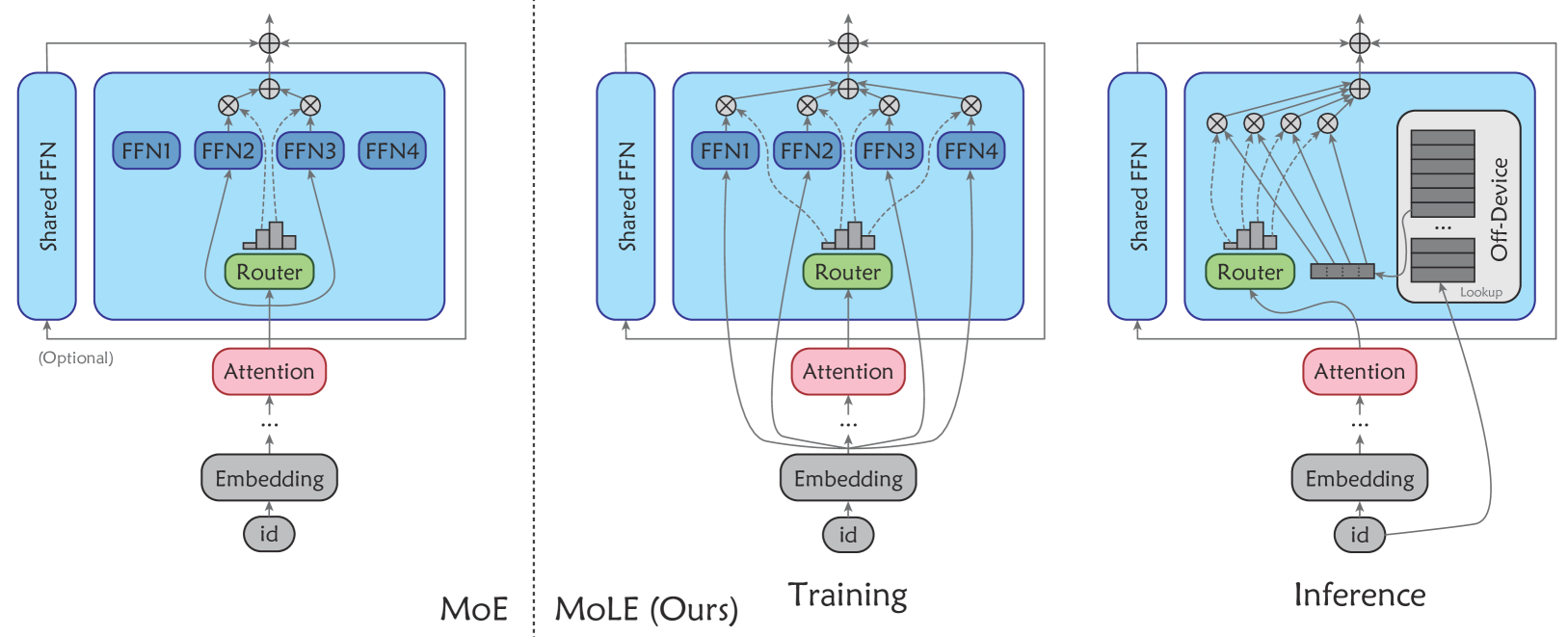
Official code of ''Mixture of Lookup Experts''.

MoLE is a novel edge-friendly LLM architecture. With the same number of activated parameters, MoLE achieves:
+ Latency and memory overhead comparable to dense models
+ Performance on par with Mixture-of-Experts (MoE) models.
## Environment
+ torch 2.0.1
+ transformers 4.38.2
## Pretraining
Please refer to ```pretrain``` folder.
## Models
#### Dense Models
+ modeling_dense.py
#### Moe Models
+ modeling_moe.py
#### MoLE Models
+ modeling_mole.py (for training)
+ modeling_mole_rep.py (for inference)
## Checkpoints
All these models are trained on a 100B-token subset of the [Pile](https://github.com/EleutherAI/the-pile) dataset.
For the MoLE model, we only provide the checkpoints before re-parameterization (i.e., for the training phase). Re-parameterization can be performed using the script provided below.
| Models | # Activated Params | URL |
| ----- | ----- | ---|
| Dense | 160M | 🤗 [JieShibo/Dense-160M](https://huggingface.co/JieShibo/Dense-160M) |
| MoE-10E | 160M | 🤗 [JieShibo/MoE-160M-10E](https://huggingface.co/JieShibo/MoE-160M-10E) |
| MoLE-4E | 160M | 🤗 [JieShibo/MoLE-160M-4E](https://huggingface.co/JieShibo/MoLE-160M-4E)|
| MoE-34E | 160M | 🤗 [JieShibo/MoE-160M-34E](https://huggingface.co/JieShibo/MoE-160M-34E) |
| MoLE-16E | 160M | 🤗 [JieShibo/MoLE-160M-16E](https://huggingface.co/JieShibo/MoLE-160M-16E)|
| Dense | 410M | 🤗 [JieShibo/Dense-410M](https://huggingface.co/JieShibo/Dense-410M) |
| MoE-10E | 410M | 🤗 [JieShibo/MoE-410M-10E](https://huggingface.co/JieShibo/MoE-410M-10E) |
| MoLE-4E | 410M | 🤗 [JieShibo/MoLE-410M-4E](https://huggingface.co/JieShibo/MoLE-410M-4E)|
## Reparameterize MoLE for Inference
```bash
python reparameterize.py --from_path --to_path
```
## Inference
```python3
from transformers import AutoTokenizer
from modeling_mole_rep import MoleForCausalLM
model = MoleForCausalLM.from_pretrained(model_path, device_map='cuda')
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
inputs = tokenizer("Hello, I am", return_tensors="pt").to(model.device)
tokens = model.generate(**inputs, max_length=10)
print(tokenizer.decode(tokens[0]))
```
Note that since the offloading of LUTs involves the support of the file system, the above demo still puts LUTs in the GPU memory. Alternatively, you can try the following demo, which offloads LUTs to CPU memory. This demo has not been specially optimized, so there may be some inefficiencies.
```python3
from transformers import AutoTokenizer
from modeling_mole_rep import MoleForCausalLM
model = MoleForCausalLM.from_pretrained(model_path, device_map='cpu')
model.model.embed_tokens.cuda()
model.model.layers.cuda()
model.model.norm.cuda()
model.lm_head.cuda()
model.model._buffers["causal_mask"] = model.model._buffers["causal_mask"].cuda()
model.model.moe_table.weight.data = model.model.moe_table.weight.data.pin_memory()
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
inputs = tokenizer("Hello, I am", return_tensors="pt").to('cuda')
tokens = model.generate(**inputs, max_length=10)
print(tokenizer.decode(tokens[0]))
```
## Citation
```
@article{jie2025mole,
title={Mixture of Lookup Experts},
author={Jie, Shibo and Tang, Yehui and Han, Kai and Li, Yitong and Tang, Duyu and Deng, Zhi-Hong and Wang, Yunhe},
journal={arXiv preprint arXiv:2503.15798},
year={2025}
}
```