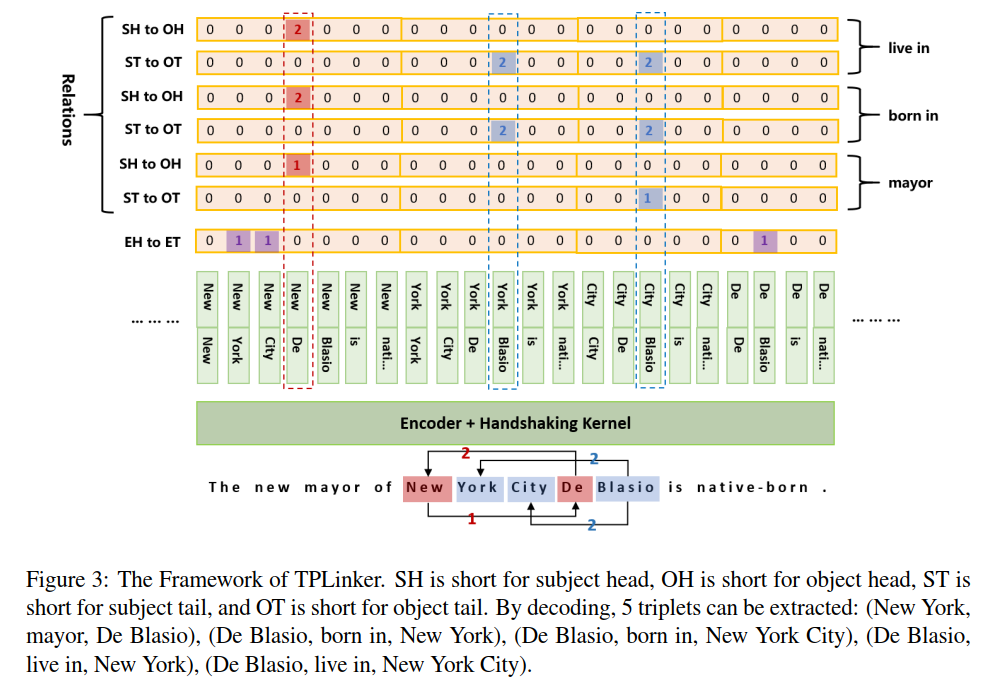
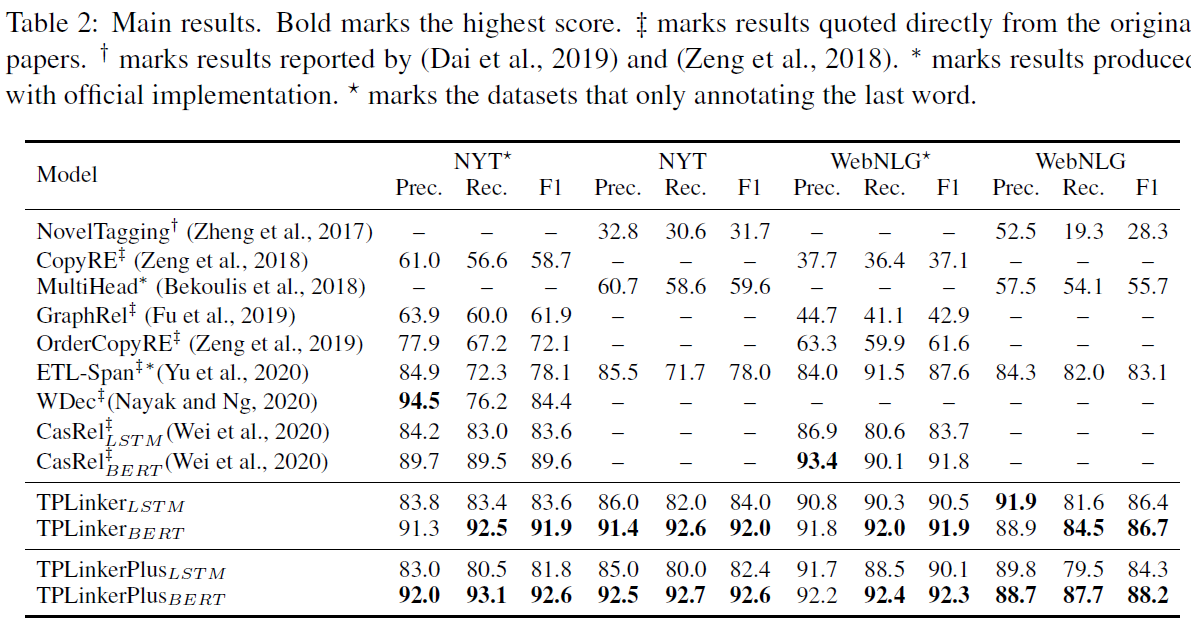
# TTPP
**Repository Path**: hawkwoodd/ttpp
## Basic Information
- **Project Name**: TTPP
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2023-10-20
- **Last Updated**: 2024-11-01
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
<<<<<<< HEAD
# TPLinker
**TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking**
This repository contains all the code of the official implementation for the paper: **[TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking](https://www.aclweb.org/anthology/2020.coling-main.138.pdf).** The paper has been accepted to appear at **COLING 2020**. \[[slides](https://drive.google.com/file/d/1UAIVkuUgs122k02Ijln-AtaX2mHz70N-/view?usp=sharing)\] \[[poster](https://drive.google.com/file/d/1iwFfXZDjwEz1kBK8z1To_YBWhfyswzYU/view?usp=sharing)\]
TPLinker is a joint extraction model resolved the issues of **relation overlapping** and **nested entities**, immune to the influence of **exposure bias**, and achieves SOTA performance on NYT (TPLinker: **91.9**, TPlinkerPlus: **92.6 (+3.0)**) and WebNLG (TPLinker: **91.9**, TPlinkerPlus: **92.3 (+0.5)**). Note that the details of TPLinkerPlus will be published in the extended paper, which is still in progress.
**Note: Please refer to Q&A and closed issues to find your question before proposed a new issue.**
- [Model](#model)
- [Results](#results)
- [Usage](#usage)
* [Prerequisites](#prerequisites)
* [Data](#data)
+ [download data](#download-data)
+ [build data](#build-data)
* [Pretrained Model and Word Embeddings](#pretrained-model-and-word-embeddings)
* [Train](#train)
+ [super parameters](#super-parameters)
* [Evaluation](#evaluation)
- [Citation](#citation)
- [Q&A](#frequently-asked-questions)
## Update
* 2020.11.01: Fixed bugs and added comments in BuildData.ipynb and build_data_config.yaml; TPLinkerPlus can support entity classification now, see [build data](#build-data) for the data format; Updated the [datasets](#download-data) (added `entity_list` for TPLinkerPlus).
* 2020.12.04: The original default parameters in `build_data_config.yaml` are all for Chinese datasets. It might be misleading for reproducing the results. I changed back to the ones for English datasets. **Note that you must set `ignore_subword` to `true` for English datasets**, or it will hurt the performance and can not reach the scores reported in the paper.
* 2020.12.09: We published model states for fast tests. See [Super Parameters](#super-parameters).
* 2021.03.22: Add Q&A part in README.
## Model
## Results
## Usage
### Prerequisites
Our experiments are conducted on Python 3.6 and Pytorch == 1.6.0.
The main requirements are:
* tqdm
* glove-python-binary==0.2.0
* transformers==3.0.2
* wandb # for logging the results
* yaml
In the root directory, run
```bash
pip install -e .
```
### Data
#### download data
Get and preprocess NYT* and WebNLG* following [CasRel](https://github.com/weizhepei/CasRel/tree/master/data) (note: named NYT and WebNLG by CasRel).
Take NYT* as an example, rename train_triples.json and dev_triples.json to train_data.json and valid_data.json and move them to `ori_data/nyt_star`, put all test*.json under `ori_data/nyt_star/test_data`. The same process goes for WebNLG*.
Get raw NYT from [CopyRE](https://github.com/xiangrongzeng/copy_re), rename raw_train.json and raw_valid.json to train_data.json and valid_data.json and move them to `ori_data/nyt`, rename raw_test.json to test_data.json and put it under `ori_data/nyt/test_data`.
Get WebNLG from [ETL-Span](https://github.com/yubowen-ph/JointER/tree/master/dataset/WebNLG/data), rename train.json and dev.json to train_data.json and valid_data.json and move them to `ori_data/webnlg`, rename test.json to test_data.json and put it under `ori_data/webnlg/test_data`.
If you are bother to prepare data on your own, you could download our preprocessed [datasets](https://drive.google.com/file/d/1RxBVMSTgBxhGyhaPEWPdtdX1aOmrUPBZ/view?usp=sharing).
#### build data
Build data by `preprocess/BuildData.ipynb`.
Set configuration in `preprocess/build_data_config.yaml`.
In the configuration file, set `exp_name` corresponding to the directory name, set `ori_data_format` corresponding to the source project name of the data.
e.g. To build NYT*, set `exp_name` to `nyt_star` and set `ori_data_format` to `casrel`. See `build_data_config.yaml` for more details.
If you want to run on other datasets, transform them into the normal format for TPLinker, then set `exp_name` to `` and set `ori_data_format` to `tplinker`:
```python
[{
"id": ,
"text": ,
"relation_list": [{
"subject": ,
"subj_char_span": , # e.g [3, 10] This key is optional. If no this key, set "add_char_span" to true in "build_data_config.yaml" when you build the data
"object":