# web-form-ui-field-detection
**Repository Path**: hf-models/web-form-ui-field-detection
## Basic Information
- **Project Name**: web-form-ui-field-detection
- **Description**: Mirror of https://huggingface.co/foduucom/web-form-ui-field-detection
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2024-05-20
- **Last Updated**: 2024-06-09
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
---
tags:
- web form detection
- form detection
- ui form detection
- form detect
- ui form detect
- web form ui detection
- Web form recognition
- Form field detection
- Form element detection
- Form field extraction
- Form structure analysis
- User interface form detection
- Web form parser
- Data extraction from forms
- Form input identification
- Form layout analysis
- Form boundary detection
- UI component recognition
- Form field segmentation
- Form element extraction
- Form data extraction
- Form field recognition
- Form text extraction
- Form structure detection
- Form field localization
- Web form layout analysis
model-index:
- name: foduucom/web-form-ui-field-detection
results:
- task:
type: object-detection
metrics:
- type: precision
value: 0.52196
name: mAP@0.95(box)
language:
- en
metrics:
- accuracy
pipeline_tag: object-detection
---
# Model architecture
# Model Overview
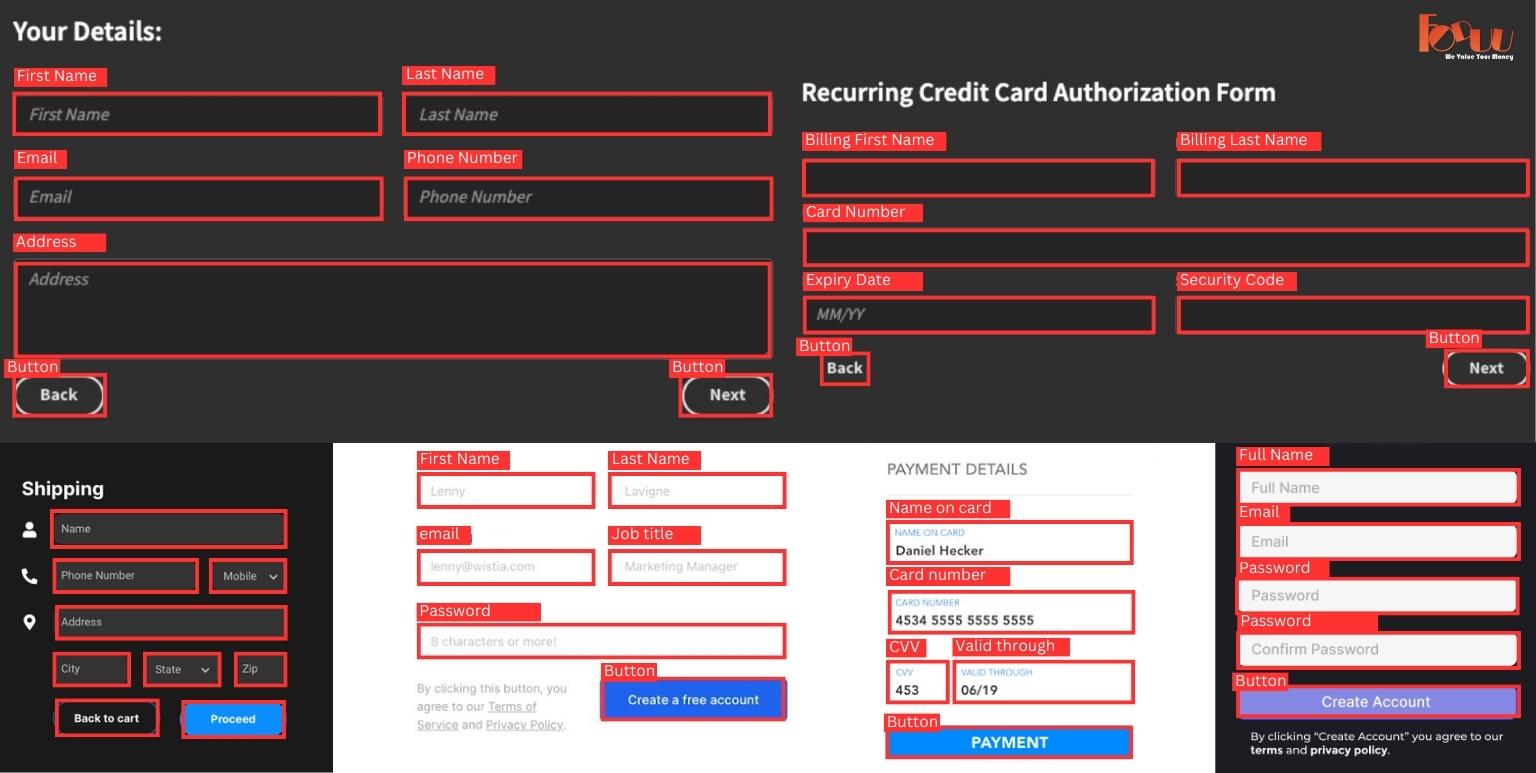
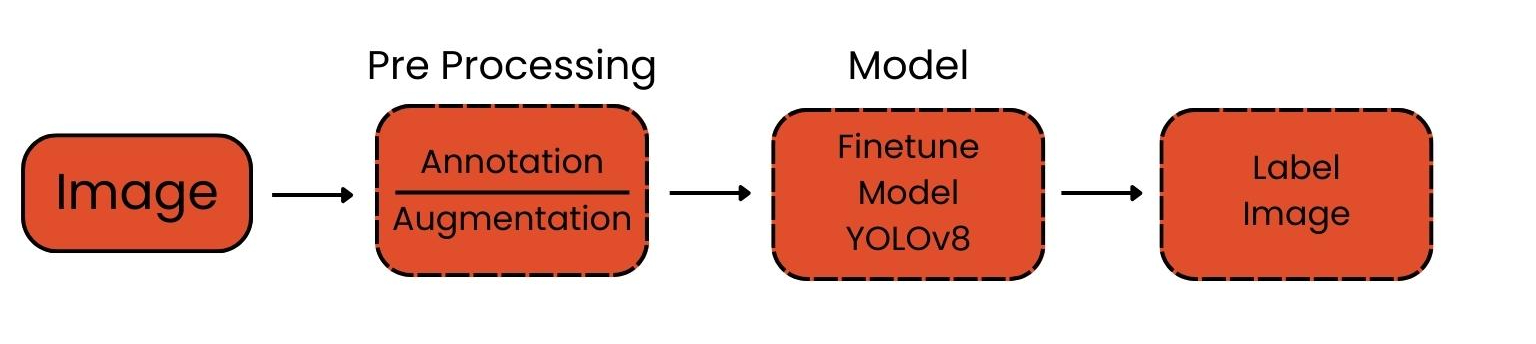
The web-form-Detect model is a yolov8 object detection model trained to detect and locate ui form fields in images. It is built upon the ultralytics library and fine-tuned using a dataset of annotated ui form images.
## Intended Use
The model is intended to be used for detecting details like Name,number,email,password,button,redio bullet and so on fields in images. It can be incorporated into applications that require automated detection ui form fields from images.
## Performance
The model has been evaluated on a held-out test dataset and achieved the following performance metrics:
Average Precision (AP): 0.51
Precision: 0.80
Recall: 0.70
F1 Score: 0.71
Please note that the actual performance may vary based on the input data distribution and quality.
## How to Get Started with the Model
To get started with the YOLOv8s object Detection model use for web ui detection, follow these steps:
```bash
pip install ultralyticsplus==0.0.28 ultralytics==8.0.43
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('foduucom/web-form-ui-field-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = '/path/to/your/document/images'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
## Training Data
The model was trained on a diverse dataset containing images of web ui form data from different sources, resolutions, and lighting conditions. The dataset was annotated with bounding box coordinates to indicate the location of the ui form fields within the image.
Total Number of Images: 600
Annotation Format: Bounding box coordinates (xmin, ymin, xmax, ymax)
## Fine-tuning Process
- Pretrained Model: TheError: Errors in your YAML metadata model was initialized with a pretrained object detection backbone (e.g. YOLO).
- Loss Function: Mean Average Precision (mAP) loss was used for optimization during training.
- Optimizer: Adam optimizer with a learning rate of 1e-4.
- Batch Size:-1
- Training Time: 1 hours on a single NVIDIA GeForce RTX 3090 GPU.
## Model Limitations
The model's performance is subject to variations in image quality, lighting conditions, and image resolutions.
The model may struggle with detecting web ui form in cases of extreme occlusion.
The model may not generalize well to non-standard ui form formats or variations.
#### Software
The model was trained and fine-tuned using a Jupyter Notebook environment.
## Model Card Contact
For inquiries and contributions, please contact us at info@foduu.com.
```bibtex
@ModelCard{
author = {Nehul Agrawal and
Rahul parihar},
title = {YOLOv8s web-form ui fields detection},
year = {2023}
}
```
---