标签中的文本,模型效果有一定的提升,根据观察可得,包含
的html语句大部分也是正常的文本对,其中包括了一定数量的sum数据集,对其进行过滤会导致优质sum数据集数量不足。因此,不对
的数据进行过滤。 - **filter_no_sum**: 排除包含摘要、总结等关键词的数据,在混合数据集中,我们不希望加入数据的数据集和总结的数据集。 - **filter_other_language**: 排除非目标语言的数据,如德语,法语等,仅留下中文和英文数据集。 - **filter_sum_data**: 专门筛选包含摘要、总结等关键词的总结数据,用于增强总结能力。 - **filter_math_data**: 筛选包含数学内容的数据,通过多种规则匹配(如正则匹配,等式检测)筛选出包含数学等式的数据,用于增强数学能力。 ## 数据处理 ### 生成混合数据集 **generate_mixture**: 从多个数据源中生成混合数据集。首先,对每个数据源应用过滤器,然后平衡文本长度分布,最后从平衡后的数据集中采样生成最终的混合数据集。 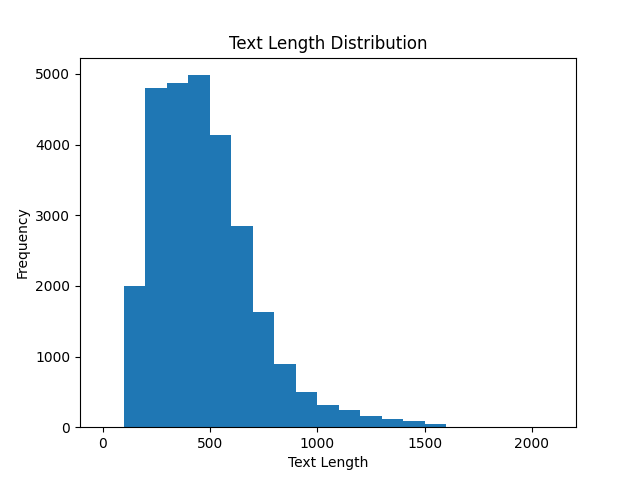 以下是平衡之后的数据长度分布: 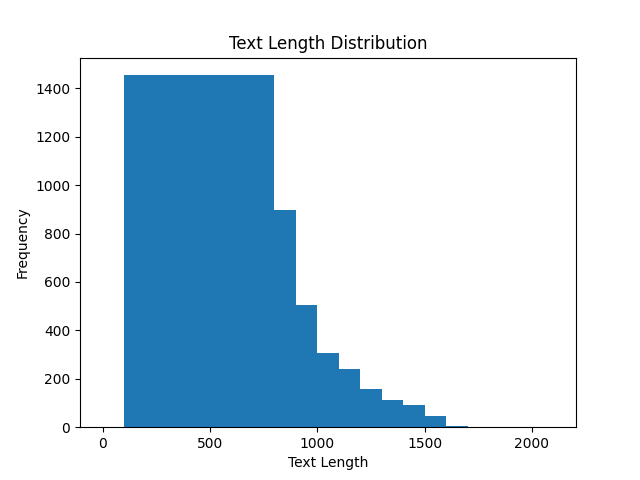 以下是我们的生成混合数据集所包含所有的算法处理的代码: ```python def calc_total(data): return (filter_data(data) and filter_no_high_code(data) and filter_input_url(data) and filter_no_html_code(data) and 100 < len(data['output']) < 1500 and filter_no_sum(data) and filter_other_language(data)) ``` 为保证数据长度分布的平衡,我们对其使用了均衡算法,以每100个长度片为一组,计算各组的平均数量,设置该值为长度阈值,对所有组进行数量的随机筛取,以下是数据的原始分布: 同时,我们观测了评测集中我们发现在这三个任务上提升改变较大:scrolls_summscreenfd,gsm8k, truthfulqa_mc。我们根据测试集输出分布,对我们的训练集进行了进一步的筛选和过滤。 ### 生成数学和摘要数据集 **generate_sum_math**: 生成包含数学问题和摘要的特定数据集。这涉及到从数据源中筛选出符合数学和摘要条件的数据,并进行采样。 在生成数学和摘要数据集时,我们基本保持和生成混合数据集一致的思路,但需要对数学和摘要数据集进行进一步的筛选和过滤。 以下是生成数学数据集的代码: ```python def total_math(data): return (filter_data(data) and filter_no_high_code(data) and filter_input_url(data) and filter_no_html_code(data) and 25 < len(data['output']) < 1000 and filter_no_sum(data) and filter_other_language(data) and filter_math_data(data)) ``` 以下是生成摘要数据集的代码: ```python def total_sum(data): return (filter_data(data) and filter_no_high_code(data) and filter_input_url(data) and filter_sum_data(data)) ``` 其中,特别指出,数学数据集的摘要过滤是基于正则以及条件匹配,通过正则匹配数学计算式,以及相当数量的数字(我们希望模型能够对数字数据敏感)来过滤数学的数据。 ```python def filter_math_data(data): pattern = r'\d+' # 正则表达式匹配数字 count = len(re.findall(pattern, data["text"])) # 统计匹配到的数字数量 if len(data["text"]) > 500: return False if count > 50: return False smb = any([i in data["text"] for i in ["+", "*", "plus", "equal", "="]]) return count > 6 and smb ``` 通过正则匹配摘要关键词来过滤摘要数据集。以下是我们的过滤条件: ````python def filter_sum_data(data): if any([each in data["text"].lower() for each in ["sum ", "abstract", " summari", "概要", "总结", "摘要", "概括"]]): return True return False ```` 以上算子的设置都是基于启发式方法,我们团队在上百次实验统计后的后经验结果。 ## 对去重和合并 去重和合并是数据集生成中的重要步骤,我们在实验了多种去重和合并方法后,选择了基于句子嵌入和余弦相似度的方法。 我们使用了[sentence-transformers/paraphrase-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2)模型对句子进行sentence embedding,使用余弦相似度来计算两两之间的距离。设置句子不同的判断阈值为0.92,采用概率的方法进行去重(即检测到相似度超过阈值的,则在p概率下进行保留)。考虑到中英文的相同语义可能对模型的作用不一样,我们对中英文进行了分别的处理,然后在进行简单合并。 ### 合并数据集 - **concat_dataset**: 将去重后的数据集和数学及摘要数据集合并,形成最终的数据集。为避免模型在训练的时候,由于数据分布的不均衡(比如后面全是总结数据集)而偏向于某类数据,我们采用了交叉的方式进行合并。 ## 参数设置 在整个采样策略中,通过`params_dict`和`params_dict_all`字典定义了各个数据源及其对应的采样数量。这些参数在生成混合数据集和数学及摘要数据集时被用来控制从每个数据源中采样的数据量。 ```python ratio = 0.70 params_dict = { "alpaca_data.jsonl": int(1000 * ratio), "alpaca_gpt4_data.jsonl": int(4000 * ratio), "belle_data0.5M_cn.jsonl": int(5000 * ratio), "COIG_translate_en.jsonl": int(2000 * ratio), "dolly.jsonl": int(1000 * ratio), "finance_en.jsonl": int(1000 * ratio), "gpt4all.jsonl": int(3000 * ratio), "HC3_Chinese_Human.jsonl": int(500 * ratio), "HC3_Human.jsonl": int(3000 * ratio), "instinwild_en.jsonl": int(2500 * ratio), "instruct.jsonl": int(4000 * ratio), "sharegpt.jsonl": int(4000 * ratio), "Vicuna.jsonl": int(1000 * ratio),} params_dict_all = { "alpaca_data.jsonl": int(1000 * ratio), "alpaca_gpt4_data.jsonl": int(4000 * ratio), "alpaca_gpt4_data_zh.jsonl": int(1000 * ratio), "belle_data0.5M_cn.jsonl": int(5000 * ratio), "dolly.jsonl": int(1000 * ratio), "COIG_translate_en.jsonl": int(2000 * ratio), "finance_en.jsonl": int(1000 * ratio), "gpt4all.jsonl": int(3000 * ratio), "GPTeacher.jsonl": int(2000 * ratio), "HC3_Chinese_Human.jsonl": int(500 * ratio), "HC3_Human.jsonl": int(3000 * ratio), "instinwild_en.jsonl": int(2500 * ratio), "instruct.jsonl": int(4000 * ratio), "sharegpt.jsojsonl": int(4000 * ratio), "Vicuna.jsonl": int(1000 * ratio),} ``` 学习率我们采用了1e-3的较大学习率,同时设置SFT_PACKING=False,INT8=False。 ## 总结 我们通过一系列精细的过滤和采样步骤,从多个数据源中筛选出高质量的数据。通过调整过滤器条件和采样参数,可以灵活地生成满足不同需求的数据集。可惜的是,我们并没有采用任何RLHF的方法,因此在数学任务的表现上一般,提升并不是很大。