# sharding-jdbc
**Repository Path**: ldtianzhe/sharding-jdbc
## Basic Information
- **Project Name**: sharding-jdbc
- **Description**: shardingjdbc study
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2021-04-12
- **Last Updated**: 2021-04-12
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# ShardingSphere
## 1、ShardingJdbc的概述
> ### 1.1 概述
> 官网:[https://shardingsphere.apache.org/index_zh.html](https://shardingsphere.apache.org/index_zh.html)
>
> 下载地址:https://shardingsphere.apache.org/document/current/cn/downloads/
>
> 快速入门:https://shardingsphere.apache.org/document/current/cn/quick-start/

以下来自官网原话
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
> ### 1.2 关于改名问题
在3.0以后就更改成了ShardingSphere
> ### 1.3 认识shardingjdbc
 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
> ### 1.4 认识shardingjdbc功能架构图
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
> ### 1.4 认识shardingjdbc功能架构图
 > ### 1.5 认识Sharding-Proxy
> ### 1.5 认识Sharding-Proxy
 **定位为Kubernetes的云原生数据库代理,以Sidecar的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。**
* 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用
* 适用于任何兼容 MySQL/PostgreSQL 协议的客户端
> ### 1.6 三个组件的比较
| | Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar |
| :--------- | :------------ | :------------- | :--------------- |
| 数据库 | 任意 | MySQL | MySQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
> ### 1.7 ShardingJdbc混合架构
**定位为Kubernetes的云原生数据库代理,以Sidecar的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。**
* 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用
* 适用于任何兼容 MySQL/PostgreSQL 协议的客户端
> ### 1.6 三个组件的比较
| | Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar |
| :--------- | :------------ | :------------- | :--------------- |
| 数据库 | 任意 | MySQL | MySQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
> ### 1.7 ShardingJdbc混合架构
 Sharding-JDBC采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;Sharding-Proxy提供静态入口以及异构语言的支持,适用于OLAP应用以及对分片数据库进行管理和运维的场景。
ShardingSphere是多接入端共同组成的生态圈。 通过混合使用Sharding-JDBC和Sharding-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,架构师可以更加自由的调整适合于当前业务的最佳系统架构。
> ### 1.8 ShardingShpere的功能清单
### 数据分片
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
### 分布式事务
- 标准化事务接口
- XA强一致事务
- 柔性事务
### 数据库治理
- 配置动态化
- 编排 & 治理
- 数据脱敏
- 可视化链路追踪
- 弹性伸缩(规划中)
> ### 1.9 ShardingSphere数据分片内核剖析
ShardingSphere的3个产品的数据分片主要流程是完全一致的。核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
Sharding-JDBC采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;Sharding-Proxy提供静态入口以及异构语言的支持,适用于OLAP应用以及对分片数据库进行管理和运维的场景。
ShardingSphere是多接入端共同组成的生态圈。 通过混合使用Sharding-JDBC和Sharding-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,架构师可以更加自由的调整适合于当前业务的最佳系统架构。
> ### 1.8 ShardingShpere的功能清单
### 数据分片
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
### 分布式事务
- 标准化事务接口
- XA强一致事务
- 柔性事务
### 数据库治理
- 配置动态化
- 编排 & 治理
- 数据脱敏
- 可视化链路追踪
- 弹性伸缩(规划中)
> ### 1.9 ShardingSphere数据分片内核剖析
ShardingSphere的3个产品的数据分片主要流程是完全一致的。核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
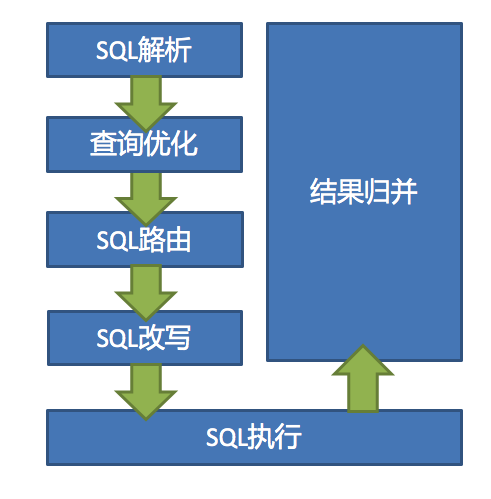 ### `SQL解析`
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
### `执行器优化`
合并和优化分片条件,如OR等。
### `SQL路由`
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
### `SQL改写`
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
### `SQL执行`
通过多线程执行器异步执行。
### `结果归并`
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
## 2、ShardingJdbc准备-Linux安装MySQL5.7
> 此处使用docker安装mysql5.7
### 2.1、安装Docker
> 第一步 卸载旧版本
```shell
#卸载旧版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
```
> 第二步 需要的安装包
```shell
#需要的安装包
yum install -y yum-utils
```
> 第三步 设置镜像的仓库
```shell
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
```
> 第四步 安装
```shell
#更新 yum软件包索引
yum makecache fast
#安装docker相关的 docker-ce 社区版 ee 企业版
yum install docker-ce docker-ce-cli containerd.io
```
`如果是在虚拟机中安装docker的话,在第三步设置镜像仓库时可能会报错解析不了域名`
`Could not fetch/save url http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo to file /etc/yum.repos.d/docker-ce.repo: [Errno 14] curl#6 - "Could not resolve host: mirrors.aliyun.com; 未知的错误"`
解决方法:
ifcfg-eth0视自己实际情况进行修改
```shell
vi /etc/sysconfig/network-scripts/ifcfg-eth0
#添加DNS1为本机DNS地址
#添加DNS2为8.8.8.8
#重启network即可
systemctl restart network
```
### 2.2、 启动Docker
```shell
[root@localhost ~]# systemctl start docker
[root@localhost ~]# docker version
Client: Docker Engine - Community
Version: 20.10.5
API version: 1.41
Go version: go1.13.15
Git commit: 55c4c88
Built: Tue Mar 2 20:33:55 2021
OS/Arch: linux/amd64
Context: default
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 20.10.5
API version: 1.41 (minimum version 1.12)
Go version: go1.13.15
Git commit: 363e9a8
Built: Tue Mar 2 20:32:17 2021
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.4.4
GitCommit: 05f951a3781f4f2c1911b05e61c160e9c30eaa8e
runc:
Version: 1.0.0-rc93
GitCommit: 12644e614e25b05da6fd08a38ffa0cfe1903fdec
docker-init:
Version: 0.19.0
GitCommit: de40ad0
```
可以通过docker version查看到版本信息即为成功
### 2.3、安装MySQL5.7
> 第一步:拉取mysql镜像
```shell
docker pull mysql:5.7
```
> 第二步:启动mysql
```shell
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
#如果想要在重启docker时重启mysql
docker run --restart always -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
#如果已经用第一行命令启动了,可以通过update命令修改
docker update --restart always mysql
```
> 第三步:授权
```mysql
use mysql;
update user set host = '%' where user = 'root';
grant all on *.* to 'root'@'%' identified by '123456';
flush privileges;
```
使用navicat连接 测试
`如果授权不成功,可以查看防火墙状态开放3306端口或者通过 ufw disable 关闭防火墙 ,开启命令是 ufw enable`
## 3、ShardingJdbc准备-MySQL完成主从复制
### `概述`
主从复制(也称AB复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
> 复制的异步的 从站不需要永久连接以接收来自主站的更新。
根据配置,您可以复制数据库中的所有数据库,所选数据库甚至选定的表。
### `01、MySQL中复制的有点包括:`
* 横向扩展解决方案 - 在多个从站之间分配负载以提高性能。在此环境中,所有写入和更新都必须在主服务器上进行。但是,读取可以在一个或者多个设备上进行。该模型可以提高写入性能(因为主设备专用于更新),同时显著提高了越来越多的从设备的读取速度。
* 数据安全性 - 因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
* 分析 - 可以在主服务器上创建实时数据,而信息分析可以在从服务器上进行,而不会影响主服务器的性能。
* 远程数据分发 - 您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
### `02、Replication 的原理`

> #### 02-1、前提是作为主服务器角色的数据库服务器必须开启二进制日志
主服务器上面的任何修改都会通过自己的I/O thread(I/O 线程)保存在二进制日志Binary log里面。
* 从服务器上面也启动一个I/O thread,通过配置好的用户名和密码,连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log(中继日志) 里面。
* 从服务器上面同时开启一个SQL thread 定时检查Realy log(这个文件也是二进制的),如果发现有更新立即把更新的内容在本机的数据库上面执行一遍。
每个从服务器都会收到主服务器二进制日志的全部内容的副本。
* 从服务器设备负责决定应该执行二进制日志中的哪些语句。
除非另行指定,否则主从二进制日志中的所有事件都在从站上执行。
如果需要,您可以将从服务器配置为仅处理一些特定数据库或表的事件。
### `03、具体配置如下`
> #### 03-01、Master节点配置 /etc/my.cnf(master节点执行)
非docker安装的mysql
```shell
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能
log-bin=mysql-bin
##复制过滤:不需要备份的数据库
binlog-ignore-db=mysql
## 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
##主从复制的格式(mixed,statement,row 默认格式是statement)
binlog_format=mixed
```
docker安装的mysql
因为docker安装的mysql镜像在容器内,所以docker安装的mysql需要先进入容器内再修改配
```shell
# 进入容器
docker exec -it mysql /bin/bash
# 镜像容器内没有安装vim工具,先安装vim
apt-get update
apt-get install vim
vi /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
## 同一局域网内注意要唯一
server-id=100
##开启二进制日志功能
log-bin=mysql-bin
##复制过滤:不需要备份的数据库
binlog-ignore-db=mysql
##为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
##主从复制的格式(mixed,statement,row 默认格式是statement)
binlog_format=mixed
```
> #### 03-02、Slave节点配置 /etc/my.cnf(slave节点执行)
非docker安装的mysql
```shell
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
server-id=101
##开启二进制日志功能,以备slave作为其他slave的master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
##复制过滤:不需要备份的数据库
binlog-ignore-db=mysql
## 如果需要同步函数或者存储过程
log_bin_trust_function_creators=true
## 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
##主从复制的格式(mixed,statement,row 默认格式是statement)
binlog_format=mixed
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
```
docker安装的mysql
```shell
# 进入容器
docker exec -it mysql /bin/bash
# 镜像容器内没有安装vim工具,先安装vim
apt-get update
apt-get install vim
vi /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
server-id=101
log-bin=mysql-slave-bin
relay_log=edu-mysql-relay-bin
binlog-ignore-db=mysql
log_bin_trust_function_creators=true
binlog_cache_size=1M
binlog_format=mixed
slave_skip_errors=1062
```
> #### 03-03、在master服务器授权slave服务器可以同步权限(master节点执行)
`注意: 在master服务器上执行`
```mysql
mysql -uroot -p123456
grant replication slave, replication client on *.* to 'root'@'slave服务器的ip' identified by 'slave服务器数据库的密码';
flush privileges;
#查看mysql现在有哪些用户及对应的ip权限(可以不执行,只是一个查看)
select user,host from mysql.user;
```
### `SQL解析`
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
### `执行器优化`
合并和优化分片条件,如OR等。
### `SQL路由`
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
### `SQL改写`
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
### `SQL执行`
通过多线程执行器异步执行。
### `结果归并`
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
## 2、ShardingJdbc准备-Linux安装MySQL5.7
> 此处使用docker安装mysql5.7
### 2.1、安装Docker
> 第一步 卸载旧版本
```shell
#卸载旧版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
```
> 第二步 需要的安装包
```shell
#需要的安装包
yum install -y yum-utils
```
> 第三步 设置镜像的仓库
```shell
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
```
> 第四步 安装
```shell
#更新 yum软件包索引
yum makecache fast
#安装docker相关的 docker-ce 社区版 ee 企业版
yum install docker-ce docker-ce-cli containerd.io
```
`如果是在虚拟机中安装docker的话,在第三步设置镜像仓库时可能会报错解析不了域名`
`Could not fetch/save url http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo to file /etc/yum.repos.d/docker-ce.repo: [Errno 14] curl#6 - "Could not resolve host: mirrors.aliyun.com; 未知的错误"`
解决方法:
ifcfg-eth0视自己实际情况进行修改
```shell
vi /etc/sysconfig/network-scripts/ifcfg-eth0
#添加DNS1为本机DNS地址
#添加DNS2为8.8.8.8
#重启network即可
systemctl restart network
```
### 2.2、 启动Docker
```shell
[root@localhost ~]# systemctl start docker
[root@localhost ~]# docker version
Client: Docker Engine - Community
Version: 20.10.5
API version: 1.41
Go version: go1.13.15
Git commit: 55c4c88
Built: Tue Mar 2 20:33:55 2021
OS/Arch: linux/amd64
Context: default
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 20.10.5
API version: 1.41 (minimum version 1.12)
Go version: go1.13.15
Git commit: 363e9a8
Built: Tue Mar 2 20:32:17 2021
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.4.4
GitCommit: 05f951a3781f4f2c1911b05e61c160e9c30eaa8e
runc:
Version: 1.0.0-rc93
GitCommit: 12644e614e25b05da6fd08a38ffa0cfe1903fdec
docker-init:
Version: 0.19.0
GitCommit: de40ad0
```
可以通过docker version查看到版本信息即为成功
### 2.3、安装MySQL5.7
> 第一步:拉取mysql镜像
```shell
docker pull mysql:5.7
```
> 第二步:启动mysql
```shell
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
#如果想要在重启docker时重启mysql
docker run --restart always -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
#如果已经用第一行命令启动了,可以通过update命令修改
docker update --restart always mysql
```
> 第三步:授权
```mysql
use mysql;
update user set host = '%' where user = 'root';
grant all on *.* to 'root'@'%' identified by '123456';
flush privileges;
```
使用navicat连接 测试
`如果授权不成功,可以查看防火墙状态开放3306端口或者通过 ufw disable 关闭防火墙 ,开启命令是 ufw enable`
## 3、ShardingJdbc准备-MySQL完成主从复制
### `概述`
主从复制(也称AB复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
> 复制的异步的 从站不需要永久连接以接收来自主站的更新。
根据配置,您可以复制数据库中的所有数据库,所选数据库甚至选定的表。
### `01、MySQL中复制的有点包括:`
* 横向扩展解决方案 - 在多个从站之间分配负载以提高性能。在此环境中,所有写入和更新都必须在主服务器上进行。但是,读取可以在一个或者多个设备上进行。该模型可以提高写入性能(因为主设备专用于更新),同时显著提高了越来越多的从设备的读取速度。
* 数据安全性 - 因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
* 分析 - 可以在主服务器上创建实时数据,而信息分析可以在从服务器上进行,而不会影响主服务器的性能。
* 远程数据分发 - 您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
### `02、Replication 的原理`

> #### 02-1、前提是作为主服务器角色的数据库服务器必须开启二进制日志
主服务器上面的任何修改都会通过自己的I/O thread(I/O 线程)保存在二进制日志Binary log里面。
* 从服务器上面也启动一个I/O thread,通过配置好的用户名和密码,连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log(中继日志) 里面。
* 从服务器上面同时开启一个SQL thread 定时检查Realy log(这个文件也是二进制的),如果发现有更新立即把更新的内容在本机的数据库上面执行一遍。
每个从服务器都会收到主服务器二进制日志的全部内容的副本。
* 从服务器设备负责决定应该执行二进制日志中的哪些语句。
除非另行指定,否则主从二进制日志中的所有事件都在从站上执行。
如果需要,您可以将从服务器配置为仅处理一些特定数据库或表的事件。
### `03、具体配置如下`
> #### 03-01、Master节点配置 /etc/my.cnf(master节点执行)
非docker安装的mysql
```shell
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能
log-bin=mysql-bin
##复制过滤:不需要备份的数据库
binlog-ignore-db=mysql
## 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
##主从复制的格式(mixed,statement,row 默认格式是statement)
binlog_format=mixed
```
docker安装的mysql
因为docker安装的mysql镜像在容器内,所以docker安装的mysql需要先进入容器内再修改配
```shell
# 进入容器
docker exec -it mysql /bin/bash
# 镜像容器内没有安装vim工具,先安装vim
apt-get update
apt-get install vim
vi /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
## 同一局域网内注意要唯一
server-id=100
##开启二进制日志功能
log-bin=mysql-bin
##复制过滤:不需要备份的数据库
binlog-ignore-db=mysql
##为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
##主从复制的格式(mixed,statement,row 默认格式是statement)
binlog_format=mixed
```
> #### 03-02、Slave节点配置 /etc/my.cnf(slave节点执行)
非docker安装的mysql
```shell
vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
server-id=101
##开启二进制日志功能,以备slave作为其他slave的master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
##复制过滤:不需要备份的数据库
binlog-ignore-db=mysql
## 如果需要同步函数或者存储过程
log_bin_trust_function_creators=true
## 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
##主从复制的格式(mixed,statement,row 默认格式是statement)
binlog_format=mixed
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
```
docker安装的mysql
```shell
# 进入容器
docker exec -it mysql /bin/bash
# 镜像容器内没有安装vim工具,先安装vim
apt-get update
apt-get install vim
vi /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
server-id=101
log-bin=mysql-slave-bin
relay_log=edu-mysql-relay-bin
binlog-ignore-db=mysql
log_bin_trust_function_creators=true
binlog_cache_size=1M
binlog_format=mixed
slave_skip_errors=1062
```
> #### 03-03、在master服务器授权slave服务器可以同步权限(master节点执行)
`注意: 在master服务器上执行`
```mysql
mysql -uroot -p123456
grant replication slave, replication client on *.* to 'root'@'slave服务器的ip' identified by 'slave服务器数据库的密码';
flush privileges;
#查看mysql现在有哪些用户及对应的ip权限(可以不执行,只是一个查看)
select user,host from mysql.user;
```
 > #### 03-04、查询master服务的binlog文件名和位置(master节点执行)
```mysql
show master status;
```
> #### 03-04、查询master服务的binlog文件名和位置(master节点执行)
```mysql
show master status;
```
 * 日志文件名:mysql-bin.000006
* 复制的位置:154
> #### 03-05、slave进行关联master节点(slave节点执行)
* 进入到slave节点
```shell
mysql -uroot -p123456
```
* 开始绑定
```mysql
change master to master_host='master服务器ip', master_user='root', master_password='master密码', master_port=3306, master_log_file='mysql-bin.000006', master_log_pos=154;
```
`这里注意一下master_log_file和master_log_pos都是通过在master服务器通过show master status获得。`
> #### 03-06、在slave节点上查看主从同步状态(slave节点执行)
**启动主从复制**
```mysql
start slave;
```
**再查看主从同步状态**
```mysql
mysql> show slave status\G;
```
* 日志文件名:mysql-bin.000006
* 复制的位置:154
> #### 03-05、slave进行关联master节点(slave节点执行)
* 进入到slave节点
```shell
mysql -uroot -p123456
```
* 开始绑定
```mysql
change master to master_host='master服务器ip', master_user='root', master_password='master密码', master_port=3306, master_log_file='mysql-bin.000006', master_log_pos=154;
```
`这里注意一下master_log_file和master_log_pos都是通过在master服务器通过show master status获得。`
> #### 03-06、在slave节点上查看主从同步状态(slave节点执行)
**启动主从复制**
```mysql
start slave;
```
**再查看主从同步状态**
```mysql
mysql> show slave status\G;
```
 > 其他命令(slave节点执行)
```mysql
## 停止复制
stop slave;
```
> #### 03-07、主从复制测试
1:在master下创建数据库和表,或者修改和新增,删除记录都会进行同步(master节点执行)
2:点击查看slave节点信息(slave节点执行)
> #### 03-08、切记
在主从复制操作的时候,不要基于去创建数据库或者相关操作。然后又去删除。这样会造成主从复制的pos改变,而造成复制失败,如果出现此类问题,查看`04-03`的常见问题排查。
### `04、主从复制相关问题排查`
> #### 04-01、主从复制Connection问题
> 其他命令(slave节点执行)
```mysql
## 停止复制
stop slave;
```
> #### 03-07、主从复制测试
1:在master下创建数据库和表,或者修改和新增,删除记录都会进行同步(master节点执行)
2:点击查看slave节点信息(slave节点执行)
> #### 03-08、切记
在主从复制操作的时候,不要基于去创建数据库或者相关操作。然后又去删除。这样会造成主从复制的pos改变,而造成复制失败,如果出现此类问题,查看`04-03`的常见问题排查。
### `04、主从复制相关问题排查`
> #### 04-01、主从复制Connection问题
 > 使用 `start slave` 开启主从复制过程后,如果SlaveIORunning一直是Connecting,则说明主从复制一直处于连接状态,这种情况一般是下面几种原因造成的,我们可以根据Last_IO_Error提示予以排除。
>
> 网络不通
>
> 检查ip,端口
>
> 检查是否创建用于同步的用户和用户密码是否正确
>
> pos不对
>
> 检查Master的 Position
> #### 04-02、MySQL镜像服务器因错误停止的恢复 ——Slave_SQL_Running:No
```mysql
#先stop slave,然后执行了一下提示的语句
stop slave;
set global sql_slave_skip_counter=1;
start slave;
show slave status\G;
```
> #### 04-03、从MySQL服务器Slave_IO_Running:No的解决
* master节点执行,获取日志文件和post
```mysql
show master status;
```
* slave节点进行重新绑定
```mysql
stop slave;
change master to master_host='master服务器ip, master_user='root', master_password='master密码', master_port=3306, master_log_file='mysql-bin.000006', master_log_pos=154;
start slave;
```
造成这类问题的原因一般是在主从复制的时候,基于创建表,然后又去删除和操作了数据库或者表。
## 4、ShardingJdbc的配置及读写分离
### `01、内容`
* 新建一个springboot工程
* 引入相关sharding依赖、springboot依赖、数据库驱动
* 定义配置application.yml
* 定义entity、mapper、controller
* 访问测试查看效果
* 小结
### `02、具体实现步骤`
案例[git地址](https://gitee.com/ldtianzhe/sharding-jdbc)
> #### 02-01、新建一个springboot工程
> 使用 `start slave` 开启主从复制过程后,如果SlaveIORunning一直是Connecting,则说明主从复制一直处于连接状态,这种情况一般是下面几种原因造成的,我们可以根据Last_IO_Error提示予以排除。
>
> 网络不通
>
> 检查ip,端口
>
> 检查是否创建用于同步的用户和用户密码是否正确
>
> pos不对
>
> 检查Master的 Position
> #### 04-02、MySQL镜像服务器因错误停止的恢复 ——Slave_SQL_Running:No
```mysql
#先stop slave,然后执行了一下提示的语句
stop slave;
set global sql_slave_skip_counter=1;
start slave;
show slave status\G;
```
> #### 04-03、从MySQL服务器Slave_IO_Running:No的解决
* master节点执行,获取日志文件和post
```mysql
show master status;
```
* slave节点进行重新绑定
```mysql
stop slave;
change master to master_host='master服务器ip, master_user='root', master_password='master密码', master_port=3306, master_log_file='mysql-bin.000006', master_log_pos=154;
start slave;
```
造成这类问题的原因一般是在主从复制的时候,基于创建表,然后又去删除和操作了数据库或者表。
## 4、ShardingJdbc的配置及读写分离
### `01、内容`
* 新建一个springboot工程
* 引入相关sharding依赖、springboot依赖、数据库驱动
* 定义配置application.yml
* 定义entity、mapper、controller
* 访问测试查看效果
* 小结
### `02、具体实现步骤`
案例[git地址](https://gitee.com/ldtianzhe/sharding-jdbc)
> #### 02-01、新建一个springboot工程
 > #### 02-02、引入相关sharding依赖、springboot依赖、数据库驱动
```xml
1.8
4.0.0-RC1
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.4
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
${sharding-sphere.version}
org.apache.shardingsphere
sharding-core-common
${sharding-sphere.version}
com.alibaba
druid-spring-boot-starter
1.2.4
```
> #### 02-03、定义配置application.yml
```yml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds1,ds2,ds3
# 给master-ds1每个数据源配置数据库连接信息
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds2:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
# 配置ds3-slave
ds3:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds1
#配置数据源的读写分离,但是数据库一定要做主从复制
masterslave:
# 配置主从名称,可以任意取名字
name: master
# 配置主库master,负责数据的写入
master-data-source-name: ds1
# 配置从库slave节点
slave-data-source-names: ds2,ds3
# 配置slave节点的负载均衡策略,默认轮询机制 round_robin ,如果想随机改 random
load-balance-algorithm-type: round_robin
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
> 注意问题:
>
> ```yml
> # 配置默认数据源ds1
> sharding:
> # 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
> default-data-source-name: ds1
> #配置数据源的读写分离,但是数据库一定要做主从复制
> masterslave:
> # 配置主从名称,可以任意取名字
> name: master
> # 配置主库master,负责数据的写入
> master-data-source-name: ds1
> # 配置从库slave节点
> slave-data-source-names: ds2,ds3
> # 配置slave节点的负载均衡策略,默认轮询机制 round_robin ,如果想随机改 random
> load-balance-algorithm-type: round_robin
> ```
>
> 如果上面的,那么shardingjdbc会采用随机的方式进行选择数据源。如果不配置 default-data-source-name,那么就会把三个节点都当做从slave节点,那么新增,修改和删除会出错。
> #### 02-04、定义mapper、controller、entity
`entity`
```java
@Data
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private Integer sex;
private Date birthday;
}
```
`mapper`
```java
@Mapper
public interface UserMapper {
@Insert("insert into t_user(name,password,age,sex,birthday) values(#{name},#{password},#{age},#{sex},#{birthday})")
@Options(useGeneratedKeys = true, keyColumn = "id", keyProperty = "id")
void addUser(User user);
@Select("select * from t_user")
List findUser();
}
```
`controller`
```java
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/save")
public String insert() {
User user = new User();
// user.setId(IdUtils.nextId());
user.setName("张三"+new Random().nextInt());
user.setPassword("123456");
user.setSex(1);
user.setBirthday(new Date());
userMapper.addUser(user);
return "success";
}
@GetMapping("/list")
public List listUser(){
return userMapper.findUser();
}
}
```
`sql`
```mysql
CREATE TABLE `t_user` (
`id` bigint(50) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`password` varchar(50) DEFAULT NULL,
`age` int(5) DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
`birthday` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
```
## 5、MySQL分库分表原理
### `01、为什么要分库分表`
一般的机器(4核16G),单库的MySQL并发(QPS+TPS)超过了2K,系统基本就完蛋了。最好是并发量控制在1K左右。这里就引出一个问题,为什么要分库分表?
> 分库分表目的:解决高并发,和数据量大的问题。
1、高并发情况下,会造成IO读写频繁,自然就会造成读写缓慢,甚至是宕机。一般单库不要超过2k并发,NB的机器除外。
2、数据量大的问题。主要由于底层索引实现导致,MySQL的索引实现为B+TREE,数据量其他,会导致索引树十分庞大,造成查询缓慢。第二,innodb的最大存储限制64TB。
> 要解决上述问题。最常见做法,就是分库分表。
>
> 分库分表的目的,是将一个表拆成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。一个表数据建议不要超过500W。
> #### 02-02、引入相关sharding依赖、springboot依赖、数据库驱动
```xml
1.8
4.0.0-RC1
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.4
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
${sharding-sphere.version}
org.apache.shardingsphere
sharding-core-common
${sharding-sphere.version}
com.alibaba
druid-spring-boot-starter
1.2.4
```
> #### 02-03、定义配置application.yml
```yml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds1,ds2,ds3
# 给master-ds1每个数据源配置数据库连接信息
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds2:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
# 配置ds3-slave
ds3:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds1
#配置数据源的读写分离,但是数据库一定要做主从复制
masterslave:
# 配置主从名称,可以任意取名字
name: master
# 配置主库master,负责数据的写入
master-data-source-name: ds1
# 配置从库slave节点
slave-data-source-names: ds2,ds3
# 配置slave节点的负载均衡策略,默认轮询机制 round_robin ,如果想随机改 random
load-balance-algorithm-type: round_robin
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
> 注意问题:
>
> ```yml
> # 配置默认数据源ds1
> sharding:
> # 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
> default-data-source-name: ds1
> #配置数据源的读写分离,但是数据库一定要做主从复制
> masterslave:
> # 配置主从名称,可以任意取名字
> name: master
> # 配置主库master,负责数据的写入
> master-data-source-name: ds1
> # 配置从库slave节点
> slave-data-source-names: ds2,ds3
> # 配置slave节点的负载均衡策略,默认轮询机制 round_robin ,如果想随机改 random
> load-balance-algorithm-type: round_robin
> ```
>
> 如果上面的,那么shardingjdbc会采用随机的方式进行选择数据源。如果不配置 default-data-source-name,那么就会把三个节点都当做从slave节点,那么新增,修改和删除会出错。
> #### 02-04、定义mapper、controller、entity
`entity`
```java
@Data
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private Integer sex;
private Date birthday;
}
```
`mapper`
```java
@Mapper
public interface UserMapper {
@Insert("insert into t_user(name,password,age,sex,birthday) values(#{name},#{password},#{age},#{sex},#{birthday})")
@Options(useGeneratedKeys = true, keyColumn = "id", keyProperty = "id")
void addUser(User user);
@Select("select * from t_user")
List findUser();
}
```
`controller`
```java
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/save")
public String insert() {
User user = new User();
// user.setId(IdUtils.nextId());
user.setName("张三"+new Random().nextInt());
user.setPassword("123456");
user.setSex(1);
user.setBirthday(new Date());
userMapper.addUser(user);
return "success";
}
@GetMapping("/list")
public List listUser(){
return userMapper.findUser();
}
}
```
`sql`
```mysql
CREATE TABLE `t_user` (
`id` bigint(50) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`password` varchar(50) DEFAULT NULL,
`age` int(5) DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
`birthday` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
```
## 5、MySQL分库分表原理
### `01、为什么要分库分表`
一般的机器(4核16G),单库的MySQL并发(QPS+TPS)超过了2K,系统基本就完蛋了。最好是并发量控制在1K左右。这里就引出一个问题,为什么要分库分表?
> 分库分表目的:解决高并发,和数据量大的问题。
1、高并发情况下,会造成IO读写频繁,自然就会造成读写缓慢,甚至是宕机。一般单库不要超过2k并发,NB的机器除外。
2、数据量大的问题。主要由于底层索引实现导致,MySQL的索引实现为B+TREE,数据量其他,会导致索引树十分庞大,造成查询缓慢。第二,innodb的最大存储限制64TB。
> 要解决上述问题。最常见做法,就是分库分表。
>
> 分库分表的目的,是将一个表拆成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。一个表数据建议不要超过500W。
 ### `02、分库分表`
> 又分为垂直拆分和水平拆分
**水平拆分:**同一个表的数据拆到不同的库不同的表中。可以根据时间、地区或某个业务键纬度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
**垂直拆分:**就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务纬度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表。也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。

### `03、不停机分库分表数据迁移`
一般数据库的拆分也是有一个过程的,一开始是单表,后面慢慢拆分成多表。那么我们就看下图和平滑的从MySQL单表过渡到MySQL的分库分表架构。
1、利用mysql+canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中。
2、利用分库分表中间件,全量数据导入到对应的新表中。
3、通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中。
4、数据稳定后,将单表的配置切换到分库分表配置上。

## 6、ShardingJdbc的分库和分表
### `01、分库分表的方式`
**水平拆分:**同一个表的数据拆到不同的库不同的表中。可以根据时间、地区或某个业务键纬度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
**垂直拆分:**就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务纬度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表。也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
### `02、逻辑表`
逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户id%2拆分为2个表,分别是:t_user0和t_user1。它们的逻辑表名是:t_user。
在shardingjdbc的定义方式如下:
```yml
spring:
shardingsphere:
sharding:
tables:
# t_user逻辑表名
t_user:
```
### `03、分库分表数据节点 - actual-data-nodes`
```yaml
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
# 数据节点:多数据源$ ->{0..N}.逻辑表名$->{0..N} 相同表
actual-data-nodes: ds$->{0..2}.t_user$->{0..1}
# 数据节点:多数据源$ ->{0..N}.逻辑表名$->{0..N} 不同表
actual-data-nodes: ds0.t_user$->{0..1},ds1.t_user$->{2..4}
#指定单数据源的配置方式
actual-data-nodes: ds0.t_user$->{0..4}
# 全部手动指定
actual-data-nodes: ds0.t_user0,ds1.t_user0,ds0.t_user1,ds1.t_user1
```
数据分片是最小单元。由数据源名称和数据表组成,比如:ds0.t_user0
> 寻找规则如下:
> **对于均匀分布的数据节点,如果数据结构如下:**
>
> ```
> db0
> ├── t_order0
> └── t_order1
> db1
> ├── t_order0
> └── t_order1
> ```
>
> 用行表达式可以简化为:
>
> ```yaml
> db${0..1}.t_order${0..1}
> 或者
> db$->{0..1}.t_order$->{0..1}
> ```
>
> **对于自定义的数据节点,如果数据结构如下:**
>
> ```
> db0
> ├── t_order0
> └── t_order1
> db1
> ├── t_order2
> ├── t_order3
> └── t_order4
> ```
>
> 用行表达式可以简化为:
>
> ```yaml
> db0.t_order${0..1},db1.t_order${2..4}
> 或者
> db0.t_order$->{0..1},db1.t_order$->{2..4}
> ```
### `04、分库分表5种分片策略`

数据源分片分为两种:
* 数据源分片
* 表分片
这两个是不同维度的分片规则,但是它们用的分片策略和规则是一样的。它们由两部分构成:
* 分片键
* 分片算法
> #### 第一种:none
对应NoneShardingStragey,不分片策略。SQL会被发给所有节点去执行,这个规则没有子项目可以配置。
> #### 第二种:inline 行表达式分片策略(核心,必须要掌握)
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: `t_user_$->{u_id % 8}` 表示t_user表根据u_id模8,而分成8张表,表名称为`t_user_0`到`t_user_7`。
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
# 数据节点:数据源$ ->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放到哪个数据库中
database-strategy:
inline:
sharding-column: age
algorithm-expression: ds$->{age % 2}
table-strategy:
inline:
sharding-column: age
algorithm-expression: t_user$->{age % 2}
```
**algorithm-expression行表达式:**
* ${begin,end}表示区间范围
* ${unit1,unit2,.....,unitn}表示枚举值
* 行表达式如果出现连续多个\${expression}或\$->{expression}表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合
```yaml
database-strategy:
standard: #单列sharding算法,需要配合对应的preciseAlgorithmClassName、rangeShardingAlgorithm接口的实现使用
shardingColumn: #列名
preciseAlgorithmClassName: #PreciseShardingAlgorithm接口实现类
rangeAlgorithmClassName: #RangeShardingAlgorithm接口实现类
```
#### 04-1、完整配置如下:
* 准备两个数据库sharding_study。名字相同,两个数据源ds0,ds1
* 每个数据库下方t_user0和t_user1即可。
* 数据库规则,性别为偶数的放入ds0库,奇数的放入ds1库
* 数据表规则,年龄为偶数的放入t_user0表,奇数的放入t_user1表。
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
# 数据节点:数据源$ ->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放到哪个数据库中
database-strategy:
inline:
sharding-column: age
algorithm-expression: ds$->{sex % 2}
table-strategy:
inline:
sharding-column: age
algorithm-expression: t_user$->{age % 2}
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
### `05、第三种:根据时间日期 - 按照标准规则分库分表`
> #### 05-1、标准分片 - Standard
* 对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
* StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
* PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
* RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
> #### 05-2、定义分片的日期规则配置
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
key-generator:
column: id
type: SNOWFLAKE
# 数据节点:数据源$ ->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放到哪个数据库中
database-strategy:
standard:
shardingColumn: birthday
preciseAlgorithmClassName: com.study.shardingjdbc.algorithm.BirthdayAlgorithm
table-strategy:
inline:
sharding-column: age
algorithm-expression: t_user$->{age % 2}
# t_user逻辑表名
t_user_order:
key-generator:
column: order_id
type: SNOWFLAKE
actual-data-nodes: ds0.t_user_order_$->{2021..2022}${(1..3).collect{t -> t.toString().padLeft(2,'0')}}
table-strategy:
# inline:
# shardingColumn: yearmonth
# algorithm-expression: t_user_order_$->{yearmonth}
standard:
shardingColumn: yearmonth
preciseAlgorithmClassName: com.study.shardingjdbc.algorithm.YeahMonthAlgorithm
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
> 05-3、定义分片的日期规则
```java
package com.study.shardingjdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.*;
/**
* @author ldtianzhe
* @date 2020/4/11
*/
public class BirthdayAlgorithm implements PreciseShardingAlgorithm {
List dateList = new ArrayList<>();
{
// Calendar calendar1 = Calendar.getInstance();
// calendar1.set(2020,1,1,0,0,0);
Calendar calendar2 = Calendar.getInstance();
calendar2.set(2021,1,1,0,0,0);
Calendar calendar3 = Calendar.getInstance();
calendar3.set(2022,1,1,0,0,0);
// dateList.add(calendar1.getTime());
dateList.add(calendar2.getTime());
dateList.add(calendar3.getTime());
}
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
Date date = preciseShardingValue.getValue();
Iterator iterator = collection.iterator();
String target = null;
for (Date s : dateList) {
target = iterator.next();
if (date.before(s)){
break;
}
}
return target; //最后返回的是ds0,ds1
}
}
```
### `06、第四种:ShardingSphere - 复合分片策略`
* 对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
* ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
```yaml
database-strategy:
complex: #支持多列的sharding
shardingColumn: #逗号切割的列
shardingAlgorithm: #ComplexShardingStrategyAlgorithm接口的实现类
```
### `07、第五种:ShardingSphere - hint分片策略`
* 对应HintShardingStrategy接口。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
* 对于分片字段非SQL决定,而是由其他外置条件决定的场景,可使用SQL hint灵活的注入分片字段。例如:按照用户登录的时间,主键等进行分库,而数据库中并无此字段。SQL hint支持通过Java API和SQL注解两种方式使用。让分库分表更加灵活。
```yaml
database-strategy:
hint: #基于标记的sharding分片
shardingAlgorithm: #需要是HintShardingStrategyAlgorithm接口的实现
```
## 7、ShardingSphere-分布式主键配置
ShardingSphere提供灵活的配置分布式主键生成策略方式。在分片规则配置模块可配置每个表的主键生成策略。默认使用雪花算法。(snowflake) 生成64bit的长整型数据。支持两种方式配置
* SNOWFLAKE
* UUID
这里切记:主键列不能自增长。数据类型是bigint(20)
```yaml
spring:
shardingsphere:
sharding:
# 配置分表的规则
tables:
# t_user逻辑表名
t_user_order:
key-generator:
column: order_id
type: SNOWFLAKE
```
## 8、ShardingSphere-分库分表-年月案例
> 实际案例按照年月分库分表
### `策略类`
```java
package com.study.shardingjdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
/**
* @author ldtianzhe
* @date 2020/4/11
*/
public class YeahMonthAlgorithm implements PreciseShardingAlgorithm {
private static final String SPLITTER = "_";
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
String tbName = preciseShardingValue.getLogicTableName() + "_" + preciseShardingValue.getValue();
System.out.println("sharding input"+preciseShardingValue.getValue()+",output:{}"+tbName);
return tbName;
}
}
```
### `entity`
```java
package com.study.shardingjdbc.entity;
import lombok.Data;
import java.util.Date;
/**
* @author ldtianzhe
* @date 2021/4/11
*/
@Data
public class UserOrder {
private Long orderId;
private String orderNumber;
private Long userId;
private Long productId;
private Date createTime;
private String yearmonth;
}
```
### `mapper`
```java
package com.study.shardingjdbc.mapper;
import com.study.shardingjdbc.entity.UserOrder;
import org.apache.ibatis.annotations.*;
import java.util.List;
/**
* @author ldtianzhe
* @date 2021/4/11
*/
@Mapper
public interface UserOrderMapper {
@Insert("insert into t_user_order(order_number,user_id,create_time,yearmonth) values(#{orderNumber},#{userId},#{createTime},#{yearmonth})")
@Options(useGeneratedKeys = true, keyProperty = "orderId", keyColumn = "order_id")
void addUserOrder(UserOrder userOrder);
@Select("select * from t_user_order limit #{limit} offset #{pageNo}")
List findList(@Param("pageNo") Integer pageNo, @Param("limit") Integer limit);
}
```
### `配置如下`
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user_order:
key-generator:
column: order_id
type: SNOWFLAKE
actual-data-nodes: ds0.t_user_order_$->{2021..2022}${(1..3).collect{t -> t.toString().padLeft(2,'0')}}
table-strategy:
# inline:
# shardingColumn: yearmonth
# algorithm-expression: t_user_order_$->{yearmonth}
standard:
shardingColumn: yearmonth
preciseAlgorithmClassName: com.study.shardingjdbc.algorithm.YeahMonthAlgorithm
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
> 具体策略类可以根据业务场景进行自定义修改
>
> 如下为真实项目订单分表策略
```java
@Slf4j
public class OrderShardingAlgorithm implements PreciseShardingAlgorithm, RangeShardingAlgorithm {
/**
* 缓存存在的表
*/
private List tables;
private final String tableHead = "t_order_";
private final String table = "t_order";
public void init(){
// tables = DBUtil.getAllOrderTable();
tables = DBUtil.getAllTableNames(table);
}
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
String target = shardingValue.getValue().toString();
Long timestamp = Long.valueOf(target.split("_")[2]);
String month = new SimpleDateFormat("yyyyMM").format(timestamp);
/*if (!tables.contains(tableHead + month)) {
DBUtil.createTable(table,month);
tables.add(tableHead + month);
//添加到rule
DataSource dataSource = SpringContextUtils.getBean("dataSource",DataSource.class);
ShardingDataSource shardingDataSource = (ShardingDataSource)dataSource;
ShardingRule shardingRule = shardingDataSource.getShardingContext().getShardingRule();
Optional orderTable = shardingRule.findTableRule(table);
TableRule tableRule = orderTable.orNull();
if(tableRule != null){
List dataNodes = tableRule.getActualDataNodes();
try {
String dataSourceName = dataNodes.get(0).getDataSourceName();
StringBuilder stringBuilder = new StringBuilder()
.append(dataSourceName).append(".");
stringBuilder.append(tableHead + month);
DataNode dataNode = new DataNode(stringBuilder.toString());
dataNodes.add(dataNode);
Field actualDataNodesField = TableRule.class.getDeclaredField("actualDataNodes");
actualDataNodesField.setAccessible(true);
actualDataNodesField.set(tableRule, dataNodes);
} catch (Exception e) {
log.error("t_order添加sharding actualDataNodes失败",e);
// e.printStackTrace();
}
}
}*/
return shardingValue.getLogicTableName() + "_" + month;
}
@Override
public Collection doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
Collection availables = new ArrayList<>();
Range valueRange = shardingValue.getValueRange();
// for (String target : tables) {
for (String target : availableTargetNames) {
String month = target.substring(target.lastIndexOf(tableHead) + 1,target.lastIndexOf(tableHead) + 7);
// if(DateUtils.isDate(month,"yyyyMM")){
Integer shardValue = Integer.parseInt(month);
if (valueRange.hasLowerBound()) {
String lowerStr = valueRange.lowerEndpoint().toString();
Integer start = Integer.parseInt(lowerStr.substring(0, 6));
if (start - shardValue > 0) {
continue;
}
}
if (valueRange.hasUpperBound()) {
String upperStr = valueRange.upperEndpoint().toString();
Integer end = Integer.parseInt(upperStr.substring(0, 6));
if (end - shardValue < 0) {
continue;
}
}
availables.add(target);
// }
}
return availables;
}
}
```
## 9、ShardingJdbc的事物管理
### 9.1 分布式事物的应用和实践
官方地址:[https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction/](https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction/)
> 数据库事务需要满足ACID(原子性、一致性、隔离性、持久性)四个特性
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
关系型数据库虽然对本地事务提供了完美的`ACID`原生支持。 但在分布式的场景下,它却成为系统性能的桎梏。如何让数据库在分布式场景下满足`ACID`的特性或找寻相应的替代方案,是分布式事务的重点工作。
> 本地事务
在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务。 它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
> 两阶段提交
XA协议最早的分布式事务模型是由`X/Open`国际联盟提出的`X/Open Distributed Transaction Processing(DTP)`模型,简称XA协议。
基于XA协议实现的分布式事务对业务侵入很小。 它最大的优势就是对使用方透明,用户可以像使用本地事务一样使用基于XA协议的分布式事务。 XA协议能够严格保障事务`ACID`特性。
严格保障事务`ACID`特性是一把双刃剑。 事务执行在过程中需要将所需资源全部锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将导致对热点数据依赖的业务系统并发性能衰退明显。 因此,在高并发的性能至上场景中,基于XA协议的分布式事务并不是最佳选择。
> 柔性事务
如果将实现了`ACID`的事务要素的事务称为刚性事务的话,那么基于`BASE`事务要素的事务则称为柔性事务。 `BASE`是基本可用、柔性状态和最终一致性这三个要素的缩写。
* 基本可用(Basically Available)保证分布式事务参与方不一定同时在线。
* 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉。
* 而最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在`ACID`事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于`ACID`的强一致性事务和基于`BASE`的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型。
| | 本地事务 | 两(三)阶段事务 | 柔性事务 |
| :------- | :--------------- | :--------------- | :-------------- |
| 业务改造 | 无 | 无 | 实现相关接口 |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
#### 9.1.1 导入分布式事务的依赖
```xml
io.shardingsphere
sharding-transaction-spring-boot-starter
3.1.0
```
#### 9.1.2 事务的几种类型
> 本地事务
- 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
- 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
- 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交。
> 两阶段事务-XA
- 支持数据分片后的跨库XA事务
- 两阶段提交保证操作的原子性和数据的强一致性
- 服务宕机重启后,提交/回滚中的事务可自动恢复
- SPI机制整合主流的XA事务管理器,默认Atomikos,可以选择使用Narayana和Bitronix
- 同时支持XA和非XA的连接池
- 提供spring-boot和namespace的接入端
不支持:
- 服务宕机后,在其它机器上恢复提交/回滚中的数据
> 柔性事务-SAGA
- 完全支持跨库事务
- 支持失败SQL重试及最大努力送达
- 支持反向SQL、自动生成更新快照以及自动补偿
- 默认使用关系型数据库进行快照及事务日志的持久化,支持使用SPI的方式加载其他类型的持久化
不支持:
- 暂不支持资源隔离
- 暂不支持服务宕机后,自动恢复提交中的commit和rollback
> 柔性事务-SEATA
- 完全支持跨库分布式事务
- 支持RC隔离级别
- 通过undo快照进行事务回滚
- 支持服务宕机后的,自动恢复提交中的事务
依赖:
- 需要额外部署Seata-server服务进行分支事务的协调
- ShardingSphere和Seata会对SQL进行重复解析
## 10、ShardingJdbc的总结
> #### 基础规范
* 表必须有主键,建议使用整型作为主键
* 禁止使用外键,表之间的关联性和完整性通过应用层来控制
* 表在设计之初,应该考虑到大致的数据级,若表记录小于1000W,尽量使用单表,不建议分表
* 建议将大字段,访问频率低,或者不需要作为筛选条件的字段拆分到扩展表中(做好垂直拆分)
* 控制单实例表的总数,单个表分表数控制在1024以内
> #### 列设计规范
* 正确区分tinyint、int、bigint的范围
* 涉及金额使用decimal,并制定精度
* 不要设计为Null的字段,而是用空字符,因为Null需要更多的空间,并且使得索引和统计变得更复杂
> #### 索引规范
* 唯一索引使用uniq_[字段名]来命名
* 非唯一索引使用ind_[字段名]来命名
* 不建议在频繁更新的字段上建立索引
* 非必要不要进行join,如果要进行join查询,被join的字段必须类型相同,并建立索引
* 单张表的索引数量建议控制在5个以内,索引过多,不仅会导致插入更新性能下降,还可能导致MySQL的索引出错和性能下降
* 组合索引字段数量不建议超过5个,理解组合索引的最左匹配原则,避免重复建设索引。比如你建立了(x,y,z)相当于你建立(x),(x,y),(x,y,z)
> #### SQL规范
* 禁止使用select * ,只获取必要字段,select * 会增加cpu/io/内存、带宽的消耗
* insert必须指定字段,禁止使用Insert into Table values().指定字段插入,在表结果变更时,能保证对应应用程序无影响
* 隐私类型转换会使索引失效,导致全表扫描。(比如:手机号码搜索时未转换成字符串)
* 禁止在where后面查询条件列使用函数或者表达式,导致不能命中索引,导致全表扫描
* 禁止负向查询(!= , not like , no in 等)以及 % 开头的模糊查询,导致不能命中索引,导致全表扫描
* 避免直接返回大结果集造成内存溢出,可采用分段和游标方式
* 返回结果集时尽量使用limit分页显示
* 尽量在order by/group by的列上创建索引
* 大表扫描操作尽量放到镜像库上做
* 禁止大表join查询和子查询
* 尽量避免数据库内置函数作为查询条件
* 应用程序尽量捕获SQL异常
> #### 表的垂直拆分
垂直拆分:业务模块拆分、商品库,用户库,订单库
水平拆分:对表进行水平拆分(也就是我们说的分表)
表进行垂直拆分:表的字段过多,字段使用的频率不一。(可以拆分两个表建立1:1关系)
将一个属性较多的表、一行数据较大的表,将不同的属性拆分到不同的表中,以降低单库中的表的大小
特点
* 每个表的结构不一致
* 每个表的数据都是全量
* 表之间至少有一列的关联数据,一般是主键
* 所有表的并集是全量数据
原则:
* 将长度较短,访问频率较高的放入一张表,如主表
* 将长度较长、访问频率较低的字段放入拓展表
* 将经常一起访问的字段放入一张表
> #### 如何平滑添加字段
场景:在开发时,有时需要给表加个字段,在大数据量且分表的情况下,怎样平滑添加
1、直接alter table add column,数据量大时不建议 (写锁、耗时间)
2、提前预留字段 (不优雅、造成空间浪费、预留多少很难控制,拓展性差)
3、新增一张表,在新表增加字段,迁移原表数据,再重命名新表为原表 (数据量很大时,迁移数据很麻烦)
4、放入extInfo,也就是加扩展表(无法使用索引)
5、提前设计,使用key-value方式存储,新增字段时,直接加一个key就好了(优雅)
## 11、SpringBoot整合SharingJdbc3.0和案例分析
SharingJdbc3.x和4.x版本配置之间的区别在于
SharingJdbc3.x
```yaml
spring:
sharding:
jdbc:
datasource:
```
SharingJdbc4.x
```yaml
spring:
shardingsphere:
datasource:
```
具体详细如下:
> 数据分片
```properties
sharding.jdbc.datasource.names=ds0,ds1
sharding.jdbc.datasource.ds0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=
sharding.jdbc.datasource.ds1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
```
> 读写分离
```properties
sharding.jdbc.datasource.names=master,slave0,slave1
sharding.jdbc.datasource.master.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master.url=jdbc:mysql://localhost:3306/master
sharding.jdbc.datasource.master.username=root
sharding.jdbc.datasource.master.password=
sharding.jdbc.datasource.slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.slave0.url=jdbc:mysql://localhost:3306/slave0
sharding.jdbc.datasource.slave0.username=root
sharding.jdbc.datasource.slave0.password=
sharding.jdbc.datasource.slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.slave1.url=jdbc:mysql://localhost:3306/slave1
sharding.jdbc.datasource.slave1.username=root
sharding.jdbc.datasource.slave1.password=
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
sharding.jdbc.config.masterslave.name=ms
sharding.jdbc.config.masterslave.master-data-source-name=master
sharding.jdbc.config.masterslave.slave-data-source-names=slave0,slave1
sharding.jdbc.config.props.sql.show=true
```
> 数据分片+读写分离
```properties
sharding.jdbc.datasource.names=master0,master1,master0slave0,master0slave1,master1slave0,master1slave1
sharding.jdbc.datasource.master0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0.url=jdbc:mysql://localhost:3306/master0
sharding.jdbc.datasource.master0.username=root
sharding.jdbc.datasource.master0.password=
sharding.jdbc.datasource.master0slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave0.url=jdbc:mysql://localhost:3306/master0slave0
sharding.jdbc.datasource.master0slave0.username=root
sharding.jdbc.datasource.master0slave0.password=
sharding.jdbc.datasource.master0slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave1.url=jdbc:mysql://localhost:3306/master0slave1
sharding.jdbc.datasource.master0slave1.username=root
sharding.jdbc.datasource.master0slave1.password=
sharding.jdbc.datasource.master1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1.url=jdbc:mysql://localhost:3306/master1
sharding.jdbc.datasource.master1.username=root
sharding.jdbc.datasource.master1.password=
sharding.jdbc.datasource.master1slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave0.url=jdbc:mysql://localhost:3306/master1slave0
sharding.jdbc.datasource.master1slave0.username=root
sharding.jdbc.datasource.master1slave0.password=
sharding.jdbc.datasource.master1slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave1.url=jdbc:mysql://localhost:3306/master1slave1
sharding.jdbc.datasource.master1slave1.username=root
sharding.jdbc.datasource.master1slave1.password=
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=master$->{user_id % 2}
sharding.jdbc.config.sharding.master-slave-rules.ds0.master-data-source-name=master0
sharding.jdbc.config.sharding.master-slave-rules.ds0.slave-data-source-names=master0slave0, master0slave1
sharding.jdbc.config.sharding.master-slave-rules.ds1.master-data-source-name=master1
sharding.jdbc.config.sharding.master-slave-rules.ds1.slave-data-source-names=master1slave0, master1slave1
```
### `02、分库分表`
> 又分为垂直拆分和水平拆分
**水平拆分:**同一个表的数据拆到不同的库不同的表中。可以根据时间、地区或某个业务键纬度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
**垂直拆分:**就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务纬度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表。也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。

### `03、不停机分库分表数据迁移`
一般数据库的拆分也是有一个过程的,一开始是单表,后面慢慢拆分成多表。那么我们就看下图和平滑的从MySQL单表过渡到MySQL的分库分表架构。
1、利用mysql+canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中。
2、利用分库分表中间件,全量数据导入到对应的新表中。
3、通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中。
4、数据稳定后,将单表的配置切换到分库分表配置上。

## 6、ShardingJdbc的分库和分表
### `01、分库分表的方式`
**水平拆分:**同一个表的数据拆到不同的库不同的表中。可以根据时间、地区或某个业务键纬度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
**垂直拆分:**就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务纬度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表。也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
### `02、逻辑表`
逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户id%2拆分为2个表,分别是:t_user0和t_user1。它们的逻辑表名是:t_user。
在shardingjdbc的定义方式如下:
```yml
spring:
shardingsphere:
sharding:
tables:
# t_user逻辑表名
t_user:
```
### `03、分库分表数据节点 - actual-data-nodes`
```yaml
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
# 数据节点:多数据源$ ->{0..N}.逻辑表名$->{0..N} 相同表
actual-data-nodes: ds$->{0..2}.t_user$->{0..1}
# 数据节点:多数据源$ ->{0..N}.逻辑表名$->{0..N} 不同表
actual-data-nodes: ds0.t_user$->{0..1},ds1.t_user$->{2..4}
#指定单数据源的配置方式
actual-data-nodes: ds0.t_user$->{0..4}
# 全部手动指定
actual-data-nodes: ds0.t_user0,ds1.t_user0,ds0.t_user1,ds1.t_user1
```
数据分片是最小单元。由数据源名称和数据表组成,比如:ds0.t_user0
> 寻找规则如下:
> **对于均匀分布的数据节点,如果数据结构如下:**
>
> ```
> db0
> ├── t_order0
> └── t_order1
> db1
> ├── t_order0
> └── t_order1
> ```
>
> 用行表达式可以简化为:
>
> ```yaml
> db${0..1}.t_order${0..1}
> 或者
> db$->{0..1}.t_order$->{0..1}
> ```
>
> **对于自定义的数据节点,如果数据结构如下:**
>
> ```
> db0
> ├── t_order0
> └── t_order1
> db1
> ├── t_order2
> ├── t_order3
> └── t_order4
> ```
>
> 用行表达式可以简化为:
>
> ```yaml
> db0.t_order${0..1},db1.t_order${2..4}
> 或者
> db0.t_order$->{0..1},db1.t_order$->{2..4}
> ```
### `04、分库分表5种分片策略`

数据源分片分为两种:
* 数据源分片
* 表分片
这两个是不同维度的分片规则,但是它们用的分片策略和规则是一样的。它们由两部分构成:
* 分片键
* 分片算法
> #### 第一种:none
对应NoneShardingStragey,不分片策略。SQL会被发给所有节点去执行,这个规则没有子项目可以配置。
> #### 第二种:inline 行表达式分片策略(核心,必须要掌握)
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: `t_user_$->{u_id % 8}` 表示t_user表根据u_id模8,而分成8张表,表名称为`t_user_0`到`t_user_7`。
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
# 数据节点:数据源$ ->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放到哪个数据库中
database-strategy:
inline:
sharding-column: age
algorithm-expression: ds$->{age % 2}
table-strategy:
inline:
sharding-column: age
algorithm-expression: t_user$->{age % 2}
```
**algorithm-expression行表达式:**
* ${begin,end}表示区间范围
* ${unit1,unit2,.....,unitn}表示枚举值
* 行表达式如果出现连续多个\${expression}或\$->{expression}表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合
```yaml
database-strategy:
standard: #单列sharding算法,需要配合对应的preciseAlgorithmClassName、rangeShardingAlgorithm接口的实现使用
shardingColumn: #列名
preciseAlgorithmClassName: #PreciseShardingAlgorithm接口实现类
rangeAlgorithmClassName: #RangeShardingAlgorithm接口实现类
```
#### 04-1、完整配置如下:
* 准备两个数据库sharding_study。名字相同,两个数据源ds0,ds1
* 每个数据库下方t_user0和t_user1即可。
* 数据库规则,性别为偶数的放入ds0库,奇数的放入ds1库
* 数据表规则,年龄为偶数的放入t_user0表,奇数的放入t_user1表。
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
# 数据节点:数据源$ ->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放到哪个数据库中
database-strategy:
inline:
sharding-column: age
algorithm-expression: ds$->{sex % 2}
table-strategy:
inline:
sharding-column: age
algorithm-expression: t_user$->{age % 2}
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
### `05、第三种:根据时间日期 - 按照标准规则分库分表`
> #### 05-1、标准分片 - Standard
* 对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
* StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
* PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
* RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
> #### 05-2、定义分片的日期规则配置
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user:
key-generator:
column: id
type: SNOWFLAKE
# 数据节点:数据源$ ->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放到哪个数据库中
database-strategy:
standard:
shardingColumn: birthday
preciseAlgorithmClassName: com.study.shardingjdbc.algorithm.BirthdayAlgorithm
table-strategy:
inline:
sharding-column: age
algorithm-expression: t_user$->{age % 2}
# t_user逻辑表名
t_user_order:
key-generator:
column: order_id
type: SNOWFLAKE
actual-data-nodes: ds0.t_user_order_$->{2021..2022}${(1..3).collect{t -> t.toString().padLeft(2,'0')}}
table-strategy:
# inline:
# shardingColumn: yearmonth
# algorithm-expression: t_user_order_$->{yearmonth}
standard:
shardingColumn: yearmonth
preciseAlgorithmClassName: com.study.shardingjdbc.algorithm.YeahMonthAlgorithm
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
> 05-3、定义分片的日期规则
```java
package com.study.shardingjdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.*;
/**
* @author ldtianzhe
* @date 2020/4/11
*/
public class BirthdayAlgorithm implements PreciseShardingAlgorithm {
List dateList = new ArrayList<>();
{
// Calendar calendar1 = Calendar.getInstance();
// calendar1.set(2020,1,1,0,0,0);
Calendar calendar2 = Calendar.getInstance();
calendar2.set(2021,1,1,0,0,0);
Calendar calendar3 = Calendar.getInstance();
calendar3.set(2022,1,1,0,0,0);
// dateList.add(calendar1.getTime());
dateList.add(calendar2.getTime());
dateList.add(calendar3.getTime());
}
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
Date date = preciseShardingValue.getValue();
Iterator iterator = collection.iterator();
String target = null;
for (Date s : dateList) {
target = iterator.next();
if (date.before(s)){
break;
}
}
return target; //最后返回的是ds0,ds1
}
}
```
### `06、第四种:ShardingSphere - 复合分片策略`
* 对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
* ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
```yaml
database-strategy:
complex: #支持多列的sharding
shardingColumn: #逗号切割的列
shardingAlgorithm: #ComplexShardingStrategyAlgorithm接口的实现类
```
### `07、第五种:ShardingSphere - hint分片策略`
* 对应HintShardingStrategy接口。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
* 对于分片字段非SQL决定,而是由其他外置条件决定的场景,可使用SQL hint灵活的注入分片字段。例如:按照用户登录的时间,主键等进行分库,而数据库中并无此字段。SQL hint支持通过Java API和SQL注解两种方式使用。让分库分表更加灵活。
```yaml
database-strategy:
hint: #基于标记的sharding分片
shardingAlgorithm: #需要是HintShardingStrategyAlgorithm接口的实现
```
## 7、ShardingSphere-分布式主键配置
ShardingSphere提供灵活的配置分布式主键生成策略方式。在分片规则配置模块可配置每个表的主键生成策略。默认使用雪花算法。(snowflake) 生成64bit的长整型数据。支持两种方式配置
* SNOWFLAKE
* UUID
这里切记:主键列不能自增长。数据类型是bigint(20)
```yaml
spring:
shardingsphere:
sharding:
# 配置分表的规则
tables:
# t_user逻辑表名
t_user_order:
key-generator:
column: order_id
type: SNOWFLAKE
```
## 8、ShardingSphere-分库分表-年月案例
> 实际案例按照年月分库分表
### `策略类`
```java
package com.study.shardingjdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
/**
* @author ldtianzhe
* @date 2020/4/11
*/
public class YeahMonthAlgorithm implements PreciseShardingAlgorithm {
private static final String SPLITTER = "_";
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
String tbName = preciseShardingValue.getLogicTableName() + "_" + preciseShardingValue.getValue();
System.out.println("sharding input"+preciseShardingValue.getValue()+",output:{}"+tbName);
return tbName;
}
}
```
### `entity`
```java
package com.study.shardingjdbc.entity;
import lombok.Data;
import java.util.Date;
/**
* @author ldtianzhe
* @date 2021/4/11
*/
@Data
public class UserOrder {
private Long orderId;
private String orderNumber;
private Long userId;
private Long productId;
private Date createTime;
private String yearmonth;
}
```
### `mapper`
```java
package com.study.shardingjdbc.mapper;
import com.study.shardingjdbc.entity.UserOrder;
import org.apache.ibatis.annotations.*;
import java.util.List;
/**
* @author ldtianzhe
* @date 2021/4/11
*/
@Mapper
public interface UserOrderMapper {
@Insert("insert into t_user_order(order_number,user_id,create_time,yearmonth) values(#{orderNumber},#{userId},#{createTime},#{yearmonth})")
@Options(useGeneratedKeys = true, keyProperty = "orderId", keyColumn = "order_id")
void addUserOrder(UserOrder userOrder);
@Select("select * from t_user_order limit #{limit} offset #{pageNo}")
List findList(@Param("pageNo") Integer pageNo, @Param("limit") Integer limit);
}
```
### `配置如下`
```yaml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
#配置数据源
datasource:
#给每个数据源取别名,下面的ds1,ds2,ds3任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.54.34:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
# 配置ds2-slave
ds1:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://172.19.56.70:3306/sharding_study?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: ldtianzhe
maxPoolSize: 100
minPoolSize: 5
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错
default-data-source-name: ds0
# 配置分表的规则
tables:
# t_user逻辑表名
t_user_order:
key-generator:
column: order_id
type: SNOWFLAKE
actual-data-nodes: ds0.t_user_order_$->{2021..2022}${(1..3).collect{t -> t.toString().padLeft(2,'0')}}
table-strategy:
# inline:
# shardingColumn: yearmonth
# algorithm-expression: t_user_order_$->{yearmonth}
standard:
shardingColumn: yearmonth
preciseAlgorithmClassName: com.study.shardingjdbc.algorithm.YeahMonthAlgorithm
# 配置mybatis
mybatis:
# 搜索指定包别名
typeAliasesPackage: com.study.shardingjdbc
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapperLocations: classpath*:mapper/**/*Mapper.xml
configuration:
map-underscore-to-camel-case: true
```
> 具体策略类可以根据业务场景进行自定义修改
>
> 如下为真实项目订单分表策略
```java
@Slf4j
public class OrderShardingAlgorithm implements PreciseShardingAlgorithm, RangeShardingAlgorithm {
/**
* 缓存存在的表
*/
private List tables;
private final String tableHead = "t_order_";
private final String table = "t_order";
public void init(){
// tables = DBUtil.getAllOrderTable();
tables = DBUtil.getAllTableNames(table);
}
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
String target = shardingValue.getValue().toString();
Long timestamp = Long.valueOf(target.split("_")[2]);
String month = new SimpleDateFormat("yyyyMM").format(timestamp);
/*if (!tables.contains(tableHead + month)) {
DBUtil.createTable(table,month);
tables.add(tableHead + month);
//添加到rule
DataSource dataSource = SpringContextUtils.getBean("dataSource",DataSource.class);
ShardingDataSource shardingDataSource = (ShardingDataSource)dataSource;
ShardingRule shardingRule = shardingDataSource.getShardingContext().getShardingRule();
Optional orderTable = shardingRule.findTableRule(table);
TableRule tableRule = orderTable.orNull();
if(tableRule != null){
List dataNodes = tableRule.getActualDataNodes();
try {
String dataSourceName = dataNodes.get(0).getDataSourceName();
StringBuilder stringBuilder = new StringBuilder()
.append(dataSourceName).append(".");
stringBuilder.append(tableHead + month);
DataNode dataNode = new DataNode(stringBuilder.toString());
dataNodes.add(dataNode);
Field actualDataNodesField = TableRule.class.getDeclaredField("actualDataNodes");
actualDataNodesField.setAccessible(true);
actualDataNodesField.set(tableRule, dataNodes);
} catch (Exception e) {
log.error("t_order添加sharding actualDataNodes失败",e);
// e.printStackTrace();
}
}
}*/
return shardingValue.getLogicTableName() + "_" + month;
}
@Override
public Collection doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
Collection availables = new ArrayList<>();
Range valueRange = shardingValue.getValueRange();
// for (String target : tables) {
for (String target : availableTargetNames) {
String month = target.substring(target.lastIndexOf(tableHead) + 1,target.lastIndexOf(tableHead) + 7);
// if(DateUtils.isDate(month,"yyyyMM")){
Integer shardValue = Integer.parseInt(month);
if (valueRange.hasLowerBound()) {
String lowerStr = valueRange.lowerEndpoint().toString();
Integer start = Integer.parseInt(lowerStr.substring(0, 6));
if (start - shardValue > 0) {
continue;
}
}
if (valueRange.hasUpperBound()) {
String upperStr = valueRange.upperEndpoint().toString();
Integer end = Integer.parseInt(upperStr.substring(0, 6));
if (end - shardValue < 0) {
continue;
}
}
availables.add(target);
// }
}
return availables;
}
}
```
## 9、ShardingJdbc的事物管理
### 9.1 分布式事物的应用和实践
官方地址:[https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction/](https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction/)
> 数据库事务需要满足ACID(原子性、一致性、隔离性、持久性)四个特性
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
关系型数据库虽然对本地事务提供了完美的`ACID`原生支持。 但在分布式的场景下,它却成为系统性能的桎梏。如何让数据库在分布式场景下满足`ACID`的特性或找寻相应的替代方案,是分布式事务的重点工作。
> 本地事务
在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务。 它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
> 两阶段提交
XA协议最早的分布式事务模型是由`X/Open`国际联盟提出的`X/Open Distributed Transaction Processing(DTP)`模型,简称XA协议。
基于XA协议实现的分布式事务对业务侵入很小。 它最大的优势就是对使用方透明,用户可以像使用本地事务一样使用基于XA协议的分布式事务。 XA协议能够严格保障事务`ACID`特性。
严格保障事务`ACID`特性是一把双刃剑。 事务执行在过程中需要将所需资源全部锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将导致对热点数据依赖的业务系统并发性能衰退明显。 因此,在高并发的性能至上场景中,基于XA协议的分布式事务并不是最佳选择。
> 柔性事务
如果将实现了`ACID`的事务要素的事务称为刚性事务的话,那么基于`BASE`事务要素的事务则称为柔性事务。 `BASE`是基本可用、柔性状态和最终一致性这三个要素的缩写。
* 基本可用(Basically Available)保证分布式事务参与方不一定同时在线。
* 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉。
* 而最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在`ACID`事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于`ACID`的强一致性事务和基于`BASE`的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型。
| | 本地事务 | 两(三)阶段事务 | 柔性事务 |
| :------- | :--------------- | :--------------- | :-------------- |
| 业务改造 | 无 | 无 | 实现相关接口 |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
#### 9.1.1 导入分布式事务的依赖
```xml
io.shardingsphere
sharding-transaction-spring-boot-starter
3.1.0
```
#### 9.1.2 事务的几种类型
> 本地事务
- 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
- 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
- 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交。
> 两阶段事务-XA
- 支持数据分片后的跨库XA事务
- 两阶段提交保证操作的原子性和数据的强一致性
- 服务宕机重启后,提交/回滚中的事务可自动恢复
- SPI机制整合主流的XA事务管理器,默认Atomikos,可以选择使用Narayana和Bitronix
- 同时支持XA和非XA的连接池
- 提供spring-boot和namespace的接入端
不支持:
- 服务宕机后,在其它机器上恢复提交/回滚中的数据
> 柔性事务-SAGA
- 完全支持跨库事务
- 支持失败SQL重试及最大努力送达
- 支持反向SQL、自动生成更新快照以及自动补偿
- 默认使用关系型数据库进行快照及事务日志的持久化,支持使用SPI的方式加载其他类型的持久化
不支持:
- 暂不支持资源隔离
- 暂不支持服务宕机后,自动恢复提交中的commit和rollback
> 柔性事务-SEATA
- 完全支持跨库分布式事务
- 支持RC隔离级别
- 通过undo快照进行事务回滚
- 支持服务宕机后的,自动恢复提交中的事务
依赖:
- 需要额外部署Seata-server服务进行分支事务的协调
- ShardingSphere和Seata会对SQL进行重复解析
## 10、ShardingJdbc的总结
> #### 基础规范
* 表必须有主键,建议使用整型作为主键
* 禁止使用外键,表之间的关联性和完整性通过应用层来控制
* 表在设计之初,应该考虑到大致的数据级,若表记录小于1000W,尽量使用单表,不建议分表
* 建议将大字段,访问频率低,或者不需要作为筛选条件的字段拆分到扩展表中(做好垂直拆分)
* 控制单实例表的总数,单个表分表数控制在1024以内
> #### 列设计规范
* 正确区分tinyint、int、bigint的范围
* 涉及金额使用decimal,并制定精度
* 不要设计为Null的字段,而是用空字符,因为Null需要更多的空间,并且使得索引和统计变得更复杂
> #### 索引规范
* 唯一索引使用uniq_[字段名]来命名
* 非唯一索引使用ind_[字段名]来命名
* 不建议在频繁更新的字段上建立索引
* 非必要不要进行join,如果要进行join查询,被join的字段必须类型相同,并建立索引
* 单张表的索引数量建议控制在5个以内,索引过多,不仅会导致插入更新性能下降,还可能导致MySQL的索引出错和性能下降
* 组合索引字段数量不建议超过5个,理解组合索引的最左匹配原则,避免重复建设索引。比如你建立了(x,y,z)相当于你建立(x),(x,y),(x,y,z)
> #### SQL规范
* 禁止使用select * ,只获取必要字段,select * 会增加cpu/io/内存、带宽的消耗
* insert必须指定字段,禁止使用Insert into Table values().指定字段插入,在表结果变更时,能保证对应应用程序无影响
* 隐私类型转换会使索引失效,导致全表扫描。(比如:手机号码搜索时未转换成字符串)
* 禁止在where后面查询条件列使用函数或者表达式,导致不能命中索引,导致全表扫描
* 禁止负向查询(!= , not like , no in 等)以及 % 开头的模糊查询,导致不能命中索引,导致全表扫描
* 避免直接返回大结果集造成内存溢出,可采用分段和游标方式
* 返回结果集时尽量使用limit分页显示
* 尽量在order by/group by的列上创建索引
* 大表扫描操作尽量放到镜像库上做
* 禁止大表join查询和子查询
* 尽量避免数据库内置函数作为查询条件
* 应用程序尽量捕获SQL异常
> #### 表的垂直拆分
垂直拆分:业务模块拆分、商品库,用户库,订单库
水平拆分:对表进行水平拆分(也就是我们说的分表)
表进行垂直拆分:表的字段过多,字段使用的频率不一。(可以拆分两个表建立1:1关系)
将一个属性较多的表、一行数据较大的表,将不同的属性拆分到不同的表中,以降低单库中的表的大小
特点
* 每个表的结构不一致
* 每个表的数据都是全量
* 表之间至少有一列的关联数据,一般是主键
* 所有表的并集是全量数据
原则:
* 将长度较短,访问频率较高的放入一张表,如主表
* 将长度较长、访问频率较低的字段放入拓展表
* 将经常一起访问的字段放入一张表
> #### 如何平滑添加字段
场景:在开发时,有时需要给表加个字段,在大数据量且分表的情况下,怎样平滑添加
1、直接alter table add column,数据量大时不建议 (写锁、耗时间)
2、提前预留字段 (不优雅、造成空间浪费、预留多少很难控制,拓展性差)
3、新增一张表,在新表增加字段,迁移原表数据,再重命名新表为原表 (数据量很大时,迁移数据很麻烦)
4、放入extInfo,也就是加扩展表(无法使用索引)
5、提前设计,使用key-value方式存储,新增字段时,直接加一个key就好了(优雅)
## 11、SpringBoot整合SharingJdbc3.0和案例分析
SharingJdbc3.x和4.x版本配置之间的区别在于
SharingJdbc3.x
```yaml
spring:
sharding:
jdbc:
datasource:
```
SharingJdbc4.x
```yaml
spring:
shardingsphere:
datasource:
```
具体详细如下:
> 数据分片
```properties
sharding.jdbc.datasource.names=ds0,ds1
sharding.jdbc.datasource.ds0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=
sharding.jdbc.datasource.ds1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
```
> 读写分离
```properties
sharding.jdbc.datasource.names=master,slave0,slave1
sharding.jdbc.datasource.master.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master.url=jdbc:mysql://localhost:3306/master
sharding.jdbc.datasource.master.username=root
sharding.jdbc.datasource.master.password=
sharding.jdbc.datasource.slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.slave0.url=jdbc:mysql://localhost:3306/slave0
sharding.jdbc.datasource.slave0.username=root
sharding.jdbc.datasource.slave0.password=
sharding.jdbc.datasource.slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.slave1.url=jdbc:mysql://localhost:3306/slave1
sharding.jdbc.datasource.slave1.username=root
sharding.jdbc.datasource.slave1.password=
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
sharding.jdbc.config.masterslave.name=ms
sharding.jdbc.config.masterslave.master-data-source-name=master
sharding.jdbc.config.masterslave.slave-data-source-names=slave0,slave1
sharding.jdbc.config.props.sql.show=true
```
> 数据分片+读写分离
```properties
sharding.jdbc.datasource.names=master0,master1,master0slave0,master0slave1,master1slave0,master1slave1
sharding.jdbc.datasource.master0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0.url=jdbc:mysql://localhost:3306/master0
sharding.jdbc.datasource.master0.username=root
sharding.jdbc.datasource.master0.password=
sharding.jdbc.datasource.master0slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave0.url=jdbc:mysql://localhost:3306/master0slave0
sharding.jdbc.datasource.master0slave0.username=root
sharding.jdbc.datasource.master0slave0.password=
sharding.jdbc.datasource.master0slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master0slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave1.url=jdbc:mysql://localhost:3306/master0slave1
sharding.jdbc.datasource.master0slave1.username=root
sharding.jdbc.datasource.master0slave1.password=
sharding.jdbc.datasource.master1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1.url=jdbc:mysql://localhost:3306/master1
sharding.jdbc.datasource.master1.username=root
sharding.jdbc.datasource.master1.password=
sharding.jdbc.datasource.master1slave0.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave0.url=jdbc:mysql://localhost:3306/master1slave0
sharding.jdbc.datasource.master1slave0.username=root
sharding.jdbc.datasource.master1slave0.password=
sharding.jdbc.datasource.master1slave1.type=org.apache.commons.dbcp.BasicDataSource
sharding.jdbc.datasource.master1slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave1.url=jdbc:mysql://localhost:3306/master1slave1
sharding.jdbc.datasource.master1slave1.username=root
sharding.jdbc.datasource.master1slave1.password=
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
sharding.jdbc.config.sharding.broadcast-tables=t_config
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=master$->{user_id % 2}
sharding.jdbc.config.sharding.master-slave-rules.ds0.master-data-source-name=master0
sharding.jdbc.config.sharding.master-slave-rules.ds0.slave-data-source-names=master0slave0, master0slave1
sharding.jdbc.config.sharding.master-slave-rules.ds1.master-data-source-name=master1
sharding.jdbc.config.sharding.master-slave-rules.ds1.slave-data-source-names=master1slave0, master1slave1
```