# Unsupervised-Indoor-Depth
**Repository Path**: loch_zhang/Unsupervised-Indoor-Depth
## Basic Information
- **Project Name**: Unsupervised-Indoor-Depth
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2020-10-14
- **Last Updated**: 2020-12-19
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# Unsupervised-Indoor-Depth
This page provides codes, models, and datasets in the paper:
>Unsupervised Depth Learning in Challenging Indoor Video: Weak Rectification to Rescue
>
>[Jia-Wang Bian](https://jwbian.net/), Huangying Zhan, Naiyan Wang, Tat-Jun Chin, Chunhua Shen, Ian Reid
>
>[[ArXiv](https://arxiv.org/abs/2006.02708) | [Project](https://jwbian.net/unsupervised-indoor-depth) | [中文主页](https://jwbian.net/unsupervised-indoor-depth-cn)]
## Depth and point cloud visulization on 7 Scenes
[](https://www.youtube.com/watch?v=A6OTJegbFzY)
## If you find our work useful in your research please consider citing our paper:
@inproceedings{bian2019depth,
title={Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video},
author={Bian, Jia-Wang and Li, Zhichao and Wang, Naiyan and Zhan, Huangying and Shen, Chunhua and Cheng, Ming-Ming and Reid, Ian},
booktitle= {Thirty-third Conference on Neural Information Processing Systems (NeurIPS)},
year={2019}
}
@article{bian2020depth,
title={Unsupervised Depth Learning in Challenging Indoor Video: Weak Rectification to Rescue},
author={Bian, Jia-Wang and Zhan, Huangying and Wang, Naiyan and Chin, Tat-Jun and Shen, Chunhua and Reid, Ian},
journal={arXiv preprint arXiv:2006.02708},
year={2020}
}
## Core contributions
1. We analyze the effects of complicated camera motions on unsupervised depth learning.
2. We release an rectified NYUv2 dataset for unsupvised learning of single-view depth CNN.
## Datasets
Download our pre-processed dataset from the following link:
[rectified_nyu (for training)](https://1drv.ms/u/s!AiV6XqkxJHE2k3elbxAE9eE4IhRB?e=WoFpdF) | [nyu_test (for evaluation)](https://1drv.ms/u/s!AiV6XqkxJHE2kz85ZcYiCoZmSjKk?e=qGpvck)
## Training
1. Download [SC-SfMLearner-Release](https://github.com/JiawangBian/SC-SfMLearner-Release) by
```
git clone https://github.com/JiawangBian/SC-SfMLearner-Release.git
```
2. Run 'scripts/train_nyu.sh'
```
TRAIN_SET=/media/bjw/Disk/Dataset/rectified_nyu/
python train.py $TRAIN_SET \
--folder-type pair \
--resnet-layers 18 \
--num-scales 1 \
-b16 -s0.1 -c0.5 --epoch-size 0 --epochs 50 \
--with-ssim 1 \
--with-mask 1 \
--with-auto-mask 1 \
--with-pretrain 1 \
--log-output --with-gt \
--dataset nyu \
--name r18_rectified_nyu
```
## Evaluation
1. Download [Pretrained Models](https://1drv.ms/u/s!AiV6XqkxJHE2k3gXVTwjCgIPAUN2?e=SD5cSg).
2. Run 'scripts/test_nyu.sh'
```
DISPNET=checkpoints/rectified_nyu_r18/dispnet_model_best.pth.tar
DATA_ROOT=/media/bjw/Disk/Dataset/nyu_test
RESULTS_DIR=results/nyu_self/
# test 256*320 images
python test_disp.py --resnet-layers 18 --img-height 256 --img-width 320 \
--pretrained-dispnet $DISPNET --dataset-dir $DATA_ROOT/color \
--output-dir $RESULTS_DIR
# evaluate
python eval_depth.py \
--dataset nyu \
--pred_depth=$RESULTS_DIR/predictions.npy \
--gt_depth=$DATA_ROOT/depth.npy
```
## Results on NYUv2
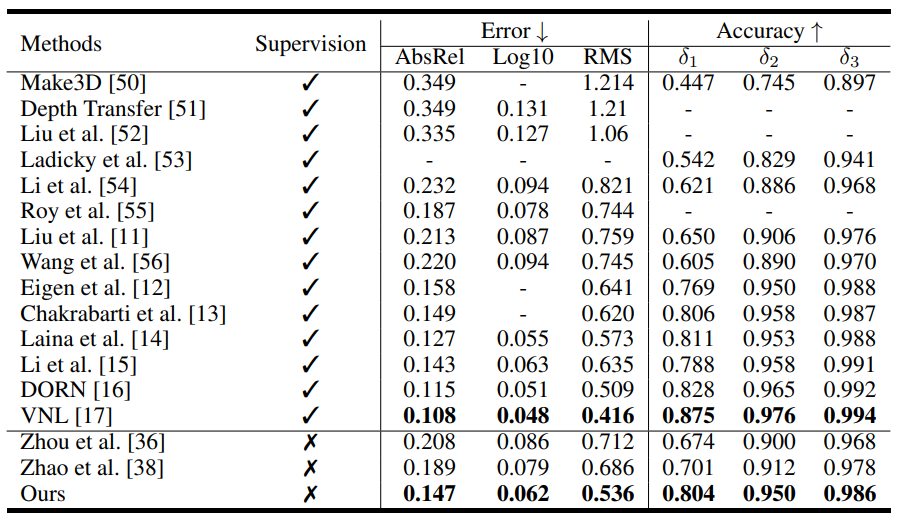 ## Visual comparison
## Visual comparison
 ## Related projects
* [SC-SfMLearner](https://github.com/JiawangBian/SC-SfMLearner-Release) (NeurIPS 2019, scale-consistent depth learning framework.)
* [Depth-VO-Feat](https://github.com/Huangying-Zhan/Depth-VO-Feat) (CVPR 2018, trained on stereo videos for depth and visual odometry)
* [DF-VO](https://github.com/Huangying-Zhan/DF-VO) (ICRA 2020, use scale-consistent depth with optical flow for more accurate visual odometry)
## Related projects
* [SC-SfMLearner](https://github.com/JiawangBian/SC-SfMLearner-Release) (NeurIPS 2019, scale-consistent depth learning framework.)
* [Depth-VO-Feat](https://github.com/Huangying-Zhan/Depth-VO-Feat) (CVPR 2018, trained on stereo videos for depth and visual odometry)
* [DF-VO](https://github.com/Huangying-Zhan/DF-VO) (ICRA 2020, use scale-consistent depth with optical flow for more accurate visual odometry)