# whisperlivekit
**Repository Path**: mirrors/whisperlivekit
## Basic Information
- **Project Name**: whisperlivekit
- **Description**: 实时、完全本地语音转文本,支持说话人识别
- **Primary Language**: Python
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: https://www.oschina.net/p/whisperlivekit
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 2
- **Created**: 2025-08-28
- **Last Updated**: 2025-11-01
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
WhisperLiveKit
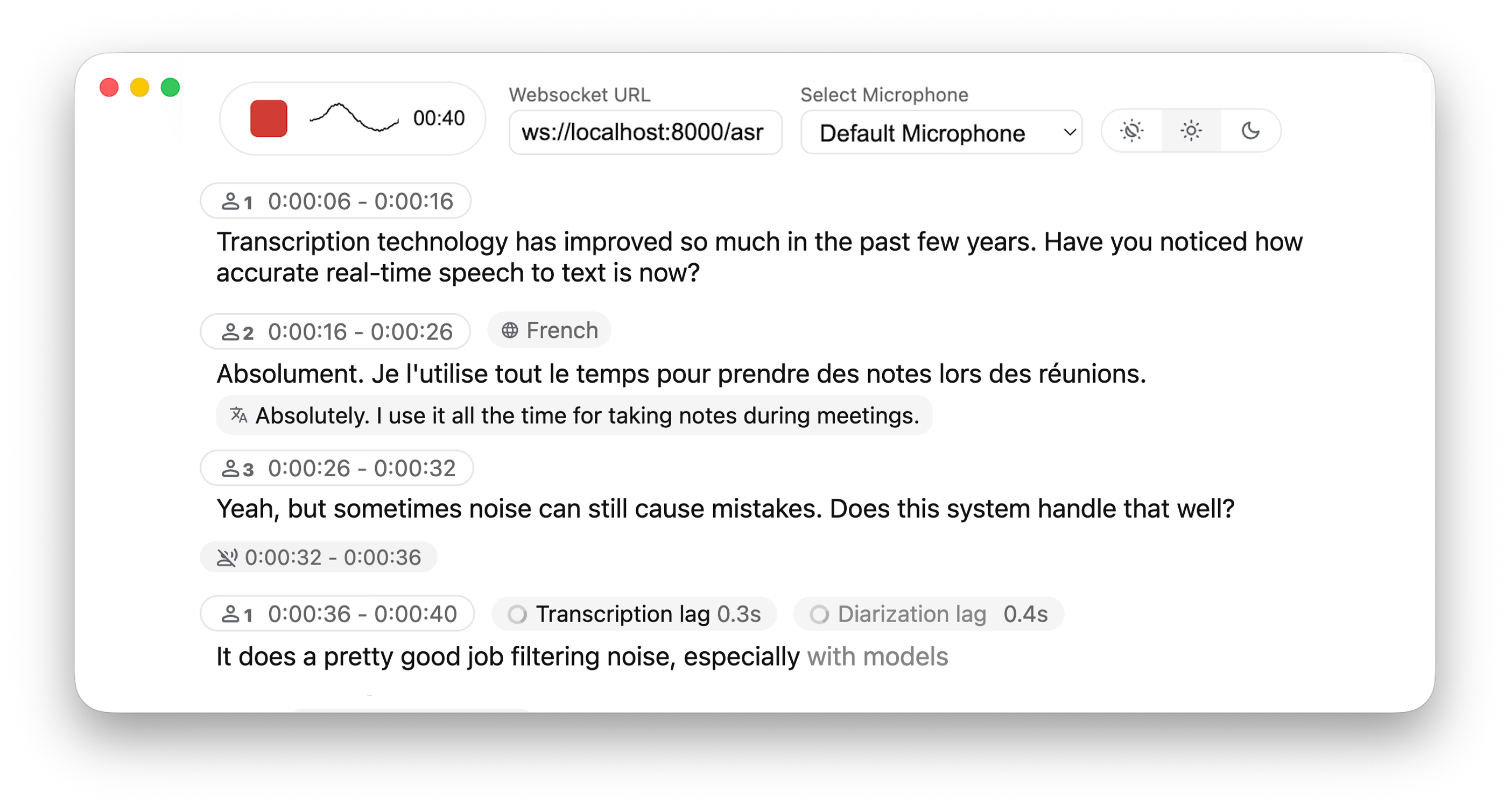
Real-time, Fully Local Speech-to-Text with Speaker Identification




Real-time transcription directly to your browser, with a ready-to-use backend+server and a simple frontend.
#### Powered by Leading Research:
- Simul-[Whisper](https://github.com/backspacetg/simul_whisper)/[Streaming](https://github.com/ufal/SimulStreaming) (SOTA 2025) - Ultra-low latency transcription using [AlignAtt policy](https://arxiv.org/pdf/2305.11408)
- [NLLW](https://github.com/QuentinFuxa/NoLanguageLeftWaiting) (2025), based on [distilled](https://huggingface.co/entai2965/nllb-200-distilled-600M-ctranslate2) [NLLB](https://arxiv.org/abs/2207.04672) (2022, 2024) - Simulatenous translation from & to 200 languages.
- [WhisperStreaming](https://github.com/ufal/whisper_streaming) (SOTA 2023) - Low latency transcription using [LocalAgreement policy](https://www.isca-archive.org/interspeech_2020/liu20s_interspeech.pdf)
- [Streaming Sortformer](https://arxiv.org/abs/2507.18446) (SOTA 2025) - Advanced real-time speaker diarization
- [Diart](https://github.com/juanmc2005/diart) (SOTA 2021) - Real-time speaker diarization
- [Silero VAD](https://github.com/snakers4/silero-vad) (2024) - Enterprise-grade Voice Activity Detection
> **Why not just run a simple Whisper model on every audio batch?** Whisper is designed for complete utterances, not real-time chunks. Processing small segments loses context, cuts off words mid-syllable, and produces poor transcription. WhisperLiveKit uses state-of-the-art simultaneous speech research for intelligent buffering and incremental processing.
### Architecture
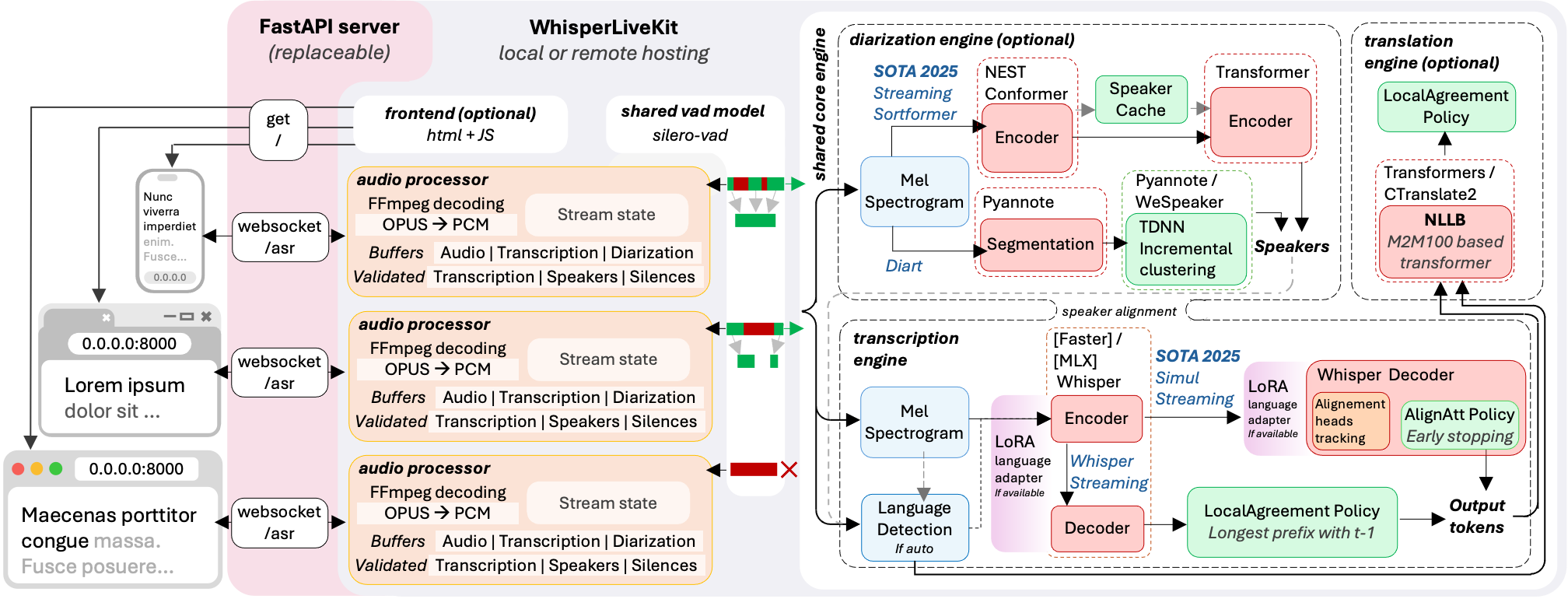 *The backend supports multiple concurrent users. Voice Activity Detection reduces overhead when no voice is detected.*
### Installation & Quick Start
```bash
pip install whisperlivekit
```
> You can also clone the repo and `pip install -e .` for the latest version.
#### Quick Start
1. **Start the transcription server:**
```bash
whisperlivekit-server --model base --language en
```
2. **Open your browser** and navigate to `http://localhost:8000`. Start speaking and watch your words appear in real-time!
> - See [tokenizer.py](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/simul_whisper/whisper/tokenizer.py) for the list of all available languages.
> - For HTTPS requirements, see the **Parameters** section for SSL configuration options.
#### Use it to capture audio from web pages.
Go to `chrome-extension` for instructions.
*The backend supports multiple concurrent users. Voice Activity Detection reduces overhead when no voice is detected.*
### Installation & Quick Start
```bash
pip install whisperlivekit
```
> You can also clone the repo and `pip install -e .` for the latest version.
#### Quick Start
1. **Start the transcription server:**
```bash
whisperlivekit-server --model base --language en
```
2. **Open your browser** and navigate to `http://localhost:8000`. Start speaking and watch your words appear in real-time!
> - See [tokenizer.py](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/simul_whisper/whisper/tokenizer.py) for the list of all available languages.
> - For HTTPS requirements, see the **Parameters** section for SSL configuration options.
#### Use it to capture audio from web pages.
Go to `chrome-extension` for instructions.
#### Optional Dependencies
| Optional | `pip install` |
|-----------|-------------|
| **Speaker diarization** | `git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]` |
| **Apple Silicon optimizations** | `mlx-whisper` |
| **Translation** | `nllw` |
| *[Not recommanded]* Speaker diarization with Diart | `diart` |
| *[Not recommanded]* Original Whisper backend | `whisper` |
| *[Not recommanded]* Improved timestamps backend | `whisper-timestamped` |
| OpenAI API backend | `openai` |
See **Parameters & Configuration** below on how to use them.
### Usage Examples
**Command-line Interface**: Start the transcription server with various options:
```bash
# Large model and translate from french to danish
whisperlivekit-server --model large-v3 --language fr --target-language da
# Diarization and server listening on */80
whisperlivekit-server --host 0.0.0.0 --port 80 --model medium --diarization --language fr
```
**Python API Integration**: Check [basic_server](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/basic_server.py) for a more complete example of how to use the functions and classes.
```python
from whisperlivekit import TranscriptionEngine, AudioProcessor, parse_args
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from contextlib import asynccontextmanager
import asyncio
transcription_engine = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global transcription_engine
transcription_engine = TranscriptionEngine(model="medium", diarization=True, lan="en")
yield
app = FastAPI(lifespan=lifespan)
async def handle_websocket_results(websocket: WebSocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
await websocket.send_json({"type": "ready_to_stop"})
@app.websocket("/asr")
async def websocket_endpoint(websocket: WebSocket):
global transcription_engine
# Create a new AudioProcessor for each connection, passing the shared engine
audio_processor = AudioProcessor(transcription_engine=transcription_engine)
results_generator = await audio_processor.create_tasks()
results_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
await websocket.accept()
while True:
message = await websocket.receive_bytes()
await audio_processor.process_audio(message)
```
**Frontend Implementation**: The package includes an HTML/JavaScript implementation [here](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/web/live_transcription.html). You can also import it using `from whisperlivekit import get_inline_ui_html` & `page = get_inline_ui_html()`
## Parameters & Configuration
| Parameter | Description | Default |
|-----------|-------------|---------|
| `--model` | Whisper model size. List and recommandations [here](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/docs/available_models.md) | `small` |
| `--model-path` | .pt file/directory containing whisper model. Overrides `--model`. Recommandations [here](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/docs/models_compatible_formats.md) | `None` |
| `--language` | List [here](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/whisperlivekit/simul_whisper/whisper/tokenizer.py). If you use `auto`, the model attempts to detect the language automatically, but it tends to bias towards English. | `auto` |
| `--target-language` | If sets, translate to using NLLB. Ex: `fr`. [200 languages available](https://github.com/QuentinFuxa/WhisperLiveKit/blob/main/docs/supported_languages.md). If you want to translate to english, you should rather use `--task translate`, since Whisper can do it directly. | `None` |
| `--task` | Set to `translate` to translate *only* to english, using Whisper translation. | `transcribe` |
| `--diarization` | Enable speaker identification | `False` |
| `--backend` | Processing backend. You can switch to `faster-whisper` if `simulstreaming` does not work correctly | `simulstreaming` |
| `--no-vac` | Disable Voice Activity Controller | `False` |
| `--no-vad` | Disable Voice Activity Detection | `False` |
| `--warmup-file` | Audio file path for model warmup | `jfk.wav` |
| `--host` | Server host address | `localhost` |
| `--port` | Server port | `8000` |
| `--ssl-certfile` | Path to the SSL certificate file (for HTTPS support) | `None` |
| `--ssl-keyfile` | Path to the SSL private key file (for HTTPS support) | `None` |
| `--forwarded-allow-ips` | Ip or Ips allowed to reverse proxy the whisperlivekit-server. Supported types are IP Addresses (e.g. 127.0.0.1), IP Networks (e.g. 10.100.0.0/16), or Literals (e.g. /path/to/socket.sock) | `None` |
| `--pcm-input` | raw PCM (s16le) data is expected as input and FFmpeg will be bypassed. Frontend will use AudioWorklet instead of MediaRecorder | `False` |
| Translation options | Description | Default |
|-----------|-------------|---------|
| `--nllb-backend` | `transformers` or `ctranslate2` | `ctranslate2` |
| `--nllb-size` | `600M` or `1.3B` | `600M` |
| Diarization options | Description | Default |
|-----------|-------------|---------|
| `--diarization-backend` | `diart` or `sortformer` | `sortformer` |
| `--disable-punctuation-split` | Disable punctuation based splits. See #214 | `False` |
| `--segmentation-model` | Hugging Face model ID for Diart segmentation model. [Available models](https://github.com/juanmc2005/diart/tree/main?tab=readme-ov-file#pre-trained-models) | `pyannote/segmentation-3.0` |
| `--embedding-model` | Hugging Face model ID for Diart embedding model. [Available models](https://github.com/juanmc2005/diart/tree/main?tab=readme-ov-file#pre-trained-models) | `speechbrain/spkrec-ecapa-voxceleb` |
| SimulStreaming backend options | Description | Default |
|-----------|-------------|---------|
| `--disable-fast-encoder` | Disable Faster Whisper or MLX Whisper backends for the encoder (if installed). Inference can be slower but helpful when GPU memory is limited | `False` |
| `--custom-alignment-heads` | Use your own alignment heads, useful when `--model-dir` is used | `None` |
| `--frame-threshold` | AlignAtt frame threshold (lower = faster, higher = more accurate) | `25` |
| `--beams` | Number of beams for beam search (1 = greedy decoding) | `1` |
| `--decoder` | Force decoder type (`beam` or `greedy`) | `auto` |
| `--audio-max-len` | Maximum audio buffer length (seconds) | `30.0` |
| `--audio-min-len` | Minimum audio length to process (seconds) | `0.0` |
| `--cif-ckpt-path` | Path to CIF model for word boundary detection | `None` |
| `--never-fire` | Never truncate incomplete words | `False` |
| `--init-prompt` | Initial prompt for the model | `None` |
| `--static-init-prompt` | Static prompt that doesn't scroll | `None` |
| `--max-context-tokens` | Maximum context tokens | `None` |
| `--preload-model-count` | Optional. Number of models to preload in memory to speed up loading (set up to the expected number of concurrent users) | `1` |
| WhisperStreaming backend options | Description | Default |
|-----------|-------------|---------|
| `--confidence-validation` | Use confidence scores for faster validation | `False` |
| `--buffer_trimming` | Buffer trimming strategy (`sentence` or `segment`) | `segment` |
> For diarization using Diart, you need to accept user conditions [here](https://huggingface.co/pyannote/segmentation) for the `pyannote/segmentation` model, [here](https://huggingface.co/pyannote/segmentation-3.0) for the `pyannote/segmentation-3.0` model and [here](https://huggingface.co/pyannote/embedding) for the `pyannote/embedding` model. **Then**, login to HuggingFace: `huggingface-cli login`
### 🚀 Deployment Guide
To deploy WhisperLiveKit in production:
1. **Server Setup**: Install production ASGI server & launch with multiple workers
```bash
pip install uvicorn gunicorn
gunicorn -k uvicorn.workers.UvicornWorker -w 4 your_app:app
```
2. **Frontend**: Host your customized version of the `html` example & ensure WebSocket connection points correctly
3. **Nginx Configuration** (recommended for production):
```nginx
server {
listen 80;
server_name your-domain.com;
location / {
proxy_pass http://localhost:8000;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
}}
```
4. **HTTPS Support**: For secure deployments, use "wss://" instead of "ws://" in WebSocket URL
## 🐋 Docker
Deploy the application easily using Docker with GPU or CPU support.
### Prerequisites
- Docker installed on your system
- For GPU support: NVIDIA Docker runtime installed
### Quick Start
**With GPU acceleration (recommended):**
```bash
docker build -t wlk .
docker run --gpus all -p 8000:8000 --name wlk wlk
```
**CPU only:**
```bash
docker build -f Dockerfile.cpu -t wlk .
docker run -p 8000:8000 --name wlk wlk
```
### Advanced Usage
**Custom configuration:**
```bash
# Example with custom model and language
docker run --gpus all -p 8000:8000 --name wlk wlk --model large-v3 --language fr
```
### Memory Requirements
- **Large models**: Ensure your Docker runtime has sufficient memory allocated
#### Customization
- `--build-arg` Options:
- `EXTRAS="whisper-timestamped"` - Add extras to the image's installation (no spaces). Remember to set necessary container options!
- `HF_PRECACHE_DIR="./.cache/"` - Pre-load a model cache for faster first-time start
- `HF_TKN_FILE="./token"` - Add your Hugging Face Hub access token to download gated models
## 🔮 Use Cases
Capture discussions in real-time for meeting transcription, help hearing-impaired users follow conversations through accessibility tools, transcribe podcasts or videos automatically for content creation, transcribe support calls with speaker identification for customer service...