![]()




&color=red)


 [](https://replicate.com/zsxkib/hunyuan-video)
[](https://replicate.com/zsxkib/hunyuan-video)
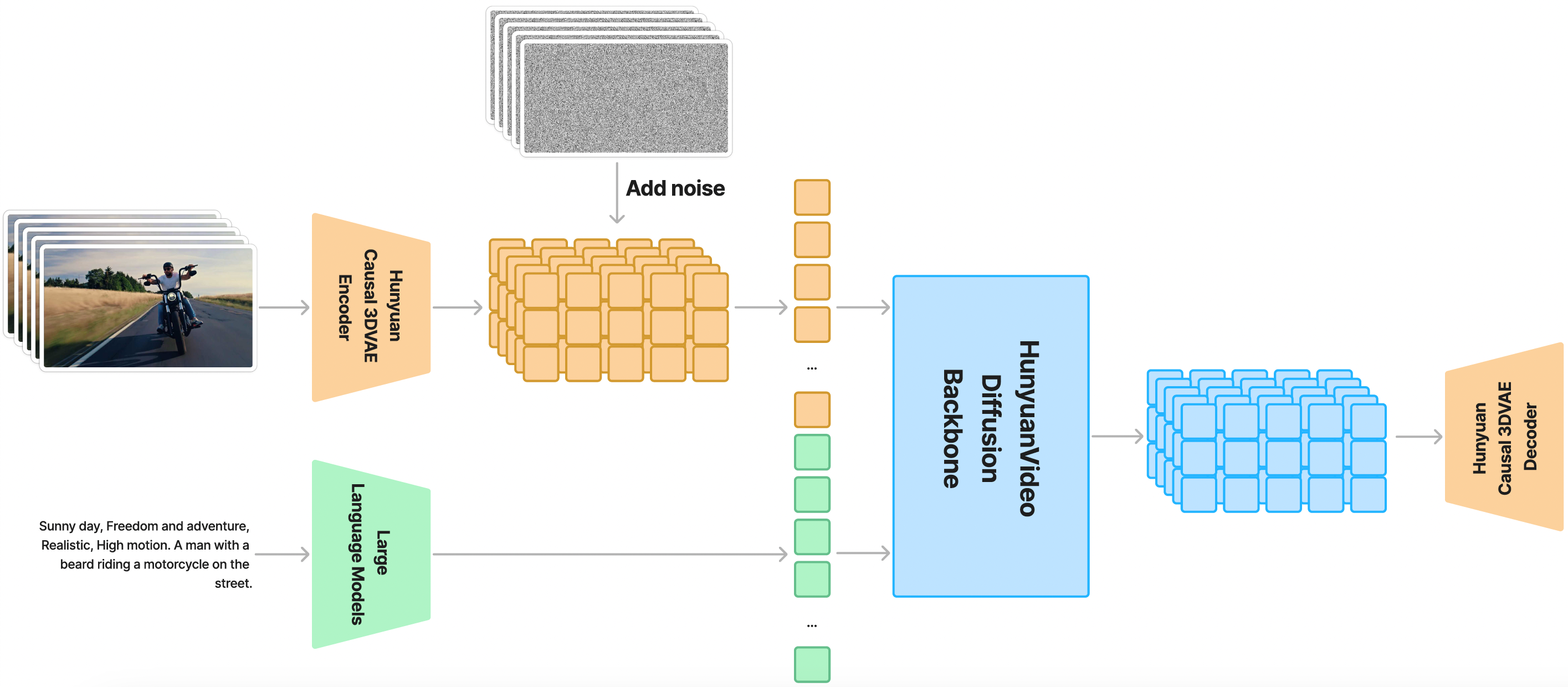
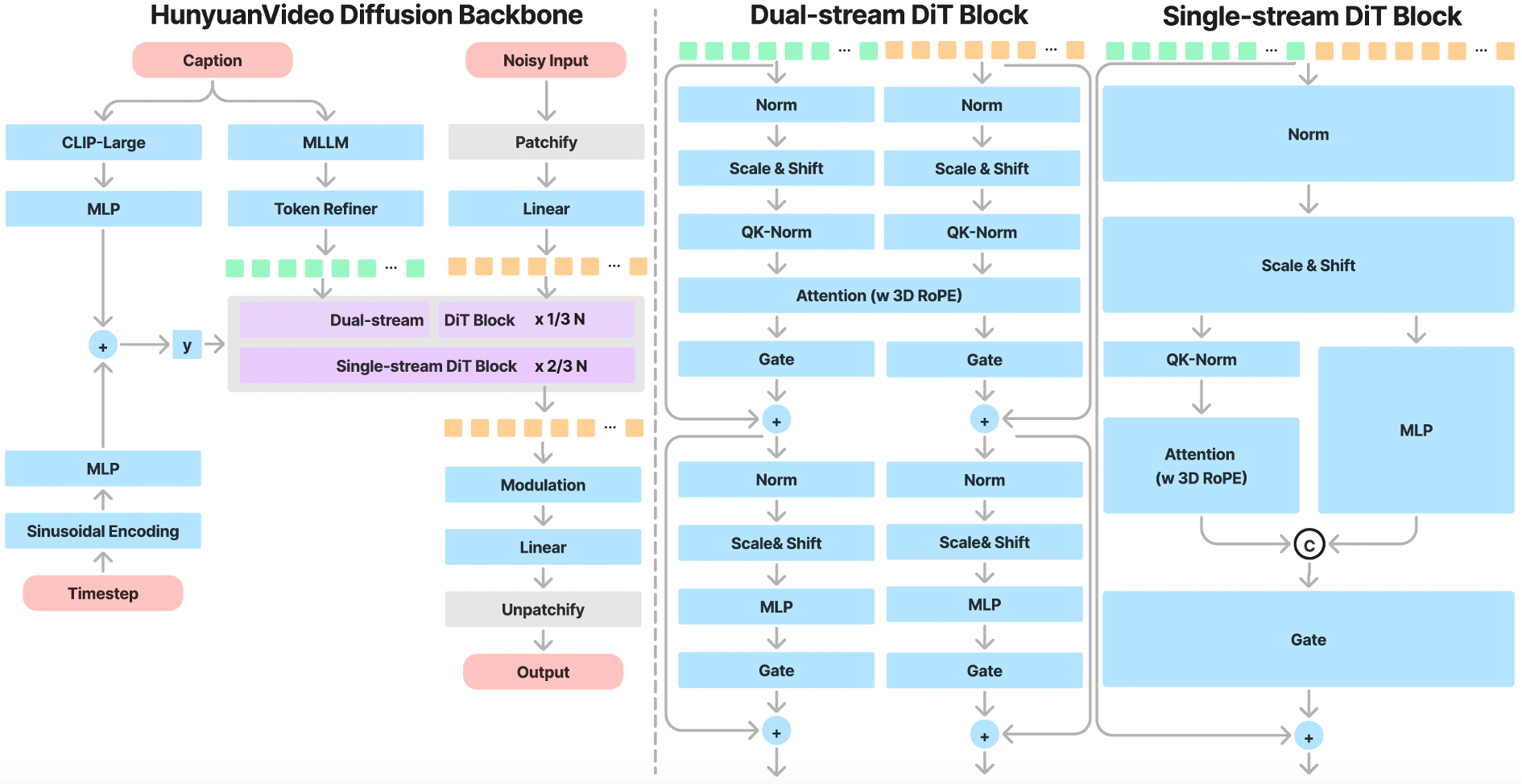
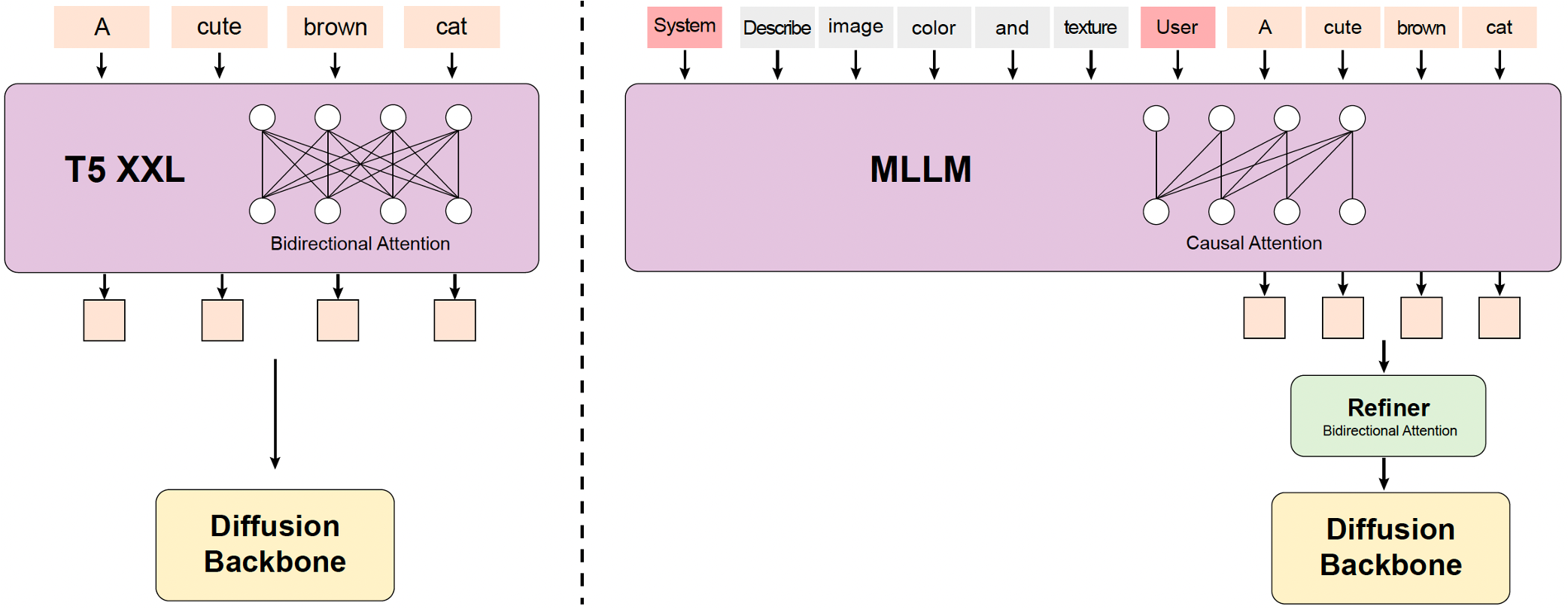

| 模型 | 是否开源 | 时长 | 文本对齐 | 运动质量 | 视觉质量 | 综合评价 | 排序 |
|---|---|---|---|---|---|---|---|
| HunyuanVideo (Ours) | ✔ | 5s | 61.8% | 66.5% | 95.7% | 41.3% | 1 |
| 国内模型 A (API) | ✘ | 5s | 62.6% | 61.7% | 95.6% | 37.7% | 2 |
| 国内模型 B (Web) | ✘ | 5s | 60.1% | 62.9% | 97.7% | 37.5% | 3 |
| GEN-3 alpha (Web) | ✘ | 6s | 47.7% | 54.7% | 97.5% | 27.4% | 4 |
| Luma1.6 (API) | ✘ | 5s | 57.6% | 44.2% | 94.1% | 24.8% | 5 |
| 在 8xGPU上生成1280x720 (129 帧 50 步)的时耗 (秒) | |||
|---|---|---|---|
| 1 | 2 | 4 | 8 |
| 1904.08 | 934.09 (2.04x) | 514.08 (3.70x) | 337.58 (5.64x) |