
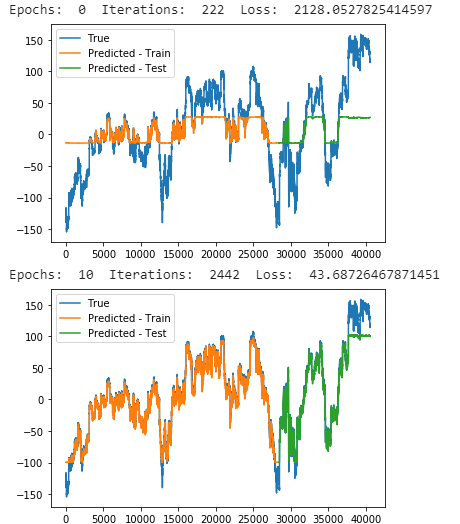
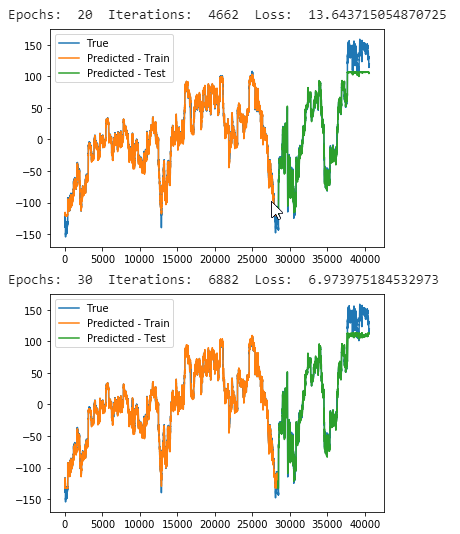
Stargazers over time
Stargazers over time
 |
|  |
|----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------|
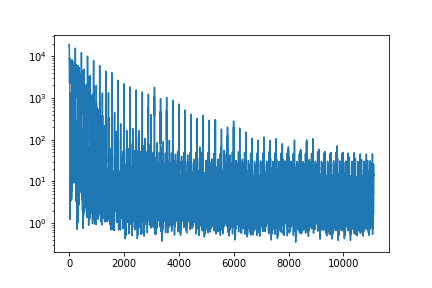
### Training Loss
|
|
|----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------|
### Training Loss
|  |
|  |
|------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
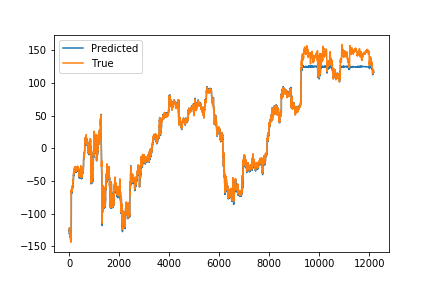
### Prediction
|
|
|------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
### Prediction
|  |
|-----------------------------------------------------------------------------------------------------|
## DA-RNN
In the paper [*"A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction"*](https://arxiv.org/pdf/1704.02971.pdf).
They proposed a novel dual-stage attention-based recurrent neural network (DA-RNN) for time series prediction. In the first stage, an input attention mechanism is introduced to adaptively extract relevant driving series (a.k.a., input features) at each time step by referring to the previous encoder hidden state. In the second stage, a temporal attention mechanism is introduced to select relevant encoder hidden states across all time steps.
For the objective, a square loss is used. With these two attention mechanisms, the DA-RNN can adaptively select the most relevant input features and capture the long-term temporal dependencies of a time series. A graphical illustration of the proposed model is shown in Figure 1.
|
|-----------------------------------------------------------------------------------------------------|
## DA-RNN
In the paper [*"A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction"*](https://arxiv.org/pdf/1704.02971.pdf).
They proposed a novel dual-stage attention-based recurrent neural network (DA-RNN) for time series prediction. In the first stage, an input attention mechanism is introduced to adaptively extract relevant driving series (a.k.a., input features) at each time step by referring to the previous encoder hidden state. In the second stage, a temporal attention mechanism is introduced to select relevant encoder hidden states across all time steps.
For the objective, a square loss is used. With these two attention mechanisms, the DA-RNN can adaptively select the most relevant input features and capture the long-term temporal dependencies of a time series. A graphical illustration of the proposed model is shown in Figure 1.

Figure 1: Graphical illustration of the dual-stage attention-based recurrent neural network.