# tvm
**Repository Path**: mirrors_pytorch/tvm
## Basic Information
- **Project Name**: tvm
- **Description**: TVM integration into PyTorch
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2020-08-18
- **Last Updated**: 2025-11-22
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# Pytorch TVM Extension
[](https://circleci.com/gh/pytorch/tvm)
 ## Build
Install the latest Nightly build of PyTorch.
Then, build this repo
```
# Make sure the right llvm-config is in your PATH
python setup.py install
```
## Test
```
python setup.py test
```
## Usage
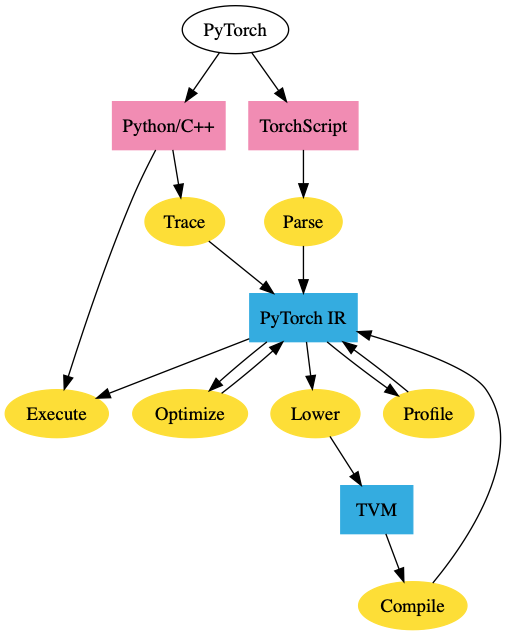
This package transparently hooks into PyTorch's JIT, so the same tooling is applicable (see `@torch.jit.script`, `torch.jit.trace` and `graph_for`). See below for an example.
```
import torch
import torch_tvm
torch_tvm.enable()
# The following function will be compiled with TVM
@torch.jit.script
def my_func(a, b, c):
return a * b + c
```
To disable the JIT hooks, use `torch_tvm.disable()`.
## Code Layout
- `register.cpp`: Sets up pybind bindings and invokes the registration of a TVM backend.
- `compiler.{h,cpp}`: Main logic to compile a PyTorch JIT graph with TVM.
- `operators.{h,cpp}`: Location of mapping from JIT IR to TVM operators.
## FAQ
### How do I configure TVM compilation?
All options are available as keyword arguments in the `enable` function exposed by `torch_tvm`.
The optimization level, device type, device and host compilation targets are all exposed directly from TVM.
```
torch_tvm.enable(
opt_level=3,
device_type="cpu",
device="llvm",
host="llvm")
```
### How do I register a new TVM operator?
First, ensure the operator is [registered with Relay](https://docs.tvm.ai/dev/relay_add_op.html#registering-an-operator).
Then, register a map from PyTorch symbols to a Relay `CallNode` with `RegisterTVMOperator`.
This can be done in any compilation unit provided it is linked into the final `torch_tvm` library.
See [`torch_tvm/operators.cpp`](https://github.com/pytorch/tvm/blob/master/torch_tvm/operators.cpp) for examples.
```
RegisterTVMOperator reg_relu({
{Symbol::fromQualString("aten::relu"),
[](Node* node, tvm::Array inputs) {
auto op = tvm::relay::Op::Get("nn.relu");
return tvm::relay::CallNode::make(op, inputs, tvm::Attrs(), {});
}},
});
```
### How do I extract the Relay expression associated with a PyTorch Graph?
If the PyTorch function can be fully converted to Relay, it is possible to extract the expression itself
using `torch_tvm.to_relay(func, inputs)`. Example inputs must be passed in to calculate type information.
```
def add(a, b, c):
return a + b + c
# via tracing
relay_graph = torch_tvm.to_relay(add, inputs)
@torch.jit.script
def mul(a, b, c):
return a * b * c
# via script
relay_graph = torch_tvm.to_relay(mul, inputs)
```
Note that not all functions can be converted to Relay in their entirety and will raise exceptions
if expression extraction is attempted. To solve this isse, simply refactor the function.
## v0.1 Roadmap
Below, in order, is a prioritized list of tasks for this repository.
- [x] End to end build and runtime
- [x] Operator translation
- [x] Add
- [x] Multiply
- [x] Convolution
- [x] BatchNorm
- [x] Relu
- [x] AveragePool
- [x] MaxPool
- [x] Linear
- [x] Reshape
- [x] AdaptiveAveragePool
- [x] Tooling
- [x] Model coverage checks
- [x] Benchmarks for master
- [x] User exposed configurations
- [x] Backend selection (CPU/Cuda/OpenCL)
- [x] Optimization level
- [ ] Custom TVM operator registration
- [ ] Enable Python/C++ mechanism to use custom TVM operators and schedules
- [x] Enable Relay op registration
- [x] Bail-out mechanism
- When TVM cannot compile a subgraph, invoke PyTorch JIT fallback
- [x] Extract Relay expression
- [x] Enable exposure of ops registered in eager mode under `torch.ops.tvm.*`
### v0.2 Plan
- [ ] View support
- [x] Zero copy `set_input`
- [ ] Subsystem integration
- [ ] Threadpool integration
- [ ] Allocator integration
- `tvm/include/tvm/runtime/device_api.h`
- [ ] Distributed communication
- [ ] IR integration
- [ ] Control flow
- [ ] Aliasing
- [ ] Operators
- [ ] transpose
- [ ] chunk
- [ ] repeat
- [ ] cat
- [ ] unsqueeze
- [ ] slice
- [ ] softmax
- [ ] bmm
- [ ] layernorm
## Build
Install the latest Nightly build of PyTorch.
Then, build this repo
```
# Make sure the right llvm-config is in your PATH
python setup.py install
```
## Test
```
python setup.py test
```
## Usage
This package transparently hooks into PyTorch's JIT, so the same tooling is applicable (see `@torch.jit.script`, `torch.jit.trace` and `graph_for`). See below for an example.
```
import torch
import torch_tvm
torch_tvm.enable()
# The following function will be compiled with TVM
@torch.jit.script
def my_func(a, b, c):
return a * b + c
```
To disable the JIT hooks, use `torch_tvm.disable()`.
## Code Layout
- `register.cpp`: Sets up pybind bindings and invokes the registration of a TVM backend.
- `compiler.{h,cpp}`: Main logic to compile a PyTorch JIT graph with TVM.
- `operators.{h,cpp}`: Location of mapping from JIT IR to TVM operators.

## FAQ
### How do I configure TVM compilation?
All options are available as keyword arguments in the `enable` function exposed by `torch_tvm`.
The optimization level, device type, device and host compilation targets are all exposed directly from TVM.
```
torch_tvm.enable(
opt_level=3,
device_type="cpu",
device="llvm",
host="llvm")
```
### How do I register a new TVM operator?
First, ensure the operator is [registered with Relay](https://docs.tvm.ai/dev/relay_add_op.html#registering-an-operator).
Then, register a map from PyTorch symbols to a Relay `CallNode` with `RegisterTVMOperator`.
This can be done in any compilation unit provided it is linked into the final `torch_tvm` library.
See [`torch_tvm/operators.cpp`](https://github.com/pytorch/tvm/blob/master/torch_tvm/operators.cpp) for examples.
```
RegisterTVMOperator reg_relu({
{Symbol::fromQualString("aten::relu"),
[](Node* node, tvm::Array inputs) {
auto op = tvm::relay::Op::Get("nn.relu");
return tvm::relay::CallNode::make(op, inputs, tvm::Attrs(), {});
}},
});
```
### How do I extract the Relay expression associated with a PyTorch Graph?
If the PyTorch function can be fully converted to Relay, it is possible to extract the expression itself
using `torch_tvm.to_relay(func, inputs)`. Example inputs must be passed in to calculate type information.
```
def add(a, b, c):
return a + b + c
# via tracing
relay_graph = torch_tvm.to_relay(add, inputs)
@torch.jit.script
def mul(a, b, c):
return a * b * c
# via script
relay_graph = torch_tvm.to_relay(mul, inputs)
```
Note that not all functions can be converted to Relay in their entirety and will raise exceptions
if expression extraction is attempted. To solve this isse, simply refactor the function.
## v0.1 Roadmap
Below, in order, is a prioritized list of tasks for this repository.
- [x] End to end build and runtime
- [x] Operator translation
- [x] Add
- [x] Multiply
- [x] Convolution
- [x] BatchNorm
- [x] Relu
- [x] AveragePool
- [x] MaxPool
- [x] Linear
- [x] Reshape
- [x] AdaptiveAveragePool
- [x] Tooling
- [x] Model coverage checks
- [x] Benchmarks for master
- [x] User exposed configurations
- [x] Backend selection (CPU/Cuda/OpenCL)
- [x] Optimization level
- [ ] Custom TVM operator registration
- [ ] Enable Python/C++ mechanism to use custom TVM operators and schedules
- [x] Enable Relay op registration
- [x] Bail-out mechanism
- When TVM cannot compile a subgraph, invoke PyTorch JIT fallback
- [x] Extract Relay expression
- [x] Enable exposure of ops registered in eager mode under `torch.ops.tvm.*`
### v0.2 Plan
- [ ] View support
- [x] Zero copy `set_input`
- [ ] Subsystem integration
- [ ] Threadpool integration
- [ ] Allocator integration
- `tvm/include/tvm/runtime/device_api.h`
- [ ] Distributed communication
- [ ] IR integration
- [ ] Control flow
- [ ] Aliasing
- [ ] Operators
- [ ] transpose
- [ ] chunk
- [ ] repeat
- [ ] cat
- [ ] unsqueeze
- [ ] slice
- [ ] softmax
- [ ] bmm
- [ ] layernorm