

代码拉取完成,页面将自动刷新
Data Accelerator for Apache Spark democratizes streaming big data using Spark by offering several key features such as a no-code experience to set up a data pipeline as well as fast dev-test loop for creating complex logic. Our team has been using the project for two years within Microsoft for processing streamed data across many internal deployments handling data volumes at Microsoft scale. It offers an easy to use platform to learn and evaluate streaming needs and requirements. We are thrilled to share this project with the wider community as open source!
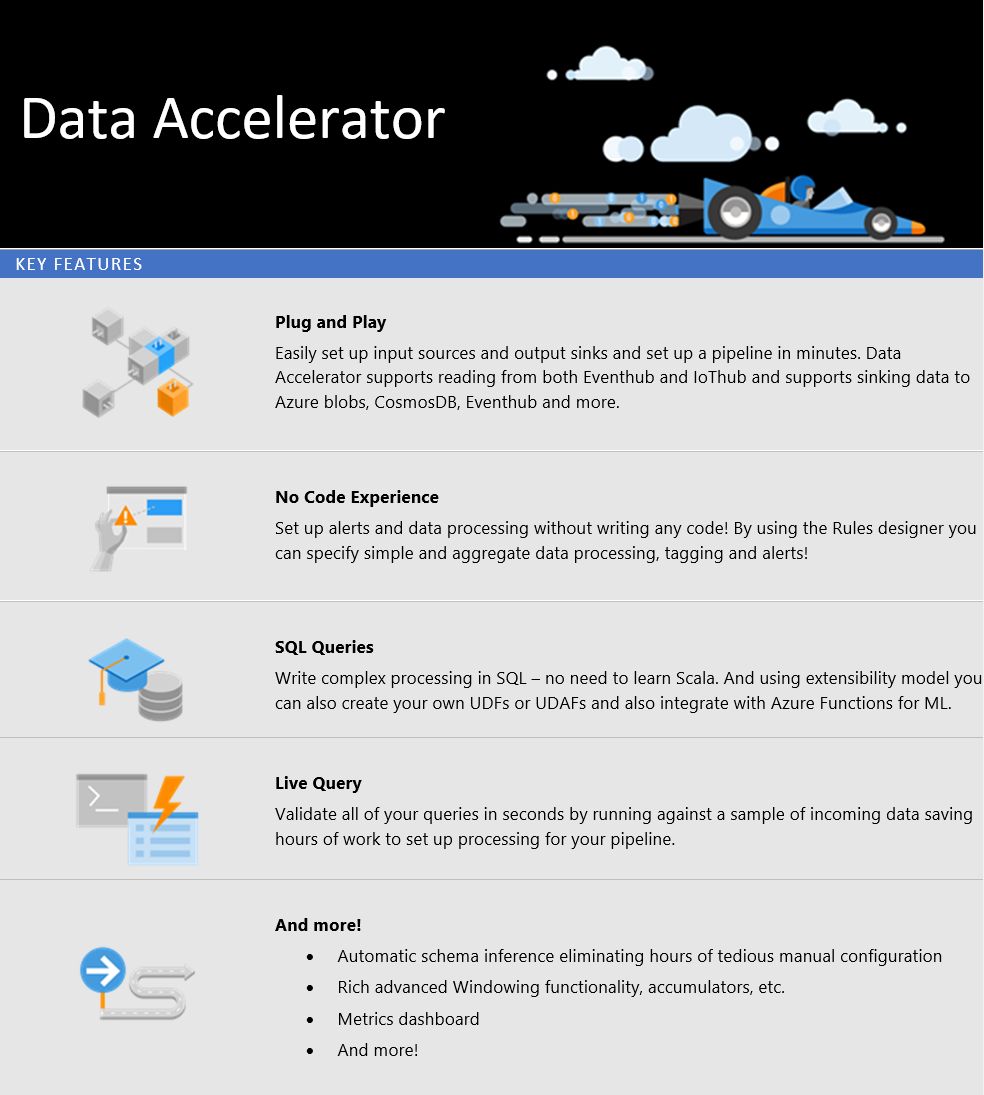
Data Accelerator offers three level of experiences:
You can get started locally for Windows, macOs and Linux following these instructions
To deploy to Azure, you can use the ARM template; see instructions deploy to Azure.
The data-accelerator repository contains everything needed to set up an end-to-end data pipeline. There are many ways you can participate in the project:
To unleash the full power Data Accelerator, deploy to Azure and check cloud mode tutorials.
We have also enabled a "hello world" experience that you try out locally by running docker container. When running locally there are no dependencies on Azure, however the functionality is very limited and only there to give you a very cursory overview of Data Accelerator.
To run Data Accelerator locally, deploy locally and then check out the local mode tutorials.
Data Accelerator for Spark runs on the following:
See the wiki pages for further information on how to build, diagnose and maintain your data pipelines built using Data Accelerator for Spark.
If you are interested in fixing issues and contributing to the code base, we would love to partner with you. Try things out, join in the design conversations and make pull requests.
Please also see our Code of Conduct.
Security issues and bugs should be reported privately, via email, to the Microsoft Security Response Center (MSRC) secure@microsoft.com. You should receive a response within 24 hours. If for some reason you do not, please follow up via email to ensure we received your original message. Further information, including the MSRC PGP key, can be found in the Security TechCenter.
This repository is licensed with the MIT license.
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





