

代码拉取完成,页面将自动刷新
同步操作将从 xiyuan0918/ppspider 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
# win
set PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1
# unix
export PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1
@Launcher({
workplace: __dirname + "/workplace",
tasks: [
TestTask
],
workerFactorys: [
new PuppeteerWorkerFactory({
headless: false,
executablePath: "YOU_CHROMIUM_OR_CHROME_EXECUTE_PATH"
})
]
})
class App {}
npm install -g typescript
推荐使用 IDEA + nodejs 插件
IDEA一定要下载 Ultimate 版本,否则有很多功能无法使用

下载nodejs插件的时候,需根据IDEA的版本下载可用的 nodejs 版本,IDEA的版本可通过菜单栏点击 Help -> About 看到
例如我正在使用的IDEA和nodejs插件版本


ppspider_example github 地址
https://github.com/xiyuan-fengyu/ppspider_example
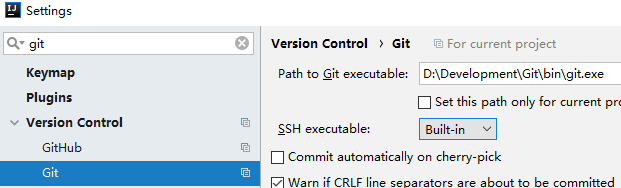
需要先安装git,并在IDEA中配置git的可执行文件的路径
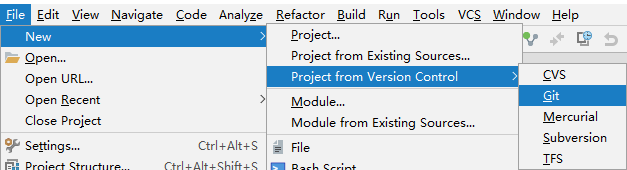

鼠标右键 package.json ,点击 Run 'npm install'
或者在terminal中cd到项目所在目录,运行 'npm install'
所有的npm依赖都会存放到当前项目下的 node_modules 文件夹中
tsc 是 typescript 的编译工具,将 typescript 代码编译为 js,之后便可右键 js 文件运行了
tsc 在运行期间会监听 ts 文件变化,自动编译有变动的 ts 文件
运行方式:
1.(推荐)右键 package.json,点击 Show npm Scripts,双击 auto build
2.在 IDEA 中打开一个 terminal, 运行 tsc
右键运行 lib/quickstart/App.js
用浏览器打开 http://localhost:9000 可以实时查看爬虫系统的运行情况
申明形式
export function TheDecoratorName(args) { ... }
使用方式
@TheDecoratorName(args)
乍一看和java中的注解一样,但实际上这个更为强大,不仅能提供元数据,还能对类或方法的属性行为做修改装饰,实现切面的效果,ppspider中很多功能都是通过装饰器来提供的
接下来介绍一下实际开发中会使用到的装饰器
export function Launcher(theAppInfo: AppInfo) { ... }
用于申明整个爬虫系统的启动入口
其参数类型为
export type AppInfo = {
// workplace属性描述了整个爬虫系统的工作目录,系统停止时保存工作状态的cache文件、系统工作中保存任务信息的数据库文件都会存储到整个目录下;用户抓取的数据文件也可以保存到整个目录下
workplace: string;
// tasks属性用于注入所有的任务的类
tasks: any[];
// workerFactory属性用于注入所有worker的工厂类实例,目前仅提供了一种工厂类 PuppeteerWorkerFactory
workerFactorys: WorkerFactory<any>[];
// webUiPort属性用于申明系统管理界面的服务器端口,默认9000
webUiPort?: number | 9000;
// 日志配置
logger?: LoggerSetting;
}
可以通过全局变量 appInfo 访问到这些信息
import {Launcher, PuppeteerWorkerFactory} from "ppspider";
import {TestTask} from "./tasks/TestTask";
@Launcher({
workplace: __dirname + "/workplace",
tasks: [
TestTask
],
workerFactorys: [
new PuppeteerWorkerFactory({
headless: false
})
]
})
class App {
}
export function OnStart(config: OnStartConfig) { ... }
用于声明一个在爬虫系统启动时执行一次的子任务;后续可以在管理界面上点击该任务名后面的重新执行的按钮即可让该任务重新执行一次
参数说明
export type OnStartConfig = {
// 页面地址
urls: string | string[];
// worker工厂类型,其类型的实例必须在 @Launcher 参数的workerFactorys属性中申明(NoneWorkerFactory 除外)
// 目前提供的 WorkerFactory 有 ,PuppeteerWorkerFactory, NoneWorkerFactory
workerFactory: WorkerFactoryClass;
// 系统启动后该队列是否处于工作状态
// 通过 mainMessager.emit(MainMessagerEvent.QueueManager_QueueToggle_queueName_running, queueNameRegex: string, running: boolean) 来更改多个队列的工作情况
running?: boolean;
// 任务的最大并行数配置,可以是具体的数字,也可以用cron表达式动态设置最大的并行数
parallel?: ParallelConfig;
// 该子任务的执行间隔,同一个队列中多个并行任务共享同一个间隔
exeInterval?: number;
// 在 exeInterval 基础上增加一个随机的抖动,这个值为左右抖动最大半径,默认为 exeIntervalJitter * 0.25
exeIntervalJitter?: number;
// 该子任务的具体描述
description?: string;
}
使用例子 @OnStart example
import {
Job,
logger,
mainMessager,
MainMessagerEvent,
NoneWorkerFactory,
OnStart, PromiseUtil,
PuppeteerUtil,
PuppeteerWorkerFactory
} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnStart({
urls: "http://www.baidu.com",
workerFactory: PuppeteerWorkerFactory
})
async index(page: Page, job: Job) {
await page.goto(job.url());
const urls = await PuppeteerUtil.links(page, {
"all": "http.*"
});
logger.debugValid && logger.debug(JSON.stringify(urls, null, 4));
// 等待 3000 毫秒 后启动 OnStart_TestTask_noneWorkerTest 这个队列
await PromiseUtil.sleep(3000);
mainMessager.emit(MainMessagerEvent.QueueManager_QueueToggle_queueNameRegex_running, "OnStart_TestTask_noneWorkerTest", true);
}
@OnStart({
urls: "",
workerFactory: NoneWorkerFactory,
running: false, // 系统启动后这个队列处于等待状态,直到这个属性被一个事件消息更改为 true
parallel: 1,
exeInterval: 10000
})
async noneWorkerTest(worker: any, job: Job) {
console.log("noneWorkerTest", worker, job);
}
}
export function OnTime(config: OnTimeConfig) { ... }
用于声明一个在特定时间周期性执行的任务,通过cron表达式设置执行时间
参数说明
export type OnTimeConfig = {
// 页面地址
urls: string | string[];
// 执行时间的cron表达式
cron: string;
// worker工厂类型,其类型的实例必须在 @Launcher 参数的workerFactorys属性中申明(NoneWorkerFactory 除外)
// 目前提供的 WorkerFactory 有 ,PuppeteerWorkerFactory, NoneWorkerFactory
workerFactory: WorkerFactoryClass;
running?: boolean;
// 任务的最大并行数配置,可以是具体的数字,也可以用cron表达式动态设置最大的并行数
parallel?: ParallelConfig;
// 该子任务的最小执行间隔,多个并行任务共享同一个间隔
exeInterval?: number;
exeIntervalJitter?: number;
// 该子任务的具体描述
description?: string;
}
使用例子 @OnTime example
import {Job, PuppeteerWorkerFactory, OnTime, DateUtil} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnTime({
urls: "http://www.baidu.com",
cron: "*/5 * * * * *",
workerFactory: PuppeteerWorkerFactory
})
async index(page: Page, job: Job) {
console.log(DateUtil.toStr());
}
}
这两个装饰器必须一起使用,@AddToQueue 将返回结果转换为 Job 添加到队列中,@FromQueue 从队列中获取 Job 并执行
@AddToQueue 的申明
export function AddToQueue(queueConfigs: AddToQueueConfig | AddToQueueConfig[]) { ... }
一个 @AddToQueue 可以配置一个或多个队列
队列配置的类型如下:
export type AddToQueueConfig = {
// 队列名
name: string;
// 队列类型, 目前提供了 DefaultQueue(先进先出),DefaultPriorityQueue(优先级队列)
queueType?: QueueClass;
// 过滤器类型,目前提供了 NoFilter(不进行过滤),BloonFilter(布隆过滤器)
filterType?: FilterClass;
}
可以在多个地方用 @AddToQueue 往同一个队列中添加 Job ,队列类型由第一次申明处的 queueType 决定,但每一处的 filterType 可以不一样
@AddToQueue 装饰的方法的返回结果必须是 AddToQueueData 类型的
export type CanCastToJob = string | string[] | Job | Job[];
export type AddToQueueData = Promise<CanCastToJob | {
[queueName: string]: CanCastToJob
}>
当 @AddToQueue 配置了多个队列信息时,返回类型必须是
Promise<{
[queueName: string]: CanCastToJob
}>
格式的数据;可以使用 PuppeteerUtil.links 方法方便的获取想要的连接,这个方法的返回结果正好是 AddToQueueData 格式的,具体的用法后面会介绍
@FromQueue 的申明
export function FromQueue(config: FromQueueConfig) { ... }
参数说明
export type FromQueueConfig = {
// 队列名
name: string;
// worker工厂类型,其类型的实例必须在 @Launcher 参数的workerFactorys属性中申明(NoneWorkerFactory 除外)
// 目前提供的 WorkerFactory 有 ,PuppeteerWorkerFactory, NoneWorkerFactory
workerFactory: WorkerFactoryClass;
running?: boolean;
// 任务的最大并行数配置,可以是具体的数字,也可以用cron表达式动态设置最大的并行数
parallel?: ParallelConfig;
// 该子任务的最小执行间隔,多个并行任务共享同一个间隔
exeInterval?: number;
exeIntervalJitter?: number;
// 该子任务的具体描述
description?: string;
}
使用例子 @AddToQueue @FromQueue example
import {AddToQueue, AddToQueueData, FromQueue, Job, OnStart, PuppeteerUtil, PuppeteerWorkerFactory} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnStart({
urls: "http://www.baidu.com",
workerFactory: PuppeteerWorkerFactory,
parallel: {
"0/20 * * * * ?": 1,
"10/20 * * * * ?": 2
}
})
@AddToQueue({
name: "test"
})
async index(page: Page, job: Job): AddToQueueData {
await page.goto(job.url());
return PuppeteerUtil.links(page, {
"test": "http.*"
});
}
@FromQueue({
name: "test",
workerFactory: PuppeteerWorkerFactory,
parallel: 1,
exeInterval: 1000
})
async printUrl(page: Page, job: Job) {
console.log(job.url());
}
}
export function JobOverride(queueName: string) { ... }
在将 job 添加到队列之前对 job 的信息进行重写修改
同一个队列只能设置一个 JobOverride
最常用的使用场景:很多时候多个带有额外参数或尾缀的url实际指向同一个页面, 这个时候可以提取出url中的唯一性标识,
并将其作为 job 的 key,用于重复性校验,避免重复抓取
实际上 OnStart, OnTime 两种类型的任务也是通过队列管理的,采用 DefaultQueue(NoFilter) 队列,队列的命名方式为
OnStart_ClassName_MethodName,所以也可以通过 JobOverride 对 job 进行修改
JobOverride example
export function Serialize(config?: SerializeConfig) { ... }
export class Serializable { ... }
export function Transient() { ... }
@Serialize 用于标记在序列化和反序列化中,需要保留类信息的类,没有这个标记的类的实例在
序列化之后会丢失类的信息
继承至 Serializable 的类可以自定义序列化和反序列化的实现方式, 例子:BitSet
@Transient 用于标记类成员,在序列化时忽略该字段。注意:类静态成员不参与序列化
这三个主要为关闭系统时保存运行状态提供支持,在实际使用的时候,如果有些类成员和运行状态没有直接关联,不需要序列化保存的
时候,一定要用 @Transient 来忽略该字段,可以减小序列化后文件的大小,也可以避免对象嵌套太深导致的反序列化失败
example
export function RequestMapping(url: string, method: "" | "GET" | "POST" = "") {}
@RequestMapping 用于声明 HTTP rest 接口,提供远程动态添加任务的能力,返回抓取结果需要自行实现(例如异步url回调) RequestMapping example
将 page 的窗口分辨率设置为 1920 * 1080
向 page 中注入 jquery,页面刷新或跳转后失效,所以这个方法必须在 page 加载完成之后调用
用于解析jsonp数据中的json
禁止或启用图片加载
用于监听接口的返回结果,可以设置监听次数
用于监听接口的返回结果,仅监听一次
下载图片
获取连接
获取满足 selector 的元素个数
使用 jQuery(selector) 查找节点, 并为其中没有 id 的节点添加随机 id,
最后返回一个所有节点 id 的数组
使用场景:
Page 中所有涉及到使用selector查找节点的方法都是使用 document.querySelector / document.querySelectorAll
但是有些 css selector, document.querySelector / document.querySelectorAll 不支持, jQuery 支持
例如 "#someId a:eq(0)", "#someId a:contains('next')"
可以通过这个方法为这些元素添加特殊的id,然后在通过 #specialId 去操作对应的节点
页面滚动到最底部
import {appInfo, Job, OnStart, PuppeteerUtil, PuppeteerWorkerFactory} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnStart({
urls: "http://www.baidu.com",
workerFactory: PuppeteerWorkerFactory
})
async index(page: Page, job: Job) {
await PuppeteerUtil.defaultViewPort(page);
await PuppeteerUtil.setImgLoad(page, false);
const hisResWait = PuppeteerUtil.onceResponse(page, "https://www.baidu.com/his\\?.*", async response => {
const resStr = await response.text();
console.log(resStr);
const resJson = PuppeteerUtil.jsonp(resStr);
console.log(resJson);
});
await page.goto("http://www.baidu.com");
await PuppeteerUtil.scrollToBottom(page, 5000, 100, 1000);
await PuppeteerUtil.addJquery(page);
console.log(await hisResWait);
const downloadImgRes = await PuppeteerUtil.downloadImg(page, ".index-logo-src", appInfo.workplace + "/download/img");
console.log(downloadImgRes);
const href = await PuppeteerUtil.links(page, {
"index": ["#result_logo", ".*"],
"baidu": "^https?://[^/]*\\.baidu\\.",
"other": (a: Element) => {
const href = (a as any).href as string;
if (href.startsWith("http")) return href;
}
});
console.log(href);
const count = await PuppeteerUtil.count(page, "#result_logo");
console.log(count);
const ids = await PuppeteerUtil.specifyIdByJquery(page, "a:visible:contains('登录')");
if (ids) {
console.log(ids);
await page.tap("#" + ids[0]);
}
}
}
通过 src/common/util/logger.ts 中定义的 logger.debug, logger.info, logger.warn, logger.error 方法输出日志
输出的日志中包含时间,等级,源文件位置这些额外信息
// 示例
// 设置输出格式
// logger.format = "yyyy-MM-dd HH:mm:ss.SSS [level] position message"
// 设置最低输出等级, 必须是 "debug", "info", "warn", "error" 中的一个
// logger.level = "info";
logger.debugValid && logger.debug("test debug");
logger.info("test info");
logger.warn("test warn");
logger.error("test error");
非注入代码可以直接在 IDEA 中调试
注入到网页中运行的js代码可以通过有界面模式下打开的 Chromium 进行调试
Chromium 界面可以在构造 PuppeteerWorkerFactory 时,参数的 headless = false开启;另外还需要设置 devtools = true ,这样可以让新打开的页面自动打开开发者工具面板,debugger 才会断点成功
Inject js debug example
import {Launcher, PuppeteerWorkerFactory} from "ppspider";
import {TestTask} from "./tasks/TestTask";
@Launcher({
workplace: __dirname + "/workplace",
tasks: [
TestTask
],
workerFactorys: [
new PuppeteerWorkerFactory({
headless: false,
devtools: true
})
]
})
class App {
}
然后在要调试的注入代码前加一行 debugger;
import {Job, OnStart, PuppeteerWorkerFactory} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnStart({
urls: "http://www.baidu.com",
workerFactory: PuppeteerWorkerFactory
})
async index(page: Page, job: Job) {
await page.goto(job.url());
const title = await page.evaluate(() => {
debugger;
const title = document.title;
console.log(title);
return title;
});
console.log(title);
}
}
使用浏览器打开 http://localhost:9000
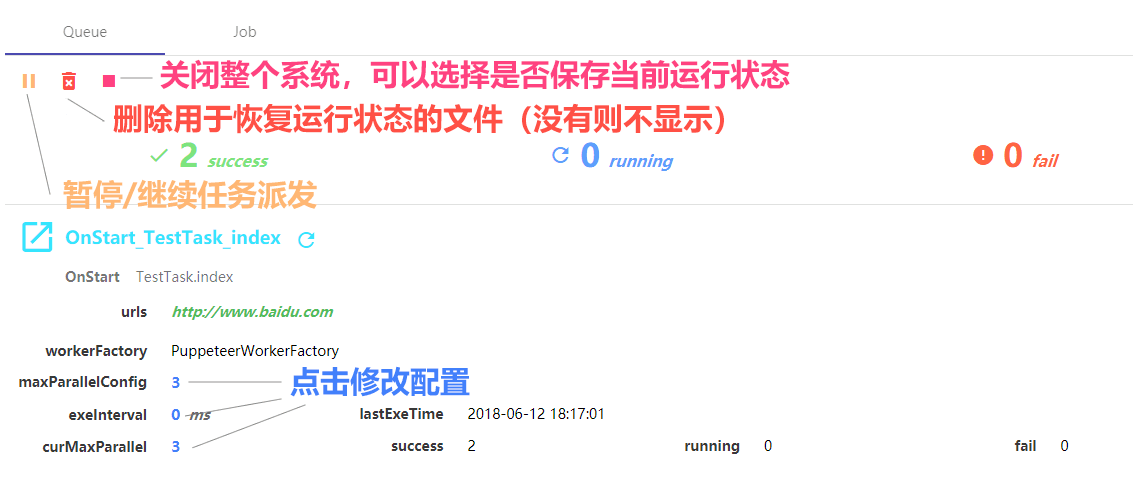
Queue 面板可以查看和管理整个系统中子任务的运行情况
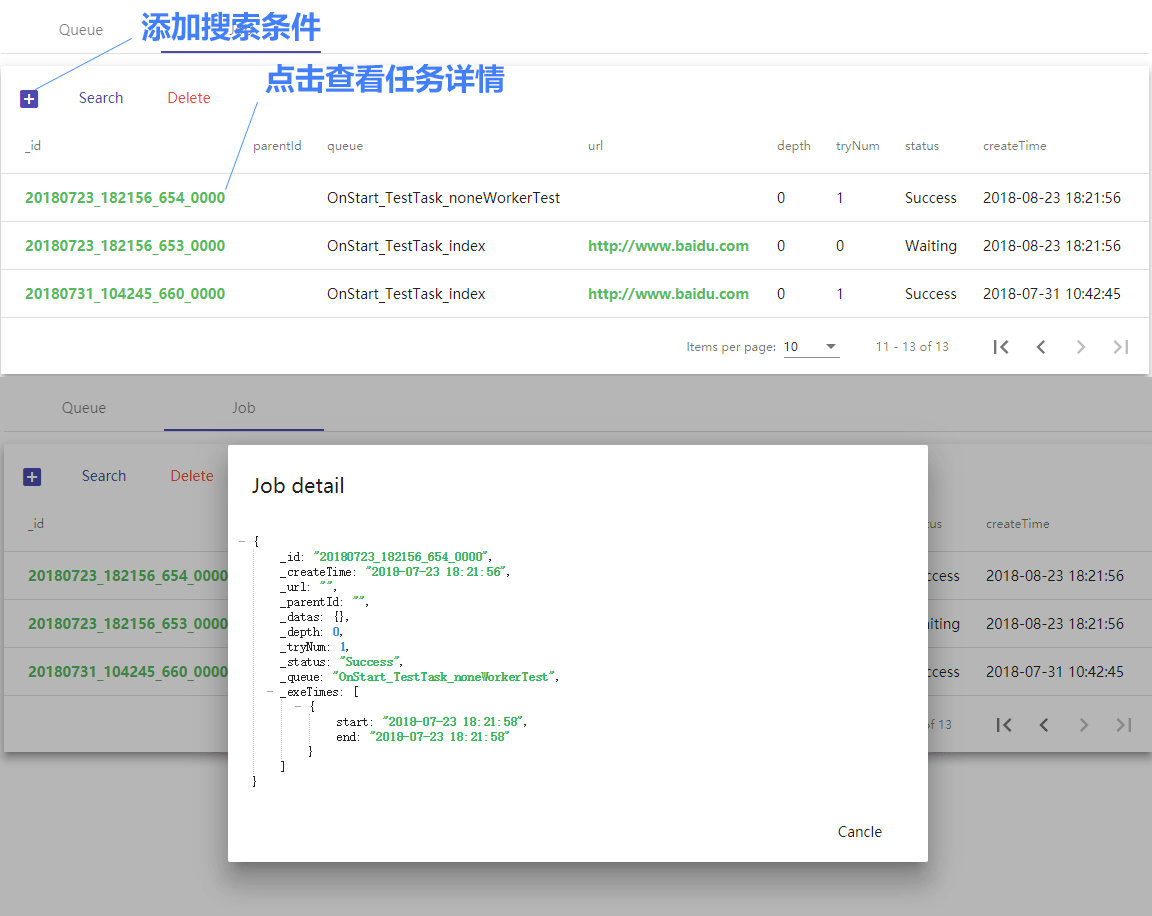
Job 面板可以对所有子任务实例进行搜索,查看任务详情
2018-09-19 v0.1.18
2018-08-24 v0.1.17
2018-07-31 v0.1.16
2018-07-30 v0.1.15
2018-07-27 v0.1.14
2018-07-24 v0.1.13
2018-07-23 v0.1.12
2018-07-19 v0.1.11
2018-07-16 v0.1.8
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





