![]()
![]()
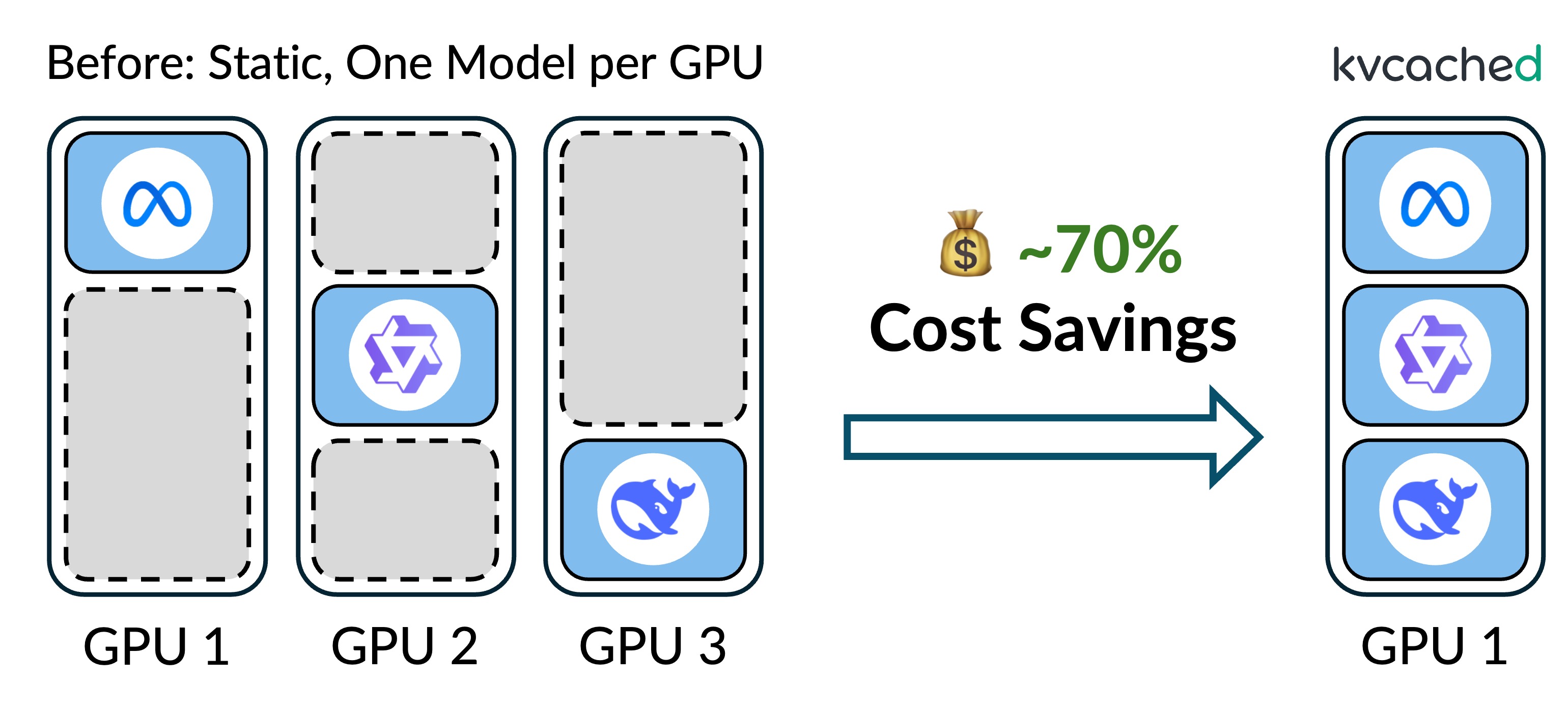

|
Multi‑LLM serving kvcached allows multiple LLMs to share a GPU's memory elastically, enabling concurrent deployment without the rigid memory partitioning used today. This improves GPU utilization and saves serving costs. |

|
Serverless LLM By allocating KV cache only when needed, kvcached supports serverless deployments where models can spin up and down on demand. |

|
Compound AI systems kvcached makes compound AI systems practical on limited hardware by elastically allocating memory across specialized models in a pipeline (e.g., retrieval, reasoning, and summarization). |

|
GPU workload colocation kvcached allows LLM inference to coexist with other GPU workloads such as training jobs, fine-tuning, or vision models. |