# llmaz
**Repository Path**: underdogs/llmaz
## Basic Information
- **Project Name**: llmaz
- **Description**: No description available
- **Primary Language**: Go
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-11-19
- **Last Updated**: 2025-11-19
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
Easy, advanced inference platform for large language models on Kubernetes
[](https://github.com/mkenney/software-guides/blob/master/STABILITY-BADGES.md#alpha)
[![GoReport Widget]][GoReport Status]
[](https://github.com/inftyai/llmaz/releases/latest)
[GoReport Widget]: https://goreportcard.com/badge/github.com/inftyai/llmaz
[GoReport Status]: https://goreportcard.com/report/github.com/inftyai/llmaz
**llmaz** (pronounced `/lima:z/`), aims to provide a **Production-Ready** inference platform for large language models on Kubernetes. It closely integrates with the state-of-the-art inference backends to bring the leading-edge researches to cloud.
> 🌱 llmaz is alpha now, so API may change before graduating to Beta.
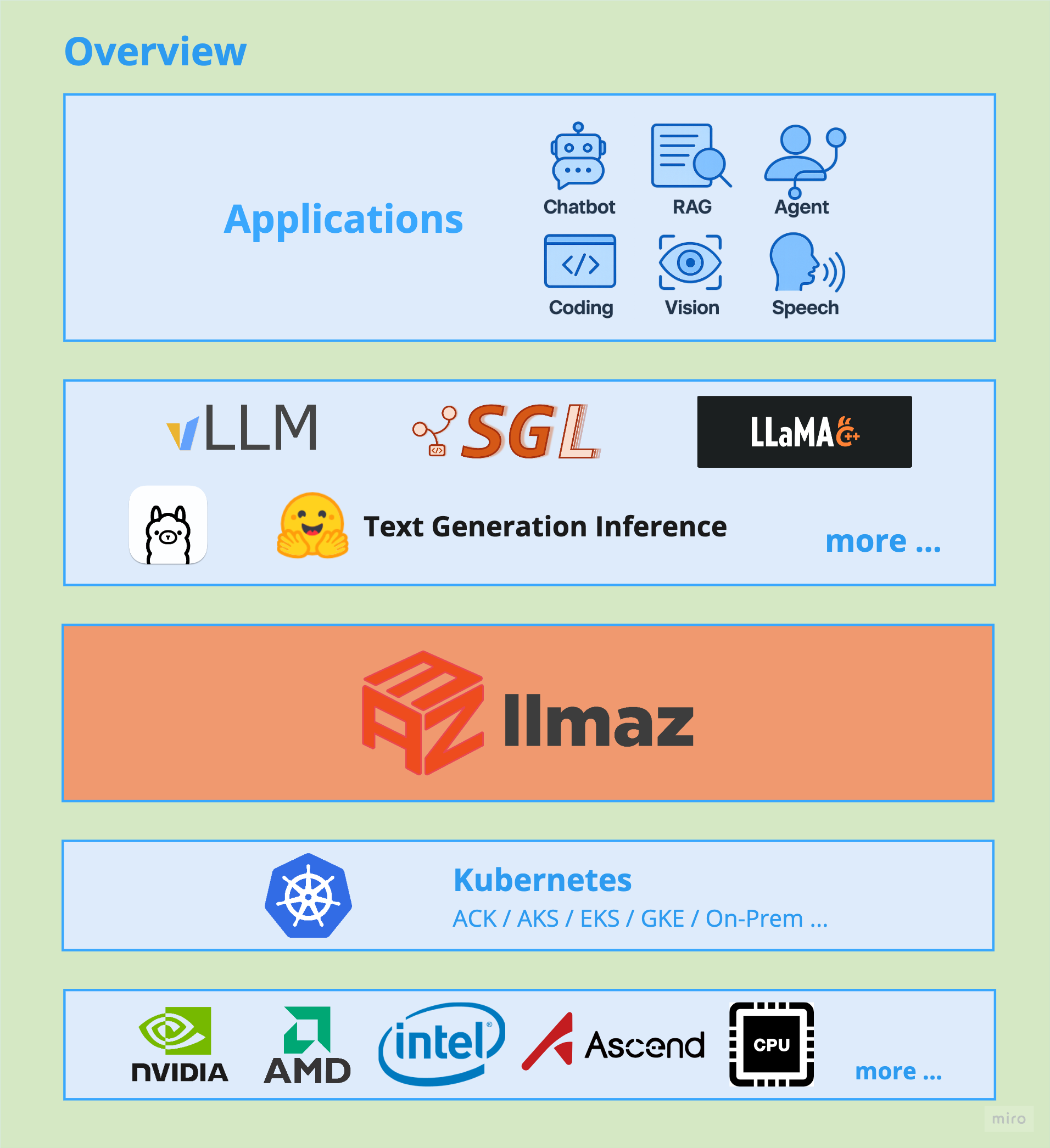
## Overview
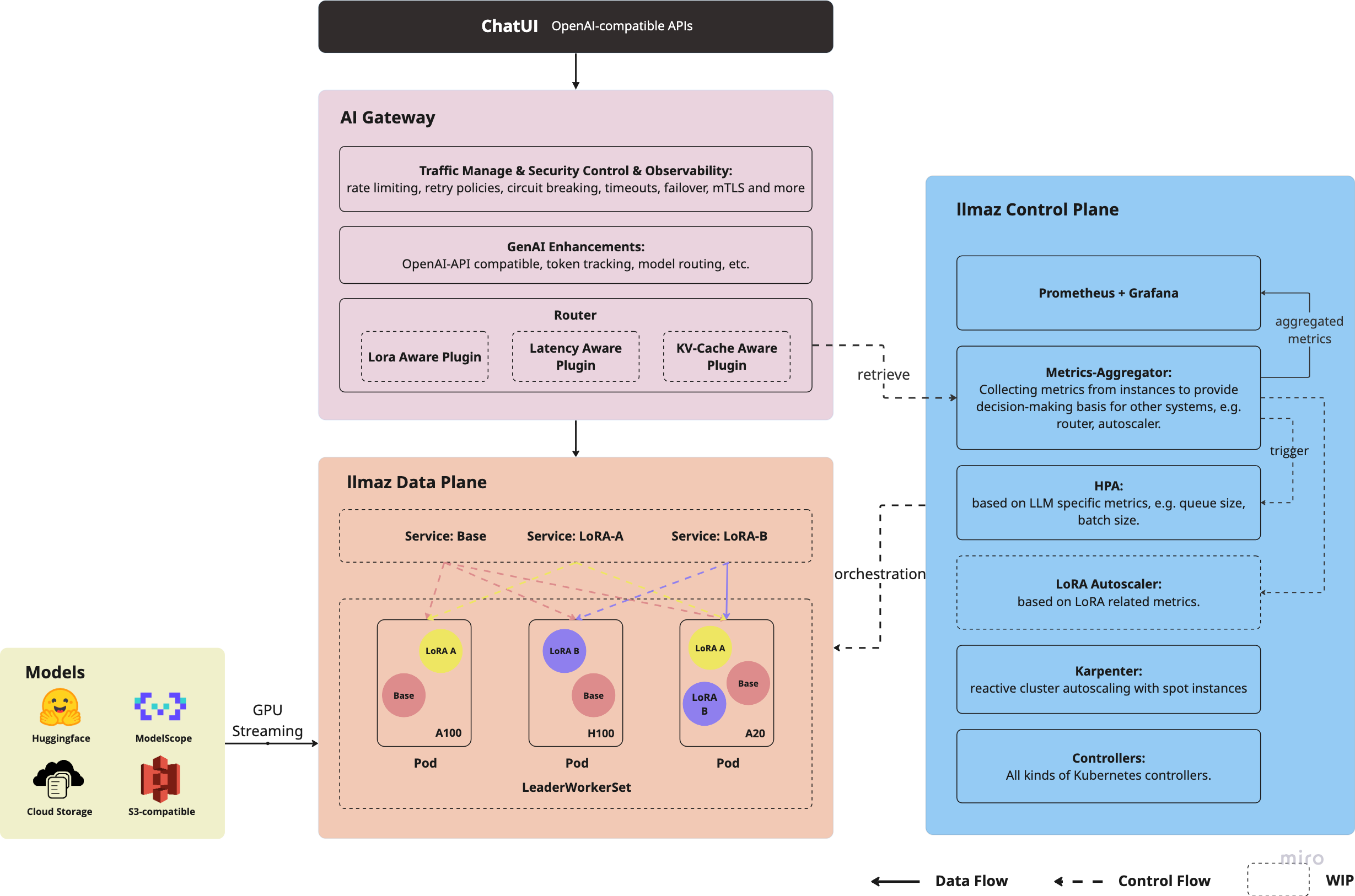
## Architecture
## Key Features
- **Easy of Use**: People can quick deploy a LLM service with minimal configurations.
- **Broad Backends Support**: llmaz supports a wide range of advanced inference backends for different scenarios, like [vLLM](https://github.com/vllm-project/vllm), [Text-Generation-Inference](https://github.com/huggingface/text-generation-inference), [SGLang](https://github.com/sgl-project/sglang), [llama.cpp](https://github.com/ggerganov/llama.cpp), [TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM). Find the full list of supported backends [here](./site/content/en/docs/integrations/support-backends.md).
- **Heterogeneous Cluster Support**: llmaz supports serving the same LLM with heterogeneous devices together with [InftyAI Scheduler](https://github.com/InftyAI/scheduler-plugins) for the sake of cost and performance.
- **Various Model Providers**: llmaz supports a wide range of model providers, such as [HuggingFace](https://huggingface.co/), [ModelScope](https://www.modelscope.cn), ObjectStores. llmaz will automatically handle the model loading, requiring no effort from users.
- **Distributed Inference**: Multi-host & homogeneous xPyD support with [LWS](https://github.com/kubernetes-sigs/lws) from day 0. Will implement the heterogeneous xPyD in the future.
- **AI Gateway Support**: Offering capabilities like token-based rate limiting, model routing with the integration of [Envoy AI Gateway](https://aigateway.envoyproxy.io/).
- **Scaling Efficiency**: Horizontal Pod scaling with [HPA](./docs/examples/hpa/README.md) with LLM-based metrics and node(spot instance) autoscaling with [Karpenter](https://github.com/kubernetes-sigs/karpenter).
- **Build-in ChatUI**: Out-of-the-box chatbot support with the integration of [Open WebUI](https://github.com/open-webui/open-webui), offering capacities like function call, RAG, web search and more, see configurations [here](./site/content/en/docs/integrations/open-webui.md).
## Quick Start
### Installation
Read the [Installation](./site/content/en/docs/getting-started/installation.md) for guidance.
### Deploy
Here's a toy example for deploying `facebook/opt-125m`, all you need to do
is to apply a `Model` and a `Playground`.
If you're running on CPUs, you can refer to [llama.cpp](/docs/examples/llamacpp/README.md).
> Note: if your model needs Huggingface token for weight downloads, please run `kubectl create secret generic modelhub-secret --from-literal=HF_TOKEN=` ahead.
#### Model
```yaml
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:
name: opt-125m
spec:
familyName: opt
source:
modelHub:
modelID: facebook/opt-125m
inferenceConfig:
flavors:
- name: default # Configure GPU type
limits:
nvidia.com/gpu: 1
```
#### Inference Playground
```yaml
apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:
name: opt-125m
spec:
replicas: 1
modelClaim:
modelName: opt-125m
```
### Verify
#### Expose the service
By default, llmaz will create a ClusterIP service named like `-lb` for load balancing.
```cmd
kubectl port-forward svc/opt-125m-lb 8080:8080
```
#### Get registered models
```cmd
curl http://localhost:8080/v1/models
```
#### Request a query
```cmd
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "opt-125m",
"prompt": "San Francisco is a",
"max_tokens": 10,
"temperature": 0
}'
```
### More than quick-start
Please refer to [examples](./docs/examples/README.md) for more tutorials or read [develop.md](./site/content/en/docs/develop.md) to learn more about the project.
## Roadmap
- Serverless support for cloud-agnostic users
- Prefill-Decode disaggregated serving
- KV cache offload support
- Model training, fine tuning in the long-term
## Community
Join us for more discussions:
- **Discord**: [#llmaz](https://discord.gg/UWnjUG6X8j)
- **Slack**: [#llmaz](https://join.slack.com/t/inftyai/shared_invite/zt-3700res2c-_AuBGD3kixDJhzycFE6L5A)
## Contributions
All kinds of contributions are welcomed ! Please following [CONTRIBUTING.md](./CONTRIBUTING.md).
We also have an official fundraising venue through [OpenCollective](https://opencollective.com/inftyai/projects/llmaz). We'll use the fund transparently to support the development, maintenance, and adoption of our project.
## Star History
[](https://www.star-history.com/#inftyai/llmaz&Date)