# cpp_load_onnx
**Repository Path**: xiaobai-zzy1/cpp_load_onnx
## Basic Information
- **Project Name**: cpp_load_onnx
- **Description**: onnxruntime部署onnx模型
使用C++分别在Linux和windows进行使用
Linux环境中使用vscode CPU
windows环境中使用vs2022 GPU
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-02-17
- **Last Updated**: 2025-03-05
## Categories & Tags
**Categories**: Uncategorized
**Tags**: Cpp
## README
onnx
[https://onnx.ai/](https://onnx.ai/)
[https://github.com/onnx/onnx](https://github.com/onnx/onnx)
ONNX 是一种开放格式,用于表示机器学习模型。ONNX 定义了一组通用运算符 —— 机器学习和深度学习模型的构建块 —— 和一种通用文件格式,使人工智能开发人员能够使用具有各种框架、工具、运行时和编译器的模型
onnxruntime
[https://onnxruntime.ai/](https://onnxruntime.ai/)
[https://github.com/microsoft/onnxruntime](https://github.com/microsoft/onnxruntime)
**ONNX Runtime**是一个跨平台的推理和训练机器学习加速器。onnxruntime 运行时推理可以实现更快的客户体验和更低的成本,支持来自深度学习框架的模型,如 PyTorch 和 TensorFlow/Keras 以及经典的机器学习库,如 scikit-learn、LightGBM、XGBoost 等。Oonnxruntime与不同的硬件、驱动程序和操作系统兼容,并通过在适用的情况下利用硬件加速器以及图形优化和转换来提供最佳性能。onnxruntime训练可以加快transformer模型的多节点 NVIDIA GPU 上的模型训练时间,并为现有的 PyTorch 训练脚本添加一行。
部署onnx(Linux)
wsl目前好像只能用CPU,所以在Linux部署onnx中使用的是CPU版本
Linux一般在嵌入式设备中,会配合使用TensorRT
**Linux环境**

wsl Ubuntu22.04
cmake version 3.31.5(onnx编译需要cmake版本高一些)[https://github.com/Kitware/CMake/releases/](https://github.com/Kitware/CMake/releases/)
vscode
1. git下载onnx项目(下载到自己安装软件的目录)
```cpp
git clone --recursive https://github.com/microsoft/onnxruntime
cd onnxruntime
```
使用git的原因是因为onnxruntime的构建脚本依赖于Git仓库和子模块同步
2. 编译
cpu版本
```cpp
# 构建并安装
./build.sh --config Release --build_shared_lib
```
编译时间较长,编译完后,在onnxruntime目录下会出现onnxruntime/build/Linux/Release
3. 安装
```cpp
cd onnxruntime/build/Linux/Release
sudo make install
```
将安装到系统默认的文件夹中
部署onnx 软件测试(Linux)CPU
可以先通过Python程序进行验证
Python
1. 环境配置
```python
conda create -n load_onnx_test python=3.10
conda activate load_onnx_test
pip install onnxtime numpy opencv-python
```
2. 测试程序(用通义生成了一段测试Resnet模型的代码,能正常运行不报错就行)
```python
import onnxruntime as ort
import cv2
import numpy as np
# 加载 ONNX 模型
session = ort.InferenceSession("resnet50.onnx")
# 准备输入数据
input_name = session.get_inputs()[0].name
# 读取图像文件
image_path = "./lion.jpg"
image = cv2.imread(image_path)
# 检查图像是否成功加载
if image is None:
raise ValueError("Could not open or find the image.")
# 预处理图像
# 1. 调整图像大小为模型输入大小(通常为 224x224)
image = cv2.resize(image, (224, 224))
# 2. 转换为浮点数并归一化
image = image.astype(np.float32) / 255.0
# 3. 转换为 RGB 格式(OpenCV 默认是 BGR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 4. 调整维度顺序为 (1, 3, 224, 224)
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, axis=0)
# 5. 转换为 ONNX Runtime 所需的格式
input_data = image
# 运行推理
result = session.run(None, {input_name: input_data})
# 输出结果
print(result)
```
C++
C++ 在编译安装好onnx的源码后,确认好自己的动态库与静态库位置,如果是默认位置一般都是
> "/usr/local/include/onnxruntime"
"/usr/local/lib"
>
注意需要安装opencv,直接使用apt安装
```bash
sudo apt update
sudo apt install libopencv-dev
```
使用vscode进行C++项目的配置.vscode/c_cpp_properties.json
```json
{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/**",
"/usr/include",
"/usr/include/opencv4",
"/usr/local/include/onnxruntime",
"/usr/local/lib"
],
"defines": [],
"compilerPath": "/usr/bin/g++",
"cStandard": "c11",
"cppStandard": "c++17",
"intelliSenseMode": "gcc-x64",
"browse": {
"path": [
"${workspaceFolder}",
"/usr/include",
"/usr/include/opencv4",
"/usr/local/include/onnxruntime",
"/usr/local/lib"
],
"limitSymbolsToIncludedHeaders": true,
"databaseFilename": ""
}
}
],
"version": 4
}
```
编写Makefile文件
```makefile
# 设置编译器
CXX = g++
# 设置编译选项
CXXFLAGS = -std=c++17 `pkg-config --cflags opencv4` -I /usr/local/include/onnxruntime
# 设置链接选项
LDFLAGS = `pkg-config --libs opencv4` -L /usr/local/lib -lonnxruntime -Wl,-rpath,/usr/local/lib
# 目标可执行文件
TARGET = helloOpenCV
SRCS = main.cpp
OBJS = $(SRCS:.cpp=.o)
all: $(TARGET)
$(TARGET): $(OBJS)
$(CXX) $(CXXFLAGS) -o $@ $^ $(LDFLAGS)
%.o: %.cpp
$(CXX) $(CXXFLAGS) -c $< -o $@
clean:
rm -f $(OBJS) $(TARGET)
```
其实使用rpath为了解决 `./helloOpenCV` 运行时找不到 `libonnxruntime.so.1` 库文件的问题
主函数主要实现的是Resnet进行图像分类的推理功能
需要的文件有,与main.cpp放在同一个文件夹下
image_classes.txt
resnet50.onnx (直接用pytorch提供的模型转化的)
lion.jpg等其他测试图片
```cpp
#include "onnxruntime_cxx_api.h"
#include "cpu_provider_factory.h"
#include
#include
// 加载标签文件获得分类标签
std::string labels_txt_file = "image_classes.txt";
std::vector readClassNames();
std::vector readClassNames()
{
std::vector classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
int main(int argc, char **argv)
{
// 预测的目标标签数
std::vector labels = readClassNames();
// 测试图片
cv::Mat image = cv::imread("cock.jpg");
cv::imshow("输入图", image);
// 初始化ONNXRuntime环境
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "ResNet-onnx");
// 设置会话选项
Ort::SessionOptions session_options;
// 优化器级别:基本的图优化级别
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
// 线程数:4
session_options.SetIntraOpNumThreads(4);
std::cout << "onnxruntime inference try to use COU Device" << std::endl;
// 检查返回值以确保执行提供程序成功添加
OrtStatus* status_cpu = OrtSessionOptionsAppendExecutionProvider_CPU(session_options, 1);
if (status_cpu != nullptr) {
Ort::ThrowOnError(status_cpu);
}
// onnx训练模型文件
std::string onnxpath = "resnet50.onnx";
const char* modelPath = onnxpath.c_str(); // 修改为 const char*
// 加载模型并创建会话
Ort::Session session_(env, modelPath, session_options); // 修改为 const char*
// 获取模型输入输出信息
int input_nodes_num = session_.GetInputCount(); // 输入节点输
int output_nodes_num = session_.GetOutputCount(); // 输出节点数
std::vector input_node_names; // 输入节点名称
std::vector output_node_names; // 输出节点名称
Ort::AllocatorWithDefaultOptions allocator;
// 输入图像尺寸
int input_h = 0;
int input_w = 0;
// 获取模型输入信息
for (int i = 0; i < input_nodes_num; i++)
{
// 获得输入节点的名称并存储
auto input_name = session_.GetInputNameAllocated(i, allocator);
input_node_names.push_back(input_name.get());
// 显示输入图像的形状
auto inputShapeInfo = session_.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
int ch = inputShapeInfo[1];
input_h = inputShapeInfo[2];
input_w = inputShapeInfo[3];
std::cout << "input format: " << ch << "x" << input_h << "x" << input_w << std::endl;
}
// 获取模型输出信息
int num = 0;
int nc = 0;
for (int i = 0; i < output_nodes_num; i++)
{
// 获得输出节点的名称并存储
auto output_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(output_name.get());
// 显示输出结果的形状
auto outShapeInfo = session_.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
num = outShapeInfo[0];
nc = outShapeInfo[1];
std::cout << "output format: " << num << "x" << nc << std::endl;
}
// 预处理输入数据
cv::Mat rgb, blob;
// 默认是BGR需要转化成RGB
cv::cvtColor(image, rgb, cv::COLOR_BGR2RGB);
// 对图像尺寸进行缩放
cv::resize(rgb, blob, cv::Size(input_w, input_h));
blob.convertTo(blob, CV_32F);
// 对图像进行标准化处理
blob = blob / 255.0; // 归一化
cv::subtract(blob, cv::Scalar(0.485, 0.456, 0.406), blob); // 减去均值
cv::divide(blob, cv::Scalar(0.229, 0.224, 0.225), blob); // 除以方差
// CHW-->NCHW 维度扩展
cv::Mat timg = cv::dnn::blobFromImage(blob);
std::cout << timg.size[0] << "x" << timg.size[1] << "x" << timg.size[2] << "x" << timg.size[3] << std::endl;
// 占用内存大小,后续计算是总像素*数据类型大小
size_t tpixels = input_h * input_w * 3;
std::array input_shape_info{1, 3, input_h, input_w};
// 准备数据输入
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
Ort::Value input_tensor_ = Ort::Value::CreateTensor(allocator_info, timg.ptr(), tpixels, input_shape_info.data(), input_shape_info.size());
// 模型输入输出所需数据(名称及其数量),模型只认这种类型的数组
const std::array inputNames = {input_node_names[0].c_str()};
const std::array outNames = {output_node_names[0].c_str()};
// 模型推理
std::vector ort_outputs;
try
{
ort_outputs = session_.Run(Ort::RunOptions{nullptr}, inputNames.data(), &input_tensor_, 1, outNames.data(), outNames.size());
}
catch (std::exception e)
{
std::cout << e.what() << std::endl;
}
// 1x5 获取输出数据并包装成一个cv::Mat对象,为了方便后处理
const float *pdata = ort_outputs[0].GetTensorMutableData();
cv::Mat prob(num, nc, CV_32F, (float *)pdata);
// 后处理推理结果
cv::Point maxL, minL; // 用于存储图像分类中的得分最小值索引和最大值索引(坐标)
double maxv, minv; // 用于存储图像分类中的得分最小值和最大值
cv::minMaxLoc(prob, &minv, &maxv, &minL, &maxL);
int max_index = maxL.x; // 获得最大值的索引,只有一行所以列坐标既为索引
std::cout << "label id: " << max_index << std::endl;
// 在测试图像上加上预测的分类标签
cv::putText(image, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("输入图像", image);
cv::waitKey(0);
// 释放资源
session_options.release();
session_.release();
return 0;
}
```
编译运行
```python
make
./helloOpenCV
```
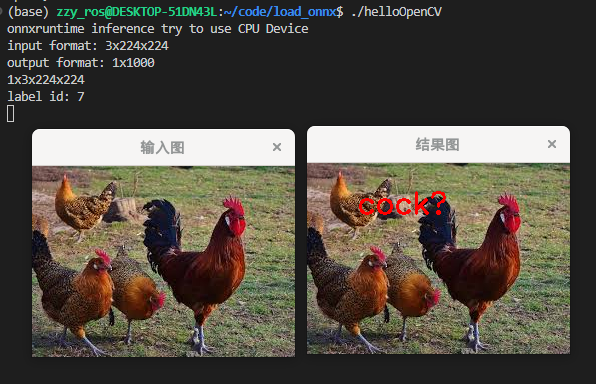
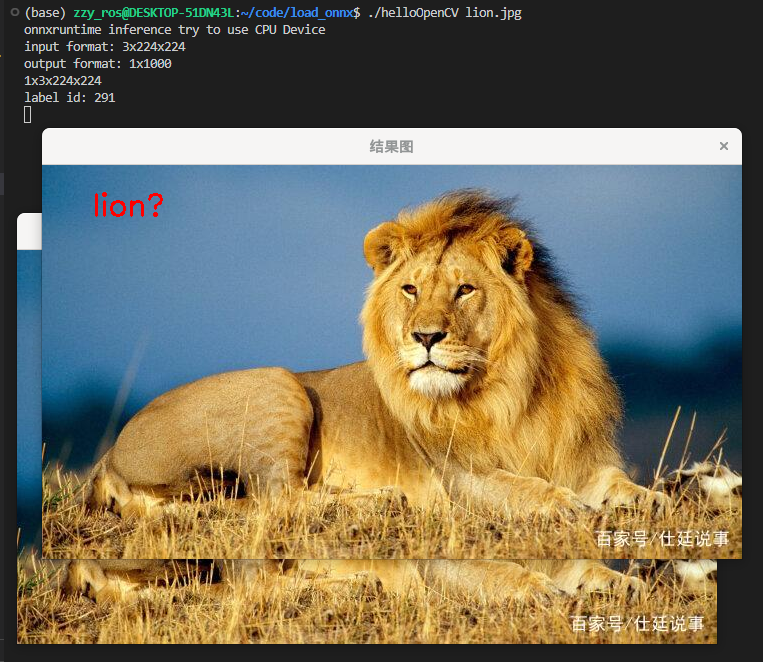
主要实现的是Resnet的onnx进行推理,实现图像分类功能
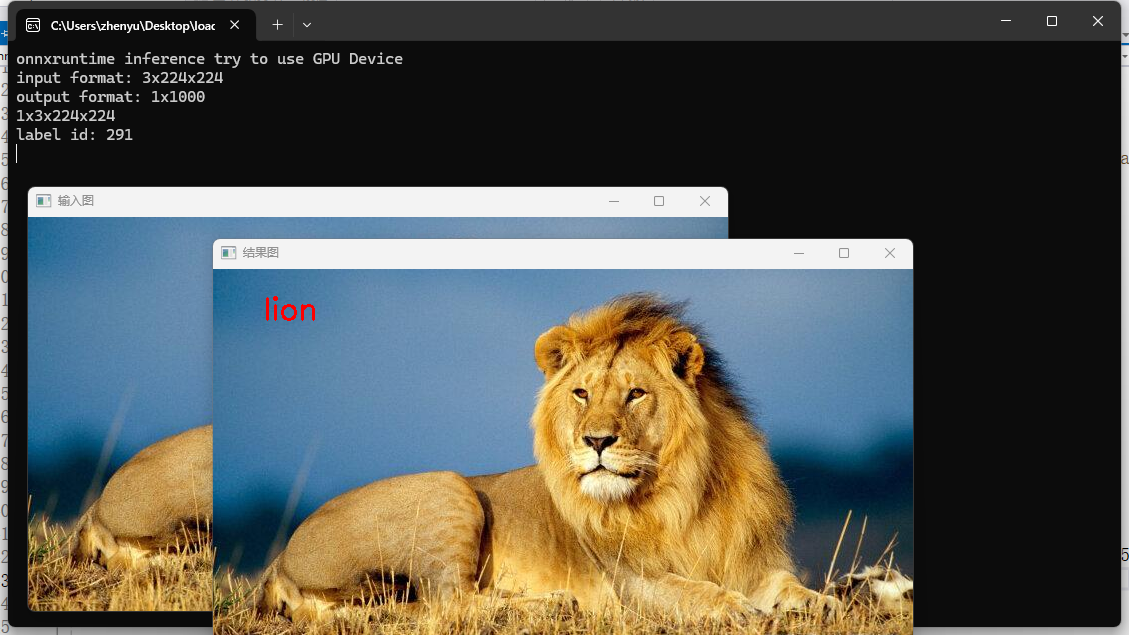
部署onnx(windows) GPU
window11
vs2022
opencv-4.10
[https://opencv.org/releases/](https://opencv.org/releases/)
直接点windows链接下载安装包,运行安装包,设置好安装目录安装即可
[https://github.com/microsoft/onnxruntime/tags](https://github.com/microsoft/onnxruntime/tags)
1. 下载onnxruntime-win-x64-gpu-1.xx.zip(需要什么版本下载对应的版本)
2. 下载放到软件安装的目录,解压,解压后应有include与lib目录
3. vs2022新建空项目
4. 添加源文件main.cpp **注意项目的设置属性与界面中的Release x64要保持一致**
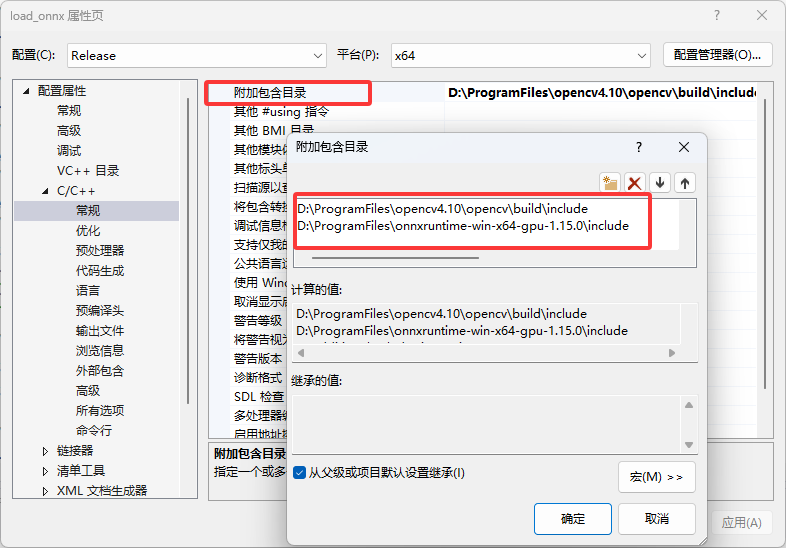
5. 设置链接库(调试->项目属性->c/c++->常规->附加包含目录)
1. 添加opnecv与onnxruntime的库目录 (注意自己的安装位置)
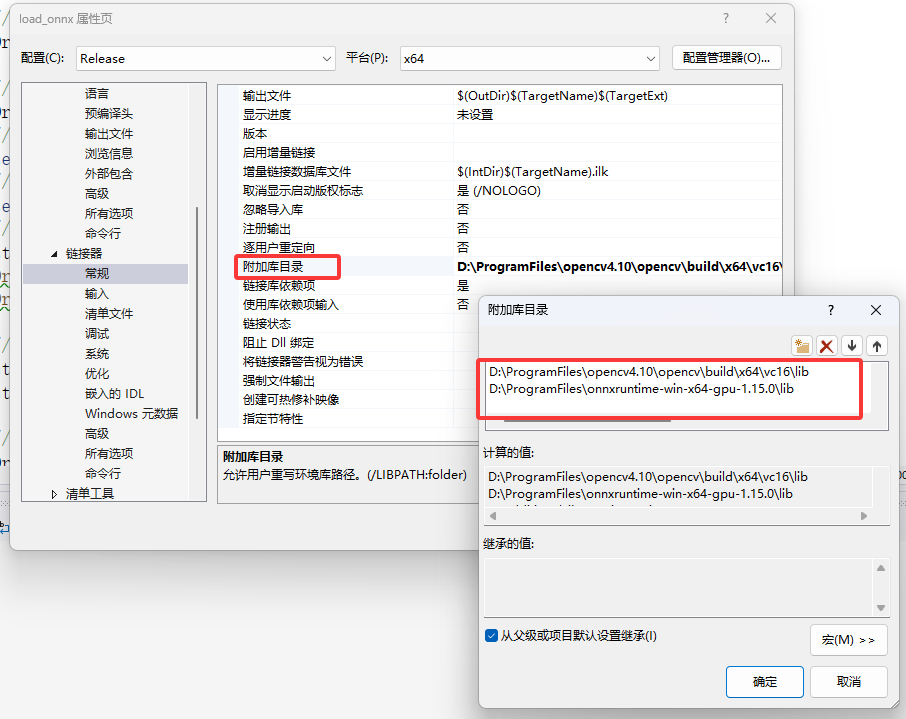
6. 添加依赖项(调试->项目属性->链接器->常规->附加库目录)
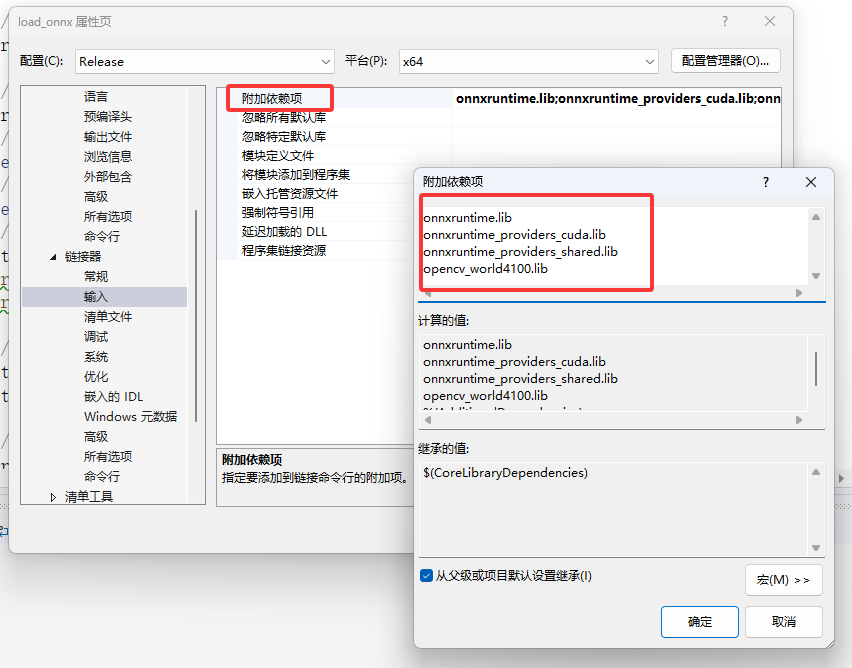
7. 添加依赖项(调试->项目属性->链接器->输入->附加依赖项)
8. 在Release x64模式下测试,将onnxruntime的onnxruntime.dll、onnxruntime_providers_cuda.dll和onnxruntime_providers_shared.dll,以及opencv的opencv_world4100.dll文件复制到自己项目的Release下。
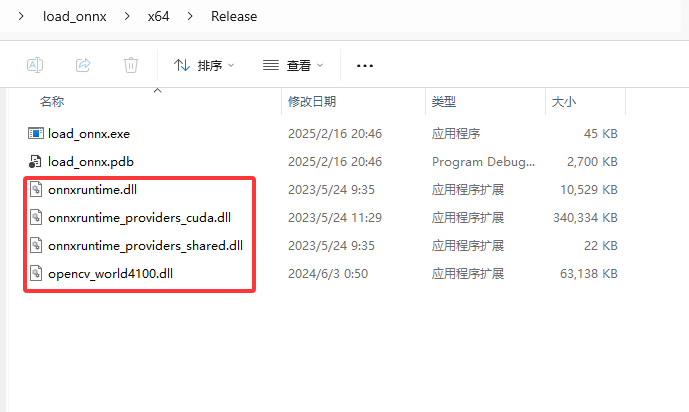
将测试文件都放在主目录下
image_classes.txt
resnet50.onnx (直接用pytorch提供的模型转化的)
lion.jpg等其他测试图片
```cpp
#include "onnxruntime_cxx_api.h"
#include "cpu_provider_factory.h"
#include
#include
// 加载标签文件获得分类标签
std::string labels_txt_file = "C:/Users/zhenyu/Desktop/load_onnx/image_classes.txt";
std::vector readClassNames();
std::vector readClassNames()
{
std::vector classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
int main(int argc, char** argv) {
// 预测的目标标签数
std::vector labels = readClassNames();
// 测试图片
cv::Mat image = cv::imread("C:/Users/zhenyu/Desktop/load_onnx/lion.jpg");
cv::imshow("输入图", image);
// 初始化ONNXRuntime环境
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "ResNet-onnx");
// 设置会话选项
Ort::SessionOptions session_options;
// 优化器级别:基本的图优化级别
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
// 线程数:4
session_options.SetIntraOpNumThreads(4);
// 设备使用优先使用GPU而是才是CPU
std::cout << "onnxruntime inference try to use GPU Device" << std::endl;
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
OrtSessionOptionsAppendExecutionProvider_CPU(session_options, 1);
// onnx训练模型文件
std::string onnxpath = "C:/Users/zhenyu/Desktop/load_onnx/resnet50.onnx";
std::wstring modelPath = std::wstring(onnxpath.begin(), onnxpath.end());
// 加载模型并创建会话
Ort::Session session_(env, modelPath.c_str(), session_options);
// 获取模型输入输出信息
int input_nodes_num = session_.GetInputCount(); // 输入节点输
int output_nodes_num = session_.GetOutputCount(); // 输出节点数
std::vector input_node_names; // 输入节点名称
std::vector output_node_names; // 输出节点名称
Ort::AllocatorWithDefaultOptions allocator;
// 输入图像尺寸
int input_h = 0;
int input_w = 0;
// 获取模型输入信息
for (int i = 0; i < input_nodes_num; i++) {
// 获得输入节点的名称并存储
auto input_name = session_.GetInputNameAllocated(i, allocator);
input_node_names.push_back(input_name.get());
// 显示输入图像的形状
auto inputShapeInfo = session_.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
int ch = inputShapeInfo[1];
input_h = inputShapeInfo[2];
input_w = inputShapeInfo[3];
std::cout << "input format: " << ch << "x" << input_h << "x" << input_w << std::endl;
}
// 获取模型输出信息
int num = 0;
int nc = 0;
for (int i = 0; i < output_nodes_num; i++) {
// 获得输出节点的名称并存储
auto output_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(output_name.get());
// 显示输出结果的形状
auto outShapeInfo = session_.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
num = outShapeInfo[0];
nc = outShapeInfo[1];
std::cout << "output format: " << num << "x" << nc << std::endl;
}
// 预处理输入数据
cv::Mat rgb, blob;
// 默认是BGR需要转化成RGB
cv::cvtColor(image, rgb, cv::COLOR_BGR2RGB);
// 对图像尺寸进行缩放
cv::resize(rgb, blob, cv::Size(input_w, input_h));
blob.convertTo(blob, CV_32F);
// 对图像进行标准化处理
blob = blob / 255.0; // 归一化
cv::subtract(blob, cv::Scalar(0.485, 0.456, 0.406), blob); // 减去均值
cv::divide(blob, cv::Scalar(0.229, 0.224, 0.225), blob); //除以方差
// CHW-->NCHW 维度扩展
cv::Mat timg = cv::dnn::blobFromImage(blob);
std::cout << timg.size[0] << "x" << timg.size[1] << "x" << timg.size[2] << "x" << timg.size[3] << std::endl;
// 占用内存大小,后续计算是总像素*数据类型大小
size_t tpixels = input_h * input_w * 3;
std::array input_shape_info{ 1, 3, input_h, input_w };
// 准备数据输入
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
Ort::Value input_tensor_ = Ort::Value::CreateTensor(allocator_info, timg.ptr(), tpixels, input_shape_info.data(), input_shape_info.size());
// 模型输入输出所需数据(名称及其数量),模型只认这种类型的数组
const std::array inputNames = { input_node_names[0].c_str() };
const std::array outNames = { output_node_names[0].c_str() };
// 模型推理
std::vector ort_outputs;
try {
ort_outputs = session_.Run(Ort::RunOptions{ nullptr }, inputNames.data(), &input_tensor_, 1, outNames.data(), outNames.size());
}
catch (std::exception e) {
std::cout << e.what() << std::endl;
}
// 1x5 获取输出数据并包装成一个cv::Mat对象,为了方便后处理
const float* pdata = ort_outputs[0].GetTensorMutableData();
cv::Mat prob(num, nc, CV_32F, (float*)pdata);
// 后处理推理结果
cv::Point maxL, minL; // 用于存储图像分类中的得分最小值索引和最大值索引(坐标)
double maxv, minv; // 用于存储图像分类中的得分最小值和最大值
cv::minMaxLoc(prob, &minv, &maxv, &minL, &maxL);
int max_index = maxL.x; // 获得最大值的索引,只有一行所以列坐标既为索引
std::cout << "label id: " << max_index << std::endl;
// 在测试图像上加上预测的分类标签
cv::putText(image, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("输入图像", image);
cv::waitKey(0);
// 释放资源
session_options.release();
session_.release();
return 0;
}
```
运行本地调试器得到结果