# experiment3
**Repository Path**: yang_zhong_man/experiment3
## Basic Information
- **Project Name**: experiment3
- **Description**: 实验三
- **Primary Language**: Java
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2020-05-17
- **Last Updated**: 2020-12-19
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
### 实验三 全球新型冠状病毒实时数据统计应用程序的设计与实现
| 实验名称 |
全球新型冠状病毒实时数据统计应用程序的设计与实现 |
实验序号 |
三 |
| 姓名 |
杨忠满 |
学号 |
201741404150 |
班级 |
17软件工程1班 |
| 实验地点 |
居家 |
实验日期 |
2020.5.5 |
指导老师 |
黎志雄 |
| 教师评语 |
|
实验成绩 |
评阅教师 |
| 百分制 |
|
| 同组同学 |
无 |
### 一、 实验目的
1、 掌握使用Spring框架自带的RestTemplate工具类爬取网络数据;
2、 掌握使用Spring框架自带的计划任务功能;
3、 掌握使用Apache Commons CSV组件解释CSV文件;
4、 掌握Java 8的Stream API处理集合类型数据;
5、 了解使用模板引擎或前端框架展示数据。
### 二、实验环境
1、 JDK 1.8或更高版本
2、 Maven 3.6+
3、 IntelliJ IDEA
4、 commons-csv 1.8+
### 三、 实验任务
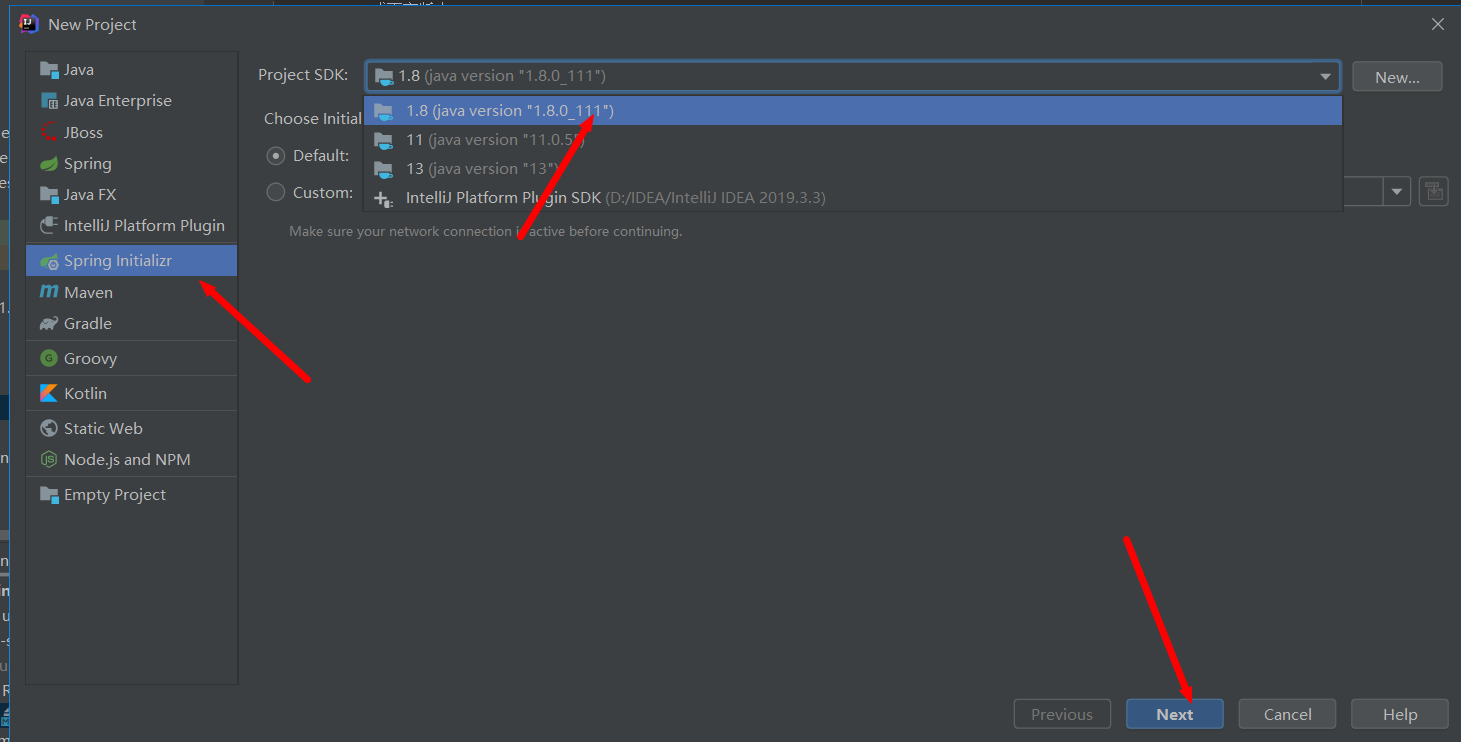
#### 1、 通过IntelliJ IDEA的Spring Initializr向导创建Spring Boot项目。
`步骤`:File->new->Project->Spring Initializr->next->填写信息->选择添加Spring Configuration Processor依赖->next,如下图所示:
#### 2、 添加功能模块:spring MVC、lombok、commons-csv等。
#### 3、 爬取全球冠状病毒实时统计数据。
```
在Github上,有一个由约翰·霍普金斯大学系统科学与工程中心(JHU CSSE)运营的2020年新型冠状病毒可视化仪表板的数据仓库,大家可以从该仓库中爬取全球新型冠状病毒最新的统计数据。
克隆到码云的gitee仓库地址:
https://gitee.com/dgut-sai/COVID-19
克隆到码云的gitee仓库的csv文件地址:
https://gitee.com/dgut-sai/COVID-19/blob/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv
```
#### 4、 使用Spring框架自带的RestTemplate工具类爬取数据。
RestTemplate采用同步方式执行 HTTP 请求的类,底层使用 JDK 原生 HttpURLConnection API ,或者 HttpComponents等其他 HTTP 客户端请求类库。
RestTemplate 工具类提供模板化的方法让开发者能更简单地发送 HTTP 请求。
RestTemplate 就是 Spring框架 封装的处理同步 HTTP 请求的工具类。
在本实验中,我们可以使用 RestTemplate 工具类获取上述的csv文件。
如果直接使用HTTP客户端请求Gitee上的文件,会报403的错误,但使用浏览器访问是正常的。经过分析,我们使用HTTP客户端请求Gitee上的文件时,需要设置一个请求头部User-Agent,否则会报403异常。
当我们使用 RestTemplate 工具类时,可以如下图所示设置请求头部并请求数据:
如上图所示,我们先实例化一个RequestEntity对象,再通过RestTemplate的exchange方法获取csv文件,这个文件的数据会封装到一个Resource对象中。我们可以通过Resource对象的getInputStream方法获取csv文件的输入流。
#### 5、分析csv文件的数据结构,定义model类。
#### 6、 使用Apache Commons CSV组件解释CSV文件。
> CSV文件是由任意数目的记录组成的,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。
CSV文件是以纯文本形式存储表格数据(数字和文本)。
为了方便应用程序处理,我们通常会把csv文件的每条记录转换为一个modle类的对象,即上一步中我们定义的model类。
把所有的model类的对象组织为一个集合,如:List 。最终,这个csv文件会转换为一个List对象。然后我们可以根据实际的业务逻辑,访问这个List即可。
我们可以定义一个Service组件处理csv文件的转换逻辑,并把最终转换后的List对象赋值给这个Service组件的成员属性,以便应用程序访问这个List对象。
#### 7、 使用Spring框架自带的计划任务功能定时更新统计数据。
要实现计划任务,首先通过在配置类上添加 @EnableScheduling 注解来开启对计划任务的支持,然后在要执行计划任务的方法上注解 @Scheduled,声明这是一个计划任务。
```
其中 @Scheduled 注解中有以下几个参数:
1. cron:cron表示式,指定任务在特定时间执行;
2. fixedDelay:表示上一次任务执行完成后多久再次执行,参数类型这long,单位ms;
3. fixedDelayString:与fixedDelay含义一样,只是参数类型变为String;
4. fixedRate:表示按一定的频率执行任务,参数类型为long,单位ms;
5. fixedRateString: 与fixedRate的含义一样,只是将参数类型变为String;
6. initialDelay:表示延迟多久后再第一次執行任務,参数类型为long,單位ms;
7. initialDelayString:与initialDelay的含义一样,只是参数类型变为String;
8. zone:时区,默认为当前时区,一般不需要设置。
```
注意:在Spring Boot应用程序中,Spring框架自带的计划任务默认是在单线程中执行的,这是因为Spring Boot在初始化计划任务线程池的时候,默认的线程池大小是 1 ,也就是说只有一个线程来执行所有计划任务,那么当有一个计划任务要耗费很长时间执行时,其它的计划任务即使到了执行时间点也只能继续等待。
我们可以通过属性文件设置计划任务线程池的大小,实现并行执行计划任务,如下图所示:
#### 8、 要确保应用程序启动时,获取一次统计数据。
#### 9、 单元测试。
所有控制器 与 Service 组件,必须写单元测试用例进行测试。
#### 10、 定义Cotroller控制器。
我们需要定义一个控制器,用于返回数据给前端展示。
控制器必须支持查询功能。如:可以选择查询某个地区或国家的新型冠状病毒实时统计数据。
#### 11、 定义前端数据展示页面。
展示页面:
查找结果: