

代码拉取完成,页面将自动刷新
记录自己从Java转Golang的一个简单历程,内含笔记及对应的demo,不做深入研究,仅作初始上手使用,有相应的代码demo。
做的比较简陋,有错误需要修改的地方烦请提出~
其实没啥好谈的,大学顺其自然学的Java,跟导师做项目也都是写的Java后台,就自然而然的写Java了,虽然也学了点c++,但是指针什么的真是太讨厌了(
至于为什么转Golang,因为秋招all in字节了,而且一直对go挺感兴趣,就去学了(
刚学下来的感觉是,Java真香。别问,问就是Java是世界上最好的语言(快逃.jpg
go是Google公司开发,09年正式对外公开的一门编译型编程语言,被人形容为是c和python的结合体,有c的运行速度 + 有python的快速开发。
拥有静态编译语言的安全和高性能,而且还达到了动态语言的开发速度和易维护性。
golang-learning
├─doc // 笔记 └─src └─main // 代码demo
Git仓库地址:https://gitee.com/yayako/go-learning.git
本来是想看尚硅谷韩顺平老师录制的教程,但是时代有点久远,所以选了最新的这个今年上传的教程,b站 @IT营 上传的视频 Golang教程_Go语言教程(此教程为2020年6月录制的Go教程)。
fmt.Println("hello wordld") // go中句末无需手动添加分号
fmt是go的打印包,相当于java中的System类,区别在于 fmt.Println("fmt", "支持多个入参")
| go | java |
|---|---|
| fmt.Println() | System.out.println() |
| fmt.Print() | System.out.print() |
| fmt.Printf() | System.out.printf() |
其中格式化输出函数 fmt.Printf() 对应的部分指令及其含义如下(摘自 Go语言的格式化输出中%d%T%v%b等的含义
| 格式化指令 | 含义 |
|---|---|
| %% | %字面量 |
| %b | 一个二进制整数,将一个整数格式转化为二进制的表达方式 |
| %c | 一个Unicode的字符 |
| %d | 十进制整数 |
| %o | 八进制整数 |
| %x | 小写的十六进制数值 |
| %X | 大写的十六进制数值 |
| %U | 一个Unicode表示法表示的整型码值 |
| %s | 输出以原生的UTF8字节表示的字符,如果console不支持utf8编码,则会乱码 |
| %t | 以true或者false的方式输出布尔值 |
| %v | 使用默认格式输出值,或者如果方法存在,则使用类性值的String()方法输出自定义值 |
| %T | 输出值的类型 |
通过 var 定义
// 声明初始值时数据类型可以省略,会自动推导 -> var a = 1
var a int = 1
// 未声明初始值时数据类型不可以省略,因为无法根据初始值来推导数据类型
var a // ×
var a int // ✔
通过 := 简短定义,只适用于局部变量,全局变量必须使用var来声明
a := 1 // 同样,数据类型会自动推导
需要注意的是,我们知道java只有全局变量即使没有赋予初始值也会在生命周期的准备阶段为其指定默认值,而在go中,即使未声明初始值,也会为其赋予默认值。
通过var声明多个变量
// 通过var在同行声明多个变量的方式限定了所有变量的数据类型必须一致
var a, b int
var a, b = 1, 2
// 该种方式内部的数据类型同样可以省略,且必须有初始值
var (
a int = 1
b string = "2"
)
通过简短定义
a, b := 5, "6"
写作 _,不占用命名空间,因为不会为其分配内存所以匿名变量之间不存在重复声明
假设有一个方法返回了两个结果(go中允许多返回值函数,暂不细谈),而我们只需要使用其中某些结果
// test为一个返回了两个结果的函数
func test(a int, b int) (int, int) {
return a + b, a - b
}
func main() {
// 此处,test函数返回的第二个结果是我们所不需要的,无需为其分配内存,因此可以使用匿名变量
a, _ := test()
_, b := test() // 匿名变量不存在重复声名
}
在idea中尝试输入const并按下回车键,idea会自动为你生成一个java中的常量
private static final int NUM = 235;
在go中的常量则是由 const 关键字定义,一旦赋值就不能改变
// 单常量定义
const k = 0
// 多常量定义,后续相同的可以省略
const (
x = 0 // 0
y = 1 // 1
z // 1
)
iota
go中存在一个常量计数器 iota ,只能在常量的表达式中使用
iota 在const关键字出现时将被重置为0,const中每新增一行常量声明,该值就会自增1,即进行一次计数,也可理解为const语句块中的行索引
const k0 = iota // 0
const (
k1 = iota // 0 —— 在const关键字出现时将被重置为0
k2 // 1 —— 每新增一行常量声明,iota自增
k3 // 2
)
const (
k4 = iota // 0
k5 = 1 // 1
k6 = iota // 2
)
const (
l1, l2 = iota, iota + 1 // 0 1
l3, l4 // 1 2
l5, l6 // 2 3
)
可以使用 unsafe 包下的 sizeof 函数来查看变量被分配的内存大小,单位为字节。
就像java中根据整形位数分为short、int、long一样,go中也进行了相应的分类,只不过命名比较直观—— int8、int16、int32、int64。
默认的 int 则根据操作系统字长来决定。比如我使用的是64位的os,那默认的 int 就是指代 int64 了。
零值为0。
var a0 int8
var a1 int16
var a2 int
fmt.Println(unsafe.Sizeof( /*int8(0)*/ a0)) // 1
fmt.Println(unsafe.Sizeof( /*int16(0)*/ a1)) // 2
fmt.Println(unsafe.Sizeof( /*int(0)*/ a2)) // 8
数字字面量语法,数字字面量语法,直接使用二进制、八进制或十六进制浮点数的格式定义数字
%d:10进制,%b:2进制,%o:8进制,%x:16进制
fmt.Printf("10进制 - %d\n", 17) // 17
fmt.Printf("0进制 - %b\n", 17) // 10001
fmt.Printf("8进制 - %o\n", 17) // 21
fmt.Printf("16进制 - %x\n", 17) // 11
同样的,java中的double、float对应go中的float32、float64,默认的取决于os字长。
零值为0。
小数的格式化输出
var pi = 3.1415926
// b = 3.1415926 -- 3.141593,保留两位小数后3.14
fmt.Printf("b = %v -- %f,保留两位小数后%.2f", b, b, b)
精度丢失问题与语言无关,本就是采用二进制来表示小数所必须面临的问题。
var f1 float64 = 8.2
var f2 float64 = 3.8
fmt.Printf("8.2 - 3.8 = %v\n", f1-f2) // 4.3999999999999995
java中采用Decimal类来避免,而在go中,也是通过第三方的decimal包来解决。后续学习第三方包的引入后再补充。
与java唯一的区别在于关键字为bool而不是boolean(
零值为false。
我们知道java中的String为引用类型,不属于基本数据类型,且其底层为char数组。而在go中,官方将string归属到基本数据类型(本质上还是一个结构体),底层是一个byte数组。
在看字符串前,先来看看go中的“字符”。
不如先看看编码方式(具体的字符编码方式之间的关系可以参考这篇博客:字符编码中ASCII、Unicode和UTF-8的区别)
而实际上,go中并没有专门的字符类型,但是可以通过 byte 、rune 两种方式来表示字符,前者通常用于表示单个字符(一个字节的长度范围内),后组合则通常用来表达字符串底层(占用四个字节)。
如果将汉字赋给byte类型,会造成溢出,相当于将int32赋给int8。
在go中,使用特殊的rune类型来处理unicode编码,可以让基于unicode的文本处理更为方便。
go的string都是由字节组成的。零值为空串 ""。
先看看底层实现(strings/strings.go
type stringStruct struct {
str unsafe.Pointer // 指向长度为len的byte数组
len int
}
普通的定义和上述几种数据类型没有什么差别。
不过在go中可以通过反引号 `` 实现多行字符串的定义,其中的反引号无法被转义
var c = `line1
line2`
fmt.Println(c)
// 打印结果:
// line1
// line2
关于字符串的操作(比较、包含、判断前后、查找下标等等),都可以参考strings.go中的函数。
go中有获取长度的 len(v type) 函数,但是该函数实际上是获取参数在内存中占用的字节数,而前面提到过:
str.length() 实际上获取到的就是内置char数组的长度所以,如果使用len函数来获取含有汉字的string的长度,将会造成错误。
e := "你好"
fmt.Println(len(e)) // 6
在go中,获取string长度有以下几种方式
先将string转化为rune数组,再通过len()函数获取rune数组的长度(有关 rune 请查看字符模块
runeE := []rune(e)
fmt.Println(len(runeE)) // 2
通过 bytes.Count(s, sep []byte) - 1 进行统计
fmt.Println(bytes.Count([]byte(e), nil) - 1) // 2
通过 strings.Count(s, substr string) - 1 进行统计
fmt.Println(strings.Count(e, "") - 1) // 2
通过 utf8.RuneCountInString(s string) - 1 进行统计
fmt.Println(utf8.RuneCountInString(e)) // 2
我们知道在java中,String是不可变的类(类被final修饰,value被final修饰),在go中也是一样,string是不可变的。
若想修改string的值就只能通过重新赋值或者通过rune数组作中间变量实现(有点类似java中的 new String(char[] value) ),因此每次修改都会重新分配内存并复制字节数组。
str := "你好,golang"
fmt.Println(str) // 你好,golang
runeStr := []rune(str) // [20320 22909 65292 103 111 108 97 110 103]
fmt.Println(runeStr)
runeStr[0] = '您'
fmt.Println(string(runeStr)) // 您好,golang
上述已知,go中的string底层是一个byte数组,因此如果直接类似使用java中的fori循环,势必出现错误
str := "你好,golang"
// 228-ä 189-½ 160- 229-å 165-¥ 189-½ 239-ï 188-¼ 140- 103-g 111-o 108-l 97-a 110-n 103-g
for i := 0; i < len(str); i++ {
fmt.Printf("%v-%c\t", str[i], str[i])
}
同样的,在go中,只要牵扯到对string的操作,多需借助rune类型。
// 20320-你 22909-好 65292-, 103-g 111-o 108-l 97-a 110-n 103-g
for _, v := range str { // 若需要使用下标 => for i, v := range str
fmt.Printf("%v-%c\t", v, v)
}
实际上,go中不存在隐式向上转型一说,必须手动显式向上转型(发出了我爱java的声音
var a0 int8
var a1 int16
// fmt.Println(a0 + a1) // × invalid operation: a0 + a1 (mismatched types int8 and int16)
fmt.Println(int16(a0) + a1) // ✔
其他基本数据类型之间的转换只要通过强制转换(括号 + 目标数据类型),而在go中则是使用函数的写法,例如上例的 int16() 。
(更多的格式参考源码中注释)
其他基本数据类型转string
通过 strconv 包的 format 函数
/*
- FormatInt
- 参数1:要转换的值
- 参数2:参数1的进制类型
*/
var str5 = strconv.FormatInt(int64(1), 10)
/*
FormatFloat
- 参数1:要转换的值
- 参数2:格式化类型 'f' (-ddd.dddd, no exponent),
- 参数3:保留的小数点 -1表示不对小数格式化
- 参数4:格式化的类型 32 64
*/
var str6 = strconv.FormatFloat(1.1, 'f', 4, 64)
通过 string() 函数 —— 注意,该函数只能将字符、rune数组、byte数组等转换为string
// a - string
fmt.Printf("%v - %T\n", string(97), string(97))
fmt.Printf("%v - %T\n", string(rune(97)), string(rune(97)))
通过 fmt.Sprintf() 函数
str1 := fmt.Sprintf("%d", 1)
fmt.Printf("值:%v,类型:%T\n", str1, str1) // 值:1,类型:string
str2 := fmt.Sprintf("%.2f", 2.2)
fmt.Printf("值:%v,类型:%T\n", str2, str2) // 值:2.20,类型:string
str3 := fmt.Sprintf("%t", false)
fmt.Printf("值:%v,类型:%T\n", str3, str3) // 值:false,类型:string
str4 := fmt.Sprintf("%c", 'a')
fmt.Printf("值:%v,类型:%T\n", str4, str4) // 值:a,类型:string
string转其他基本数据类型:通过 strconv 包的 parse 函数,返回结果为 (i int64, err error)
int0, _ := strconv.ParseInt("1",10,64)
fmt.Printf("值:%v,类型:%T\n", int0, int0)
float0,_ := strconv.ParseFloat("1.1",64)
fmt.Printf("值:%v,类型:%T\n", float0, float0)
int1, err := strconv.ParseInt("-",10,64)
fmt.Printf("值:%v,类型:%T\n", int1, int1)
fmt.Printf("值:%v,类型:%T\n", err, err)
数组,切片,结构体,函数,map,通道(channel),接口等,后续再详细看。
基本的算数运算符、关系运算符、逻辑运算符和赋值运算符(+=、-=、...)等等这些的用法没什么差别。
主要强调go中自增(++)自减(--)操作与Java的差别,以 i++ 为例,在go中
i++ 是单独的语句而不是运算符,无法返回 i 的值,即意味着 a = i++ 这种操作是不存在的++i 这种操作也是不存在的还有其他一些基本语法的差别
if-else 与 java 的唯一区别在于 go 中可以省略判断条件的括号,但是最好是加上
go中不存在while关键字,可以通过for实现
go中的goto——无条件跳转
通过标签进行代码间的无条件跳转,实现快速跳出循环、避免重复退出
n := 3
if n > 2 {
fmt.Print("跳转")
goto label
}
fmt.Println(1)
label:
fmt.Println(2)
go中的switch-case块
无需使用break来明确推出,也即意味着当其执行完一个case块后就算没有break也不会再继续往下寻找符合要求的分支来执行
case分支可以使用表达式,前提是switch后面没有判断变量
// 执行结果:1
tmp := 8
switch /* 此处无需添加判断变量*/ {
case tmp < 10:
fmt.Println(1)
case tmp < 20:
fmt.Println(2)
default:
fmt.Println(3)
}
有专为switch-case块使用的 fallthrough 关键字,用于“穿透”
该关键字可以执行满足条件的case的下一个case,是为了兼容c而设计的
// 执行结果:
// 2 case = true
// 3 case = false
// 4 case = true
switch {
case false:
fmt.Println("1 case = false")
fallthrough
case true:
fmt.Println("2 case = true")
fallthrough // 穿透
case false:
fmt.Println("3 case = false")
fallthrough
case true:
fmt.Println("4 case = true")
case false:
fmt.Println("5 case = false")
fallthrough
default:
fmt.Println("default")
}
几种初始化方式
var arr1 [3]int
var arr2 = [3]int{1, 2, 3}
arr3 := [3]int{1, 2, 3}
也可由编译器自行推断数组长度(多维数组只能推断第一层的长度
var arr4 = [...]int{1, 2, 3}
arr5 := [...]int{1, 2, 3}
也可以指定索引值进行初始化
arr6 := [...]int{0:1, 2:3}
数组的遍历则直接通过forrange即可,类似Java的foreach吧。
// 通过索引
for i := range arr {
fmt.Printf(arr[i] + " ")
}
// foreach
for _, s := range arr {
fmt.Printf(s + " ")
}
一个拥有相同类型元素的可变长度的序列,非常灵活,支持自动扩容。本质上就是对底层数组的封装,包含了底层数组的指针、切片的长度、切片的容量三个基本属性。
type slice struct {
array unsafe.Pointer // 数组指针
len int // 长度
cap int // 容量
}
未初始化的切片其默认值为空值 nil ,相当于Java中的null。
切片的普通定义方式与数组基本相同,区别在于无需定义长度
sliceObj := []int{0, 1, 2, 3, 4, 5}
基于已有数组、切片定义
var sliceObj = sli[1:2]
sliceObj := arr[:]
使用 make([]T, size, cap) 定义
sliceObj := make([]int, 2, 3)
使用 len() 获取长度,cap() 获取容量
如下例中
slices := []int{0, 1, 2, 3, 4, 5}
slice1 := slices[:] // [0 1 2 3 4 5] len = 6,cap = 6
slice2 := slices[1:] // [1 2 3 4 5] len = 5,cap = 5
slice3 := slices[1:3] // [1 2] len = 2,cap = 5
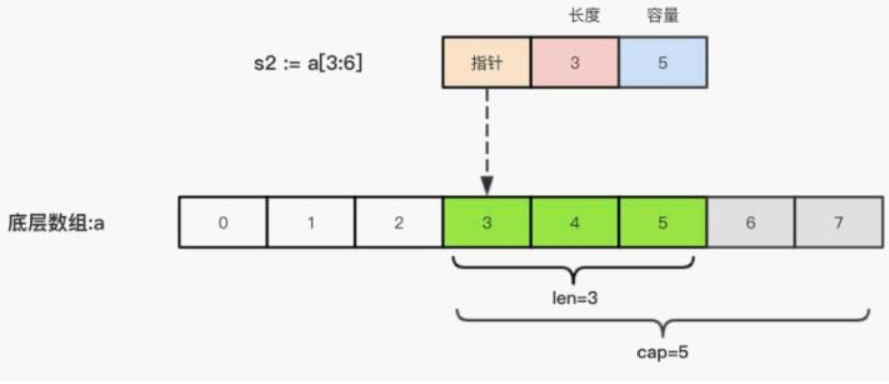
len的结果很容易理解,那为什么slice3的cap是5?
一方面要从slice的本质说起。前面说过,slice这个结构体分别由底层数组的指针、切片的长度、切片的容量三个属性组成,其与底层数组的结构如下图。
一方面要从容量本身说起,当我们通过一个make函数创建新的切牌你时,容量将由我么们手动指定。而当通过已有数组/切片重新定义新的切片时,该新切片的容量则会直接依赖于原数组/切片的长度。
func append(slice []Type, elems ...Type) []Type
用于添加元素、合并切片
sliceA := []int{0, 1}
// 添加元素
sliceA = append(sliceA, 2, 3) // 0 1 2 3
// 合并切片
sliceB := []int{4, 5}
sliceA = append(sliceA, sliceB...) // 0 1 2 3 4 5
另外,由于go中并没有删除切片元素的专用方法,因此也可以使用切片本身的特性并结合append来实现元素的删除,其实也就是把不要的丢了,把剩下的元素合并起来。。。有点无语。。。
sliceA = append(sliceA[:1], sliceA[2:]...) // 0 2 3 4 5
另外需要注意,当元素超过容量时slice会自动扩容,扩容机制如下,详见源码
func copy(dst, src []Type) int
使用copy可以实现数组/切片之间的复制,当长度不够时只复制部分元素。
sliceC := make([]int, 4, 5)
copy(sliceC, sliceA) // sliceC = [0 2 3 4]
数组、切片的排序可以直接调用go内置的 sort 包,相当于Java中的Arrays.sort()方法。
对于基本数据类型的数组和切片,可以直接调用sort包下对应的方法。
func Ints(a []int)
func Float64s(a []float64)
func Strings(a []string)
也可以先将待排序对象转换为sort内置 IntSlice 结构体,再调用 Sort方法
sort.Sort(sort.IntSlice(array)) // 等同于sort.Ints(array)
// 部分源码
type IntSlice []int
func (this IntSlice) Sort() { Sort(this) }
func Sort(data Interface) {
n := data.Len()
quickSort(data, 0, n, maxDepth(n))
}
如果是逆序排序的话就有点麻烦。。。不对,是恶心
sort.Sort(sort.Reverse(sort.IntSlice(array)))
一开始我以为 sort.Reverse 就能实现对象的逆序排序,没想到还得再在外面套一层Sort,百思不得其解,然后去看源码,源码分析到时候另写一篇再贴链接到这吧。
简单来说就是Reverse方法改写了这个IntSlice的Less方法(比较函数),而Sort方法在排序时调用了IntSlice的Less()方法,最终产生了逆序排序的效果。
sort包也支持自定义排序,只需要重写比较函数 less 即可。
func Slice(slice interface{}, less func(i, j int) bool)
使用自定义排序实现逆序排序
sort.Slice(array, func(i, j int) bool {
return array[i] < array[j]
})
自定义排序可以类比一下Java中的
public static <T> void sort(T[] a, Comparator<? super T> c)
public static <T> void sort(List<T> list, Comparator<? super T> c)
另外一点需要注意的是:==需要注意的是go中的数组是值类型,而切片则是引用类型。==
// 数组
arr1 := [...]int{1, 2, 3}
arr2 := arr1
arr1[0] = 4
fmt.Println("arr1 =", arr1) // 4 2 3
fmt.Println("arr2 =", arr2) // 1 2 3
// 切片
slice01 := []int{1, 2, 3}
slice02 := slice01
slice2[0] = 0
fmt.Println("slice01 =", slice01) // 1 2 3
fmt.Println("slice02 =", slice02) // 1 2 3
声明方式,初始化方式
mapA := make(map[int]int)
mapA[0] = 1
mapA[1] = 2
mapA[2] = 3
mapB := map[int]int{
1: 1, 2: 2, 3: 3, // 最后的“,”必须要添加,或者这样同行声明 mapB := map[int]int{1: 1, 2: 2, 3: 3}
}
// 定义值为slice的map
mapC := make(map[int][]int)
mapC[0] = []int{1, 2, 3}
value的获取,若key值不存在,第二个参数返回false,这点倒是比Java中的方便一些
val, ok := mapA[0]
map的删除
delete(mapA, 3)
map的遍历
// 只遍历key,Java中的
for k := range mapA {
// todo
}
// 同时遍历kv
for k, v := range mapA {
// todo
}
回忆一下Java中的迭代器,发现go中的forr(for range)还是很方便的
for (Integer integer : map.keySet()) {
// todo
}
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
int k = entry.getKey();
int v = entry.getValue();
// todo
}
碎碎念:回参和入参顺序跟java反着来一开始是真的难受
具体格式
func 函数名(入参) (返回结果) {
// TODO
}
普通的一个定义
func getTwoSum(a int, b int) int {
return a + b
}
可变参数
func getSum(a ...int) int {
sum := 0
for _, i := range a {
sum += i
}
return sum
}
**类型简写:**如果入参类型相同,可以简写入参的数据类型
func getSub(a /* int */, b int) int {
return a - b
}
支持多返回值
func getSumAndSub(a, b int) (int, int) {
return a + b, a - b
}
**返回值命名:**函数定义时可以给返回值名命,并在函数体中直接使用这些变量并return
func getMultiAndDiv(a int, b int) (multi, div int) {
multi = a * b
div = a / b
return multi, div
}
注意,如果在return时改变了命名返回值的顺序(如上例中修改为 return div, multi ),返回的值的顺序也会改变。
type calccalculate func(int, int) int
func calculate(a, b int, f calc /* 此处 calculate 等同于 func(int, int) int */) int {
return f(a, b)
}
func main() {
// 函数作为参数
fmt.Println(calculate(1, 1, getSub))
// 匿名函数作为参数
fmt.Println(calculate(1, 1, func(a int, b int) int {
return a + b - a*b/a
}))
// 函数作为回参
fmt.Println(calculate(1, 1, funcChoose("/")))
}
func funcChoose(s string) calc {
switch s {
case "+":
return getTwoSum
case "-":
return getSub
case "*": // 匿名函数作为返回结果
return func(a int, b int) int {
return a * b
}
case "/": // 匿名函数作为返回结果
return func(a int, b int) int {
return a / b
}
default:
return nil
}
}
go语言程序执行时会自动触发包内 init() 函数的调用,该函数无参数、返回值,在执行时自动被调用执行,不能在代码中被主动调用。
包内函数执行顺序:全局声明 -> init() -> main()
当导入多个包时,最后导入的包会最先初始化并调用其 init() 函数。
func init() {
fmt.Println("ex11:init")
}
func (实例名 实例类型) 方法名() {
// 方法体
}
假设有结构体Phone,该类结构体需要实现开机功能,实现如下
func (p Phone) start() {
fmt.Println(p.Name, "开机")
}
则可以通过Phone实例直接调用。
p := Phone{Name: "OPPO"}
p.start()
没有函数名的函数,无法像普通函数那样调用,所以匿名函数需要保存到某个变量(类似于Java中的interface)或者作为立即执行函数(匿名自执行函数)
基本格式
func(参数) (返回结果){
// 函数体
}
匿名自执行函数
// 匿名自执行函数
func(入参) {
// 函数体
}(参数)
自定义函数类型与自定义变量类型
type calc func(int, int) int
type myInt int
func main() {
var c1 calc = getTwoSum
fmt.Printf("自定义函数类型的类型:%T\n", c1) // 自定义的 main.calc 类型
c2 := getTwoSum
fmt.Printf("自定义函数的类型:%T\n", c2) // 推导得出的是function类型 func(int, int) int
var c3 myInt
fmt.Printf("自定义变量类型的类型:%T\n", c3) // main.myInt
}
可以理解为“定义在一个函数内部的函数”,本质上是将函数内部和函数外部连接起来的桥梁,或者说是函数和其引用环境的组合体。
**为什么需要闭包?**全局变量常驻内存但是污染全局,局部变量不污染全局但是不常驻内存,而闭包既可以让一个变量常驻内存,又不污染全局。
需要注意的是:闭包作用域返回的局部变量资源不会被立刻销毁回收,所以可能占用更多的内存,因此过多的使用闭包将会导致性能下降。
闭包的简单写法就是在函数中嵌套一个函数,最后返回里面的函数
type myFunc func() int
// 闭包
func add() myFunc {
i := 1 // 常驻内存,不污染全局
return func() int {
i++
return i
}
}
func main() {
fn := add() // 此处相当于执行了i:=1,并且i常驻内存,fn被赋值为函数 func() int {i++:return i},每一次调用fn(),都会执行一次i++和return i
fmt.Println(fn()) // 2
fmt.Println(fn()) // 3
fmt.Println(fn()) // 4
}
延迟关键字,会将修饰的代码段延迟执行,官方描述:
A "defer" statement invokes a function whose execution is deferred to the moment the surrounding function returns, either because the surrounding function executed a return statement, reached the end of its function body, or because the corresponding goroutine is panicking.
执行时机是 defer语句所在函数执行完毕时 ——函数执行return语句,或函数执行到末尾,或相关goroutine发生panic时。并且即使程序发生异常,也会执行。
举个简单的例子
func main() {
deferTest() // 开始 结束 3 2 1
}
func deferTest() {
fmt.Println("开始")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("结束")
}
也可以延迟匿名自执行函数
func main() {
deferTest() // 1开始 2结束 1开始 2结束 654321
}
func deferTest() {
fmt.Print("1开始 ")
defer fmt.Println(1)
defer fmt.Print(2)
defer fmt.Print(3)
fmt.Print(" 2结束 ")
// 也可以将延迟代码放到匿名函数中
fmt.Print("1开始 ")
defer func() {
defer fmt.Print(4)
defer fmt.Print(5)
defer fmt.Print(6)
}()
fmt.Print("2结束 ")
}
但需要注意, defer在命名返回值和匿名返回值中的表现是不一样的 ,如下例子中
func main() {
// - 匿名返回函数
// 控制台依次输出:1 0
fmt.Println(f1()) // ③ 打印输出返回的0
// - 命名返回值函数
// 控制台依次输出:1 1
fmt.Println(f2())
}
// 匿名返回值函数
func f1() int {
var a int
defer func() { // ② a自增为1,并输出
a++
fmt.Println("defer ", a)
}()
return a // ① 返回0
}
// 命名返回值函数
func f2() (a int) {
defer func() { // ②
a++
fmt.Println("defer ", a)
}()
return a // ①
}
匿名返回值函数的执行结果可以预见(执行顺序①②③),但是为什么命名返回值函数的执行结果会有所不同呢?
首先要知道 return的底层执行: 在go中,return并不是一个原子操作,而是分为 赋值 和 RET指令 两个操作,后者可以理解为是创建一个新的变量ret,并将我们return的值赋值给ret,再将ret返回。
而defer语句执行时机就在赋值之后,RET指令执行之前。
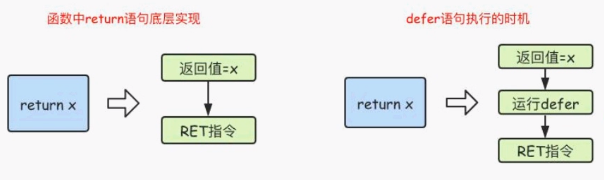
在匿名返回值函数中,相当于按如下顺序执行
而在命名返回值函数中,则是省去了创建ret变量的过程,因为 返回变量已经被指定并初始化为零值 了
这也是为什么命名返回值函数中无需在return之后带值的原因
另一点要注意的是: defer注册"要延迟执行的函数"时,这个函数所有的参数的值都需要预先被确定 。
这句话是什么意思呢?不如先查看如下例子:
func main() {
x := 1
y := 2
defer deferCalc("AA", x, deferCalc("A", x, y))
x = 10
defer deferCalc("BB", x, deferCalc("B", x, y))
y = 20
}
func deferCalc(index string, a, b int) int {
res := a + b
fmt.Println(index, a, b, res)
return res
}
执行结果如下
A 1 2 3
B 10 2 12
BB 10 12 22
AA 1 3 4
来分析一下执行顺序
当执行到第一个defer语句时,会进行函数AA的注册,所以需要预先确定函数AA的参数,此时 a = x = 1 已经确定,而b的值为 deferCalc("A", x, y) ,故需要先执行函数A,得到 b = deferCalc("A", x, y) = 3 。a、b由此确定下来,a = 1, b = 3,函数AA注册成功。
当执行到第二个defer语句时,同理会进行函数BB的注册,确定此时 a = x = 10, b = deferCalc("B", x, y) = 12 , 由此函数BB注册成功。
当函数AA、BB全部注册完毕,并且当前main函数执行完毕,会依次执行注册的defer函数BB、AA,依次输出4、22。
完整时间线整理如下:
顺序:注册AA -> 执行A -> 注册BB -> 执行B -> 执行BB -> 执行AA
x := 1
y := 2
注册AA // 注册时需要确定 x,deferCalc("A", x, y)) 的值
x = 1
执行A:deferCalc("A", x, y) => A 1 2 3
deferCalc("A", x, y) = 3
x = 10
注册BB // 注册时需要确定 x,deferCalc("B", x, y)) 的值
x = 10
执行B:deferCalc("B", x, y) => B 10 2 12
deferCalc("B", x, y) = 12
y = 20
执行BB:deferCalc("BB", x, deferCalc("B", x, y)) => BB 10 12 22
执行AA:deferCalc("AA", x, deferCalc("A", x, y)) => AA 1 3 4
还记得java中有try-catch-finally块,不论程序是否执行成功,最终都会执行finally块的语句,而我们主要在这一块写的,就是相关资源的释放,例如锁的释放、连接的释放。
而defer也是主要起这一个主要的作用——在函数执行完毕后,及时地释放资源。
go中目前没有异常处理机制,但是可以通过panic-cover模式来处理错误
func panicTest() {
/*
panic: *** panic ***
goroutine 1 [running]:
main.panicTest(...)
golang-learning/src/main/ex7.go:79
main.main()
golang-learning/src/main/ex7.go:74 +0x585
*/
fmt.Println("before panic")
panic("*** panic ***")
fmt.Println("after panic")
}
类比一下java的throw机制,区别在于java还需要在函数定义时抛出异常,并且这块代码编译就过不去。
public static void main(String[] args) throws Exception {
System.out.println("before throwing");
throw new Exception("*** throw ***");
System.out.println("after throwing"); // java: 无法访问的语句
}
func recoverTest(a, b int) {
defer func() {
// recover接收异常,只能在defer调用函数中有效
err := recover()
if err != nil {
fmt.Println("error:", err)
}
}()
fmt.Println(a / b)
}
我们取 b = 0,查看执行结果
error: runtime error: integer divide by zero
异常成功接收,并且没有停止当前程序的运行。
类比Java的try-catch,Java的异常体系更加的庞大复杂,而在go中则无需关心异常的类型,更加简介的同时也受限于此的感觉吧。
void test(int a, int b) {
try {
System.out.println(a / b);
} catch (Exception e) {
System.out.println(e);
}
}
不如模拟一个写入文件操作,且要求改写异常提示,如果文件不存在则提示”打开文件失败“,如果写入文件失败,则提示”写入文件失败“。
func write2Txt(path string) {
file, err := os.OpenFile(path, os.O_WRONLY, 666)
defer func() { // finally
file.Close()
myErr := recover() // catch
if myErr != nil {
fmt.Println("error: ", myErr)
}
}()
if err != nil {
panic("打开文件失败")
}
_, err = file.WriteString("直接写入字符串\r\n")
if err != nil {
panic("写入文件失败")
}
}
import "time"
用于获取当前时间的函数,返回了结构体 Time ,还可以进一步获取当前年月日时分秒。
time.Now().Year()
time.Now().Month()
time.Now().Day()
time.Now().Hour()
time.Now().Minute()
time.Now().Second()
Time 还提供了格式化方法
但是需要注意go语言的格式化时间模板不是常见的Y-m-d H:M:S,而是go诞生时间**(2006-01-02 15:04:05 -> 2006 1 2 3 4 5)**
timeTmp := time.Now()
// 使用format格式化
formatDate1 := timeTmp.Format("2006-01-02 03:04:05") // 使用 03 表示采取12小时制
fmt.Println(formatDate1) // 2020-11-04 01:09:32
formatDate2 := timeTmp.Format("2006/01/02 15:04:05") // 使用 15 表示采取24小时制
fmt.Println(formatDate2) // 2020/11/04 13:09:32
日期字符串转时间
timeStr := "2021-01-29 18:06:53"
// Local represents the system's local time zone. 代表系统本地时区
timeTmp, _ = time.ParseInLocation("2006-01-02 15:04:05", timeStr, time.Local)
结果
日期字符串[2021-01-29 18:06:53] 转 时间[2021-01-29 18:06:53 +0800 CST]
通过 Unix 函数获取时间戳
timeStamp := time.Now().Unix()
时间戳转日期
// 参数1:秒时间戳,参数2:纳秒时间戳。不需要的设为默认值0即可
t := time.Unix(timeStamp, 0) // 返回结构体Time
timeStamp := time.Now().Unix()
timeStr := t.Format("2006-01-02 15:04:05")
结果
时间戳[1611914813] 转 时间[2021-01-29 18:06:53]
time包中定义了许多常量,可以直接使用
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
以及定义了一些时间操作函数
// 时间加法
func (t Time) Add(d Duration) Time
// 时间减法
func (t Time) Sub(u Time) Duration
// 从t以来经过的时间
// 类似于time.Now().Sub(t).
func Since(t Time) Duration
// 直到t所需的时间
// 类似于t.Sub(time.Now()).
func Until(t Time) Duration
// 将时间加上所给年月日并返回
func (t Time) AddDate(years int, months int, days int) Time
以 Add 为例
timeTmp = timeTmp.Add(time.Hour) // 2021-01-29 18:06:53 + 1h
fmt.Println(timeTmp.Format("2006-01-02 15:04:05"))
输出结果 2021-01-29 19:06:53
time.NewTicker(d Duration) 创建一个定时器,d 代表时间间隔,定时器的需要通过 for range 执行,任务执行完毕后调取 Stop 终止定时器。
需要注意的是,终止定时器后,还需通过 break 跳出该 for range 循环,否则会引发死锁。
// 定义一个定时器,5秒内每隔一秒打印一次当前时间
ticker := time.NewTicker(time.Second)
n := 5
for t := range ticker.C {
n--
fmt.Println(t)
if n == 0 {
ticker.Stop() // 终止定时器
// 若此处不写break退出定时任务语句,会发生死锁:
// fatal error: all goroutines are asleep - deadlock!
//
// goroutine 1 [chan receive]:
// main.main()
// golang-learning/src/main/ex8.go:71 +0x869
break
}
}
time.Sleep(time.Second * 3)
本科是有学c++和Java两门课的,最终走上了Java的路,一方面是大环境,另一方面就是那时候觉得指针很烦,而Java正好没有指针。没想到转到了go后还是要重新捡起来。
普通的变量对应了自己内存地址,而指针是一种特殊的变量,对应了另一个变量的内存地址。
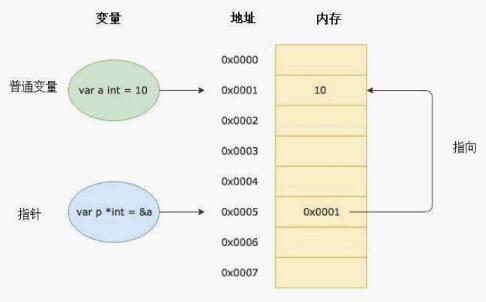
谈到指针离不开谈 &、* 两个符号,前者用于取地址,而后者则是指针运算符,可以标识指针类型,也可以表示一个指针变量所指向的存储单元。
以该结构体为例
type Test struct {
a int
b int
}
以下代码,分别以两种方式创建出了普通变量 t1 和指针变量 t2 ,将其分别赋值给 tt1 和 tt2 后再分别改变原来的a值,最后打印出 tt1 和 tt2 的现值查看区别。
/* 普通变量 */
var t1 Test = Test{a: 0, b: 0}
// t1 值:{0 0},类型:main.Test,地址:0xc00000a0c0
fmt.Printf("t1 值:%v,类型:%T,地址:%this\n", t1, t1, &t1)
tt1 := t1
// tt1 值:{0 0},类型:main.Test,地址:0xc00000a0f0
fmt.Printf("tt1 值:%v,类型:%T,地址:%this\n", tt1, tt1, &tt1)
t1.a = 1 // 修改原t1中a的值
fmt.Println(t1) // {1 0}
fmt.Println(tt1) // {0 0} 发现此处tt1的a值并没有改变
/* 指针变量 */
var t2 *Test = &Test{a: 0, b: 0}
// t2 值:&{0 0},类型:*main.Test,地址:0xc000006048,指向地址:0xc00000a140
fmt.Printf("t2 值:%v,类型:%T,地址:%this,指向地址:%this\n", t2, t2, &t2, t2)
tt2 := t2
// tt2 值:&{0 0},类型:*main.Test,地址:0xc000006050,指向地址:0xc00000a140
fmt.Printf("tt2 值:%v,类型:%T,地址:%this,指向地址:%this\n", tt2, tt2, &tt2, tt2)
t2.a = 1 // 修改原t2中a的值
fmt.Println(t2) // &{1 0}
fmt.Println(tt2) // &{1 0} 发现此处tt2的a值也发生了改变
控制台中我们会发现普通变量 t1 赋值给 tt1 后两者在内存中分配的地址并不相同,而指针变量 t2 与 tt2 则还是指向同一个存储单元。
内存分配情况大致如下:
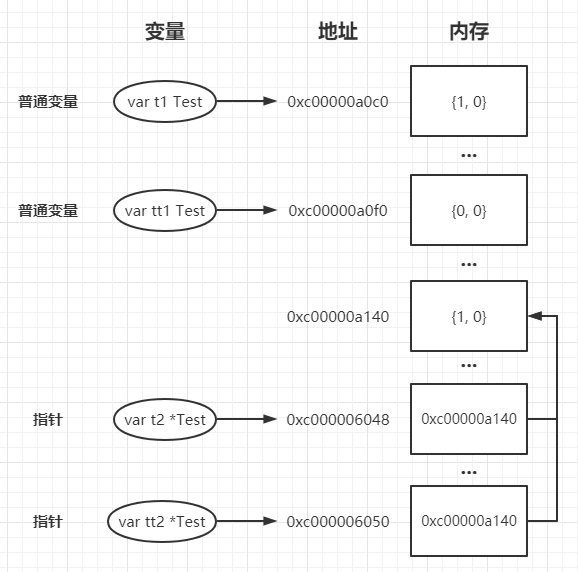
**值类型:**直接存储数据,在声明时就会默认为其分配内存空间。go中的数组、基本数据类型、结构体都是值类型变量。
**引用类型:**持有数据的引用,在使用时不仅需要声明,还需要手动为其分配内存空间。go中的slice、map、channel都是引用类型变量。(Java中除了基本数据类型外,所有变量都是引用型变量。
用数组和slice举个与上述相同的例子,会发现效果一致。
/* 数组 */
arr1 := [...]int{1, 2, 3}
// arr1 值:[1 2 3],类型:[3]int,地址:0xc000012380
fmt.Printf("arr1 值:%v,类型:%T,地址:%this\n", arr1, arr1, &arr1)
arr2 := arr1
// arr1 值:[1 2 3],类型:[3]int,地址:0xc0000123e0
fmt.Printf("arr1 值:%v,类型:%T,地址:%this\n", arr2, arr2, &arr2)
arr1[0] = 4
fmt.Println("arr1 =", arr1) // [4 2 3]
fmt.Println("arr2 =", arr2) // [1 2 3]
/* 切片 */
slice01 := []int{1, 2, 3}
// slice01 值:[1 2 3],类型:[]int,地址:0xc0000044a0,指向地址:0xc000012480
fmt.Printf("slice01 值:%v,类型:%T,地址:%this,指向地址:%this\n", slice01, slice01, &slice01, slice01)
slice02 := slice01
// slice02 值:[1 2 3],类型:[]int,地址:0xc000004520,指向地址:0xc000012480
fmt.Printf("slice02 值:%v,类型:%T,地址:%this,指向地址:%this\n", slice02, slice02, &slice02, slice02)
slice02[0] = 0
fmt.Println("slice01 =", slice01) // [0 2 3]
fmt.Println("slice02 =", slice02) // [0 2 3]
func new(Type) *Type
内建函数new,分配内存,第一个实参为类型。其返回值为指向该类型的新分配的零值的指针。
使用 new 创建一个指针类型的数组进行上面的实验
t := new(Test)
tt := t
// t 值:&{0 0},类型:*main.Test,地址:0xc000006048,指向的地址:0xc00000a1f0
fmt.Printf("t 值:%v,类型:%T,地址:%this,指向的地址:%this\n", t, t, &t, t)
// tt 值:&{0 0},类型:*main.Test,地址:0xc000006050,指向的地址:0xc00000a1f0
fmt.Printf("tt 值:%v,类型:%T,地址:%this,指向的地址:%this\n", tt, tt, &tt, tt)
func make(Type, size IntegerType) Type
内建函数make,分配并初始化一个类型为slice、map、或channel的对象,第一个实参为类型。make的返回类型与其参数相同,而不是指向它的指针。
type StructName struct {
// 属性
}
几个点:
结构名和字段名首字母大小写同样意味着访问权限,大写表示共有,小写表示当前包私有。
定义结构体时允许成员字段没有字段名,这些字段称为匿名字段,且类型必须唯一,其他包也无法访问匿名字段。
type Nameless struct {
string
int
*Address
}
type Address struct {
Country string
City string
}
匿名字段使用
n := Nameless{
string: "",
Address: &Address{
Country: "",
City: "",
},
}
n.int = 1
n.Address = &Address{}
假设有结构体如下
type Person struct {
Name string
Age int
Addr Address
}
type Address struct {
Country string
City string
}
几种实例化/初始化方式
var p = new(Person)
var p *Person
var p = &Person{}
p := &Person{}
// 也可以简化初始,属性名称要么都写,要么都省略
var p = &Person{
/* Name: */ "李四",
/* age: */ 18,
&Address{
Country: "中国",
},
}
在go中支持对结构体指针直接使用 . 来访问结构体成员,例如 p.name 在底层实际上是 (*p).name 。
另外,当访问结构体成员时,会先在结构体中查找该字段,找不到再去匿名结构中查找,如果多个嵌套结构体内都包含相同的字段,则会报错 ambiguous selector 。
// 以下两行代码是同一效果
p1.City = "浙江"
p1.Address.City = "浙江"
最后一点需要注意的是,结构体是值类型。
在Java中,想要将实例json序列化通常需要使用第三方包的方法,例如阿里的fastjson。而在go中则只需要使用tag进行标记,再通过自由的json包序列化/反序列化即可。
不过需要注意私有字段不会被序列化。
如下结构体,定义了json tag做序列化时的kv映射
type Student struct {
ID int `json:"id"` // 定义tag做json的kv映射
Person `json:"person"` // 继承Person类
}
序列化示例,主要是 Marshal 方法
s := &Student{
ID: 0,
Person: Person{
Name: "小红",
age: 22,
Address: &Address{},
},
}
// 1. 将结构体转换为byte数组
jsonByte, _ := json.Marshal(s)
// 2. byte数组转json字符串
jsonStr := string(jsonByte) // {"id":0,"person":{"Name":"小红","Country":"","City":""}}
反序列化示例,主要是 Unmarshal 方法
var s *Student
err := json.Unmarshal([]byte(jsonStr), &s) // &main.Student{ID:0, Person:main.Person{Name:"小红", age:22, Address:(*main.Address)(0xc000004600)}}
在go中,没有类的概念,但是可以给类型(结构体、自定义类型)定义方法 —— 定义了接收者的函数。接收者就类似java中的this。
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
// 方法体
}
以Person为例
func (this *Person) SetInfo(name string, age int) {
this.Name = name
this.age = age
}
使用
p.SetInfo("哈哈", 22)
go中继承的实现挺令人无语的,通过嵌套实现
假设有Person的子类Student,则Student的结构体需要将Person设为自己的属性
type Student struct {
ID
Person // 继承Person类
}
由此创建的Student实例即可调用Person的方法
结构定义
type 接口名 interface {
// 接口内容
}
现定义一个usb接口、Phone结构体如下。
type Phone struct {
Name string
}
type Usber interface {
charge()
transport()
InnerInterface // 内嵌接口
}
type InnerInterface interface {
fix()
}
接口必须实现接口必须实现接口内的所有方法
func (p *Phone) transport() {
fmt.Println(p.Name, "修理")
}
func (p *Phone) charge() {
fmt.Println(p.Name, "充电")
}
func (p *Phone) fix() {
fmt.Println(p.Name, "修理")
}
实现所有方法之后就可以使用
创建接口实例的两种方式
var u = Usber(&Phone{Name: "OPPO"})
var u Usber = &Camera{Name: "Casio"}
写法的区别仅在于接口实现方法的接收者是值类型还是指针类型
值类型实例 和 指针类型实例 都可以赋值给 值类型接收者 的接口变量——如果结构体中的方法是值接收者(Camera实现的方法),那么实例化后的结构体值类型和结构体指针类型都可以赋值给接口变量(u2和u3)。
func (c Camera) charge() {
fmt.Println(c.Name, "充电")
}
func main() {
var u2 Usber = Camera{Name: "Casio"}
var u3 Usber = &Camera{Name: "Sony"}
}
只能将实例化后的 结构体指针类型 赋值给 指针类型接收者 的接口变量——如果结构体中的方法是指针接收者,那么实例化后结构体指针类型可以赋值给接口变量,结构体值类型无法赋值。
func (p *Phone) charge() {
fmt.Println(p.Name, "充电")
}
func main() {
var u1 Usber = &Phone{Name: "VIVO"}
}
没有任何约束的接口,任何类型变量都可以实现空接口,是go中类似Java中Object的存在。
type Object interface{}
以该方法为例
func show(o interface{}) {
fmt.Printf("值:%v,类型:%T\n", o, o) // 1 int
}
依次调用
show(1) // 值:1,类型:int
show("1") // 值:1,类型:string
show(1.1) // 值:1.1,类型:float64
show(true) // 值:true,类型:bool
同理可用于map、slice等结构
userinfo := make(map[string]interface{})
userinfo["name"] = "张三"
userinfo["age"] = 22
userinfo["hobby"] = []string{"吃饭", "睡觉", "打豆豆"}
userinfo["phone"] = Phone{Name: "oppo"}
但是空接口类型不支持索引、自定义类型,不过可以通过类型断言转换
用于判断空接口中值的类型
格式如下,返回转换后的变量和布尔值
x.(T) // 源数据.(目标类型)
举个简单的例子
var b interface{}
b = "你好,golang"
v, ok := b.(string)
if ok {
fmt.Println("a是一个string类型的值 ——", v)
} else {
fmt.Println("a不是一个string类型的值")
}
// a是一个string类型的值 —— 你好,golang
再以上面的map为例
// fmt.Println(userinfo["hobby"][1]) ✖ type interface {} does not support indexing
// fmt.Println(userinfo["phone"].Name) ✖ type interface {} is interface with no methods
fmt.Println(userinfo["hobby"].([]string)[0])
fmt.Println(userinfo["phone"].(Phone).Name)
用户级线程,对内核透明,系统并不知道有协程的存在,完全由自己的程序进行调度。
在一个golang程序的主线程上可以起多个协程,golang中多协程可以实现并发或者并行。
当主线程执行完毕后即使协程没有执行完毕,程序也会退出。
golang的一大特色:从语言层面原生支持协程,goroutine就是其表现形式。
goroutine默认占用内存远比线程少,os线程一般都有固定的栈内存(2mb左右),而一个goroutine占用内存非常小(2kb左右)。另一方面,多协程goroutine切换调度的开销远比线程调度要小。
使用goroutine的方式很简单,直接在需要另起协程执行的方法前加上 go 关键字即可,以及,为了防止在协程因主线程停止而被动停止,需要使用协程计数器来保证“通讯”。相关操作实现都在sync包中。
一个简单的使用goroutine的例子:
// 协程计数主要由sync中的WaitGroup结构体实现
var wg sync.WaitGroup
func main() {
wg.Add(1) // 协程计数器 +1
go goroutineTest() // 开启一个协程
wg.Wait() // 等待协程执行完毕
fmt.Println("main 退出")
}
func goroutineTest() {
defer wg.Done()
// 方法体
}
其中 wg.Done() 源码如下,实际上就是计数器-1。
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
假设在协程执行的方法中出现了异常,则需要使用 defer+recover来捕获处理
但必须要注意执行 wg.Done() ,和Java的finally一定要释放锁是同一个道理。
var wg sync.WaitGroup
func main() {
wg.Add(2)
go errFunc()
go healthyFunc()
wg.Wait()
}
func errFunc() {
defer func() {
if err := recover(); err != nil {
fmt.Println("【errFunc】执行失败,异常已捕获")
}
wg.Done()
}()
// 一段有问题的代码
var myMap map[int]int
myMap[0] = 0
}
func healthyFunc() {
defer wg.Done()
time.Sleep(time.Millisecond * 50)
fmt.Println("【healthyFunc】执行成功")
}
控制台输出结果
【errFunc】执行失败,异常已捕获
【healthyFunc】执行成功
channel(管道)是语言级别上提供的goroutine间的通讯方式,可以在多个goroutine之间传递消息,是一种通信机制。
go语言的并发模型是CSP(Conmunicating Sequential Process),提倡通过通信共享内存而不是通过共享内存实现通信。
channel在go中是一种特殊的类型,且是引用类型,遵循fifo的规则,保证收发数据的顺序,每一个管道都是一个具体类型的导管,声明时需要为其指定元素类型。
通过 chan 关键字声明,通过 make 函数初始化
make(chan 元素类型, 容量)
通过 <- 读取/写入数据
channel := make(chan int, 2)
channel <- 1
channel <- 2
// channel <- 3 // 超出容量 -> 管道阻塞 all goroutines are asleep - deadlock!
// 值:0xc00010a000,类型:chan int,容量:3,长度:2
fmt.Printf("值:%v,类型:%T,容量:%v,长度:%v\n", channel, channel, cap(channel), len(channel))
a := <-channel
fmt.Println(a) // 1
fmt.Println(<-channel) // 2
// fmt.Println(<- channel) // 超取 -> 管道阻塞 all goroutines are asleep - deadlock!
通过 for 遍历读取
for i := 0; i < 2; i++ {
fmt.Println(<-channel)
}
但需要注意的是,如果通过 for range 遍历读取,则在遍历之前必须关闭通道,否则会出现死锁问题
close(channel) // 关闭管道
for v := range channel {
fmt.Println(v)
}
channel默认情况下是双向管道,可读可写,只写或只读的管道称为单向管道。
单向管道只需要在初始化时声明类型即可
// 只写管道 —— chan<-
wch := make(chan<- int, 2)
// 只读管道 —— <-chan
rch := make(<-chan int, 2)
下面结合goroutine和channel实现并行读写
var wg sync.WaitGroup
func main() {
ch := make(chan int, 10)
wg.Add(2)
go write(ch)
go read(ch)
wg.Wait()
}
func write(ch chan int /* 可使用单向管道(只写):ch chan<- int */) {
for i := 0; i < 10; i++ {
ch <- i
fmt.Printf("【写入】%v\n", i)
time.Sleep(time.Millisecond * 50)
}
// 写完记得关闭
close(ch)
wg.Done()
}
func read(ch chan int /* 可使用单向管道(只读):ch <-chan int */) {
for v := range ch {
fmt.Printf("【读取】%v\n", v)
time.Sleep(time.Millisecond * 50)
}
wg.Done()
}
控制台输出结果
【写入】0
【读取】0
【写入】1
【读取】1
【写入】2
【读取】2
【写入】3
【读取】3
【写入】4
【读取】4
【写入】5
【读取】5
【写入】6
【读取】6
【写入】7
【读取】7
【写入】8
【读取】8
【写入】9
【读取】9
当我们需要同时从多个channel接收数据时,可以选择开启多个协程来完成,但这种方式的运行性能会差很多,可以进一步使用 select-case 来实现多路复用。
每个case对应一个channel的通信过程,select会一直等待,直到某个case的通信操作完成时,就会执行case分支内的语句。
假设有两个channel,分别写入了int和float64,现在要通过select实现同时从两个channel中读取数据:
func main() {
// 写入数据
intChan := make(chan int, 5)
floatChan := make(chan float64, 5)
for i := 0; i < 5; i++ {
intChan <- i
floatChan <- float64(i) + 0.1
}
// 使用select来获取channel中的数据时无需关闭channel
for {
select {
case v := <-intChan:
fmt.Printf("【intChan】%v\n", v)
time.Sleep(time.Millisecond * 50)
case v := <-floatChan:
fmt.Printf("【floatChan】%v\n", v)
time.Sleep(time.Millisecond * 50)
default:
fmt.Println("【over】")
break
}
}
}
控制台输出结果
【floatChan】0.1
【floatChan】1.1
【intChan】0
【intChan】1
【floatChan】2.1
【intChan】2
【intChan】3
【floatChan】3.1
【floatChan】4.1
【intChan】4
【over】
同样的,sync包中还提供了多种锁组件,如互斥锁、读写锁等。
以下是一个简单的互斥锁的实践,通过互斥锁保证共享资源 count 在并发情况下的的递增。
var wg sync.WaitGroup
var mutex sync.Mutex
var count int
func main() {
for i := 0; i < 20; i++ {
wg.Add(1)
go mutexTest()
}
go wg.Wait()
}
func mutexTest() {
mutex.Lock() // 上锁
count++
fmt.Println("count =", count)
wg.Done()
mutex.Unlock() // 解锁
}
go的runtime包中提供了多种对环境变量的操作,例如获取cpu核数
cpuNum := runtime.NumCPU() // 相当于java中的 Runtime.getRuntime().availableProcessors()
fmt.Println("cpu数量", cpuNum) // 12
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





