
 |
|  |
|----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------|
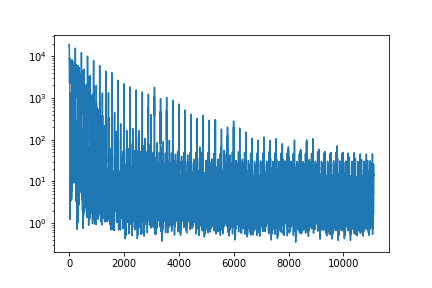
### Training Loss
|
|----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------|
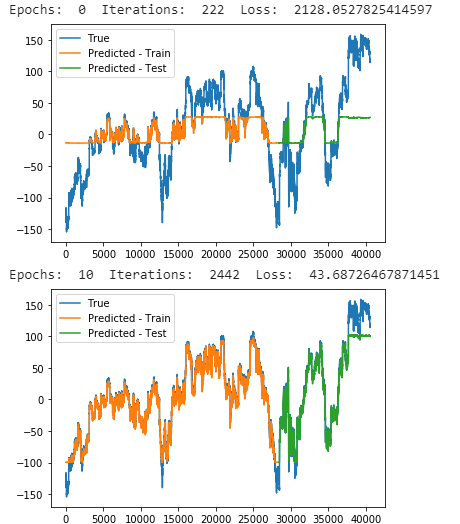
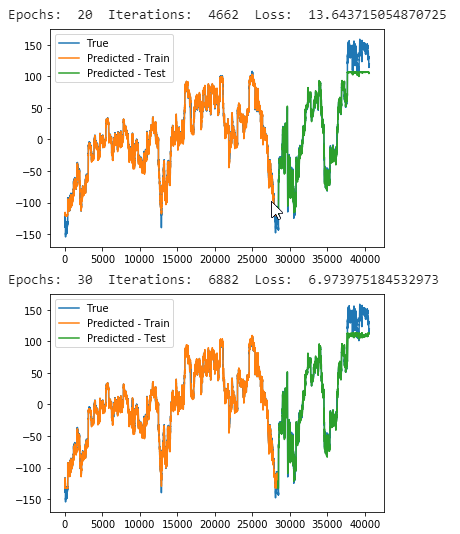
### Training Loss

Figure 1: Graphical illustration of the dual-stage attention-based recurrent neural network.