

代码拉取完成,页面将自动刷新
同步操作将从 程序员充电站/LeetCode-Py 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
快速排序(Quick Sort)基本思想:
采用经典的分治策略,选择数组中某个元素作为基准数,通过一趟排序将数组分为独立的两个子数组,一个子数组中所有元素值都比基准数小,另一个子数组中所有元素值都比基准数大。然后再按照同样的方式递归的对两个子数组分别进行快速排序,以达到整个数组有序。
假设数组的元素个数为 $n$ 个,则快速排序的算法步骤如下:
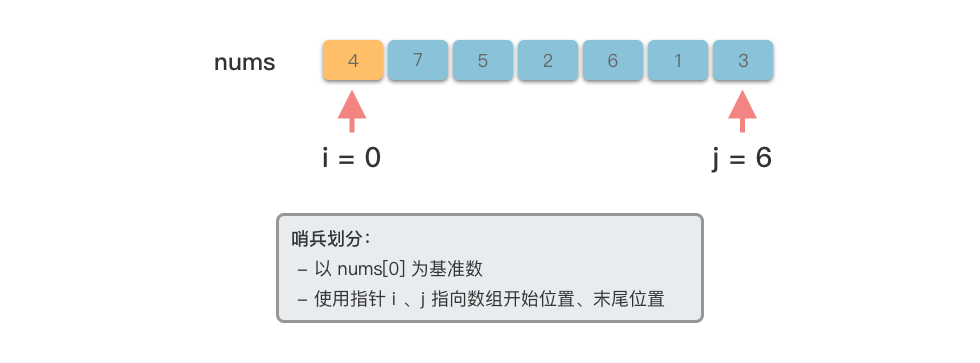
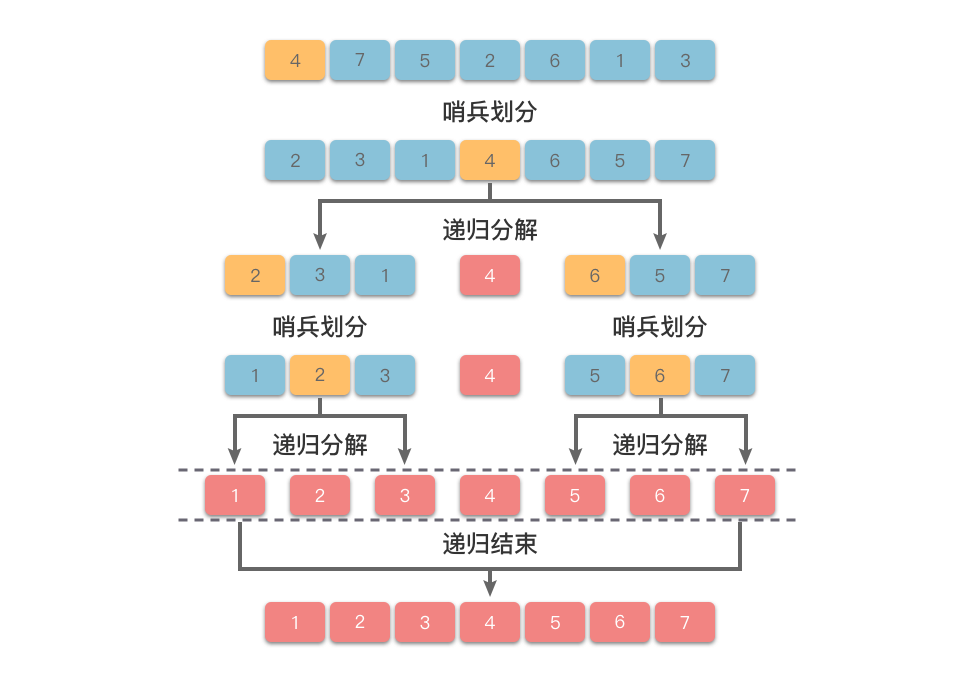
我们以 $[4, 7, 5, 2, 6, 1, 3]$ 为例,演示一下快速排序的整个步骤。
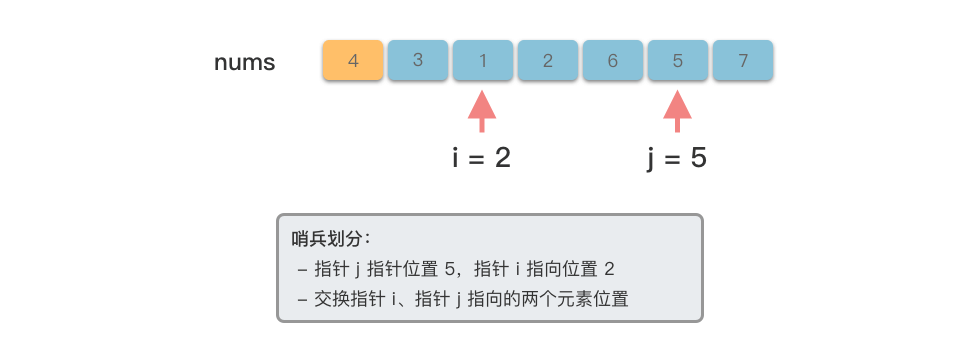
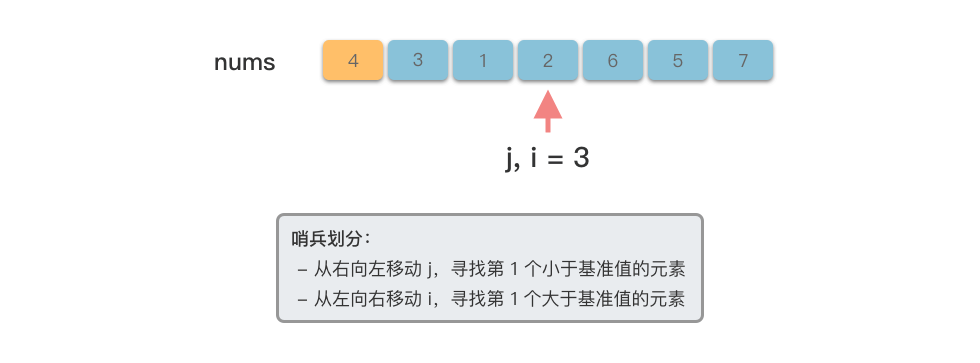
我们先来看一下单次「哨兵划分」的过程。
::: tabs#partition
@tab <1>
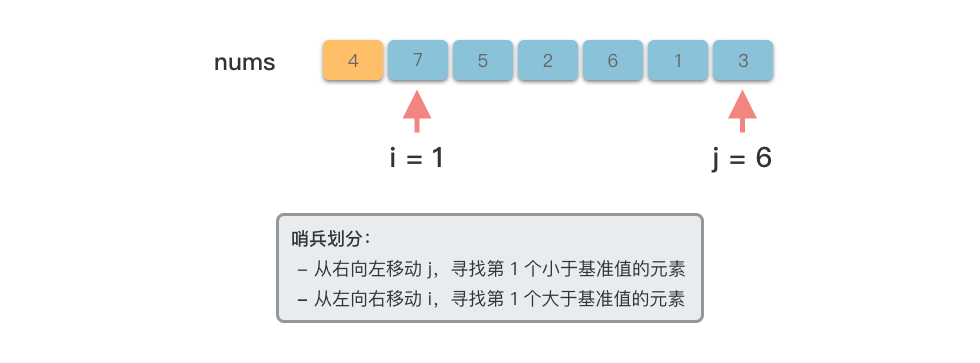
@tab <2>
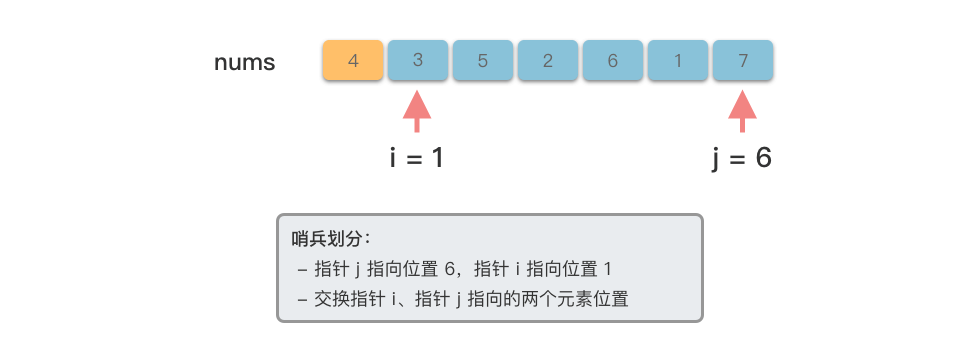
@tab <3>
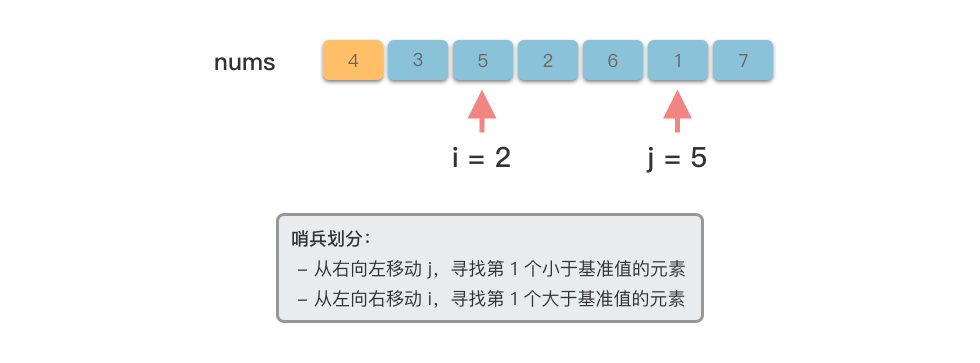
@tab <4>
@tab <5>
@tab <6>
@tab <7>

:::
在经过一次「哨兵划分」过程之后,数组就被划分为左子数组、基准数、右子树组三个独立部分。接下来只要对划分好的左右子数组分别进行递归排序即可完成排序。整个步骤如下:
import random
class Solution:
# 随机哨兵划分:从 nums[low: high + 1] 中随机挑选一个基准数,并进行移位排序
def randomPartition(self, nums: [int], low: int, high: int) -> int:
# 随机挑选一个基准数
i = random.randint(low, high)
# 将基准数与最低位互换
nums[i], nums[low] = nums[low], nums[i]
# 以最低位为基准数,然后将数组中比基准数大的元素移动到基准数右侧,比他小的元素移动到基准数左侧。最后将基准数放到正确位置上
return self.partition(nums, low, high)
# 哨兵划分:以第 1 位元素 nums[low] 为基准数,然后将比基准数小的元素移动到基准数左侧,将比基准数大的元素移动到基准数右侧,最后将基准数放到正确位置上
def partition(self, nums: [int], low: int, high: int) -> int:
# 以第 1 位元素为基准数
pivot = nums[low]
i, j = low, high
while i < j:
# 从右向左找到第 1 个小于基准数的元素
while i < j and nums[j] >= pivot:
j -= 1
# 从左向右找到第 1 个大于基准数的元素
while i < j and nums[i] <= pivot:
i += 1
# 交换元素
nums[i], nums[j] = nums[j], nums[i]
# 将基准节点放到正确位置上
nums[i], nums[low] = nums[low], nums[i]
# 返回基准数的索引
return i
def quickSort(self, nums: [int], low: int, high: int) -> [int]:
if low < high:
# 按照基准数的位置,将数组划分为左右两个子数组
pivot_i = self.randomPartition(nums, low, high)
# 对左右两个子数组分别进行递归快速排序
self.quickSort(nums, low, pivot_i - 1)
self.quickSort(nums, pivot_i + 1, high)
return nums
def sortArray(self, nums: [int]) -> [int]:
return self.quickSort(nums, 0, len(nums) - 1)
快速排序算法的时间复杂度主要跟基准数的选择有关。本文中是将当前数组中第 $1$ 个元素作为基准值。
在这种选择下,如果参加排序的元素初始时已经有序的情况下,快速排序方法花费的时间最长。也就是会得到最坏时间复杂度。
在这种情况下,第 $1$ 趟排序经过 $n - 1$ 次比较以后,将第 $1$ 个元素仍然确定在原来的位置上,并得到 $1$ 个长度为 $n - 1$ 的子数组。第 $2$ 趟排序进过 $n - 2$ 次比较以后,将第 $2$ 个元素确定在它原来的位置上,又得到 $1$ 个长度为 $n - 2$ 的子数组。
最终总的比较次数为 $(n − 1) + (n − 2) + … + 1 = \frac{n(n − 1)}{2}$。因此这种情况下的时间复杂度为 $O(n^2)$,也是最坏时间复杂度。
我们可以改进一下基准数的选择。如果每次我们选中的基准数恰好能将当前数组平分为两份,也就是刚好取到当前数组的中位数。
在这种选择下,每一次都将数组从 $n$ 个元素变为 $\frac{n}{2}$ 个元素。此时的时间复杂度公式为 $T(n) = 2 \times T(\frac{n}{2}) + \Theta(n)$。根据主定理可以得出 $T(n) = O(n \times \log n)$,也是最佳时间复杂度。
而在平均情况下,我们可以从当前数组中随机选择一个元素作为基准数。这样,每一次选择的基准数可以看做是等概率随机的。其期望时间复杂度为 $O(n \times \log n)$,也就是平均时间复杂度。
下面来总结一下:
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







