

代码拉取完成,页面将自动刷新
同步操作将从 程序员充电站/LeetCode-Py 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
「堆排序(Heap sort)」是一种基于「堆结构」实现的高效排序算法。在介绍「堆排序」之前,我们先来了解一下什么是「堆结构」。
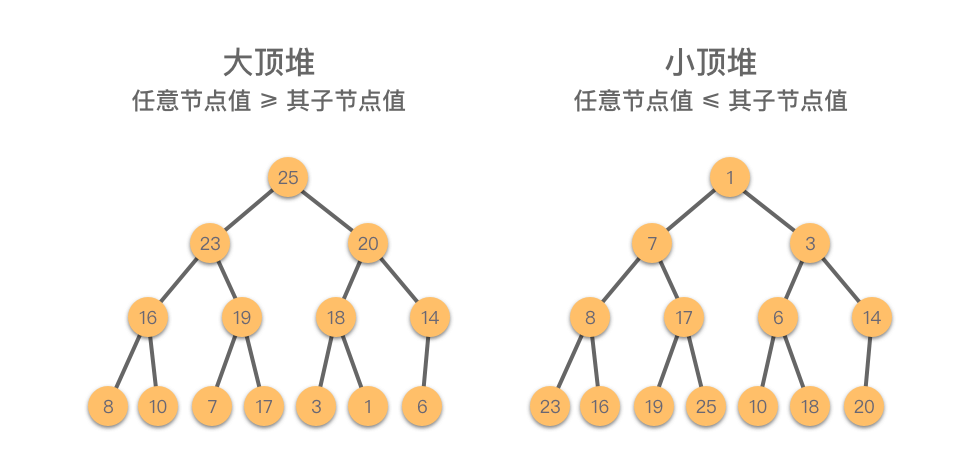
堆(Heap):一种满足以下两个条件之一的完全二叉树:
- 大顶堆(Max Heap):任意节点值 ≥ 其子节点值。
- 小顶堆(Min Heap):任意节点值 ≤ 其子节点值。
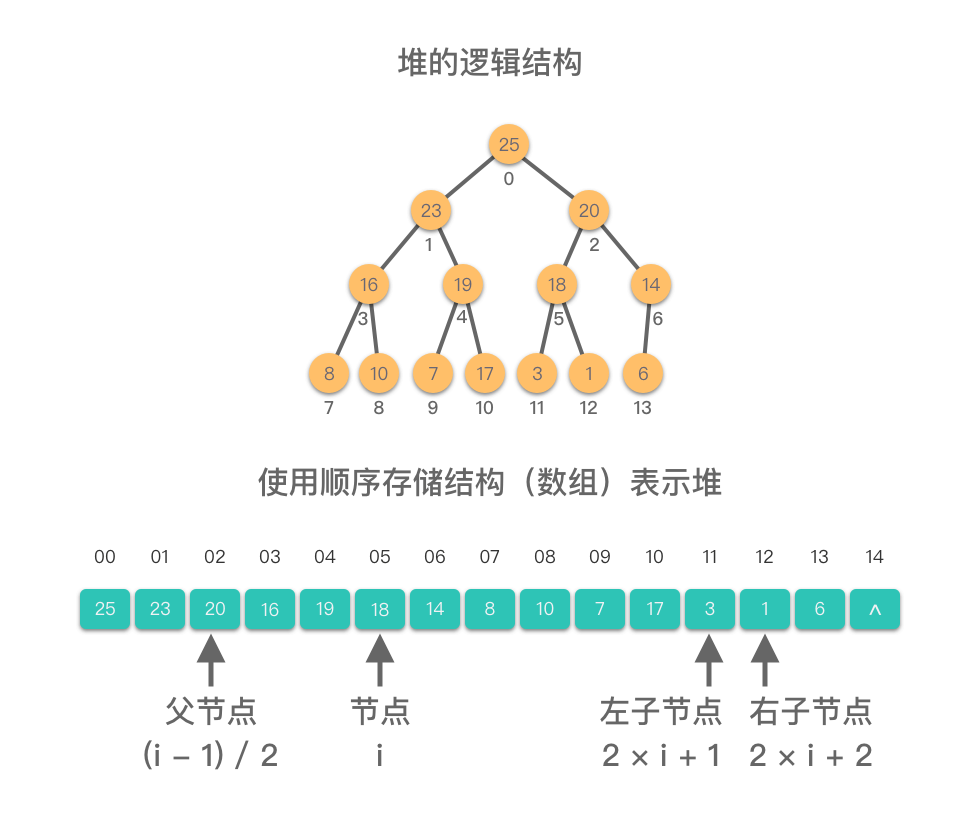
堆的逻辑结构就是一颗完全二叉树。而我们在「07.树 - 01.二叉树 - 01.树与二叉树的基础知识」章节中学过,对于完全二叉树(尤其是满二叉树)来说,采用顺序存储结构(数组)的形式来表示完全二叉树,能够充分利用存储空间。
当我们使用顺序存储结构(即数组)来表示堆时,堆中元素的节点编号与数组的索引关系为:
class MaxHeap:
def __init__(self):
self.max_heap = []
访问堆顶元素:指的是从堆结构中获取位于堆顶的元素。
在堆中,堆顶元素位于根节点,当我们使用顺序存储结构(即数组)来表示堆时,堆顶元素就是数组的首个元素。
class MaxHeap:
......
def peek(self) -> int:
# 大顶堆为空
if not self.max_heap:
return None
# 返回堆顶元素
return self.max_heap[0]
访问堆顶元素不依赖于数组中元素个数,因此时间复杂度为 $O(1)$。
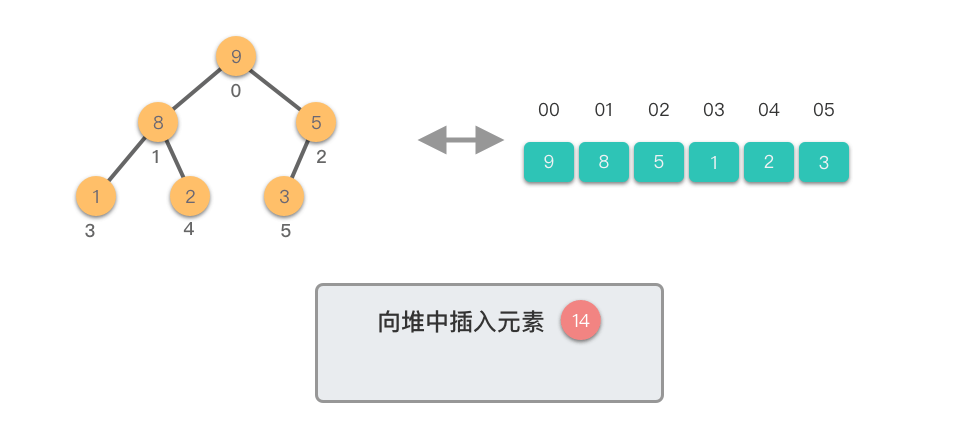
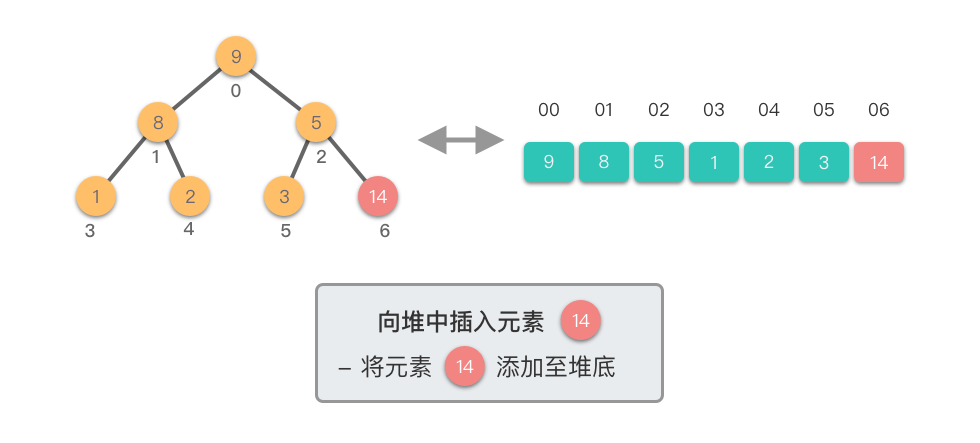
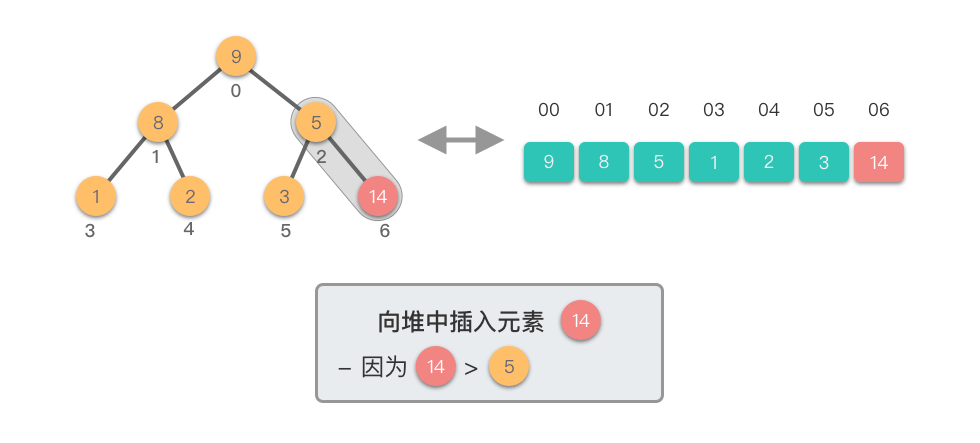
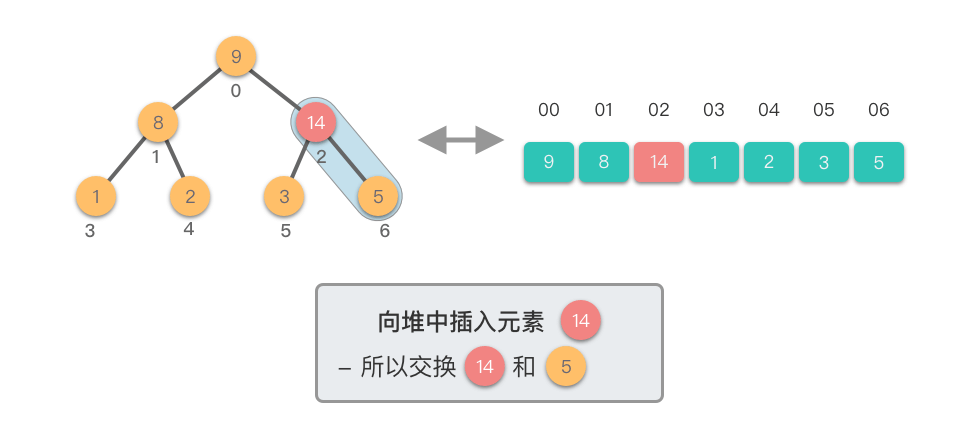
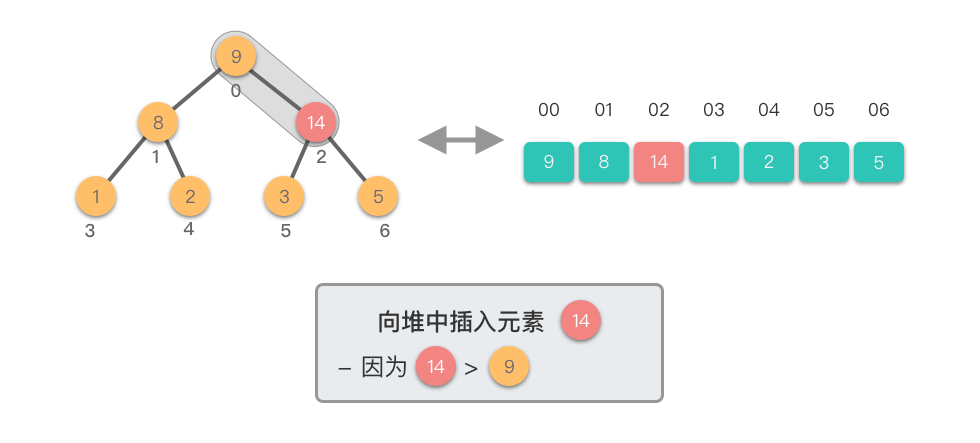
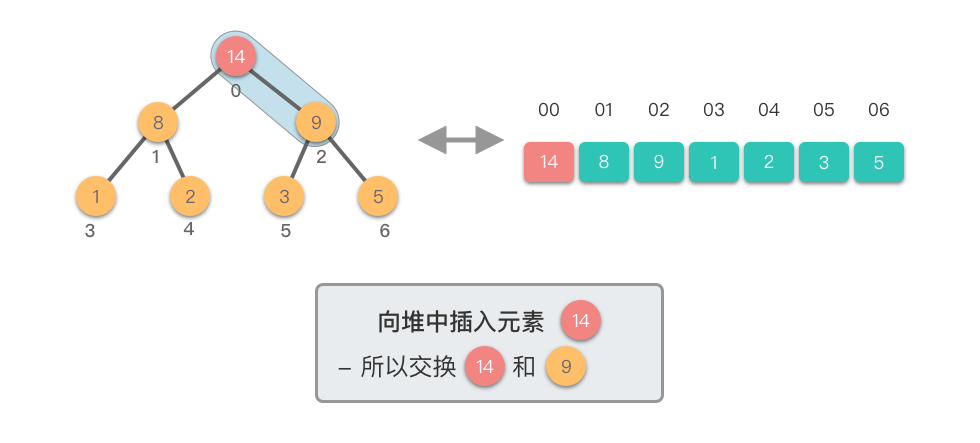
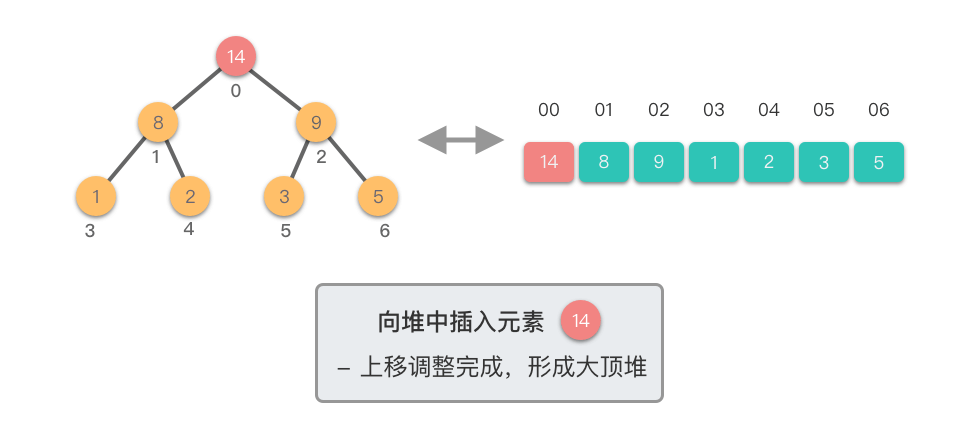
向堆中插入元素:指的将一个新的元素添加到堆中,调整堆结构,以保持堆的特性不变。
向堆中插入元素的步骤如下:
这个过程称为「上移调整(Shift Up)」。因为新插入的元素会逐步向堆的上方移动,直到找到了合适的位置,保持堆的有序性。
::: tabs#heapPush
@tab <1>
@tab <2>
@tab <3>
@tab <4>
@tab <5>
@tab <6>
@tab <7>
:::
class MaxHeap:
......
def push(self, val: int):
# 将新元素添加到堆的末尾
self.max_heap.append(val)
size = len(self.max_heap)
# 从新插入的元素节点开始,进行上移调整
self.__shift_up(size - 1)
def __shift_up(self, i: int):
while (i - 1) // 2 >= 0 and self.max_heap[i] > self.max_heap[(i - 1) // 2]:
self.max_heap[i], self.max_heap[(i - 1) // 2] = self.max_heap[(i - 1) // 2], self.max_heap[i]
i = (i - 1) // 2
在最坏情况下,「向堆中插入元素」的时间复杂度为 $O(\log n)$,其中 $n$ 是堆中元素的数量,这是因为堆的高度是 $\log n$。
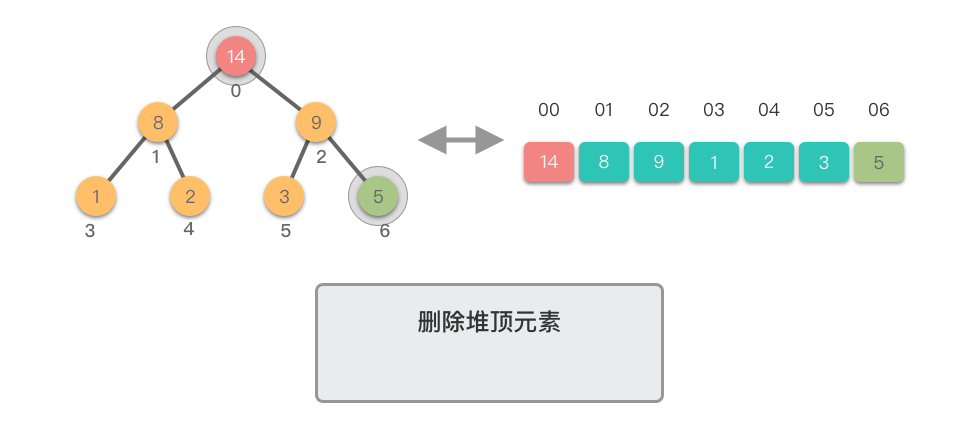
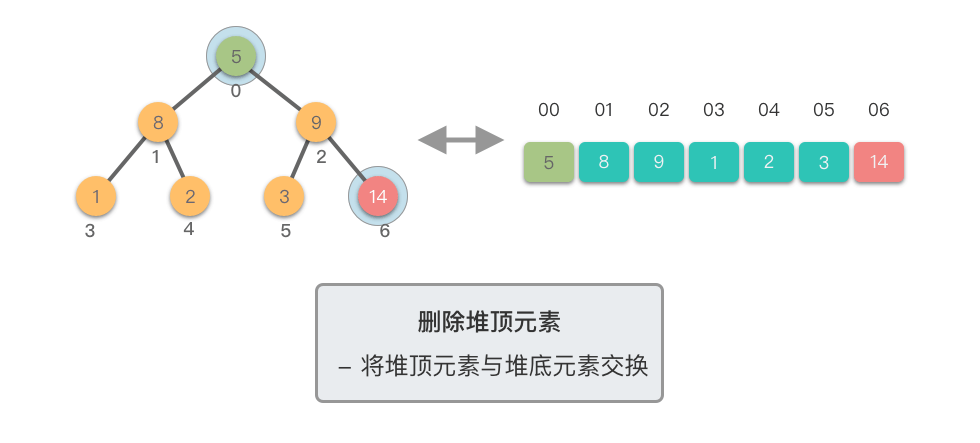
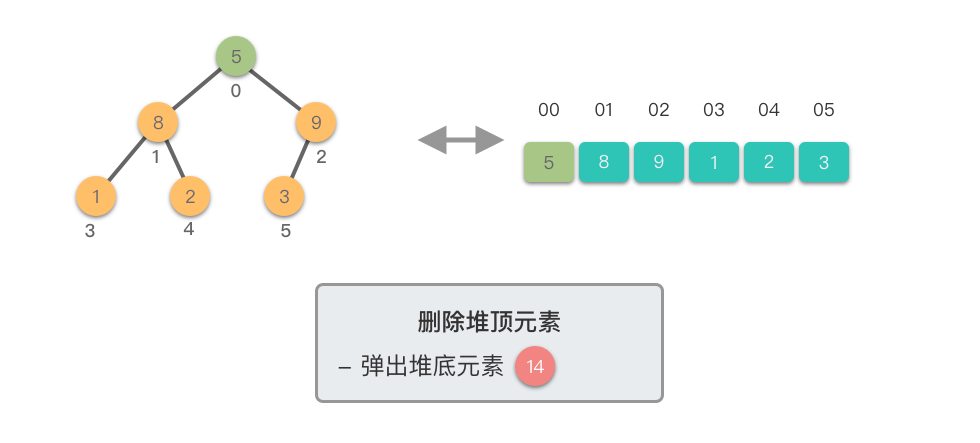
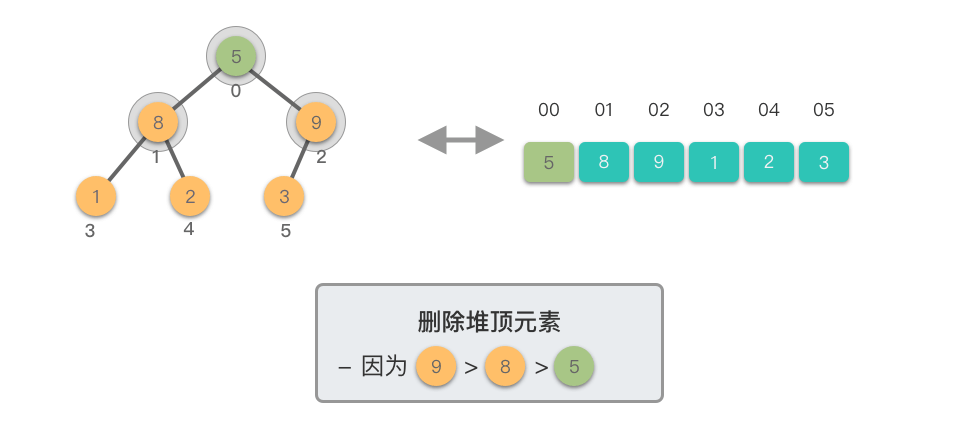
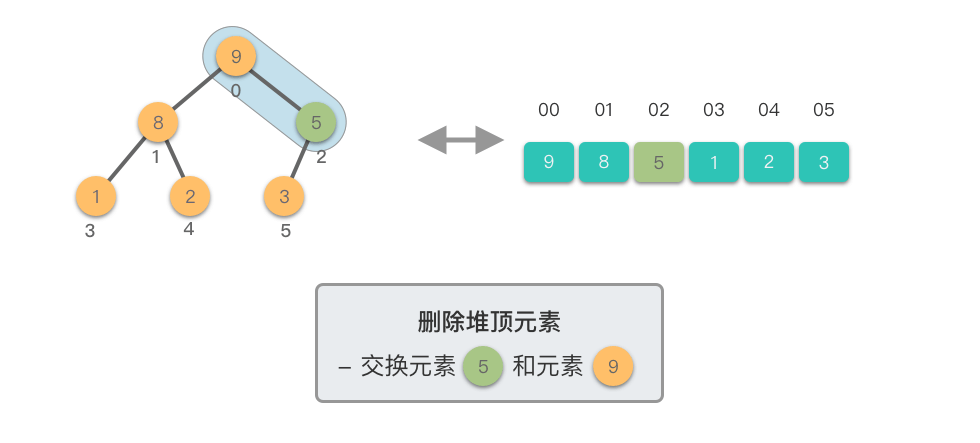
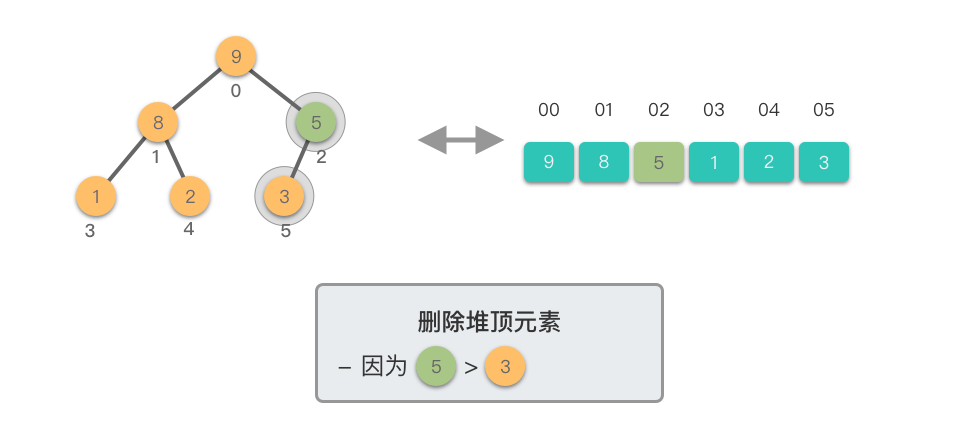
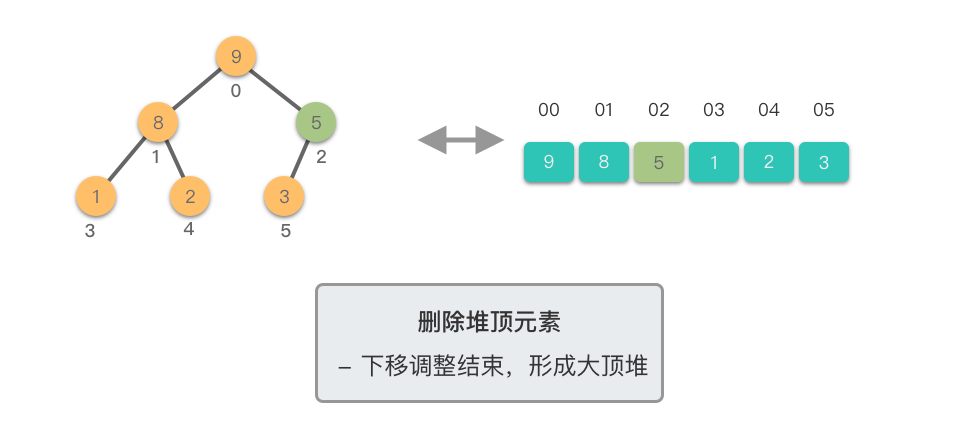
删除堆顶元素:指的是从堆中移除位于堆顶的元素,并重新调整对结果,以保持堆的特性不变。
删除堆顶元素的步骤如下:
这个过程称为「下移调整(Shift Down)」。因为新的堆顶元素会逐步向堆的下方移动,直到找到了合适的位置,保持堆的有序性。
::: tabs#heapPop
@tab <1>
@tab <2>
@tab <3>
@tab <4>
@tab <5>
@tab <6>
@tab <7>
:::
class MaxHeap:
......
def pop(self) -> int:
# 堆为空
if not self.max_heap:
raise IndexError("堆为空")
size = len(self.max_heap)
self.max_heap[0], self.max_heap[size - 1] = self.max_heap[size - 1], self.max_heap[0]
# 删除堆顶元素
val = self.max_heap.pop()
# 节点数减 1
size -= 1
# 下移调整
self.__shift_down(0, size)
# 返回堆顶元素
return val
def __shift_down(self, i: int, n: int):
while 2 * i + 1 < n:
# 左右子节点编号
left, right = 2 * i + 1, 2 * i + 2
# 找出左右子节点中的较大值节点编号
if 2 * i + 2 >= n:
# 右子节点编号超出范围(只有左子节点
larger = left
else:
# 左子节点、右子节点都存在
if self.max_heap[left] >= self.max_heap[right]:
larger = left
else:
larger = right
# 将当前节点值与其较大的子节点进行比较
if self.max_heap[i] < self.max_heap[larger]:
# 如果当前节点值小于其较大的子节点,则将它们交换
self.max_heap[i], self.max_heap[larger] = self.max_heap[larger], self.max_heap[i]
i = larger
else:
# 如果当前节点值大于等于于其较大的子节点,此时结束
break
「删除堆顶元素」的时间复杂度通常为$O(\log n)$,其中 $n$ 是堆中元素的数量,因为堆的高度是 $\log n$。
堆排序(Heap sort)基本思想:
借用「堆结构」所设计的排序算法。将数组转化为大顶堆,重复从大顶堆中取出数值最大的节点,并让剩余的堆结构继续维持大顶堆性质。
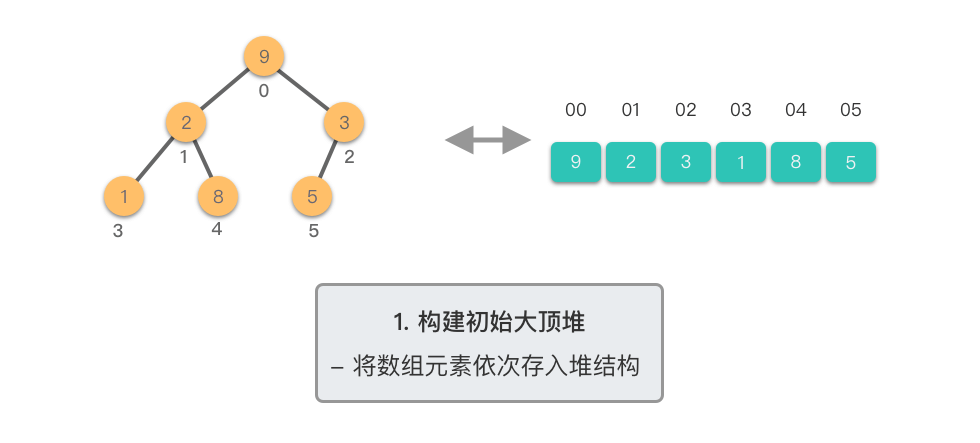
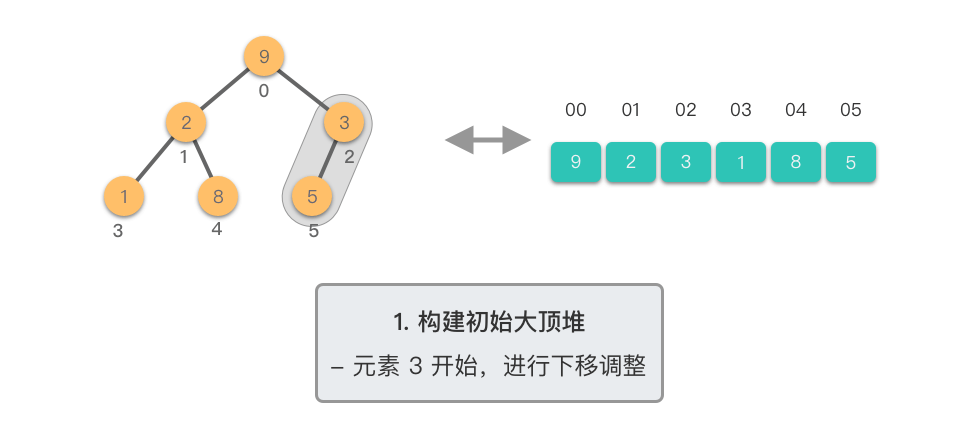
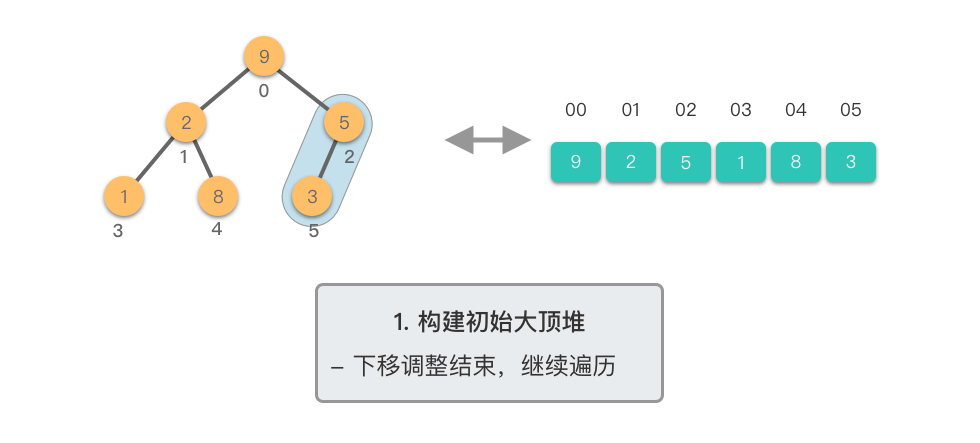
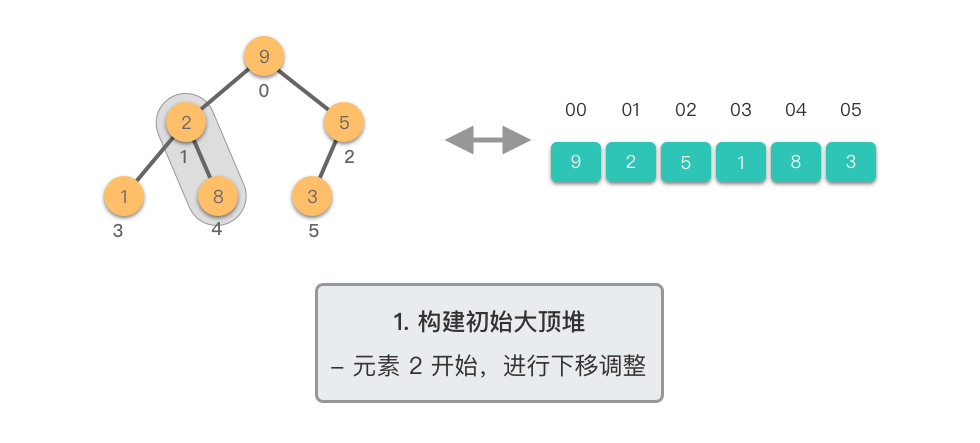
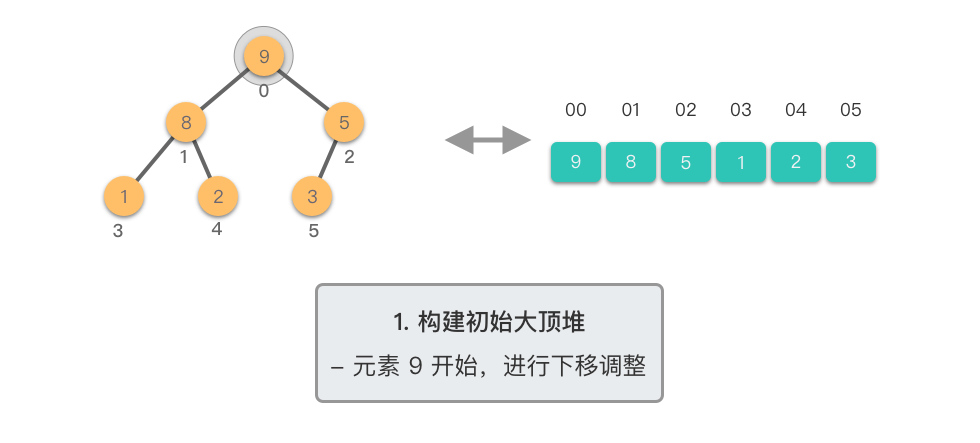
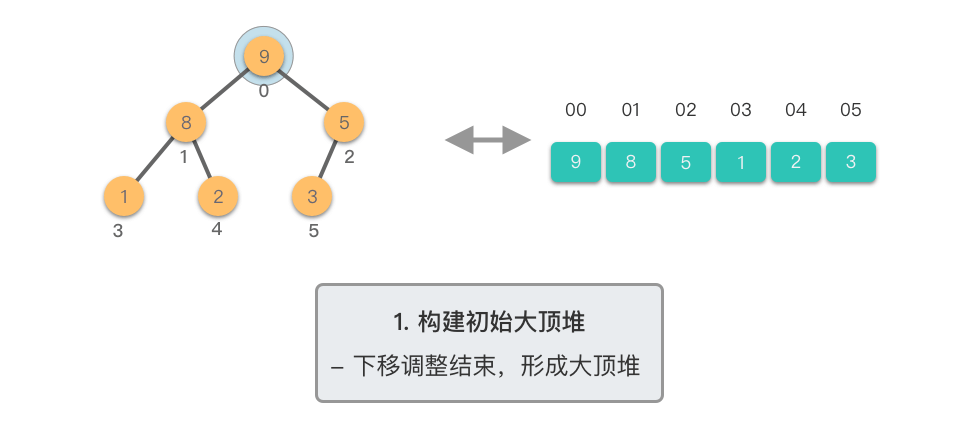
构建初始大顶堆:
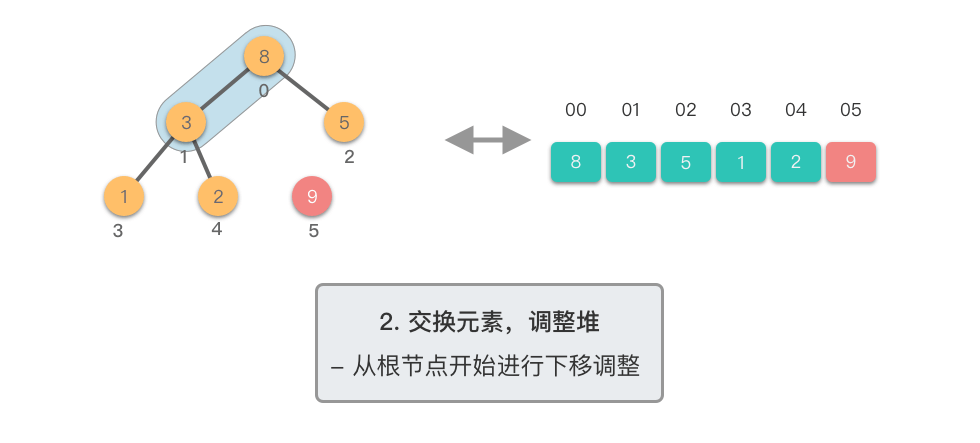
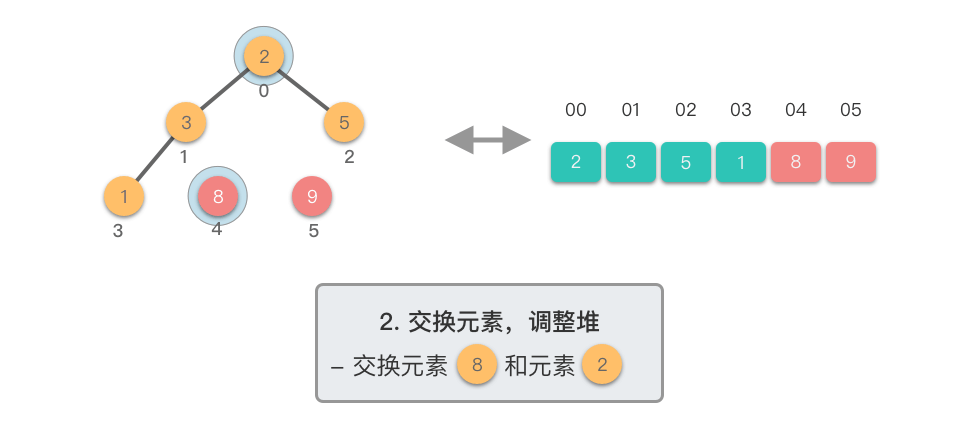
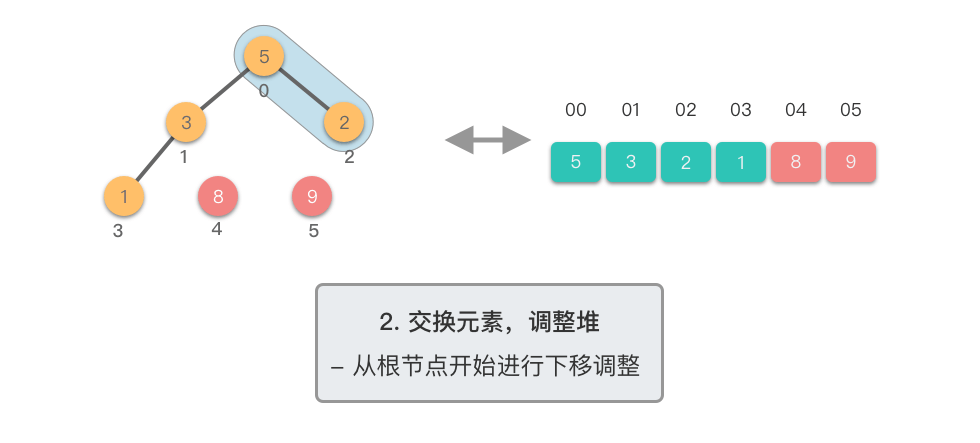
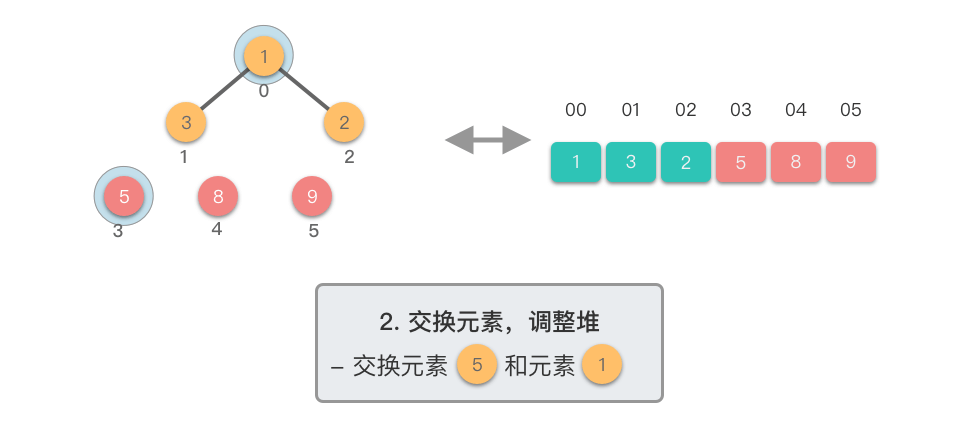
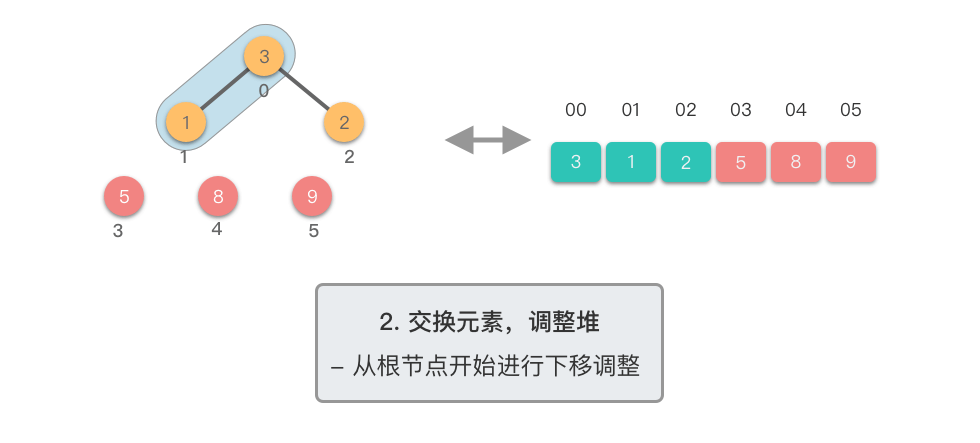
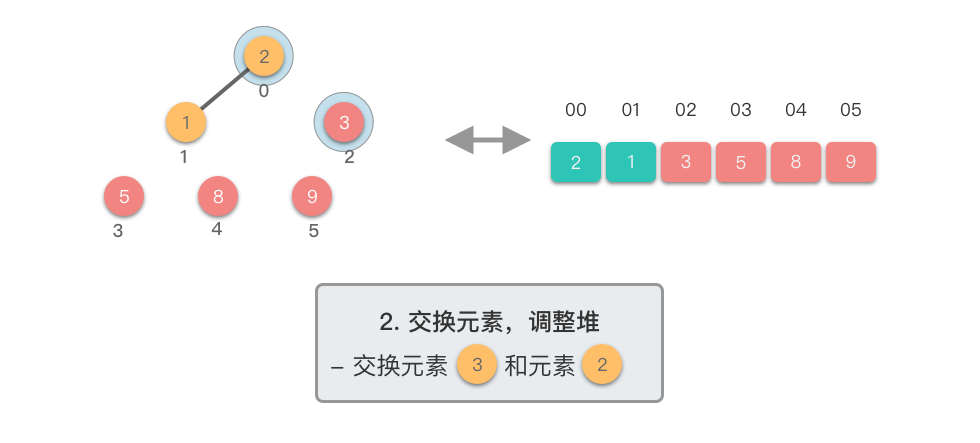
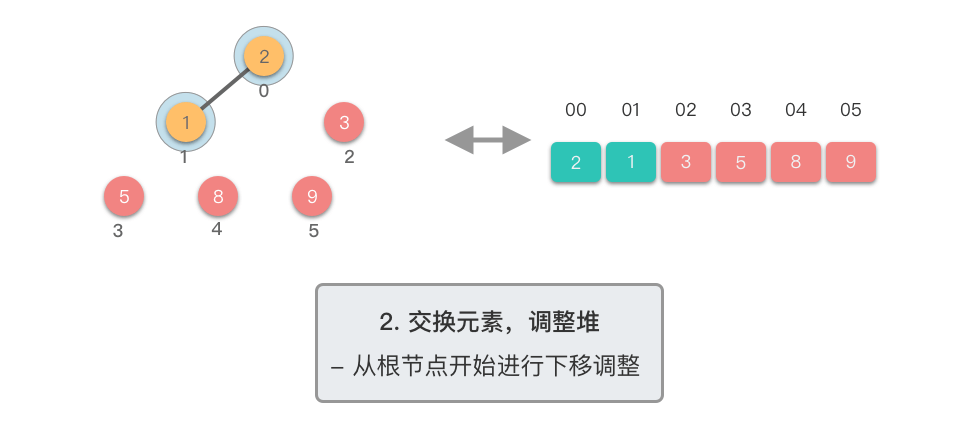
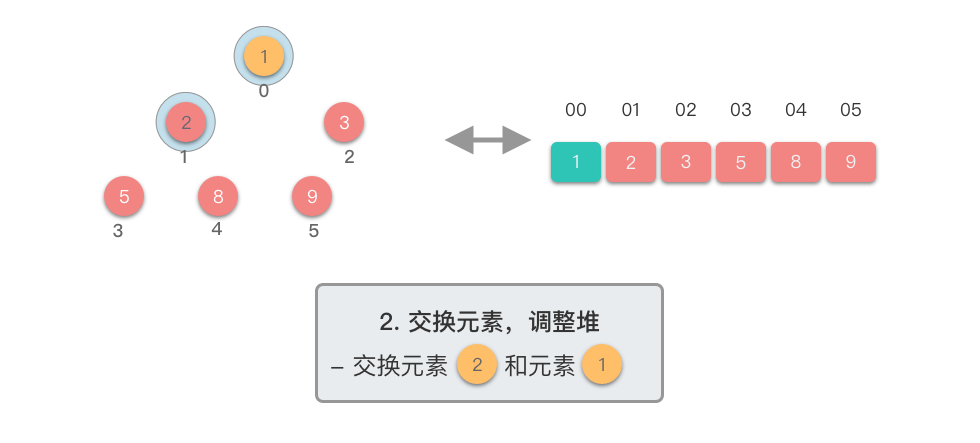
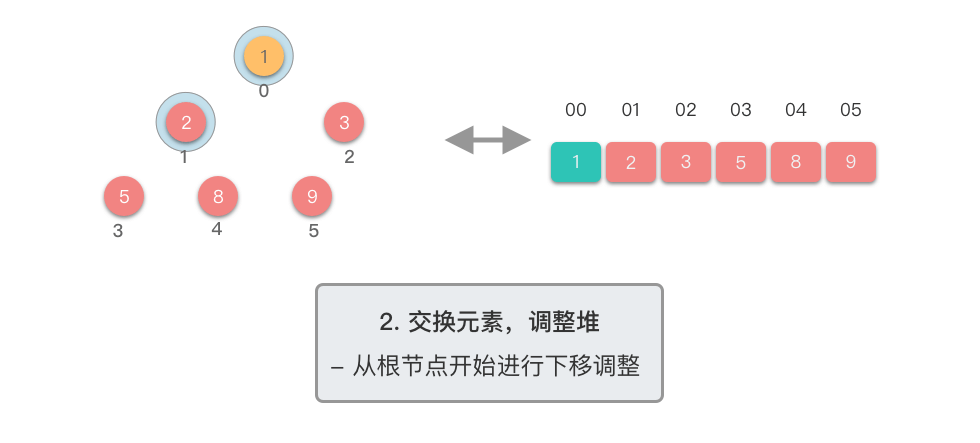
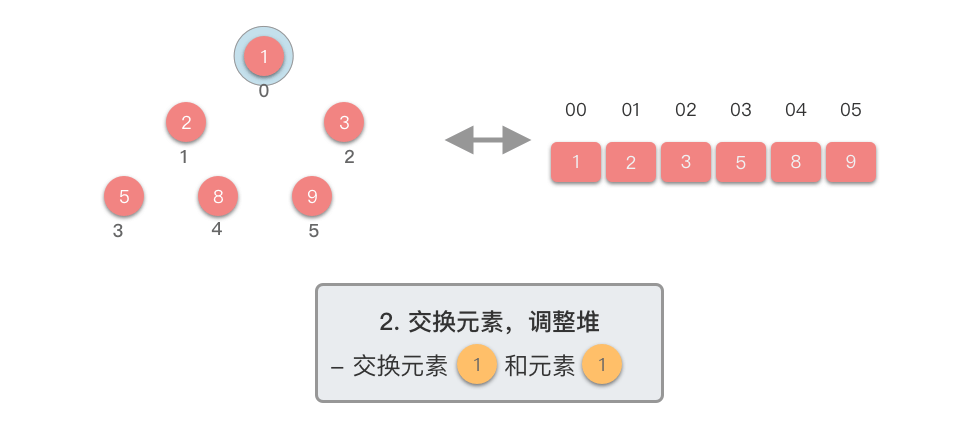
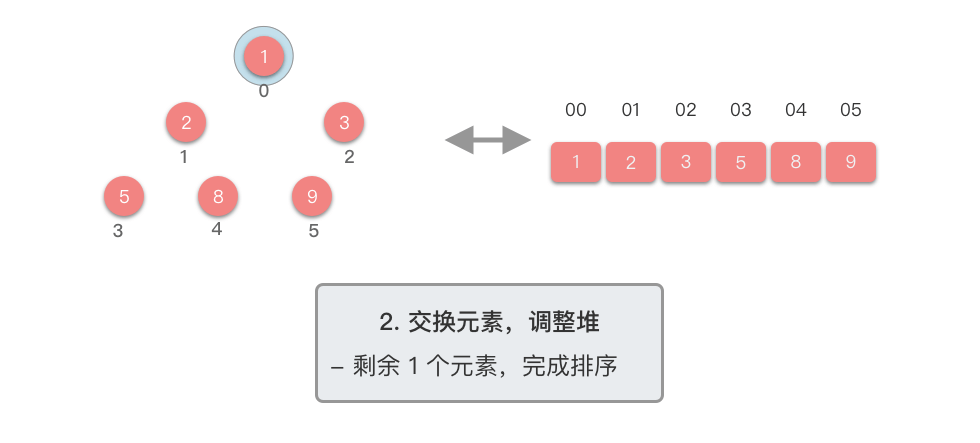
交换元素,调整堆:
重复交换和调整堆:
::: tabs#heapSortBuildMaxHeap
@tab <1>
@tab <2>
@tab <3>
@tab <4>
@tab <5>
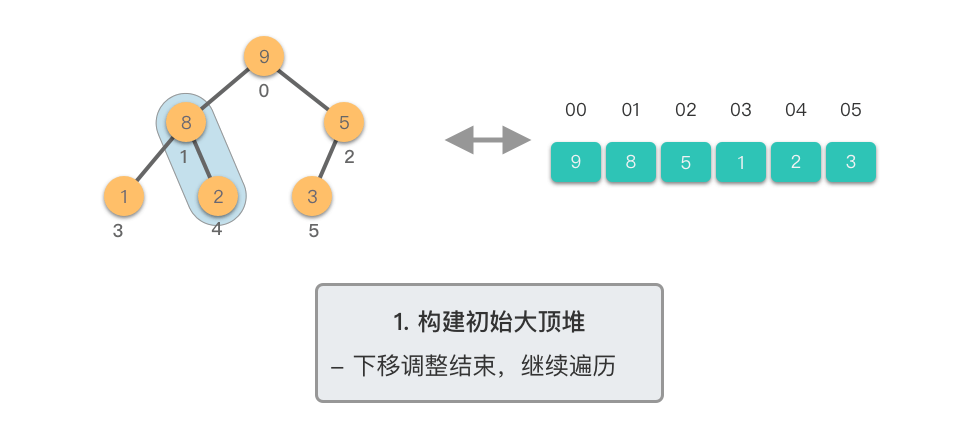
@tab <6>
@tab <7>
:::
::: tabs#heapSortExchangeVal
@tab <1>
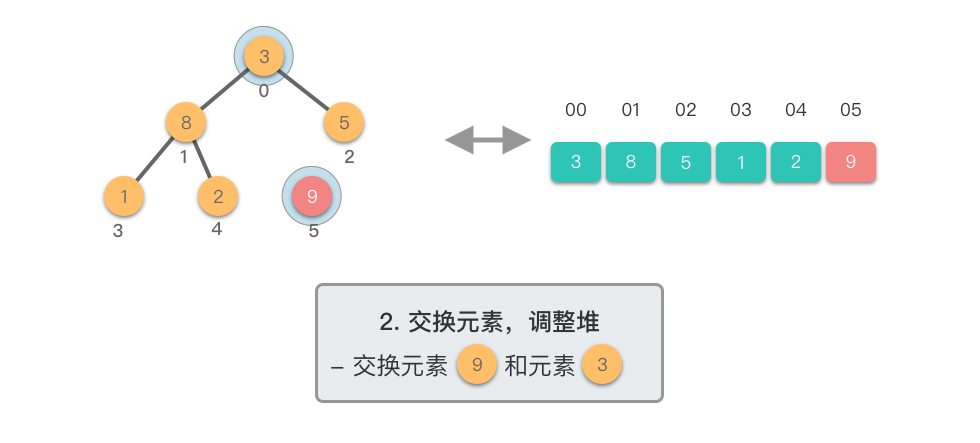
@tab <2>
@tab <3>
@tab <4>
@tab <5>
@tab <6>
@tab <7>
@tab <8>
@tab <9>
@tab <10>
@tab <11>
@tab <12>
:::
class MaxHeap:
......
def __buildMaxHeap(self, nums: [int]):
size = len(nums)
# 先将数组 nums 的元素按顺序添加到 max_heap 中
for i in range(size):
self.max_heap.append(nums[i])
# 从最后一个非叶子节点开始,进行下移调整
for i in range((size - 2) // 2, -1, -1):
self.__shift_down(i, size)
def maxHeapSort(self, nums: [int]) -> [int]:
# 根据数组 nums 建立初始堆
self.__buildMaxHeap(nums)
size = len(self.max_heap)
for i in range(size - 1, -1, -1):
# 交换根节点与当前堆的最后一个节点
self.max_heap[0], self.max_heap[i] = self.max_heap[i], self.max_heap[0]
# 从根节点开始,对当前堆进行下移调整
self.__shift_down(0, i)
# 返回排序后的数组
return self.max_heap
class Solution:
def maxHeapSort(self, nums: [int]) -> [int]:
return MaxHeap().maxHeapSort(nums)
def sortArray(self, nums: [int]) -> [int]:
return self.maxHeapSort(nums)
print(Solution().sortArray([10, 25, 6, 8, 7, 1, 20, 23, 16, 19, 17, 3, 18, 14]))
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







