

代码拉取完成,页面将自动刷新
同步操作将从 程序员充电站/LeetCode-Py 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
字符串(String):简称为串,是由零个或多个字符组成的有限序列。一般记为 $s = a_1a_2…a_n (0 \le n ⪇ \infty)$。
下面介绍一下字符串相关的一些重要概念。
""。举个例子来说明一下:
str = "Hello World"
在示例代码中,$str$ 是一个字符串的变量名称,Hello World 则是该字符串的值,字符串的长度为 $11$。该字符串的表示如下图所示:

可以看出来,字符串和数组有很多相似之处。比如同样使用 名称[下标] 的方式来访问一个字符。
之所以单独讨论字符串是因为:
根据字符串的特点,我们可以将字符串问题分为以下几种:
两个数字之间很容易比较大小,例如 $1 < 2$。而字符串之间的比较相对来说复杂一点。字符串之间的大小取决于它们按顺序排列字符的前后顺序。
比如字符串 str1 = "abc" 和 str2 = "acc",它们的第一个字母都是 $a$,而第二个字母,由于字母 $b$ 比字母 $c$ 要靠前,所以 $b < c$,于是我们可以说 "abc" < "acd" ,也可以说 $str1 < str2$。
字符串之间的比较是通过组成字符串的字符之间的「字符编码」来决定的。而字符编码指的是字符在对应字符集中的序号。
我们先来考虑一下如何判断两个字符串是否相等。
如果说两个字符串 $str1$ 和 $str2$ 相等,则必须满足两个条件:
下面我们再来考虑一下如何判断两个字符串的大小。
而对于两个不相等的字符串,我们可以以下面的规则定义两个字符串的大小:
"abc" < "acc"。"bcd" > "bad"。"abc" < "abcde"。"abcde" > "abc"。"abcd" == "abcd"。按照上面的规则,我们可以定义一个 strcmp 方法,并且规定:
strcmp 方法返回 $-1$。strcmp 方法返回 $0$。strcmp 方法返回 $1$。strcmp 方法对应的具体代码如下:
def strcmp(str1, str2):
index1, index2 = 0, 0
while index1 < len(str1) and index2 < len(str2):
if ord(str1[index1]) == ord(str2[index2]):
index1 += 1
index2 += 1
elif ord(str1[index1]) < ord(str2[index2]):
return -1
else:
return 1
if len(str1) < len(str2):
return -1
elif len(str1) > len(str2):
return 1
else:
return 0
上面关于字符串大小的定义有点复杂,其实字符串比较大小最简单的例子就是「查英语词典」。在英语词典的目录中,前面的单词要比后面的单词小。我们将英语词典中的每个英语单词都当做是一个字符串,那么查找单词的过程,其实就是比较字符串大小的过程。
刚才我们提到了字符编码,这里我们也稍微介绍一下字符串中常用的字符编码标准。
以计算机中常用字符使用的 ASCII 编码为例。最早的时候,人们制定了一个包含 $127$ 个字符的编码表 ASCII 到计算机系统中。ASCII 编码表中的字符包含了大小写的英文字母、数字和一些符号。每个字符对应一个编码,比如大写字母 $A$ 的编码是 $65$,小写字母 $a$ 的编码是 $97$。
ASCII 编码可以解决以英语为主的语言,可是无法满足中文编码。为了解决中文编码,我国制定了 GB2312、GBK、GB18030 等中文编码标准,将中文编译进去。但是世界上有上百种语言和文字,各国有各国的标准,就会不可避免的产生冲突,于是就有了 Unicode 编码。Unicode 编码最常用的就是 UTF-8 编码,UTF-8 编码把一个 Unicode 字符根据不同的数字大小编码成 $1 \sim 6$ 个字节,常用的英文字母被编码成 $1$ 个字节,汉字通常是 $3$ 个字节。
字符串的存储结构跟线性表相同,分为「顺序存储结构」和「链式存储结构」。
与线性表的顺序存储结构相似,字符串的顺序存储结构也是使用一组地址连续的存储单元依次存放串中的各个字符。按照预定义的大小,为每个定义的字符串变量分配一个固定长度的存储区域。一般是用定长数组来定义。
字符串的顺序存储结构如下图所示。

如上图所示,字符串的顺序存储中每一个字符元素都有自己的下标索引,下标所以从 $0$ 开始,到 $\text{字符串长度} - 1$ 结束。字符串中每一个「下标索引」,都有一个与之对应的「字符元素」。
跟数组类似,字符串也支持随机访问。即字符串可以根据下标,直接定位到某一个字符元素存放的位置。
字符串的存储也可以采用链式存储结构,即采用一个线性链表来存储一个字符串。字符串的链节点包含一个用于存放字符的 $data$ 变量,和指向下一个链节点的指针变量 $next$。这样,一个字符串就可以用一个线性链表来表示。
在字符串的链式存储结构中,每个链节点可以仅存放一个字符,也可以存放多个字符。通常情况下,链节点的字符长度为 $1$ 或者 $4$,这是为了避免浪费空间。当链节点的字符长度为 $4$ 时,由于字符串的长度不一定是 $4$ 的倍数,因此字符串所占用的链节点中最后那个链节点的 $data$ 变量可能没有占满,我们可以用 # 或其他不属于字符集的特殊字符将其补全。
字符串的链式存储结构图下图所示。
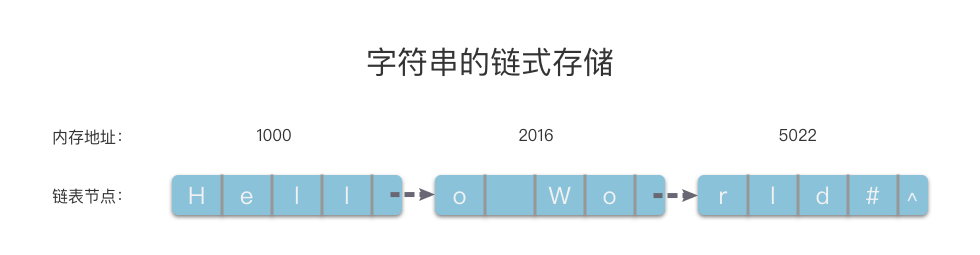
如上图所示,字符串的链式存储将一组任意的存储单元串联在一起。链节点之间的逻辑关系是通过指针来间接反映的。
\0 结尾的字符数组。\0 符号用于标记字符串的结束。C 语言的标准库 string.h 头文件中提供了各种操作字符串的函数。string 类类型。string 类处理起字符串来会方便很多,完全可以代替 C 语言中的字符数组或字符串指针。String 类作为字符串库。str 对象来代表字符串。str 对象一种不可变类型对象。即 str 类型创建的字符串对象在定义之后,无法更改字符串的长度,也无法改变或删除字符串中的字符。字符串匹配(String Matching):又称模式匹配(Pattern Matching)。可以简单理解为,给定字符串 $T$ 和 $p$,在主串 $T$ 中寻找子串 $p$。主串 $T$ 又被称为文本串,子串 $p$ 又被称为模式串(
Pattern)。
在字符串问题中,最重要的问题之一就是字符串匹配问题。而按照模式串的个数,我们可以将字符串匹配问题分为:「单模式串匹配问题」和「多模式串匹配问题」。
单模式匹配问题(Single Pattern Matching):给定一个文本串 $T = t_1t_2...t_n$,再给定一个特定模式串 $p = p_1p_2...p_n$。要求从文本串 $T$ 找出特定模式串 $p$ 的所有出现位置。
有很多算法可以解决单模式匹配问题。而根据在文本中搜索模式串方式的不同,我们可以将单模式匹配算法分为以下几种:
多模式匹配问题(Multi Pattern Matching):给定一个文本串 $T = t_1t_2...t_n$,再给定一组模式串 $P = {p^1, p^2, ... ,p^r}$,其中每个模式串 $p^i$ 是定义在有限字母表上的字符串 $p^i = p^i_1p^i_2...p^i_n$。要求从文本串 $T$ 中找到模式串集合 $P$ 中所有模式串 $p^i$ 的所有出现位置。
模式串集合 $P$ 中的一些字符串可能是集合中其他字符串的子串、前缀、后缀,或者完全相等。解决多模式串匹配问题最简单的方法是利用「单模式串匹配算法」搜索 $r$ 遍。这将导致预处理阶段的最坏时间复杂度为 $O(|P|)$,搜索阶段的最坏时间复杂度为 $O(r \times n)$。
如果使用「单模式串匹配算法」解决多模式匹配问题,那么根据在文本中搜索模式串方式的不同,我们也可以将多模式串匹配算法分为以下三种:
需要注意的是,以上所介绍的多模式串匹配算法大多使用了一种基本的数据结构:「字典树(Trie Tree)」。著名的 「Aho-Corasick Automaton (AC 自动机) 算法」 就是在「KMP 算法」的基础上,与「字典树」结构相结合而诞生的。而「AC 自动机算法」也是多模式串匹配算法中最有效的算法之一。
所以学习多模式匹配算法,重点是要掌握 「字典树」 和 「AC 自动机算法」 。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







