

代码拉取完成,页面将自动刷新
同步操作将从 程序员充电站/LeetCode-Py 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
贪心算法(Greedy Algorithm):一种在每次决策时,总是采取在当前状态下的最好选择,从而希望导致结果是最好或最优的算法。
贪心算法是一种改进的「分步解决算法」,其核心思想是:将求解过程分成「若干个步骤」,然后根据题意选择一种「度量标准」,每个步骤都应用「贪心原则」,选取当前状态下「最好 / 最优选择(局部最优解)」,并以此希望最后得出的结果也是「最好 / 最优结果(全局最优解)」。
换句话说,贪心算法不从整体最优上加以考虑,而是一步一步进行,每一步只以当前情况为基础,根据某个优化测度做出局部最优选择,从而省去了为找到最优解要穷举所有可能所必须耗费的大量时间。
对许多问题来说,可以使用贪心算法,通过局部最优解而得到整体最优解或者是整体最优解的近似解。但并不是所有问题,都可以使用贪心算法的。
一般来说,这些能够使用贪心算法解决的问题必须满足下面的两个特征:
贪心选择性质:指的是一个问题的全局最优解可以通过一系列局部最优解(贪心选择)来得到。
换句话说,当进行选择时,我们直接做出在当前问题中看来最优的选择,而不用去考虑子问题的解。在做出选择之后,才会去求解剩下的子问题,如下图所示。
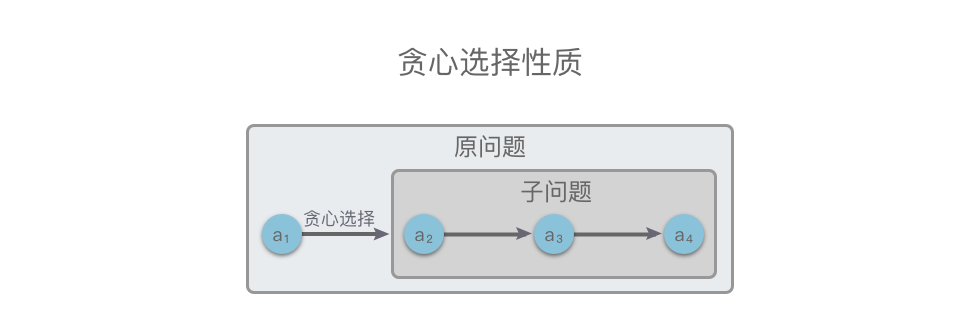
贪心算法在进行选择时,可能会依赖之前做出的选择,但不会依赖任何将来的选择或是子问题的解。运用贪心算法解决的问题在程序的运行过程中无回溯过程。
最优子结构性质:指的是一个问题的最优解包含其子问题的最优解。
问题的最优子结构性质是该问题能否用贪心算法求解的关键。
举个例子,如下图所示,原问题 $S = \lbrace a_1, a_2, a_3, a_4 \rbrace$,在 $a_1$ 步我们通过贪心选择选出一个当前最优解之后,问题就转换为求解子问题 $S_{\text{子问题}} = \lbrace a_2, a_3, a_4 \rbrace$。如果原问题 $S$ 的最优解可以由「第 $a_1$ 步通过贪心选择的局部最优解」和「 $S_{\text{子问题}}$ 的最优解」构成,则说明该问题满足最优子结构性质。
也就是说,如果原问题的最优解包含子问题的最优解,则说明该问题满足最优子结构性质。
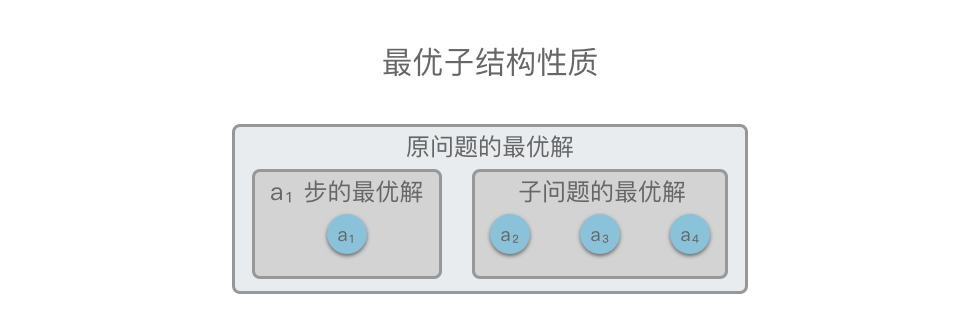
在做了贪心选择后,满足最优子结构性质的原问题可以分解成规模更小的类似子问题来解决,并且可以通过贪心选择和子问题的最优解推导出问题的最优解。
反之,如果不能利用子问题的最优解推导出整个问题的最优解,那么这种问题就不具有最优子结构。
贪心算法最难的部分不在于问题的求解,而在于是正确性的证明。我们常用的证明方法有「数学归纳法」和「交换论证法」。
数学归纳法:先计算出边界情况(例如 $n = 1$)的最优解,然后再证明对于每个 $n$,$F_{n + 1}$ 都可以由 $F_n$ 推导出。
交换论证法:从最优解出发,在保证全局最优不变的前提下,如果交换方案中任意两个元素 / 相邻的两个元素后,答案不会变得更好,则可以推定目前的解是最优解。
判断一个问题是否通过贪心算法求解,是需要进行严格的数学证明的。但是在日常写题或者算法面试中,不太会要求大家去证明贪心算法的正确性。
所以,当我们想要判断一个问题是否通过贪心算法求解时,我们可以:
描述:一位很棒的家长为孩子们分发饼干。对于每个孩子 $i$,都有一个胃口值 $g[i]$,即每个小孩希望得到饼干的最小尺寸值。对于每块饼干 $j$,都有一个尺寸值 $s[j]$。只有当 $s[j] > g[i]$ 时,我们才能将饼干 $j$ 分配给孩子 $i$。每个孩子最多只能给一块饼干。
现在给定代表所有孩子胃口值的数组 $g$ 和代表所有饼干尺寸的数组 $j$。
要求:尽可能满足越多数量的孩子,并求出这个最大数值。
说明:
示例:
输入:g = [1,2,3], s = [1,1]
输出:1
解释:你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1, 2, 3。虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。所以应该输出 1。
输入: g = [1,2], s = [1,2,3]
输出: 2
解释: 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1, 2。你拥有的饼干数量和尺寸都足以让所有孩子满足。所以你应该输出 2。
为了尽可能的满⾜更多的⼩孩,而且一块饼干不能掰成两半,所以我们应该尽量让胃口小的孩子吃小块饼干,这样胃口大的孩子才有大块饼干吃。
所以,从贪心算法的角度来考虑,我们应该按照孩子的胃口从小到大对数组 $g$ 进行排序,然后按照饼干的尺寸大小从小到大对数组 $s$ 进行排序,并且对于每个孩子,应该选择满足这个孩子的胃口且尺寸最小的饼干。
下面我们使用贪心算法三步走的方法解决这道题。
使用贪心算法的代码解决步骤描述如下:
class Solution:
def findContentChildren(self, g: List[int], s: List[int]) -> int:
g.sort()
s.sort()
index_g, index_s = 0, 0
res = 0
while index_g < len(g) and index_s < len(s):
if g[index_g] <= s[index_s]:
res += 1
index_g += 1
index_s += 1
else:
index_s += 1
return res
描述:给定一个区间的集合 $intervals$,其中 $intervals[i] = [starti, endi]$。从集合中移除部分区间,使得剩下的区间互不重叠。
要求:返回需要移除区间的最小数量。
说明:
示例:
输入:intervals = [[1,2],[2,3],[3,4],[1,3]]
输出:1
解释:移除 [1,3] 后,剩下的区间没有重叠。
输入: intervals = [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
这道题我们可以转换一下思路。原题要求保证移除区间最少,使得剩下的区间互不重叠。换个角度就是:「如何使得剩下互不重叠区间的数目最多」。那么答案就变为了:「总区间个数 - 不重叠区间的最多个数」。我们的问题也变成了求所有区间中不重叠区间的最多个数。
从贪心算法的角度来考虑,我们应该将区间按照结束时间排序。每次选择结束时间最早的区间,然后再在剩下的时间内选出最多的区间。
我们用贪心三部曲来解决这道题。
使用贪心算法的代码解决步骤描述如下:
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
if not intervals:
return 0
intervals.sort(key=lambda x: x[1])
end_pos = intervals[0][1]
count = 1
for i in range(1, len(intervals)):
if end_pos <= intervals[i][0]:
count += 1
end_pos = intervals[i][1]
return len(intervals) - count
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







