

代码拉取完成,页面将自动刷新
[TOC]
This section describes InnoDB in-memory structures and related topics.
本文详细介绍InnoDB在内存中的存储结构, 以及相关的模型。
The buffer pool is an area in main memory where InnoDB caches table and index data as it is accessed. The buffer pool permits frequently used data to be processed directly from memory, which speeds up processing. On dedicated servers, up to 80% of physical memory is often assigned to the buffer pool.
For efficiency of high-volume read operations, the buffer pool is divided into pages that can potentially hold multiple rows. For efficiency of cache management, the buffer pool is implemented as a linked list of pages; data that is rarely used is aged out of the cache using a variation of the LRU algorithm.
Knowing how to take advantage of the buffer pool to keep frequently accessed data in memory is an important aspect of MySQL tuning.
缓冲池是主内存中的一个存储区域, InnoDB用来缓存数据行以及索引。 通过缓冲池可以直接从内存中获取经常使用的数据, 从而加快处理速度。 在专用服务器上, 通常可以将高达80%的物理内存分配给缓冲池。
为了提高大量读操作的性能, 缓冲池分为多个 内存页(page), 每一页可以存储很多行。 为了提高效率, 缓冲池使用链表结构来管理内存页。 使用自定义的 LRU 算法, 将长时间较少使用的数据从缓存中去除。
理解怎样利用缓冲池来将经常访问的数据保留在内存中, 是MySQL优化中的一个重要考点。
The buffer pool is managed as a list using a variation of the least recently used (LRU) algorithm. When room is needed to add a new page to the buffer pool, the least recently used page is evicted and a new page is added to the middle of the list. This midpoint insertion strategy treats the list as two sublists:
缓冲池使用LRU算法(least recently used, 最近最少使用)的变体, 将页面作为列表进行管理。 需要将新页面添加到缓冲池时, 会先驱逐最近最少使用的页面, 然后再将新页面添加到列表的中间(middle)。 这种中点插入策略将整个列表当做两个子列表:

图 14.2 InnoDB缓冲池链表管理机制
The algorithm keeps frequently used pages in the new sublist. The old sublist contains less frequently used pages; these pages are candidates for eviction.
By default, the algorithm operates as follows:
InnoDB reads a page into the buffer pool, it initially inserts it at the midpoint (the head of the old sublist). A page can be read because it is required for a user-initiated operation such as an SQL query, or as part of a read-ahead operation performed automatically by InnoDB.LRU算法将常用的页面保留在新页面的子列表中。 旧页面的子列表包含不常用的页面; 这些旧页面是 逐出(eviction) 的候选页面。
默认情况下, 这种算法的运行方式如下:
By default, pages read by queries are immediately moved into the new sublist, meaning they stay in the buffer pool longer. A table scan, performed for a mysqldump operation or a SELECT statement with no WHERE clause, for example, can bring a large amount of data into the buffer pool and evict an equivalent amount of older data, even if the new data is never used again. Similarly, pages that are loaded by the read-ahead background thread and accessed only once are moved to the head of the new list. These situations can push frequently used pages to the old sublist where they become subject to eviction. For information about optimizing this behavior, see Section 14.8.3.3, “Making the Buffer Pool Scan Resistant”, and Section 14.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”.
InnoDB Standard Monitor output contains several fields in the BUFFER POOL AND MEMORY section regarding operation of the buffer pool LRU algorithm. For details, see Monitoring the Buffer Pool Using the InnoDB Standard Monitor.
默认情况下, 查询读取的页面会立即移入新页面子列表, 这意味着它们在缓冲池中的停留时间更长。 对 mysqldump 操作或不带 WHERE 子句的SELECT语句执行的全表扫描, 会将大量数据带入缓冲池, 并逐出同等数量的旧数据, 即使新数据不再使用。 同样, 由后台的预读线程加载且仅访问一次的页面也会移至新列表的开头。 这种情况可能会将常用页面推到旧列表中, 导致被逐出。关于这种行为的优化, 请参考 Section 14.8.3.3, “Making the Buffer Pool Scan Resistant”, 和 Section 14.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”。
InnoDB Standard Monitor 会在 BUFFER POOL AND MEMORY 部分的输出中, 包含缓冲池LRU算法相关的操作信息。 更多详细信息, 请参考 Monitoring the Buffer Pool Using the InnoDB Standard Monitor。
You can configure the various aspects of the buffer pool to improve performance.
InnoDB acts like an in-memory database, reading data from disk once and then accessing the data from memory during subsequent reads. See Section 14.8.3.1, “Configuring InnoDB Buffer Pool Size”.InnoDB preserves the current buffer pool state to avoid a lengthy warmup period after a server restart. For details, see Section 14.8.3.6, “Saving and Restoring the Buffer Pool State”.我们可以从多个维度配置缓冲池, 以提升InnoDB的性能.
InnoDB Standard Monitor output, which can be accessed using SHOW ENGINE INNODB STATUS, provides metrics regarding operation of the buffer pool. Buffer pool metrics are located in the BUFFER POOL AND MEMORY section of InnoDB Standard Monitor output and appear similar to the following:
使用 SHOW ENGINE INNODB STATUS 命令可以获取 InnoDB Standard Monitor 的输出, 其中包含了缓冲池相关的指标信息。
缓冲池指标位于 BUFFER POOL AND MEMORY 这部分, 大致类似于下面这样:
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 22355640320
Dictionary memory allocated 15517867
Internal hash tables (constant factor + variable factor)
Adaptive hash index 342600512 (339961792 + 2638720)
Page hash 2656792 (buffer pool 0 only)
Dictionary cache 100508315 (84990448 + 15517867)
File system 4375120 (812272 + 3562848)
Lock system 53203640 (53125256 + 78384)
Recovery system 0 (0 + 0)
Buffer pool size 1310560
Buffer pool size, bytes 21472215040
Free buffers 8192
Database pages 1302209
Old database pages 480533
Modified db pages 125
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 47795, not young 843770
0.00 youngs/s, 0.00 non-youngs/s
Pages read 134869, created 1313756, written 162255077
0.00 reads/s, 0.00 creates/s, 1.47 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1302209, unzip_LRU len: 0
I/O sum[728]:cur[0], unzip sum[0]:cur[0]
The following table describes buffer pool metrics reported by the InnoDB Standard Monitor.
Note
Per second averages provided in
InnoDBStandard Monitor output are based on the elapsed time sinceInnoDBStandard Monitor output was last printed.
下面对这些指标进行解读。
注意
InnoDBStandard Monitor 输出中的每秒平均数值信息, 是基于上次打印之后经过的时间来计算的。
表 14.2 InnoDB Buffer Pool 指标解读
| 指标名称 | 说明 |
|---|---|
| Total memory allocated | 缓冲池总共分配的内存字节数. |
| Dictionary memory allocated |
InnoDB数据字典分配的总内存字节数. |
| Buffer pool size | 分配给缓冲池的页面总数量. |
| Free buffers | 缓冲池列表中的空闲页面数. |
| Database pages | 缓冲池 LRU 列表中的页面总数. |
| Old database pages | 缓冲池中, 老的 LRU 列表中的页面总数. |
| Modified db pages | 当前缓冲池中被修改过的页面数量. |
| Pending reads | 等待读取到缓冲池中的页面数量. |
| Pending writes LRU | 缓冲池中,位于LRU列表底部, 等待写入磁盘的脏页数量. |
| Pending writes flush list | 要刷数据的缓冲池页面数量. |
| Pending writes single page | 缓冲池中待写入处理的独立页面数量. |
| Pages made young | 缓冲池LRU列表中变为新页的数量(移动到 “new” 子列表头部). |
| Pages made not young | 缓冲池LRU列表中没有变为新页的数量(依然在 “old” 子列表中). |
| youngs/s | 每秒访问缓冲池LRU列表中“old”页面次数的平均频率, 导致这些页面变新。详情参考下文. |
| non-youngs/s | 每秒访问缓冲池LRU列表中“old”页面次数的平均频率, 没有导致这些页面变新。详情参考下文. |
| Pages read | 从缓冲池中读取的总页数. |
| Pages created | 在缓冲池中创建的总页数. |
| Pages written | 从缓冲池中写出去的总页数. |
| reads/s | 每秒从缓冲池中读取的页数平均值. |
| creates/s | 每秒创建的缓冲池中页数平均值. |
| writes/s | 每秒从缓冲池中写出去的页数平均值. |
| Buffer pool hit rate | 缓冲池命中率 = 从缓冲池读取的页数 / 直接从磁盘读取的页数. |
| young-making rate | 导致页面变新的平均命中率. 详情参考下文. |
| not (young-making rate) | 没有导致页面变新的平均命中率. 详情参考下文. |
| Pages read ahead | 平均每秒预读取操作的数量. |
| Pages evicted without access | 平均每秒因为没有读取操作而从缓冲池中驱逐的页面数量. |
| Random read ahead | 平均每秒随机预读取操作的数量. |
| LRU len | 缓冲池LRU列表中的页面总数. |
| unzip_LRU len | 缓冲池unzip_LRU列表中的页面总数. |
| I/O sum | 缓冲池LRU列表中, 最近 50 秒, 被读取/写入的页面次数. |
| I/O cur | 缓冲池LRU列表中, 当前被读取/写入的页面次数. |
| I/O unzip sum | 缓冲池unzip_LRU列表中, 被读取/写入的页面总次数. |
| I/O unzip cur | 缓冲池unzip_LRU列表中, 当前被读取/写入的页面次数. |
Notes:
youngs/s metric is applicable only to old pages. It is based on the number of accesses to pages and not the number of pages. There can be multiple accesses to a given page, all of which are counted. If you see very low youngs/s values when there are no large scans occurring, you might need to reduce the delay time or increase the percentage of the buffer pool used for the old sublist. Increasing the percentage makes the old sublist larger, so pages in that sublist take longer to move to the tail, which increases the likelihood that those pages are accessed again and made young.non-youngs/s metric is applicable only to old pages. It is based on the number of accesses to pages and not the number of pages. There can be multiple accesses to a given page, all of which are counted. If you do not see a higher non-youngs/s value when performing large table scans (and a higher youngs/s value), increase the delay value.young-making rate accounts for accesses to all buffer pool pages, not just accesses to pages in the old sublist. The young-making rate and not rate do not normally add up to the overall buffer pool hit rate. Page hits in the old sublist cause pages to move to the new sublist, but page hits in the new sublist cause pages to move to the head of the list only if they are a certain distance from the head.not (young-making rate) is the average hit rate at which page accesses have not resulted in making pages young due to the delay defined by innodb_old_blocks_time not being met, or due to page hits in the new sublist that did not result in pages being moved to the head. This rate accounts for accesses to all buffer pool pages, not just accesses to pages in the old sublist.Buffer pool server status variables and the INNODB_BUFFER_POOL_STATS table provide many of the same buffer pool metrics found in InnoDB Standard Monitor output. For more information, see Example 14.10, “Querying the INNODB_BUFFER_POOL_STATS Table”.
注意:
youngs/s 指标仅适用于旧页面。它基于对页面的访问次数, 而不是页面数。对给定页面可能会有多次访问, 所有访问都计入在内。如果没有发生大型的全表扫描时, 看到的 youngs/s 数值很低, 可能需要降低移到旧页面子列表的延迟时间, 或者增加旧页面子列表所占的缓冲池百分比。 增加百分比会使旧页面子列表变大, 因此该子列表中的页面需要更长的时间才能移到尾部, 这增加了再次访问这些页面并使它们变年轻的可能性。non-youngs/s 指标仅适用于旧页面。它基于对页面的访问次数, 而不是页面数。对给定页面可能会有多次访问, 所有访问都计入在内。如果没有发生大型的全表扫描, 或者youngs/s很大, 但是 non-youngs/s 的值却不高, 那么我们需要增加延迟值。young-making 频率用于统计所有对缓冲池页面的访问次数, 而不仅仅是对旧页面子列表的页面访问次数。 young-making 频率和 not 频率通常不加到整个缓冲池的总命中率。命中旧页面子列表中的页面, 会导致页面被移动到新页面子列表中, 但命中新页面子列表中的页面时, 只有页面与列表头部保持一定距离时才会被移动到列表头部。not (young-making rate) 是一个平均速率, 原因是由于不满足 innodb_old_blocks_time, 或者由于命中了新页面子列表却没有让页面移动到头部。 此速率统计了对所有缓冲池页面的访问, 而不仅仅是对旧页面子列表中页面的访问。缓冲池server status variables和 INNODB_BUFFER_POOL_STATS表提供了许多与 InnoDB Standard Monitor 输出中相同的缓冲池指标。 更多信息请参考 Example 14.10, “Querying the INNODB_BUFFER_POOL_STATS Table”。
The change buffer is a special data structure that caches changes to secondary index pages when those pages are not in the buffer pool. The buffered changes, which may result from INSERT, UPDATE, or DELETE operations (DML), are merged later when the pages are loaded into the buffer pool by other read operations.
写缓冲(Change Buffer)是一种特殊的数据结构, 当 二级索引(secondary index) 页的更改不在buffer pool之中时。 缓冲的更改可能是由于INSERT, UPDATE, or DELETE 等DML操作, 后续通过其他读取操作将页面加载到缓冲池中时, 它们将会被合并。
Figure 14.3 Change Buffer
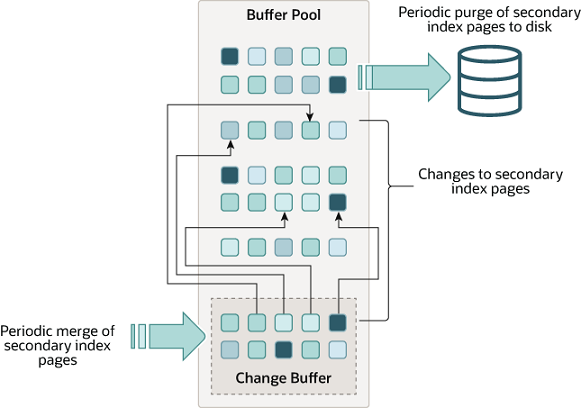
Unlike clustered indexes, secondary indexes are usually nonunique, and inserts into secondary indexes happen in a relatively random order. Similarly, deletes and updates may affect secondary index pages that are not adjacently located in an index tree. Merging cached changes at a later time, when affected pages are read into the buffer pool by other operations, avoids substantial random access I/O that would be required to read secondary index pages into the buffer pool from disk.
与聚集索引(clustered indexes)不同, 二级索引(secondary indexes) 一般都不是唯一约束, 并且会以相对随机的顺序添加到二级索引中。 同样, 删除和更新操作也会影响索引树中不相邻的二级索引页。 当后续的操作将受影响的页读入缓冲池, 则会合并缓存的变更, 避免了从磁盘上将二级索引页读入缓冲池所需的大量随机I/O。
Periodically, the purge operation that runs when the system is mostly idle, or during a slow shutdown, writes the updated index pages to disk. The purge operation can write disk blocks for a series of index values more efficiently than if each value were written to disk immediately.
Change buffer merging may take several hours when there are many affected rows and numerous secondary indexes to update. During this time, disk I/O is increased, which can cause a significant slowdown for disk-bound queries. Change buffer merging may also continue to occur after a transaction is committed, and even after a server shutdown and restart (see Section 14.22.2, “Forcing InnoDB Recovery” for more information).
在系统比较空闲时, 会定期运行清除操作(purge operation), 把更新的索引页写入磁盘, 或者在缓慢关机期间也会执行。 清除操作将索引值批量写入磁盘, 比起每次变化都立刻刷新, 效率要高很多。
当受影响的行太多, 需要更新的二级索引数据量很大时, 写缓冲的合并可能要消耗很多个小时。 在此期间, 磁盘 I/O 会增加, 这可能会导致有磁盘读取的查询操作的执行速度明显变慢。 事务提交之后, 甚至在服务器关闭并重新启动之后, 写缓冲的合并都有可能持续发生( 更多信息请参考 Section 14.22.2, “Forcing InnoDB Recovery” )。
In memory, the change buffer occupies part of the buffer pool. On disk, the change buffer is part of the system tablespace, where index changes are buffered when the database server is shut down.
The type of data cached in the change buffer is governed by the innodb_change_buffering variable. For more information, see Configuring Change Buffering. You can also configure the maximum change buffer size. For more information, see Configuring the Change Buffer Maximum Size.
Change buffering is not supported for a secondary index if the index contains a descending index column or if the primary key includes a descending index column.
For answers to frequently asked questions about the change buffer, see Section A.16, “MySQL 5.7 FAQ: InnoDB Change Buffer”.
在内存中, 写缓冲占用了缓冲池的一部分内存空间。 在磁盘上, 写缓冲是系统表空间的一部分,当数据库服务器关闭时,索引的变更会存储在里面。
写缓冲中缓存的数据类型由 innodb_change_buffering 变量控制。 更多信息请参考 Configuring Change Buffering。
我们还可以设置写缓冲的最大空间。 更多信息请参考 Configuring the Change Buffer Maximum Size。
如果主键索引或者二级索引包含降序的索引列,则二级索引不支持写缓冲操作。
有关写缓冲的常见问题和答案,请参考 Section A.16, “MySQL 5.7 FAQ: InnoDB Change Buffer”。
When INSERT, UPDATE, and DELETE operations are performed on a table, the values of indexed columns (particularly the values of secondary keys) are often in an unsorted order, requiring substantial I/O to bring secondary indexes up to date. The change buffer caches changes to secondary index entries when the relevant page is not in the buffer pool, thus avoiding expensive I/O operations by not immediately reading in the page from disk. The buffered changes are merged when the page is loaded into the buffer pool, and the updated page is later flushed to disk. The InnoDB main thread merges buffered changes when the server is nearly idle, and during a slow shutdown.
Because it can result in fewer disk reads and writes, the change buffer feature is most valuable for workloads that are I/O-bound, for example applications with a high volume of DML operations such as bulk inserts.
对某个表执行 INSERT,UPDATE 和 DELETE 操作时,索引列(尤其是二级索引)的值通常是处于未排序的顺序, 这需要大量的 I/O 操作才能使二级索引保持最新状态。
如果相关的page不在缓冲池之中, 则MySQL可以使用写缓冲(change buffer)将二级索引的变更缓存起来,这样就不必立即从磁盘上读取页面, 避免了高负载时期大量昂贵的I/O操作。
当新页面加载到缓冲池时, 会合并相应的写缓冲,更新的页面随后会被刷新到磁盘。
InnoDB主线程在服务器接近空闲时合并缓冲的更改, 在slow shutdown 期间也会执行。
由于写缓冲可以减少磁盘读写操作,因此对于受I/O约束的任务最有价值(比如具有批量插入之类的大量DML操作的应用)。
However, the change buffer occupies a part of the buffer pool, reducing the memory available to cache data pages. If the working set almost fits in the buffer pool, or if your tables have relatively few secondary indexes, it may be useful to disable change buffering. If the working data set fits entirely within the buffer pool, change buffering does not impose extra overhead, because it only applies to pages that are not in the buffer pool.
但是,写缓冲占用了缓冲池的一部分空间,也就减少了可用于缓存数据页的内存。 如果工作集跟缓冲池差不多大小,或者二级索引相对较少,则禁用写缓冲可能性能更好。 如果缓冲池完全足够放下工作数据集,则写缓冲不会带来额外的开销,因为它只适用于不在缓冲池中的那些页面。
You can control the extent to which InnoDB performs change buffering using the innodb_change_buffering configuration parameter. You can enable or disable buffering for inserts, delete operations (when index records are initially marked for deletion) and purge operations (when index records are physically deleted). An update operation is a combination of an insert and a delete. The default innodb_change_buffering value is all.
Permitted innodb_change_buffering values include:
我们可以使用参数 innodb_change_buffering 来控制 InnoDB 使用多少比例的写缓冲。
可以为 insert, delete 操作(最初将索引记录标记为删除)和 purge 操作(从物理上删除索引记录时)启用或禁用缓冲。 update操作则是 insert 和 delete 的组合。 innodb_change_buffering的默认值为all。
允许的innodb_change_buffering取值包括:
all The default value: buffer inserts, delete-marking operations, and purges.
none Do not buffer any operations.
inserts Buffer insert operations.
deletes Buffer delete-marking operations.
changes Buffer both inserts and delete-marking operations.
purges Buffer physical deletion operations that happen in the background.
You can set the innodb_change_buffering parameter in the MySQL option file (my.cnf or my.ini) or change it dynamically with the SET GLOBAL statement, which requires privileges sufficient to set global system variables. See Section 5.1.8.1, “System Variable Privileges”. Changing the setting affects the buffering of new operations; the merging of existing buffered entries is not affected.
all 默认值:缓冲区插入,删除(标记)操作和清除。
none 不缓冲任何操作。
inserts 缓冲插入操作。
deletes 缓冲删除(标记)操作。
changes 缓冲插入和删除(标记)操作。
purges 缓冲在后台发生的物理删除操作。
您可以在MySQL配置文件(my.cnf or my.ini)中设置innodb_change_buffering参数。
也可以使用 SET GLOBAL 语句来动态更改参数值,执行该语句需要具有设置全局系统变量的权限才能执行。 请参考Section 5.1.8.1, “System Variable Privileges”。
更改设置之后会影响新操作的缓冲; 现有缓冲条目的合并不受影响。
The innodb_change_buffer_max_size variable permits configuring the maximum size of the change buffer as a percentage of the total size of the buffer pool. By default, innodb_change_buffer_max_size is set to 25. The maximum setting is 50.
Consider increasing innodb_change_buffer_max_size on a MySQL server with heavy insert, update, and delete activity, where change buffer merging does not keep pace with new change buffer entries, causing the change buffer to reach its maximum size limit.
可以将 innodb_change_buffer_max_size 变量的值设置为总缓冲池的百分比。
默认 innodb_change_buffer_max_size 的值为 25。 允许的最大值是 50。
如果有大量的插入,更新和删除操作, 可能MySQL服务器的写缓冲合并跟不上缓冲区的变更条目,从而导致写缓冲区达到最大限制, 可以考虑加大 innodb_change_buffer_max_size 的比例。
Consider decreasing innodb_change_buffer_max_size on a MySQL server with static data used for reporting, or if the change buffer consumes too much of the memory space shared with the buffer pool, causing pages to age out of the buffer pool sooner than desired.
Test different settings with a representative workload to determine an optimal configuration. The innodb_change_buffer_max_size setting is dynamic, which permits modifying the setting without restarting the server.
如果MySQL服务器主要主要用于报表分析, 存储的是静态数据,或者写缓冲区消耗了太多的内存空间, 挤占了缓冲池,导致页面比预期值更快地过期,可以考虑减小 innodb_change_buffer_max_size。
请使用具有代表性的工作负载强度来测试不同配置,以确定最佳配置。 innodb_change_buffer_max_size 的值可以动态修改,也就是可以在不重启服务器的情况下改变写缓冲的比例。
The following options are available for change buffer monitoring:
InnoDB Standard Monitor output includes change buffer status information. To view monitor data, issue the SHOW ENGINE INNODB STATUS statement.下面的方式可用于监控写缓冲区:
InnoDB Standard Monitor 的输出内容中包含了写缓冲区的状态信息。 要查看监控数据,请执行 SHOW ENGINE INNODB STATUS 语句。mysql> SHOW ENGINE INNODB STATUS\G
Change buffer status information is located under the INSERT BUFFER AND ADAPTIVE HASH INDEX heading and appears similar to the following:
写缓冲区的状态信息位于 INSERT BUFFER AND ADAPTIVE HASH INDEX 标题下,大致长这样:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 4425293, used cells 32, node heap has 1 buffer(s)
13577.57 hash searches/s, 202.47 non-hash searches/s
For more information, see Section 14.18.3, “InnoDB Standard Monitor and Lock Monitor Output”.
有关信息,请参考 Section 14.18.3, “InnoDB Standard Monitor and Lock Monitor Output”。
INFORMATION_SCHEMA.INNODB_METRICS table provides most of the data points found in InnoDB Standard Monitor output, plus other data points. To view change buffer metrics and a description of each, issue the following query:INFORMATION_SCHEMA.INNODB_METRICS 表提供了大部分 InnoDB Standard Monitor 的输出内容,以及其他数据点。 要查看写缓冲区的指标以及每个指标的说明信息,请执行以下查询:mysql> SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME LIKE '%ibuf%'\G
For INNODB_METRICS table usage information, see Section 14.16.6, “InnoDB INFORMATION_SCHEMA Metrics Table”.
有关 INNODB_METRICS 表的使用信息,请参考 Section 14.16.6, “InnoDB INFORMATION_SCHEMA Metrics Table”。
INFORMATION_SCHEMA.INNODB_BUFFER_PAGE table provides metadata about each page in the buffer pool, including change buffer index and change buffer bitmap pages. Change buffer pages are identified by PAGE_TYPE. IBUF_INDEX is the page type for change buffer index pages, and IBUF_BITMAP is the page type for change buffer bitmap pages.INFORMATION_SCHEMA.INNODB_BUFFER_PAGE 表提供了 缓冲池中每个页面的元数据信息, 包括写缓冲区索引和写缓冲区位图页面。 写缓冲区页面由 PAGE_TYPE 标识。 IBUF_INDEX 是写缓冲区索引页面的页面类型,而 IBUF_BITMAP 是写缓冲区位图页面的页面类型。Warning
Querying the INNODB_BUFFER_PAGE table can introduce significant performance overhead. To avoid impacting performance, reproduce the issue you want to investigate on a test instance and run your queries on the test instance.
For example, you can query the INNODB_BUFFER_PAGE table to determine the approximate number of IBUF_INDEX and IBUF_BITMAP pages as a percentage of total buffer pool pages.
警告
查询 INNODB_BUFFER_PAGE 表会带来巨大的性能开销。 为避免影响性能,请在测试环境中模拟要排查的问题,然后在测试机器上执行查询。
例如,可以查询 INNODB_BUFFER_PAGE 表来确定 IBUF_INDEX 和 IBUF_BITMAP 页面的数量占缓冲池页面总数的近似百分比。
mysql> SELECT (SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE PAGE_TYPE LIKE 'IBUF%') AS change_buffer_pages,
(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,
(SELECT ((change_buffer_pages/total_pages)*100))
AS change_buffer_page_percentage;
+---------------------+-------------+-------------------------------+
| change_buffer_pages | total_pages | change_buffer_page_percentage |
+---------------------+-------------+-------------------------------+
| 25 | 8192 | 0.3052 |
+---------------------+-------------+-------------------------------+
For information about other data provided by the INNODB_BUFFER_PAGE table, see Section 23.32.1, “The INFORMATION_SCHEMA INNODB_BUFFER_PAGE Table”. For related usage information, see Section 14.16.5, “InnoDB INFORMATION_SCHEMA Buffer Pool Tables”.
有关 INNODB_BUFFER_PAGE 表提供的其他数据,请参考 Section 23.32.1, “The INFORMATION_SCHEMA INNODB_BUFFER_PAGE Table”。 相关信息的用法,请参考Section 14.16.5, “InnoDB INFORMATION_SCHEMA Buffer Pool Tables”。
mysql> SELECT * FROM performance_schema.setup_instruments
WHERE NAME LIKE '%wait/synch/mutex/innodb/ibuf%';
+-------------------------------------------------------+---------+-------+
| NAME | ENABLED | TIMED |
+-------------------------------------------------------+---------+-------+
| wait/synch/mutex/innodb/ibuf_bitmap_mutex | YES | YES |
| wait/synch/mutex/innodb/ibuf_mutex | YES | YES |
| wait/synch/mutex/innodb/ibuf_pessimistic_insert_mutex | YES | YES |
+-------------------------------------------------------+---------+-------+
For information about monitoring InnoDB mutex waits, see Section 14.17.2, “Monitoring InnoDB Mutex Waits Using Performance Schema”.
有关 InnoDB 互斥锁等待的监控信息,请参考 Section 14.17.2, “Monitoring InnoDB Mutex Waits Using Performance Schema”。
The adaptive hash index feature enables InnoDB to perform more like an in-memory database on systems with appropriate combinations of workload and sufficient memory for the buffer pool without sacrificing transactional features or reliability. The adaptive hash index feature is enabled by the innodb_adaptive_hash_index variable, or turned off at server startup by --skip-innodb-adaptive-hash-index.
Based on the observed pattern of searches, a hash index is built using a prefix of the index key. The prefix can be any length, and it may be that only some values in the B-tree appear in the hash index. Hash indexes are built on demand for the pages of the index that are accessed often.
If a table fits almost entirely in main memory, a hash index can speed up queries by enabling direct lookup of any element, turning the index value into a sort of pointer. InnoDB has a mechanism that monitors index searches. If InnoDB notices that queries could benefit from building a hash index, it does so automatically.
自适应哈希索引,在具有足够的缓冲池内存的系统中, 可以使InnoDB在一定的工作负载强度下, 具有像内存数据库一样的性能, 而不会牺牲事务功能或可靠性。 通过系统变量 innodb_adaptive_hash_index 开启自适应哈希索引功能,或在服务器启动时通过 --skip-innodb-adaptive-hash-index 参数关闭。
根据观察到的搜索模式,使用索引key的前缀来构建哈希索引。 前缀可以是任何长度,也可以是哈希索引 B-tree 中的某些值。 哈希索引是根据对经常访问的索引页面的需求而建立的。
如果一个表基本上能整个放到内存中,则哈希索引可以通过启用直接查找任何元素的功能来加速查询,从而将索引值转换为某种指针。 InnoDB具有监控索引搜索的机制。如果InnoDB注意到查询可以从建立哈希索引中受益,则会自动创建。
With some workloads, the speedup from hash index lookups greatly outweighs the extra work to monitor index lookups and maintain the hash index structure. Access to the adaptive hash index can sometimes become a source of contention under heavy workloads, such as multiple concurrent joins. Queries with LIKE operators and % wildcards also tend not to benefit. For workloads that do not benefit from the adaptive hash index feature, turning it off reduces unnecessary performance overhead. Because it is difficult to predict in advance whether the adaptive hash index feature is appropriate for a particular system and workload, consider running benchmarks with it enabled and disabled. Architectural changes in MySQL 5.6 make it more suitable to disable the adaptive hash index feature than in earlier releases.
在某些工作负载下,哈希索引查找的速度大大超过了对索引查找进行监控和维护哈希索引结构的额外工作。 在繁重的工作负载(例如大量并发连接)情况下,访问自适应哈希索引有时可能会成为争用的源。 带有 LIKE 运算符和 % 通配符的查询也往往不会受益。
对于无法从自适应哈希索引功能中受益的工作负载,将其关闭可减少不必要的性能开销。
由于很难预先预测自适应哈希索引功能是否适用于特定的系统和工作负载,因此请考虑在启用和禁用情况下运行基准测试。
与以前的版本相比,MySQL 5.6 中的体系结构变更更适合禁用自适应哈希索引功能。
In MySQL 5.7, the adaptive hash index feature is partitioned. Each index is bound to a specific partition, and each partition is protected by a separate latch. Partitioning is controlled by the innodb_adaptive_hash_index_parts variable. In earlier releases, the adaptive hash index feature was protected by a single latch which could become a point of contention under heavy workloads. The innodb_adaptive_hash_index_parts variable is set to 8 by default. The maximum setting is 512.
在MySQL 5.7中,自适应哈希索引会进行分片。 每个索引都绑定到特定分片,并且每个分片均受单独的 latch 保护。分片由 innodb_adaptive_hash_index_parts 变量控制。 在较早的版本中,自适应哈希索引功能受单个闩锁(latch)保护, 在繁重的工作负载下,该闩锁可能成为争用点。 innodb_adaptive_hash_index_parts 变量的默认设置为8。 允许的最大值为512。
You can monitor adaptive hash index use and contention in the SEMAPHORES section of SHOW ENGINE INNODB STATUS output. If there are numerous threads waiting on RW-latches created in btr0sea.c, consider increasing the number of adaptive hash index partitions or disabling the adaptive hash index feature.
For information about the performance characteristics of hash indexes, see Section 8.3.8, “Comparison of B-Tree and Hash Indexes”.
我们可以在 SHOW ENGINE INNODB STATUS 输出的 SEMAPHORES 部分查看自适应哈希索引的使用和争用情况。 如果有很多线程在 btr0sea.c 中创建的 RW-latches 上等待,请考虑增加自适应哈希索引的分片数量, 或者禁用自适应哈希索引功能。
有关哈希索引的性能特征,请参考 Section 8.3.8, “Comparison of B-Tree and Hash Indexes”。
The log buffer is the memory area that holds data to be written to the log files on disk. Log buffer size is defined by the innodb_log_buffer_size variable. The default size is 16MB. The contents of the log buffer are periodically flushed to disk. A large log buffer enables large transactions to run without the need to write redo log data to disk before the transactions commit. Thus, if you have transactions that update, insert, or delete many rows, increasing the size of the log buffer saves disk I/O.
The innodb_flush_log_at_trx_commit variable controls how the contents of the log buffer are written and flushed to disk. The innodb_flush_log_at_timeout variable controls log flushing frequency.
For related information, see Memory Configuration, and Section 8.5.4, “Optimizing InnoDB Redo Logging”.
日志缓冲区(Log Buffer)是用于保存即将写入磁盘的日志文件数据的存储区域。 日志缓冲区的大小由系统变量 innodb_log_buffer_size 指定。 默认大小为 16MB。 日志缓冲区的内容会定期刷到磁盘。 较大的日志缓冲区, 可以支持比较大型的事务,在事务提交前, 无需将重做日志(redo log)写入磁盘。 因此,如果有更新,插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘I/O。
系统变量 innodb_flush_log_at_trx_commit 控制日志缓冲区的内容写入并刷到磁盘的方式。 innodb_flush_log_at_timeout 变量则控制日志刷新的频率。
更多相关信息,请参考 内存配置 章节和 Section 8.5.4, “Optimizing InnoDB Redo Logging”。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







