

代码拉取完成,页面将自动刷新
String类型是二进制安全的。
原子加减
SETNX product:10001 true //返回1代表获取锁成功 返回0代表获取锁失败
SET product:10001 true expire 10 seconds//防止程序意外终止而导致死锁
INCR article:readcount:id
redis是个单线程应用程序 这样不会导致高并发的脏读,主从的redis 在后面会使用分布式锁,一般单体的redis并发量在9-10万左右
原理是把原有的tomcat存储用户信息转为redis 把用户的信息 序列化后 存入redis
INCRBY orderId 1000 //redis 批量生产订单id提示性能
如项目使用 分库分表 ,就可以使用这个 ,目的是让主键ID 在都是唯一的 ,这个在实际场景非常重要
是一个Mapmap,指值本身又是一种键值对结构
添加商品 hset cart:userid goodsId 1
删除商品 hdel cart:userid goodsId
添加商品数量 hincyby cart:userid goodsId 1
商品总数 hlen cart:userid
获取购物车全部商品 hgetall cart:userId
同类数据归类整合储存,方便数据管理
相比string操作消耗内存与cpu更小
相比string储存更节省空间
过期功能不支持到field,只能作用到key上
redis集群架构不适合大规模使用
hash的会分配槽位,集群中 会导致数据过于集中,没办法做分片。
链表(redis 使用双端链表实现的 List),是有序的,value可以重复,可以通过下标取出对应的value值,左右两边都能进行插入和删除数据。
L-------------------------->R
**正序:**0 N
逆序 :-N -1
常用数据结构:
Statck: LPUSH+LPOP=FIFO
QUEUE: LPUSH+RPOP
Blocking QUEUE:LPUSH+BRPOP
说明:
常用命令:
运算命令:
SADD key userId 将用户id添加进抽奖列表中
SMEMBERS key 查看抽奖用户列表
SRANDMEMBER key count /SPOP key count 随机获取count个用户id
点赞:SADD like:消息ID 用户id
取消点赞 SREM liek:消息ID 用户ID
是否点赞 SISREMBER like:消息ID 用户ID
获取点赞用户列表 SREMEBER like:消息ID
获取点赞用户量 SCARD like:消息ID
1.你关注的人
set guanzhu:我的id {张三、李四、王五、小明、程咬金}
2.小明关注的人
set guanzhu:小明的id {张三、赵六、尼古拉斯}
3.程咬金关注的人
set guanzhu:程咬金的id {小明、李四}
4.我和小明的共同关注:
SINTER guanzhu:我的id guanzhu:小明的id
得到就是 张三
5.我关注的人也在关注他 【我关注的某人 否也关注小明】
SISMEMBER guanzhu:程咬金的id 小明的ID
SISMEMBER guanzhu:张三的id 小明的ID
SISMEMBER //判断 member 元素是否是集合 key 的成 员
6.我可能认识的人
SDIFF guanzhu:小明的id 我的ID
zset是一个有序集合,靠score来排序,允许score重复
常用命令:
zadd key score member 添加元素
zadd myzset 10 v1
zrange key start stop 查看区间元素 (0,-1全部元素)
zrange myzset 0 -1
zrangebyscore key min max 查看分数为min-max之间的value(只显示值),加上"("标识不包括,"+inf"标识无限制
zrangebyscore zset 9 10
zrangebyscore zset (9 10
zrangebyscore zset 9 +inf
zrangebyscore key min max withscores 显示值附带分数
zrangebyscore zset 9 10 withscores
zrem key value value... 删除一个或多个元素
zrem myzset v1 v2
zscard key 查看key中个数
zincryby key score value 增减元素的score
zincyby myzset 20 v1 -> score+20
zcount key score(start) score(stop) 获取分数之间的元素
zcount myzset 10 20
zrank key rember 获取rember的下标
zrank myzset v1
以时间戳为key,文章id为member,点击量或浏览量作为score储存,实现排行榜
以用户ID为key 文章id为member 回复加1
AOF通过保存Redis服务器的执行的写命令来记录数据库状态。redis服务的写命令会被写入OS Cache,每隔1s调用操作系统的fsync命令写入AOF。
redis内存文件(日志文件)是一定大的,但AOF文件是无限追加的,只有写命令就会写入AOF文件。
解决方案:AOF有rewrite。当AOF文件大小达到一定大小时,就会基于当时redis内存数据重新构建一份更加小的AOF文件,替换旧的数据。
*流程:*
appendonly yes
AOF持久化,默认是关闭的,默认是打开RDB持久化,AOF和RDB都开启了,redis重启的时候,也是优先通过AOF进行数据恢复的,因为AOF数据比较完整
appendfsync always
appendfsync everysec
appendfsync no
AOF文件膨胀到配置大小界限,触发AOF文件rewrite的命令BGREWEITEAOF。
redis进程fork一个子进程,基于redis当前的内存结构,构建新的AOF文件。
在构建新的AOF文件与旧的AOF文件没有任何关系,是基于当前redis内存数据结构,并且会对写入命令进程重构,如:多条同一个键的写入重构成一条命令。
在rewrite期间,redis会继续接受新的写入命令,并把他们缓存在重新缓存区中。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
RDB是redis按规定时间生成的内存数据快照,在redis启动时,会自动读取rdb文件还原数据,默认是开启的。新生成的RDB文件会将旧的文件替换掉,
//默认配置
save 900 1
save 300 10
save 60 10000
save n m //服务器在n秒内至少进行了m次修改(读不算)
当redis服务启动时,会读取redis.config配置文件信息,将多个配置读入saveparam的数组中。该数组为redisServer结构的saveparams属性对应上。结构如下
redisServer |saveparams[0] |saveparams[1] |saveparams[2]|
.................... |seconds 900 | seconds 300 | seconds 60 |
saveparams----->|changs 1 | changes 10 | changes 1000|
.......................
redis服务的周期性函数ServerCorn默认每隔100ms就会执行一次,该函数会对运行中的服务进行维护,其中一项工作就是检查save选项设置的保存条件是否满足,满足的会执行bgsave操作。流程如下:
其存储结构主要使用的是Redis的有序结构,其score是GeoHash的52位整数值
127.0.0.1:6379> ZRANGE city 0 -1 WITHSCORES
1) "hangzhou"
2) "4054134257390783"
3) "shanghai"
4) "4054803462927619"
5) "beijing"
6) "4069885360207904"
其原理比较容易理解,核心思想就是将球体转换为球面,区块转换为一点:
主要分为三步
详细原理解析可以参考这边文章GeoHash核心原理解析
通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。
Bitmaps本身不是一种数据结构,实际上它就是字符串(key 对应的 value 就是上图中最后的一串二进制),但是它可以对字符串的位进行操作,利用了位运算的高性能。 Bitmaps 单独提供了一套命令,所以在 Redis 中使用 Bitmaps 和使用字符串的方法不太相同。可以把 Bitmaps 想象成一个以 位 为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量
语法:
新增:
SETBIT key offset valuekey不存在时创建,字符串会进行伸展(grown)以确保它可以将 value保存在指定的偏移量上。当字符串值进行伸展时,空白位置以0填充 。offset 参数必须大于或等于 0 ,小于 2^32 (bit 映射被限制在 512 MB 之内)。 对使用大的 offset 的 SETBIT 操作来说,内存分配可能造成 Redis 服务器被阻塞。 返回值:字符串值指定偏移量上原来储存的位(bit)。 示例: // SETBIT 会返回之前位的值(默认是 0)这里会生成126 个位 SETBIT testBit 125 1 (integer) 0 SETBIT testBit 125 0 (integer) 1 SETBIT testBit 125 1 (integer) 0 GETBIT testBit 125 (integer) 1 GETBIT testBit 100 (integer) 0 value 只能是 0 或者 1 二进制只能是0或者1 SETBIT testBit 618 2
(error) ERR bit is not an integer or out of range
Redis 是用 C 语言写的,但是对于Redis的字符串,却不是 C 语言中的字符串(即以空字符’\0’结尾的字符数组),它是自己构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。
SDS 定义
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
SDS存储如图:
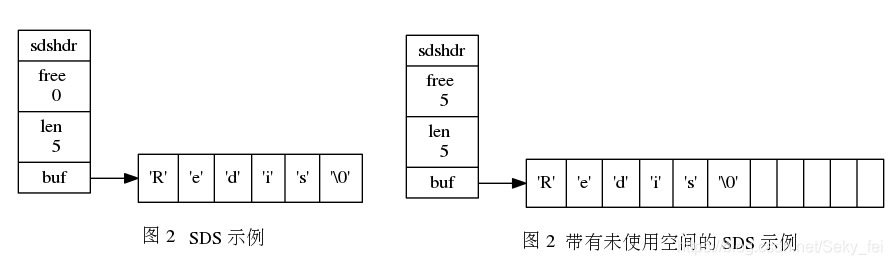
好处:
常数复杂度获取字符串长度:
由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过 strlen key 命令可以获取 key 的字符串长度
杜绝缓冲区溢出:
我们知道在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,由于__内存分配和释放策略__,在进行字符修改的时候,会首先根据记录的 free 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
内存分配释放策略
C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于SDS,由于len属性和free属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:
空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数,
如果对SDS字符串修改后,len的值小于1MB,那么程序会分配和len同样大小的空间给free,此时len和free的值是相同,例如:如果SDS的字符串长度修改为15字节,那么会分配15字节空间给free,SDS的buf属性长度为15(len)+15(free)+1(空字符) = 31字节。
如果SDS字符串修改后,len大于等于1MB,那么程序会分配1MB的空间给free。例如:SDS字符串长度修改为50MB那么程序会分配1MB的未使用空间给free,SDS的buf属性长度为 50MB(len)+1MB(free)+1byte(空字符)
惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 free 属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
链表是一种常用的数据结构,C 语言内部是没有内置这种数据结构的实现,所以Redis自己构建了链表的实现。
链表定义:
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}listNode
通过多个 listNode 结构就可以组成链表,这是一个双向链表,Redis还提供了操作链表的数据结构:
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void (*free) (void *ptr);
//节点值释放函数
void (*free) (void *ptr);
//节点值对比函数
int (*match) (void *ptr,void *key);
}list;

Redis链表特性:
字典又称为符号表或者关联数组、或映射(map),是一种用于保存键值对的抽象数据结构。字典中的每一个键 key 都是唯一的,通过 key 可以对值来进行查找或修改。C 语言中没有内置这种数据结构的实现,所以字典依然是 Redis自己构建的。
Redis 的字典使用哈希表作为底层实现,定义如下:
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht
哈希表是由数组 table 组成,table 中每个元素都是指向 dict.h/dictEntry 结构,dictEntry 结构定义如下:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
key 用来保存键,val 属性用来保存值,值可以是一个指针,也可以是uint64_t整数,也可以是int64_t整数。
注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过next这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
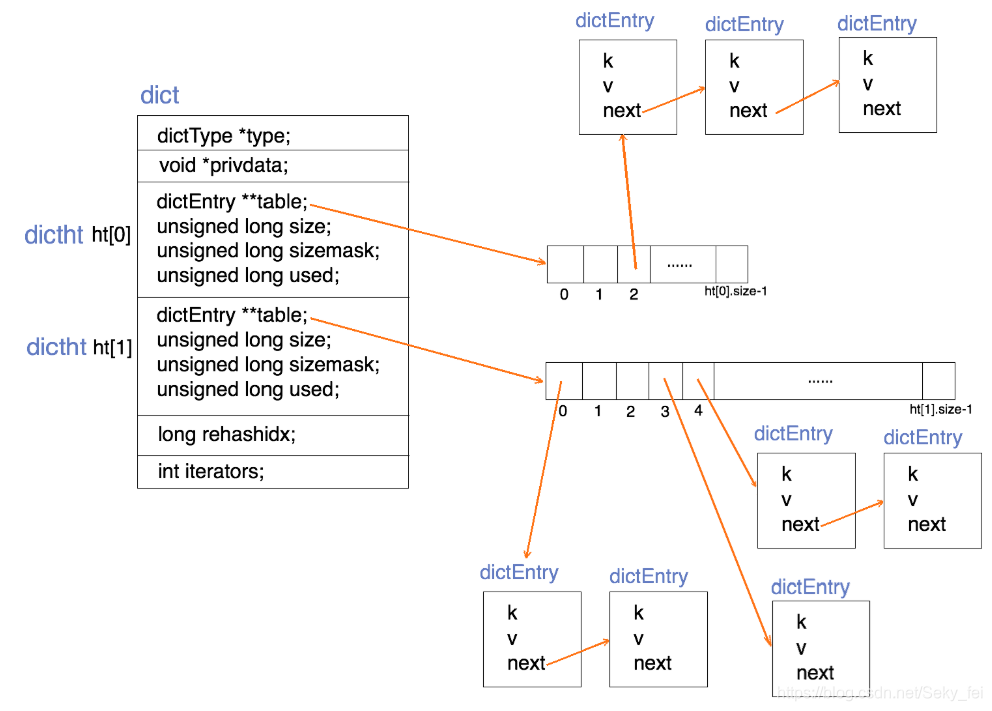
**哈希算法:**Redis计算哈希值和索引值方法如下:
1、使用字典设置的哈希函数,计算键 key 的哈希值
hash = dict->type->hashFunction(key);
2、使用哈希表的sizemask属性和第一步得到的哈希值,计算索引值
index = hash & dict->ht[x].sizemask;
**解决哈希冲突:**这个问题上面我们介绍了,方法是链地址法。通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点.
**扩容和收缩:**跟HashMap一样,当装载因子(load factor)超过预定值时就会进行rehash,但当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
触发扩容的条件:
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
渐近式 rehash
扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。查找效率堪比优化过的二叉平衡树(红黑树),且比平衡树的实现简单,查找单个key,skiplist和平衡树的时间复杂度都为O(log n)。平衡树的插入和删除操作可能引发树的旋转调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。具有如下性质:
由很多层结构组成;
每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
最底层的链表包含了所有的元素;
如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;

而SkipList是基于下图这种的链表设计出来的:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当查找数据的时候,可以先沿着这个新链表(**第一层链表)**进行查找。当碰到比待查数据大的节点时,再回到第二层链表进行查找。比如,要查找23,查找的路径是沿着上图中标红的指针所指向的方向进行的:整个查询路线如红色箭头。
**skiplist正是受这种多层链表的想法的启发而设计出来的,实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。**但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
**skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。**比如:一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。
skiplist中一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。而**节点的层数(level)也不全是没有规则随机的,而是按照节点平均指针数目计算出来的。**如下图各个节点层数(level)是随机出来的一个skiplist,我们依然查找23,查找路径如图:
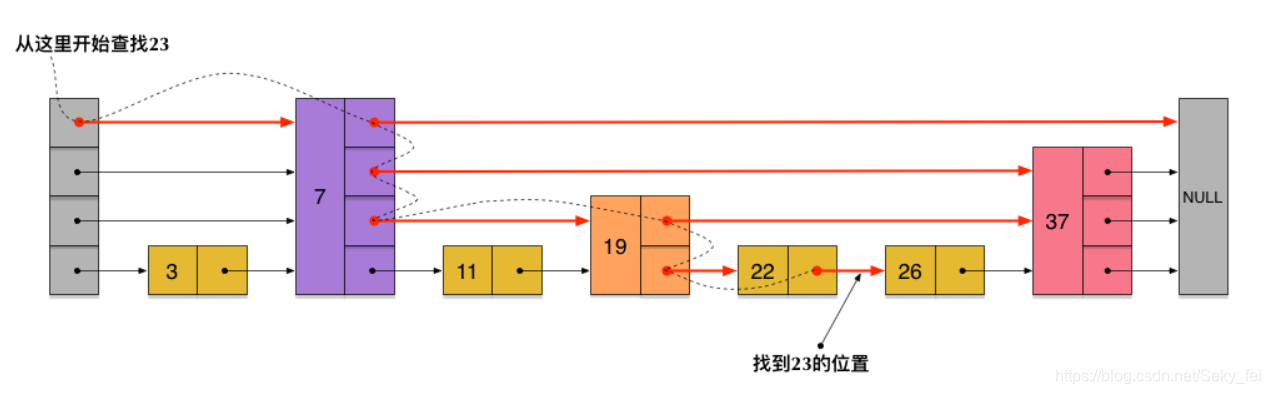
Redis中跳跃表节点定义如下:
typedef struct zskiplistNode {
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
} zskiplistNode
多个跳跃表节点构成一个跳跃表:
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;

skiplist与平衡树、哈希表的比较
intset是Redis集合的底层实现之一,当存储整数集合并且数据量较小的情况下Redis会使用intset作为set的底层实现,当数据量较大或者集合元素为字符串时则会使用dict实现set。
intset的数据结构定义
typedef struct intset {
uint32_t encoding; //intset的类型编码
uint32_t length; //集合包含的元素数量
int8_t contents[]; //保存元素的数组
}
inset数据集合具有以下特点:
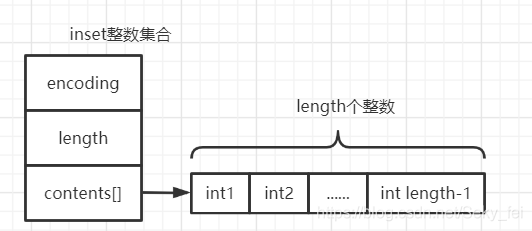
元素升级
当新增的元素类型比原集合元素类型的长度要大时(比如:原来是int16_t,现在新增一个int64_t的元素),需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
注意:升级能极大地节省内存;整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
由于设置缓存时,__key都采用了相同expire__或者__更新策略__或者__数据热点__或者__缓存服务宕机__等原因,可能导致缓存数据同一时刻大规模不可用,或者都更新。 在某一时间内大量key集中失效,在高并发访问时,容易直接达到数据库,使mysql崩溃调
大量请求穿过redis,直接访问mysql,大部分是访问不存在的值,在数据库查询值为null。
是指某一个key非常热点,大量的请求对这个key进行访问,当这个key在失效的瞬间,大量的请求会打到数据库,好像蛮力击穿一样
redis事务本质就是一组命令的集合,事务支持一次执行多个命令,一个事务中所有的命令都会被序列化(redis事务就是一次性,顺序性,排他性的执行队列中的一条条命令),但Redis的事务不具有原子性
事务错误&回滚:
执行错误、
入列错误,不会终止
入列错误,会终止
关键词:
特性
redis采用了多路复用的IO模型,多路复用IO模型解决了单线程多个用户阻塞访问的问题:
但有一个客户端进程和服务器进程,服务器端read (sockfd1,bud,bufsize),此时客户端进程没有发送数据,那么read(阻塞调用)将阻塞直到客户端write(sockfd,but,size)发来数据。在一个客户和服务器通信时这没什么问题,当多个客户与服务器通信时,若服务器阻塞于其中一个客户sockfd1,当另一个客户的数据到达套接字sockfd2时,服务器仍不能处理,仍然阻塞在read(sockfd1,...)上。此时问题就出现了,不能及时处理另一个客户的服务。
多路复用解决思路:多路 I/O 复用模型是利用select、poll、epoll可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗以及上下文切换的时间和性能的小号),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量
介绍
原理
typedef struct pubsubPattern {
redisClient *client;//订阅模式的客户端信息
robj *pattern ; //保存着被订阅的模式
}
主库Master只负责写操作,从库Slave只负责读操作,一个主库可以有多个从库,但一个从库只能隶属于一个主库
开销问题:
在2.8之后开始支持,可以减少全量复制的开销
原理:
部分复制常用在主从连接断开,Master抖动时。
流程如下:
*概念*:服务器每次运行时生成的id,用于身份识别,一台服务器每次启动时生成的运行id都是不同的。
*组成*:运行id由40位随机的16进制字符组成
*作用*:用于服务器之前传输,做身份识别
*实现方式*:运行id在服务器启动时自动生成,master在首次连接一个slave时,会把运行id发给slave,slave会保存这个id,通过info server命令可以查看服务器的运行id
\2. 复制积压缓冲区
*概念*:复制积压缓冲区是一个先进先出的队列,用于存储服务器执行过的命令,每次命令传播,master都会将传播的命令记录在缓冲区。
创建时间点:每台服务器启动时,如果有开启AOF或者被连接成为master节点,就会创建缓冲区
*组成*:缓冲区并不是直接把命令塞进去,而是用aof文件中记录命令的格式来存储,如命令set name jam,在缓冲区存的就是
$3
set
$5
name
$6
hyf
这种格式也会把回车和换行符转义,变
成"$3\r\nset\r\n$4\r\nname\r\n$3\r\njam\r\n"。另外缓
冲区不仅仅只存储命令,命令在缓冲区是以字符存在
的,针对每个字符都会有一个偏移量(offset)来对
应,来记录字符在缓存区的位置。
1523 1524 1525 1526 1527 1528 1529 15210 15211
$ 3 \ r \ n s e t
info server命令可以查看服务器的运行id 3. 偏移量
上文可知,在缓冲区中,存在由一个偏移量,这个偏移量 是用来记录数据同步进行到的位置的。
在master中,会记录给各个slave发送的同步数据的偏移量,多少个slave就有多少个记录。
在slave中,会记录master在同步数据中发送过来的偏移量。
作用:在同步数据、对比slave与master数据的差异时,用来判断slave与master是否存在差异,如果有差异,也可以由此知道该从哪个位置开始恢复数据。
监控偏移量offset,如果超出范围就将读节点切换到
Master上,并重新全量复制到Slaves上
懒惰性策略是指只有操作key时才去看数据是否过
期,采样式策略指定期会去采样,如果过期,自动删
除。 当过期数量非常多时,采样速度比不上逻辑数据变
化的速度,Slave只有读权限,不可以删除,就会出现过
期数据。
Redis 3.2 以上版本修复此问题。
Slave节点通过持久化数据节点与主节点进行部分
复制同步;Redis2.8实现Slave恢复后部分复制同步。
需要主动切换主从关系。
使用Redis哨兵模式自动完成主从切换。
2.*复制风暴*
Master重启时,多个Slave需要复制,这个时候需要更换复制拓扑,通过在Slave下再分从机,减少主机Master的压力
################################# REPLICATION #################################
# 复制选项,slave复制对应的master。
slaveof
# 如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。
# masterauth就是用来配置master的密码,这样可以在连上master后进行认证。
# masterauth
# 当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:
# 1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。
# 2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。
slave-serve-stale-data yes
# 作为从服务器,默认情况下是只读的(yes)
slave-read-only yes
# 是否使用socket方式复制数据。
# 目前redis复制提供两种方式,disk和socket。
# 如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。
# 有2种方式:
# 1.disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。
# 2.socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。
# disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。
# socket的方式就的一个个slave顺序复制。
# 在磁盘速度缓慢,网速快的情况下推荐用socket方式。
repl-diskless-sync no
# diskless复制的延迟时间,防止设置为0。
# 一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。
# 所以最好等待一段时间,等更多的slave连上来。
repl-diskless-sync-delay 5
# slave根据指定的时间间隔向服务器发送ping请求。
# 时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。
# repl-ping-slave-period 10
# 复制连接超时时间。
# master和slave都有超时时间的设置。
# master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。
# slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。
# 需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时。
# repl-timeout 60
# 是否禁止复制tcp链接的tcp nodelay参数,可传递yes或者no。
# 默认是no,即使用tcp nodelay。
# 如果master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带宽。
# 但是这也可能带来数据的延迟。
# 默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes。
repl-disable-tcp-nodelay no
# 复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。
# 这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。
# 缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。
# 没有slave的一段时间,内存会被释放出来,默认1m。
# repl-backlog-size 5mb
# master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。
# 单位为秒。
# repl-backlog-ttl 3600
# 当master不可用,Sentinel会根据slave的优先级选举一个master。
# 最低的优先级的slave,当选master。
# 而配置成0,永远不会被选举。
# 注意:要实现Sentinel自动选举,至少需要2台slave。
slave-priority 100
# redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。
# master最少得有多少个健康的slave存活才能执行写命令。
# 这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。
# 设置为0是关闭该功能,默认也是0。
# min-slaves-to-write 3
# 延迟小于min-slaves-max-lag秒的slave才认为是健康的slave。
# min-slaves-max-lag 10
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。








