
代码拉取完成,页面将自动刷新

同步操作将从 百度开源/BRPC 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
NOTE: following tests were done in 2015, which may not reflect latest status of the package.
在多核的前提下,性能和线程是紧密联系在一起的。线程间的跳转对高频IO操作的性能有决定性作用: 一次跳转意味着至少3-20微秒的延时,由于每个核心的L1 cache独立(我们的cpu L2 cache也是独立的),随之而来是大量的cache miss,一些变量的读取、写入延时会从纳秒级上升几百倍至微秒级: 等待cpu把对应的cacheline同步过来。有时这带来了一个出乎意料的结果,当每次的处理都很简短时,一个多线程程序未必比一个单线程程序更快。因为前者可能在每次付出了大的切换代价后只做了一点点“正事”,而后者在不停地做“正事”。不过单线程也是有代价的,它工作良好的前提是“正事”都很快,否则一旦某次变慢就使后续的所有“正事”都被延迟了。在一些处理时间普遍较短的程序中,使用(多个不相交的)单线程能最大程度地”做正事“,由于每个请求的处理时间确定,延时表现也很稳定,各种http server正是这样。但我们的检索服务要做的事情可就复杂多了,有大量的后端服务需要访问,广泛存在的长尾请求使每次处理的时间无法确定,排序策略也越来越复杂。如果还是使用(多个不相交的)单线程的话,一次难以预计的性能抖动,或是一个大请求可能导致后续一堆请求被延迟。
为了避免请求之间相互影响,请求级的线程跳转是brpc必须付出的代价,我们能做的是使线程跳转最优化。不过,对服务的性能测试还不能很好地体现这点。测试中的处理往往极为简单,使得线程切换的影响空前巨大,通过控制多线程和单线程处理的比例,我们可以把一个测试服务的qps从100万到500万操纵自如(同机),这损伤了性能测试结果的可信度。要知道,真实的服务并不是在累加一个数字,或者echo一个字符串,一个qps几百万的echo程序没有指导意义。鉴于此,在发起性能测试一年后(15年底),在brpc又经历了1200多次改动后,我们需要review所有的测试,加强其中的线程因素,以获得对真实场景有明确意义的结果。具体来说:
我们希望这套测试场景对其他服务的性能测试有借鉴意义。
百度在08年开发的RPC框架,在百度产品线广泛使用,已被brpc代替。UB的每个请求独占一个连接(连接池),在大规模服务中每台机器都需要保持大量的连接,限制了其使用场景,像百度的分布式系统没有用UB。UB只支持nshead+mcpack协议,也没怎么考虑扩展性,所以增加新协议和新功能往往要调整大段代码,在实践中大部分人“知难而退”了。UB缺乏调试和运维接口,服务的运行状态对用户基本是黑盒,只能靠低效地打日志来追踪问题,服务出现问题时常要拉上维护者一起排查,效率很低。UB有多个变种:
我们以在百度网盟团队广泛使用的nova_pbrpc为UB的代表。测试时其代码为r10500。早期的UB支持CPOOL和XPOOL,分别使用select和leader-follower模型,后来提供了EPOLL,使用epoll处理多路连接。鉴于产品线大都是用EPOLL模型,我们的UB配置也使用EPOLL。UB只支持连接池,结果用“ubrpc_mc"指代(mc代表"multiple connection")。虽然这个名称不太准确(见上文对ubrpc的介绍),但在本文的语境下,请默认ubrpc = UB。
百度在13年基于saber(kylin变种)和protobuf实现的RPC框架,hulu在多线程实现上有较多问题,已被brpc代替,测试时其代码为pbrpc_2-0-15-27959_PD_BL。hulu-pbrpc只支持单连接,结果用“hulu-pbrpc"指代。
INF在2014年底开发至今的rpc产品,支持百度内所有协议(不限于protobuf),并第一次统一了百度主要分布式系统和业务线的RPC框架。测试时代码为r31906。brpc既支持单连接也支持连接池,前者的结果用"baidu-rpc"指代,后者用“baidu-rpc_mc"指代。
百度大搜团队在13年基于boost::asio和protobuf实现的RPC框架,有多个版本,咨询相关同学后,确认ps/opensource下的和github上的较新,且会定期同步。故测试使用使用ps/opensource下的版本。测试时其代码为sofa-pbrpc_1-0-2_BRANCH。sofa-pbrpc只支持单连接,结果用“sofa-pbrpc”指代。
thrift是由facebook最早在07年开发的序列化方法和rpc框架,包含独特的序列化格式和IDL,支持很多编程语言。开源后改名apache thrift,fb自己有一个fbthrift分支,我们使用的是apache thrift。测试时其代码为thrift_0-9-1-400_PD_BL。thrift的缺点是: 代码看似分层清晰,client和server选择很多,但没有一个足够通用,每个server实现都只能解决很小一块场景,每个client都线程不安全,实际使用很麻烦。由于thrift没有线程安全的client,所以每个线程中都得建立一个client,使用独立的连接。在测试中thrift其实是占了其他实现的便宜: 它的client不需要处理多线程问题。thrift的结果用"thrift_mc"指代。
由google开发的rpc框架,使用http/2和protobuf 3.0,测试时其代码为https://github.com/grpc/grpc/tree/release-0_11。gRPC并不是stubby,定位更像是为了推广http/2和protobuf 3.0,但鉴于很多人对它的表现很感兴趣,我们也(很麻烦地)把它加了进来。gRPC的结果用"grpc"指代。
如序言中解释的那样,性能数字有巨大的调整空间。这里的关键在于,我们对RPC的底线要求是什么,脱离了这个底线,测试中的表现就严重偏离真实环境中的了。
这个底线我们认为是RPC必须能处理长尾。
在百度的环境中,这是句大白话,哪个产品线,哪个系统没有长尾呢?作为承载大部分服务的RPC框架自然得处理好长尾,减少长尾对正常请求的影响。但在实现层面,这个问题对设计的影响太大了。如果测试中没有长尾,那么RPC实现就可以假设每个请求都差不多快,这时候最优的方法是用多个线程独立地处理请求。由于没有上下文切换和cache一致性同步,程序的性能会显著高于多个线程协作时的表现。
比如简单的echo程序,处理一个请求只需要200-300纳秒,单个线程可以达到300-500万的吞吐。但如果多个线程协作,即使在极其流畅的系统中,也要付出3-5微秒的上下文切换代价和1微秒的cache同步代价,这还没有考虑多个线程间的其他互斥逻辑,一般来说单个线程的吞吐很难超过10万,即使24核全部用满,吞吐也只有240万,不及一个线程。这正是以http server为典型的服务选用单线程模型的原因(多个线程独立运行eventloop): 大部分http请求的处理时间是可预测的,对下游的访问也不会有任何阻塞代码。这个模型可以最大化cpu利用率,同时提供可接受的延时。
多线程付出这么大的代价是为了隔离请求间的影响。一个计算复杂或索性阻塞的过程不会影响到其他请求,1%的长尾最终只会影响到1%的性能。而多个独立的线程是保证不了这点的,一个请求进入了一个线程就等于“定了终生”,如果前面的请求慢了一下,那也只能跟着慢了。1%的长尾会影响远超1%的请求,最终表现不佳。换句话说,乍看上去多线程模型“慢”了,但在真实应用中反而会获得更好的综合性能。
延时能精确地体现出长尾的干扰作用,如果普通请求的延时没有被长尾请求干扰,就说明RPC成功地隔离了请求。而QPS无法体现这点,只要CPU都在忙,即使一个正常请求进入了挤满长尾的队列而被严重延迟,最终的QPS也变化不大。为了测量长尾的干扰作用,我们在涉及到延时的测试中都增加了1%的长尾请求。
性能测试使用的机器配置为:
下面所有的曲线图是使用brpc开发的dashboard程序绘制的,去掉路径后可以看到和所有brpc server一样的内置服务。
如无特殊说明,所有测试中的配置只是数量差异(线程数,请求大小,client个数etc),而不是模型差异。我们确保用户看到的qps和延时是同一个场景的不同维度,而不是无法统一的两个场景。
所有RPC server都配置了24个工作线程,这些线程一般运行用户的处理逻辑。关于每种RPC的特殊说明:
所有的RPC client都以多个线程同步方式发送,这种方法最接近于真实系统中的情况,在考察QPS时也兼顾了延时因素。
一种流行的方案是client不停地往连接中写入数据看server表现,这个方法的弊端在于: server一下子能读出大量请求,不同RPC的比拼变成了“for循环执行用户代码”的比拼,而不是分发请求的效率。在真实系统中server很少能同时读到超过4个请求。这个方法也完全放弃了延时,client其实是让server陷入了雪崩时才会进入的状态,所有请求都因大量排队而超时了。
本测试运行在单机1上。图中的数值均为用户数据的字节数,实际的请求尺寸还要包括协议头,一般会增加40字节左右。
(X轴是用户数据的字节数,Y轴是对应的QPS)

以_mc结尾的曲线代表client和server保持多个连接(线程数个),在本测试中会有更好的表现。
分析
本测试运行在单机1上。
(X轴是线程数,Y轴是对应的QPS)

分析
brpc: 随着发送线程增加,QPS在快速增加,有很好的多线程扩展性。
UB和thrift: 8个线程下高于brpc,但超过8个线程后被brpc迅速超过,thrift继续“平移”,UB出现了明显下降。
gRPC,hulu-pbrpc,sofa-pbrpc: 几乎重合,256个线程时相比1个线程时只有1倍的提升,多线程扩展性不佳。
本测试运行在单机1上。考虑到不同RPC的处理能力,我们选择了一个较低、在不少系统中会达到的的QPS: 1万。
本测试中有1%的长尾请求耗时5毫秒,长尾请求的延时不计入结果,因为我们考察的是普通请求是否被及时处理了。
(X轴是延时(微秒),Y轴是小于X轴延时的请求比例)

分析
本测试运行在多机1上。
(X轴是client数,Y轴是对应的QPS)

分析
本测试运行在多机1上。负载均衡算法为round-robin或RPC默认提供的。由于有32个client且一些RPC的单client能力不佳,我们为每个client仅设定了2500QPS,这是一个真实业务系统能达到的数字。
本测试中有1%的长尾请求耗时15毫秒,长尾请求的延时不计入结果,因为我们考察的是普通请求是否被及时处理了。
(X轴是延时(微秒),Y轴是小于X轴延时的请求比例)

分析
本测试运行在多机2上。20台每台运行4个client,多线程同步访问10台server。负载均衡算法为round-robin或RPC默认提供的。由于gRPC访问多server较麻烦且有很大概率仍表现不佳,这个测试不包含gRPC。
本测试中有1%的长尾请求耗时10毫秒,长尾请求的延时不计入结果,因为我们考察的是普通请求是否被及时处理了。
(X轴是延时(微秒),Y轴是小于X轴延时的请求比例)
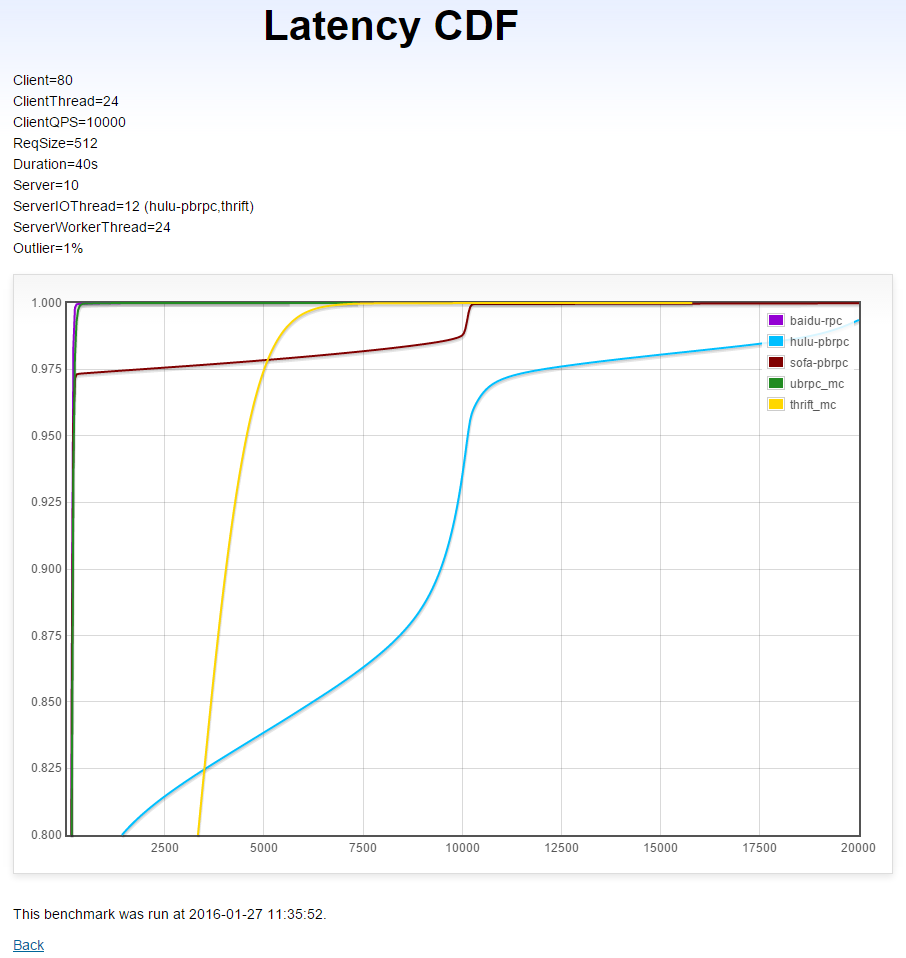
分析
本测试运行在多机2上。14台每台运行4个client,多线程同步访问8台server,这些server还会同步访问另外8台server。负载均衡算法为round-robin或RPC默认提供的。由于gRPC访问多server较麻烦且有很大概率仍表现不佳,这个测试不包含gRPC。
本测试中有1%的长尾请求耗时10毫秒,长尾请求的延时不计入结果,因为我们考察的是普通请求是否被及时处理了。
(X轴是延时(微秒),Y轴是小于X轴延时的请求比例)

分析
brpc: 在吞吐,平均延时,长尾处理上都表现优秀。
UB: 平均延时和长尾处理的表现都不错,吞吐的扩展性较差,提高线程数和client数几乎不能提升吞吐。
thrift: 单机的平均延时和吞吐尚可,多机的平均延时明显高于brpc和UB。吞吐的扩展性较差,提高线程数和client数几乎不能提升吞吐。
sofa-pbrpc: 处理小包的吞吐尚可,大包的吞吐显著低于其他RPC,延时受长尾影响很大。
hulu-pbrpc: 单机表现和sofa-pbrpc类似,但多机的延时表现极差。
gRPC: 几乎在所有参与的测试中垫底,可能它的定位是给google cloud platform的用户提供一个多语言,对网络友好的实现,性能还不是要务。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。