
来源:Gitee 封面人物 丨 2024-04-25

零一万物算法副总裁,北京大学计算机博士
进入 2024 年,国内开源大模型正面临着前所未有的发展机遇。一方面,它们在处理超长文本、多模态数据等方面展现出了前所未有的潜力;另一方面,开源社区的蓬勃发展,为这些模型的迭代升级和应用拓展提供了强大的动力。
我们有幸邀请到了零一万物的算法副总裁黄文灏博士做客《Gitee 封面人物》,我们将与黄博士一起,深入探讨国内开源大模型的现状与未来,以及零一万物在这一领域的努力和愿景。
黄文灏: 我是黄文灏,目前在零一万物担任算法副总裁。我是北京大学计算机博士毕业,读博期间恰好碰上 Deep Learning 开始兴起,就 All in Deep Learning 展开研究,算是国内最早做 Deep Learning 的一批人。毕业之后,加入微软亚洲研究院,做的方向和现在大家说的 Agent 有点相似,我们聚焦在可以完成任务的聊天机器人(Task Completion Chatbot)。再之后一直在做 AI 技术落地的一些尝试,包括金融量化、AI for Science 等等。在智源研究院的时候,那时还没有 ChatGPT,OpenAI 也不是很受关注,但智源以 OpenAI 为目标,看到了大模型可能是通往 AGI 非常 Promising 的路径,自己也决定 All in 大模型。

黄文灏: 我们的 Yi 系列模型是一连串工作的成果。首次开源的 LLM 包括 34B 和 6B 两种版本。34B 版本与常规的 7B 或 13B 相比,展现了更丰富的知识处理能力,并达到了大模型能力涌现的临界点。此外,经过精细的量化处理,34B 模型能在消费级显卡(如 RTX4090)上运行,为开发者提供操作便利和部署优势。
Yi 系列模型支持了 200K 超长上下文窗口的版本,能处理 20-30 万汉字的超长文本输入。这一能力在文档摘要、基于文档的问答等领域至关重要,为法律、财务、传媒和档案整理等多个垂直行业提供了广阔的应用场景。Yi-34B 作为开源模型,为开发者在超长上下文窗口微调上提供了更多可能性。
由于运行 Yi-34B-200K 需要的硬件资源过高,我们以低门槛的 API 形式提供,同时会根据大家的反馈进行迭代升级。希望这样强大的的 AI 能力能够触及到更广泛的人群,而不只是单纯局限于算法工程师。
此外,我们还推出了 Yi-VL 多模态模型,在英文和中文的多模态数据集上取得领先成绩,展现了其在跨学科任务上的强大能力,成为开源多模态模型中的领跑者。
黄文灏: 首先可以看一下什么是所谓的「LLaMA 的架构」,或者说这是不是一个可以固化的概念。下面是 LLaMA paper 中关于 architecture 的全部篇幅,在双栏 paper 中只占1/4页。

上面说明了模型是基于 Transformer 架构,做了三个常用的改进,分别是 Pre-norm、SwiGlue 和 RoPE。再回顾看看在 ChatGPT 发布前,或者说 LLaMA 发布前大家是怎么训练大模型的,无论是 GPTNeoX,BloomZ 还是 Galectica,基本都是一样的架构,和 LLaMA 架构基本没有区别。所以,只要是之前训练大模型的人,大家都知道训练大模型的架构应该是什么样子的。
大家不知道的是,用高质量的数据原来能训练出一个还不错的模型,因为之前的数据质量问题,用同样架构并没有训练出效果出众的模型。但当 LLaMA 出来之前大家开始做大模型的时候,但凡稍微有点大模型背景的研究人员早就已经把数据提高到了第一优先级。所以,「借鉴架构」的概念是很难成立的,因为 LLaMA 本身就不能被称为一种架构,或者说 LLaMA 出来之前大模型架构已经收敛了。LLaMA 更多是给了大家信心和敢于投入的勇气,从这点来说还是有很大帮助的。
黄文灏: 训练数据的来源大致可以分为三种方式,网络采集、开源数据和 IP 方合作。数据来源的不同、规模的大小、质量的高低都会影响模型训练的效果,理论上,它们越大越好,越多越好,越丰富越好。
但我们也在思考,能否有可能通过一些技术手段来实现高质量数据的筛选让模型能够直接学习精华,而不是再只是去追求原始数据的总规模,不再去一味地广撒网,穷尽所有信息。
在零一万物,我们会采集大量的数据,但我们只精选它们当中的大约1%来做模型的训练。在这个过程中,我们设计了一套有着 12 层过滤机制的数据处理体系,去筛除那些有风险的、有偏差的、包含隐私信息的、质量不够好的数据。有了更好的训练数据,这就确保了我们的模型训练不仅是有效的,也是高效的。这意味着更高的质量,也意味着更少的时间和更低的成本。
黄文灏: 大模型公司的确使用了大量互联网上的高质量数据,这也是模型能力逐步变强的重要原因,但其实不用太担心数据耗尽的问题。首先,我们在处理高质量数据的时候,过滤了很多的数据,以 Yi-34B 的训练过程来看,我们从原始 6PB 的数据中最终只保留了 3T token。这些被过滤的数据中其实也是有大量有价值的信息的,也是可以压缩出智能的,所以用好这部分数据是很重要的研究方向。另外,多模态数据的量会比文本大很多,每天产生的多模态数据其实大概率是比我们处理数据的速度快很多的。我们也在研究统一多模态模型,不仅是可以利用多模态模型处理数据,多模态内容还能进一步提高模型的智能。
黄文灏: 我们精选了最受弱智吧网友欢迎的数百个帖子,这些帖子都是网友们绞尽脑汁所想出的段子和问题。他们并非我们日常中「直来直去」的问题,而是包含许多逻辑/事实缪误,并且需要回答者通过多步推理和思考才能给出正确回答,而这每一步的推理通常都需要联系其背后的隐含知识。例如一个有趣的例子:「几百年后,在秦始皇陵复活的秦始皇长叹一声:假人们,谁动啊」,模型需要识别出中文谐音,准确的结合现代网络用语和历史知识,一个简短的问题便可在多个维度上对模型提出了挑战。
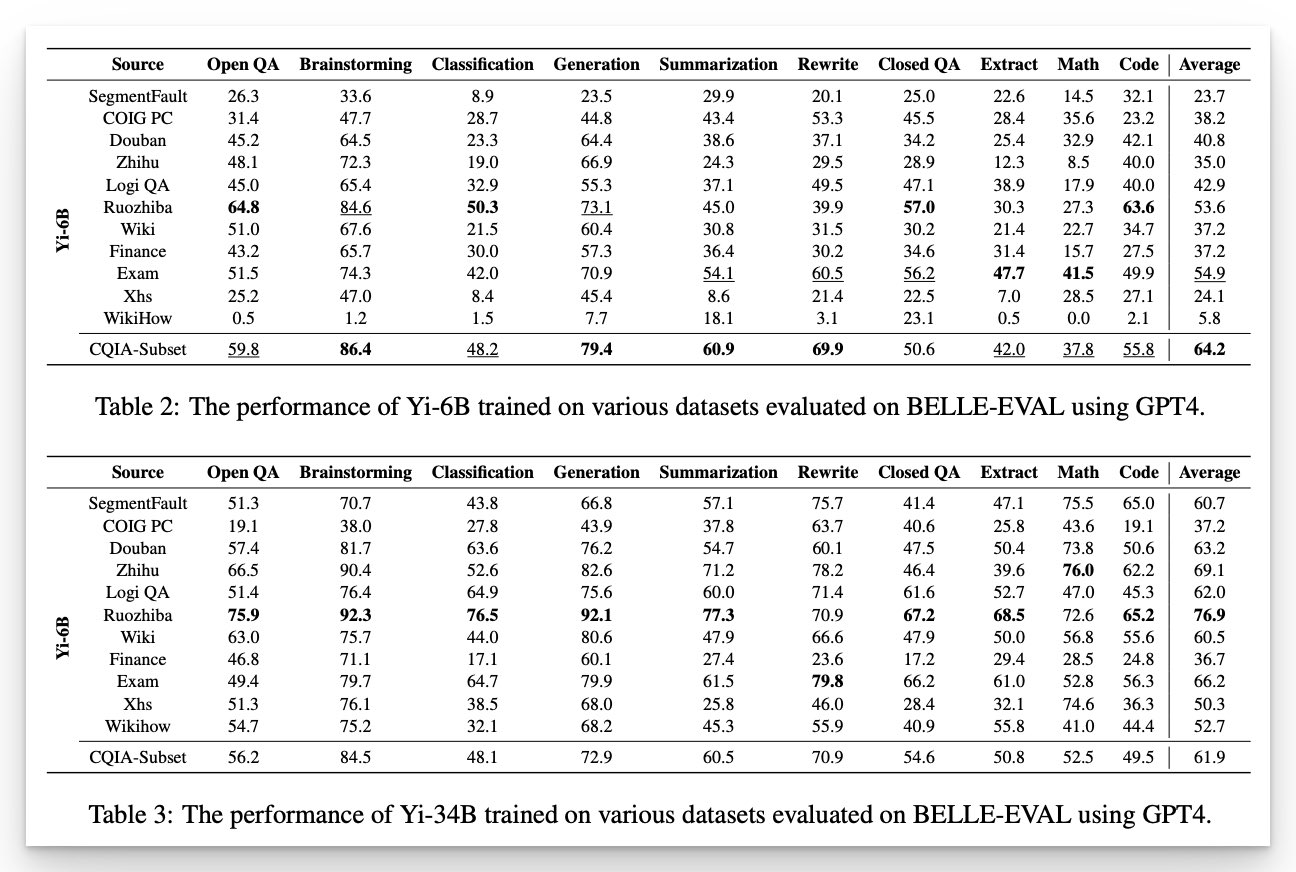
除此之外,对于弱智吧回答的构造上我们也力求精准全面,我们首先人工识别出问题的「易错点」,作为提示让 GPT4 给出回答框架,但这些框架通常并不能直接作为训练数据,我们随后又人工修改回答框架,保证了回答的高质量。除了数据质量高,基座模型的选择也十分关键,Yi 系列模型在知识、推理、计算方面都在公开的中英文 benchmark 上取得了极具竞争力的效果,甚至经常可以挑战参数量更高的其他开源大模型。经过弱智吧数据的训练,更加激发了模型在预训练阶段已习得的各种能力。
黄文灏: 让模型更安全,就像教小朋友一样,要不断地告诉他什么是对的,什么是错的。针对大模型的安全性问题和伦理性问题,我们研发了一套 Responsible AI Safety Engine 的安全体系,我们称之为「RAISE」。通过「RAISE」,我们将我们的安全能力覆盖到大模型从研发到应用的全生命周期之中,最大限度地减少潜在的风险和威胁。
不论是在预训练的数据筛选中,还是在模型对齐的过程中,RAIS E会要求模型不断去理解我们人类的文化和习惯,学习更好的观点和更好的回答,提高模型自身对于很多安全问题、伦理问题的判断力和弹性。
这些是「RAISE」体系的一部分能力,当然它还有更多的能力。而这些的核心目标只有一个,就是努力确保大模型的安全性、伦理性,让它的行为始终能够符合我们人类的正确价值观。
黄文灏: 评测最重要的作用应该是作为观测指标指导训练过程。完美的评测标准是不存在的,或者说当一个 metric 被作为评测标准后,就很容易被 overfitting。好的评测标准需要至少满足两个条件:
之前在智源研究院时,我们从事更多的是从-1到0的工作,当国内没有人在做大模型的时候,智源研究院就开始投入,可以看到后来基本上大部分大模型公司都和智源研究院有密切联系。但当 ChatGPT 出来之后,大模型逐渐形成共识,需要更多的资源去完成从0到1的过程。这个机会更多是留给工业界的。但 AI-Native 的公司从组织形态上就需要是 AI-Native 的,我觉得创业公司在这个过程中可以保持很高的人才密度和很强的组织能力,在大模型赛道上有很大的机会。正好和开复老师交流了他对大模型和 AI-Native 的看法,觉得很匹配就加入零一万物了。

我的愿景和零一万物的愿景是一致的——「Make AGI Accessible and Beneficial to Everyone」。我相信 AGI 这个目标对每一个做 AI 研究的人都是圣杯。同时我们希望在实现 AGI 这件事情上,所有人都是普惠的和受益的。

我觉得最大的挑战是人才密度。以大模型为代表的 AI 2.0 是有史以来最伟大的科技革命和平台革命。AI 2.0 和之前的几次科技革命有很大区别——只需要少量的人和大量的算力资源。大部分训练模型的团队都是几个人,但却会占用几千张、上万张卡,对应着每年几个亿美金的算力资源。组建团队时的容错率是很低的。如何找到优秀的人,给大家足够的信任,是很大的挑战。比如,是不是有可能给刚毕业的学生几千张卡去完成一个任务,相信对哪个 CEO 来说都是很难的决定。
开源是大模型发展很重要的催化剂。开源能让技术社区能站在巨人的肩膀上爬得更高,例如国内外都有不少社区、高校甚至企业是以 Yi-34B 作为基础再微调出更多的衍生模型,使得更多不同的场景和需求能被满足,这不仅使得零一万物的 Yi 模型生态能通过社区更加扩大茁壮,也真真切切的帮助到 LLM 技术更快地发展,开发者也能产出各种应用。
全球的开源模型如此之多、甚至不断追逐更大的参数,我们也设身处地考虑到要如何开源才对开发者有所帮助,因此我们通过 34B 和 6B/9 B的两类模型提供我们的 Yi 模型,开发者能审视其自身算力规模来决定使用什么规格的模型;更多超大、几百B的开源模型,能有足够算力运行的也都是企业级的用户,这时对广大开发者的使用和意义其实比较受限。开源也呼应了零一万物的愿景:「让通用人工智能普惠各地,人人受益」,这也是我们的核心价值主张。
「百模大战」这个词在过去一年被反复提及,但大家似乎混淆了所谓「模型」的概念。大模型应该分为两类,一类是从头开始训练的基础模型,比如:Yi,QWen,ChatGLM,DeepSake 等等;另一类是 Continue Pretraining 和 SFT 类别的模型。这两类最大的差别就是花费的资源和训练用的数据。
前一类现在大家基本上都是 2T 左右 token 起,也有3、4T token 的数量级的,这类工作即使训练 7B 的模型也需要几百万的代价,训练 30B 以上的模型更是数千万的成本。先不管大家模型最终效果如何,至少是花了真金白银做出来的,而且这个是一次训练的成本,还有大量的试错和实验,真实花费代价在几倍以上。
后一类 Variance 就比较大了,有用几百 B 数据做 Continue Pretraining 的,也有用几百条数据做 SFT 的,花费则是从几十万到几十块不等。这种情况下,把花费相差5、6个数量级的模型放在一起比较本来就是有失公允的。但如果仔细看「百模大战」里的模型类别,可以发现大多数都是后一类,前一类可能也就十几个,不到二十个。而真正关键的是前一类的基础模型,也是大家真金白银炼出来的模型。
最重要的还是 follow 自己的目标,脚踏实地的把每一步都走实了。AGI 是一场长征,不要太在意短期的成果,要始终保持对最终目标的追求。
比如,在公司成立初期,我们花了很长的时间在做数据处理的 pipeline,scaling law 的基础研究,这些工作为我们后期顺利的 scale up 提供了最重要的基础保障。如果我们很着急地去做一些模型而忽略了这些基础工作,现在我们在模型训练上绝对不会这么顺利。另一方面,我们的目标一直是全球市场,我们的竞争对手是 OpenAI、Anthropic、Google,我们的模型也在全球市场上取得了不错的表现。
最核心的点是保持人才密度和组织能力,其次是争取更多的算力。大模型时代有一个简单的公式:「组织 = 人才密度 * 算力」。然后怀抱着 AGI 的梦想,有耐心,脚踏实地,技术创新是自然而然的事情。
算力肯定是第一生产力,公司也在积极地扩大算力规模。现在我们的算力规模在国内也是比较领先的。除此以外,我们也做了大量的工作来提高已有算力的使用效率。
首先,我们在 infra 上花了很多时间,做算法和 infra 一体的优化,不断提高训练效率。其次,我们在探索给定 computation 情况下,最高效的模型架构,数据配比,充分发挥已有算力的价值。我们的优化目标一直是优化给定算力条件下的智能水平,效率和算法同等重要。
Sora 难或是不难其实并不重要。重要的还是去理解 Sora 背后 OpenAI 的方法论。零一万物最相信的是 scaling law,也就是我经常说的 scale up is all you need。要反复阅读、理解、背诵 Bitter Lesson。我们相信所有模型 scale up 以后都会有智能,我们只是需要在算力约束条件下,找到一种能更高效地 scale up 的结构和范式。
最重要的肯定是 scale up,无论是数据、模型还有算力都还有很多 scale up 的空间,我们对模型能力有数量级提升持乐观态度,scaling law 还远远没有达到极限。另外我们觉得应该 all in one,现在的多模态还是有点割裂,是各种模态往语言模型对齐的。所有的模态数据都可以看作是一种新的语言,和自然语言训练类似,我们可以从一开始就把多有模态数据混在一起,在一起做压缩的过程中产生更高的智能。
最重要的是每天使用大模型,感受它的能力,形成一种习惯。然后,争取一切能够训练或者微调大模型的机会,只有 hands on 的经验才是最重要的。大模型时代,算力会成为一种很重要的 scalar,或者杠杆,所有人的能力都会被算力放大,scalar 大小很重要。





