

代码拉取完成,页面将自动刷新
| 文档名称 | Story Museum(文物智能识别APP)产品需求文档 |
|---|---|
| 版本 | 2.0 |
| 1.0版本 | diff链接对比视图 |
| 撰写人 | 李彤 |
| 撰写时间 | 2020.7.24 |
| 状态 | 初稿 |
本产品主要针对游客在博物馆游览时因为对文物历史背景知识缺乏导致游览兴致不高或是游览体验不佳的问题,提供了物体识别API技术、语音合成API技术以及文本翻译API技术进行综合运用以为产品加值,帮助用户了解更多文物展品背后的故事提升博物馆游览体验。
博物馆,是征集、典藏和研究代表自然和人类文化遗产的实物的场所,也是为人们提供知识、教育及欣赏服务的场所。如今,随着中国文博事业的迅速发展,参观博物馆逐渐成为了大众的一种旅游潮流。
统计数据显示,截至2019年年底,全国备案的博物馆达到5535家,比上一年度增加181家,中国每25万人拥有1个博物馆。其中免费开放的博物馆4929家,全年接待观众10.22亿人次。
国家统计局统计数据显示,2013年以来,我国博物馆收入整体呈现震荡上行趋势,2017年,全国博物馆实现收入325.56亿元,创近年新高,2018年,博物馆整体收入有所下滑。结合2019年,我国博物馆发展情况及全年文化旅游接待游客数量变化情况来看,初步估计,2019年,我国博物馆收入约为323亿元。
互联网作为当今时代最具发展活力的领域,已经全面融入生活的方方面面,也使得博物馆依托互联网时代的技术与平台重焕生机成为可能。尤其是2016年由国家文物局、国家发展改革委、科技部、工信部、财政部印发了《“互联网+中华文明”三年行动计划》,在此背景下,如何利用网络媒介有效传播中华优秀传统文化,成为目前博物馆领域正在探讨的重要课题。
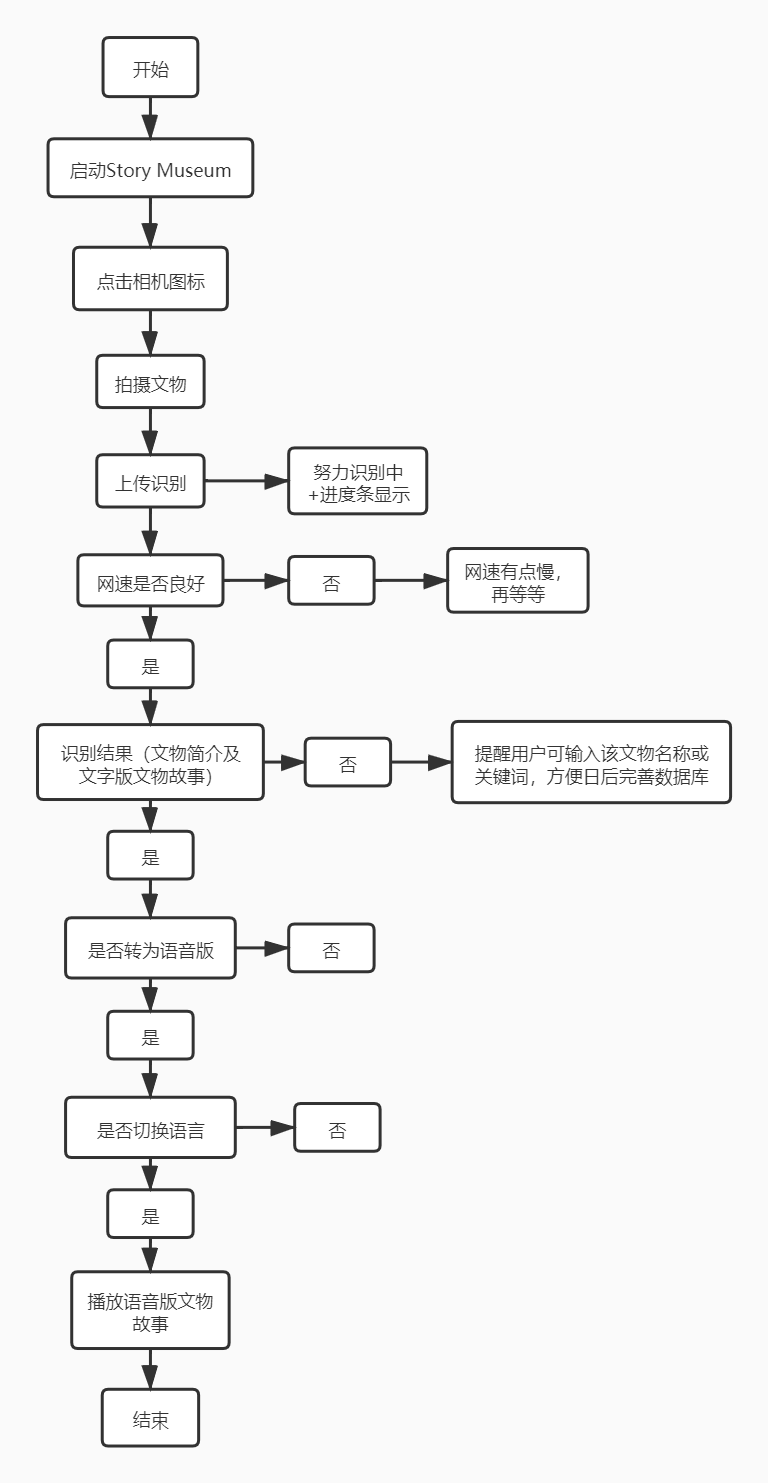
针对游客在逛博物馆时可能对文物背景知识缺乏了解而大大降低游览体验这一问题,该产品可提供拍照智能识物功能、智能语音合成功能以及文本翻译功能提升游览博物馆体验。游客可以在参观过程中通过对文物进行拍照识别获得该文物的背景知识信息以及语音合成版文物故事,且可根据需求选择语言和音色。
用户痛点:
核心价值:
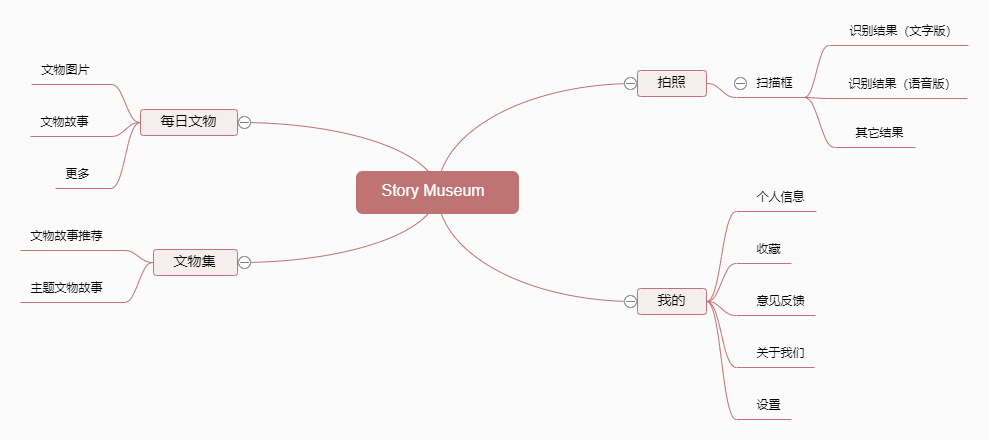
产品中的拍照智能识物功能和智能语音合成功能可以让用户只需要对文物扫描拍照便可获取关于该文物的精选背景知识信息;此外,产品中还存储了文物故事,包括文字版和语音版,用户可根据自身需求选择文字版或是语音版,且可选择不同语言版以及不同音色。
根据同程艺龙与同程旅游联合发布的《中国博物馆主题游消费趋势报告2019》来看,我国博物馆客群年龄结果分布偏向年轻化,“90后”占比43.2%,“95后”占比24.9%。庞大的“90后”消费群体,在旅游偏好上与以往大有不同。“90后”深谙流行文化,主张彰显个性,追求新潮好玩,近年来许多网红博物馆的出现恰恰是契合了年轻一代的个性需求。
此外,近年来亲子游的火热说明亲子也是值得关注的一大用户群体。数据显示,每年的暑期(7月和8月)是全国博物馆主题游的旺季,客流量占全年总接待量的29.2%。而从每周的客流分布情况来看,全国主要收费博物馆双休日的客流量占一周客流总量的37.5%,尤以周六的客流量最大。另外,以“夜宿博物馆”为代表的亲子主题产品一度风靡,国内外博物馆暑期主题研学旅行也深受家长们追捧。
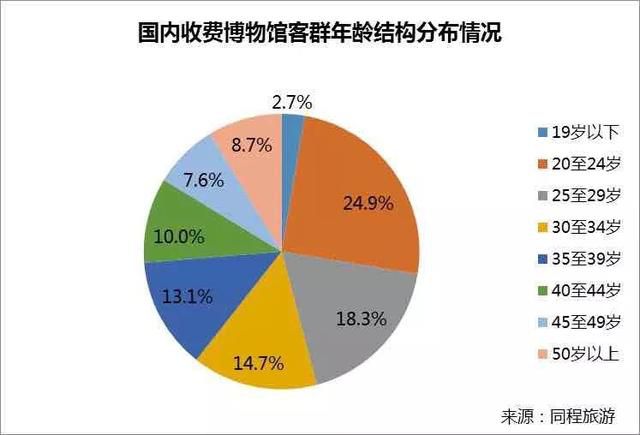
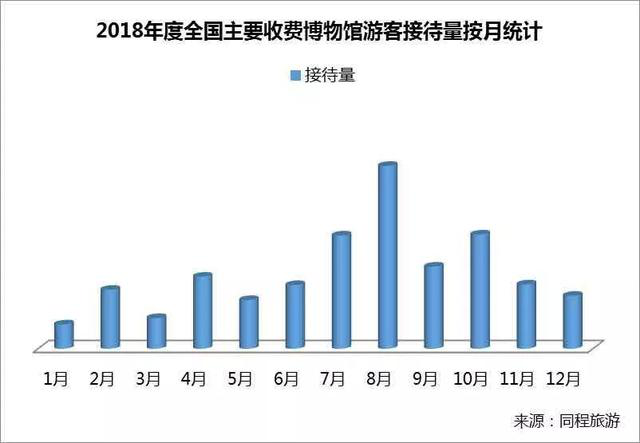
但也有业内人士指出相较欧美国家,我国青少年对博物馆的兴趣还有上升空间,说明这一市场仍具有较大挖掘潜力。
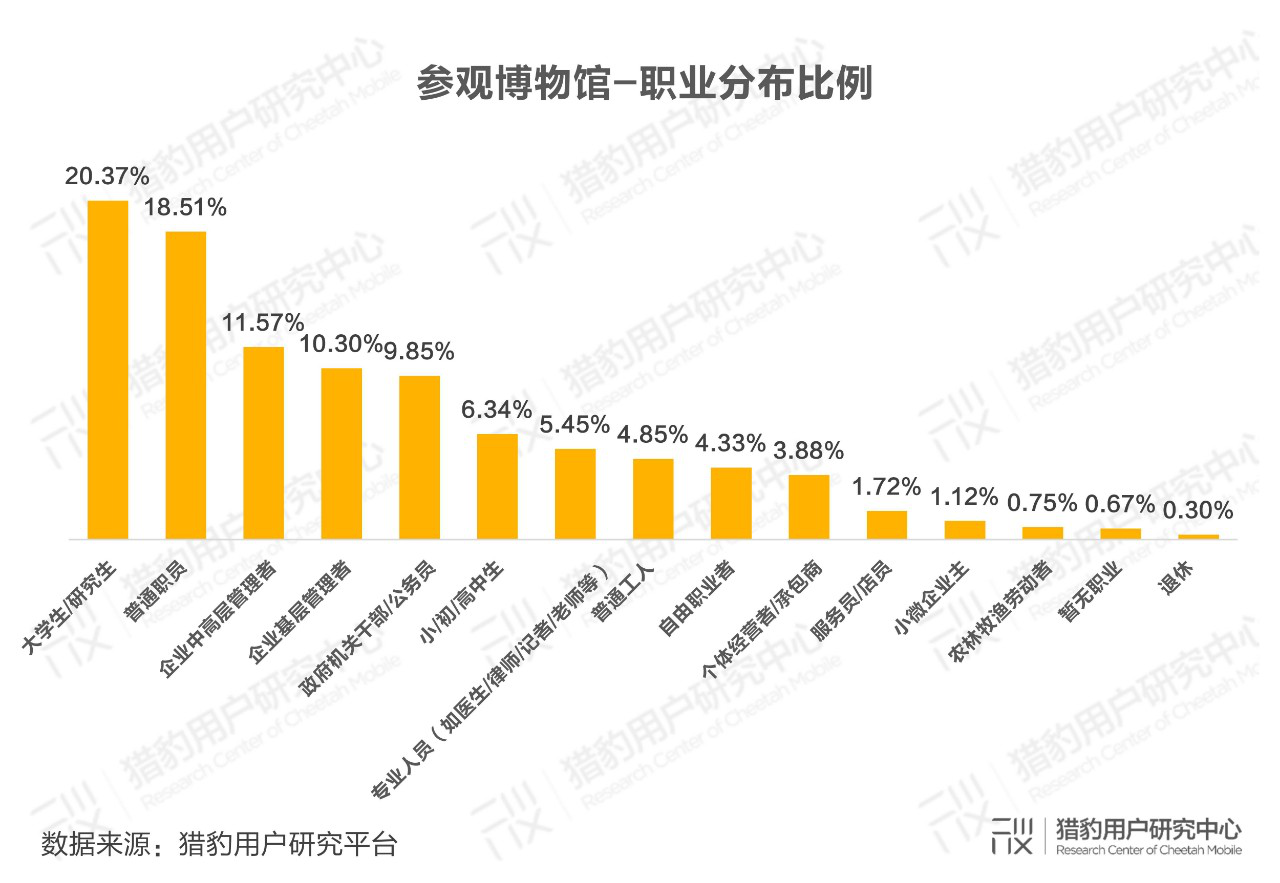
在猎豹用户研究中心针对参观博物馆的人群的调研中,主要职业类别为大学生/研究生和公司普通职员,占比分别为20.37%和18.51%。
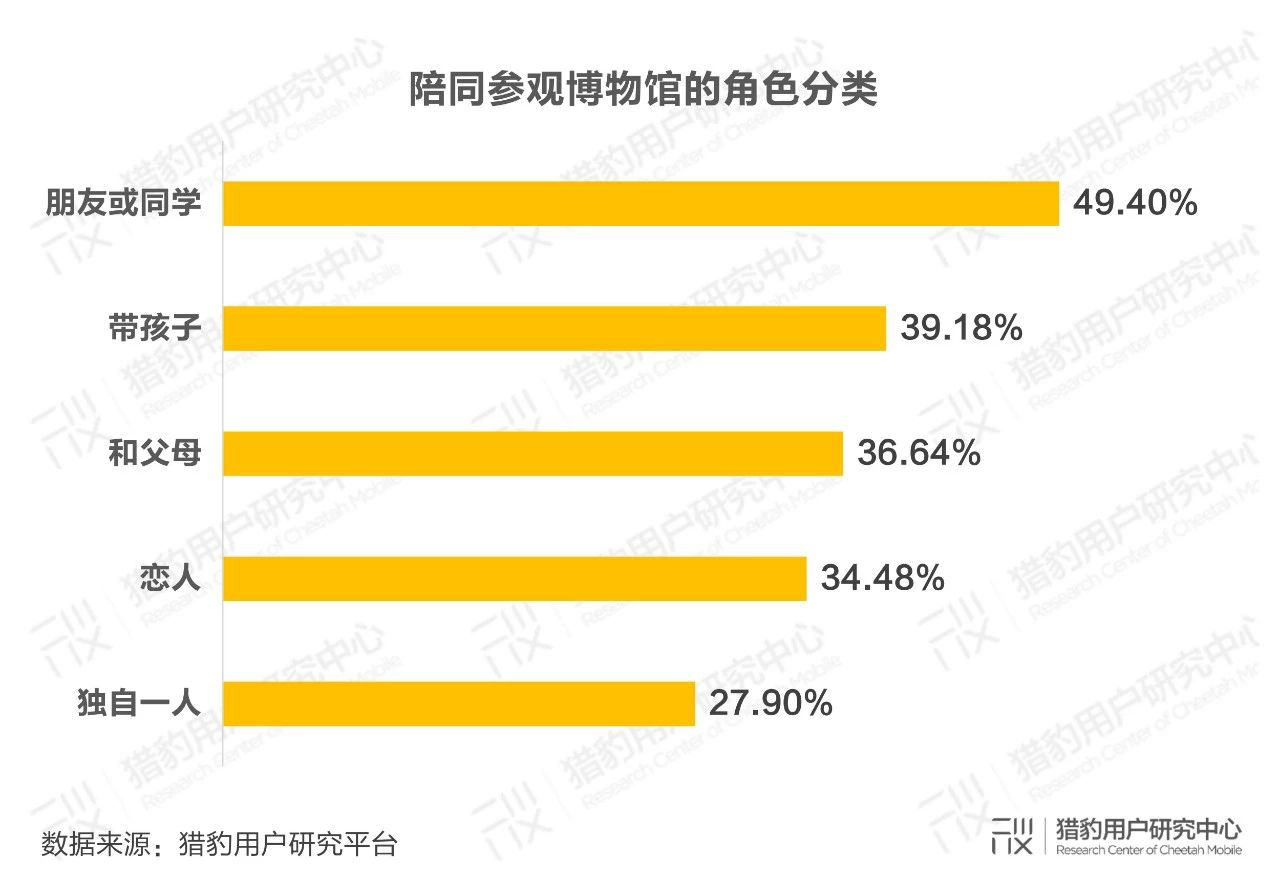
在选择和谁一起去博物馆这一项中,和朋友或同学去博物馆这一选项最高,占比49.40%,有39.18%的人选择带孩子参观,也有27.90%的人选择独自一人去博物馆。
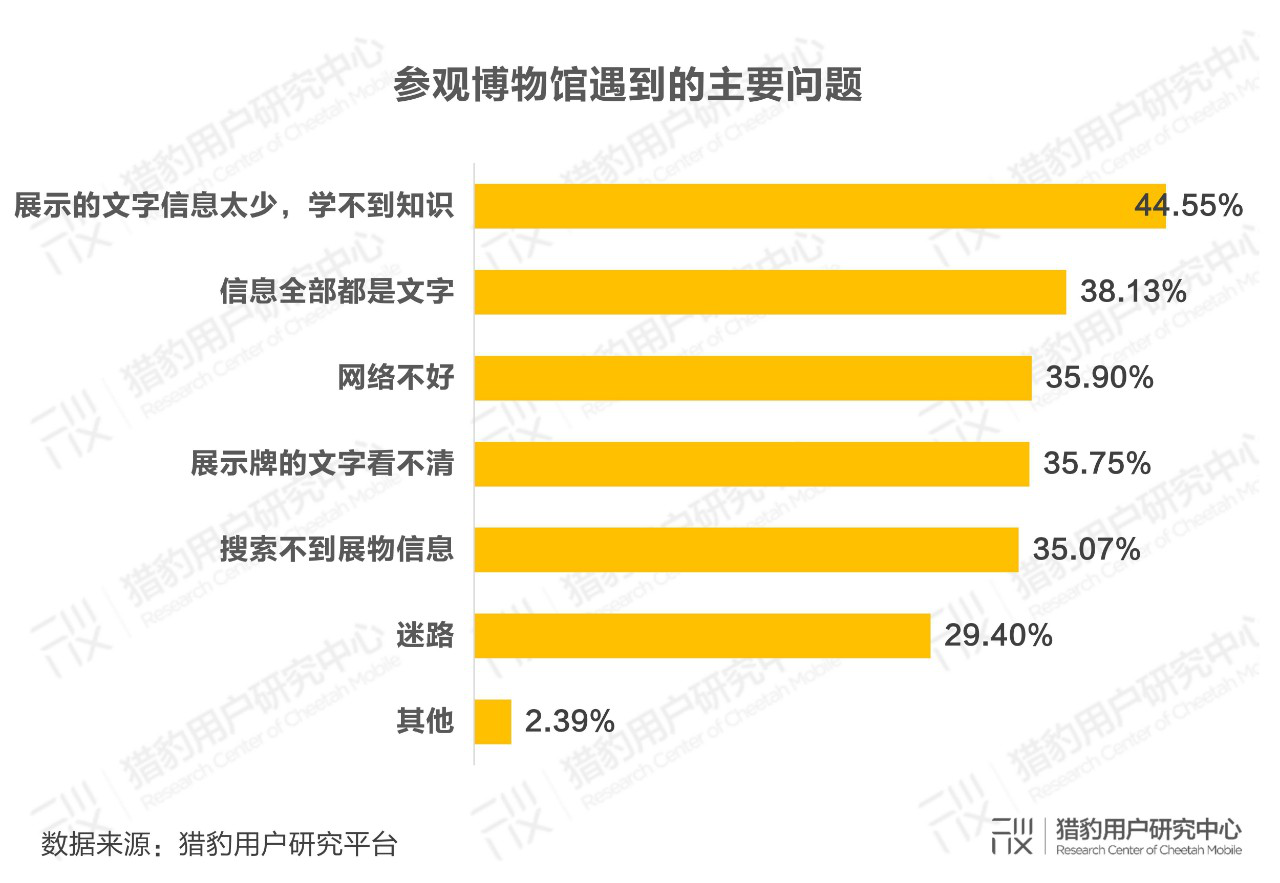
有44.55%的博物馆观众群体表示展物的介绍信息太少是参观过程中遇到的最主要问题,其余也大多是与展示信息效果欠佳相关。
同时,通过这张词云图可以看出,博物馆参观群体对于博物馆的“智能”有较强烈的需求。

核心用户:6-25岁的博物馆参观爱好者年轻群体
主要用户:6-40岁的博物馆参观爱好者群体

使用场景:
小丽是一名在校大学生,比较喜欢中国传统文化,在假期时间会和朋友一起去逛逛周边的博物馆,但是感觉讲解员的讲解有些枯燥无味,于是她打开Story Museum APP,对感兴趣的文物进行拍照识别,APP中出现该文物的一些相关介绍和文物故事,故事以某历史人物的第一人称角度展开,讲述该历史人物与该文物之间的故事,这让小丽不仅感觉拉近了真实世界和数字世界之间的距离,也对该文物的故事有了深刻印象。

使用场景:
小明是一个喜欢了解历史的小学生,假期和爸爸妈妈去各个城市旅游的时候最喜欢去逛博物馆,当他看到一件非常感兴趣的文物展品时,想问爸爸妈妈这件文物背后的故事,但是小明的爸爸妈妈对此了解也不多,于是小明打开Story Museum APP,对文物进行拍照识别,APP中出现该文物的第一人称视角故事,小明选择了语音版故事播放,新奇有趣的叙事角度和故事更加吸引了小明对该文物的兴趣。

使用场景:
Mary是一名初来中国的留学生,还不太熟悉中文,但是对于中国传统文化和历史非常感兴趣,所以喜欢去博物馆参观。在博物馆里,她不太能听懂讲解员的讲解和看懂展板上简略的信息,因而她打开了Story Museum APP对文物进行拍照识别,APP出现文物故事,Mary在语言中选择了英语进行播放。
| 优先级 | 用户需求 | 智能加值 | API类型 | API来源 |
|---|---|---|---|---|
| 1 | 想要了解文物背后的相关信息和故事 | 是 | 物体识别 | 百度开放平台通用物体和场景识别 |
| 2 | 不想看文字故事,想直接听声音或切换其他语言进行播报 | 是 | 语音合成 | 讯飞开放平台在线语音合成 |
| 3 | 希望文物故事能切换其它语言 | 是 | 文字翻译及翻译语音合成 | 百度通用翻译+语音合成资源 |

在产品设计上,需要对该张图的第一二象限的利益相关者尤为重视,尽最大能力满足他们的需求和提升他们的用户体验满意度;对于第二象限的利益相关者,需要给予一定程度的重视,随时掌握其与产品的相关性,比如实时关注博物馆文化事业的发展状况,根据变化更改完善产品;对于第三象限影响力小但相关度高的利益相关者,需要让他们充分了解情况并与他们交谈以帮助产品完善细节;对于第四象限的利益相关者,主要是持续关注他们,不必进行过度的沟通。


综合百度开放平台数据库、收集文物图片数据及对应名称数据以及制定文物故事数据
本产品的API主要采用的是百度开放平台的通用物体和场景识别、讯飞在线语音合成以及百度开放平台通用翻译技术。
百度开放平台通用物体和场景识别API由于拥有超大规模数据集,深度学习算法能力强,无论是技术还是准确率在业界都属于领先水平;正常情况下其准确率较高,但可能会受一些环境因素(光线、拍摄角度)的影响出错,但是都为小概率事件且在产品界面中会提示用户在拍摄时注意这些问题。
讯飞开放平台在线语音合成API技术成熟,语音合成效果断句合理、自然流畅,与真人朗读无太大差别,且提供多种语言、音色选择,准确率高、合成效果良好,出错概率极小。
百度开放平台通用翻译API不仅能进行普通的文本之间的翻译,还能将文本直接翻译成语音,是市面上不多见的翻译技术,翻译的质量准确率也比较高,翻译出现错误的情况概率比较低,但是由于本产品需要翻译的文本专业性较强可能会出现翻译质量不佳的情况,也可以通过在使用过程中数据的收集再训练进一步优化。
人工智能概率性考量总结:
总体来说,本产品所选用的百度开放平台通用物体和场景识别API、讯飞开放平台在线语音合成API、百度开放平台通用翻译API都处于各自所属API类型目前业界的领先水平,准确率较高,训练模型技术也较为成熟,因而也利于之后在产品使用过程中收集到的数据的再训练,进而不断地优化人工智能概率性,提升产品的用户体验感。
(1)API调用
接口描述:该请求用于通用物体及场景识别,即对于输入的一张图片(可正常解码,且长宽比适宜),输出图片中的多个物体及场景标签。
请求URL :https://aip.baidubce.com/rest/2.0/image-classify/v2/advanced_general
请求方法:POST
# encoding:utf-8
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
print(response.json())
# encoding:utf-8
import requests
import base64
'''
通用物体和场景识别
'''
request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v2/advanced_general"
# 二进制方式打开图片文件
f = open('./簪花仕女图.png', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
{'log_id': 8705286469577267761, 'result_num': 5, 'result': [{'score': 0.823557, 'root': '商品-工艺品', 'keyword': '绘画'}, {'score': 0.578453, 'root': '商品-绘画', 'keyword': '图画'}, {'score': 0.386313, 'root': '非自然图像-彩色动漫', 'keyword': '卡通动漫人物'}, {'score': 0.210961, 'root': '非自然图像-文字图', 'keyword': '报纸杂志'}, {'score': 0.027196, 'root': '人物-人物特写', 'keyword': '美女'}]}
(2)API比较
华为云图像标签:只能识别物体的名称和标签,无法返回其它信息内容。
百度开放平台的通用物体和场景识别:能识别的物品数量庞大,且能支持获取图片识别结果对应的百科信息,接口返回百科词条URL、图片和摘要描述。
总结分析:通过二者API技术调用结果的比较,我认为华为云对于本产品的拍照识别功能用处不大,因为它只能返回物体的名称;而百度开放平台的通用物体和场景识别不仅可以返回物体名称,还能返回百科词条和摘要描述等信息,在本产品的拍照识别返回文物故事这一功能上进行优化的可能性较大。
(1)API调用
接口描述:该语音能力是通过Websocket API的方式给开发者提供一个通用的接口。Websocket API具备流式传输能力,适用于需要流式数据传输的AI服务场景。相较于SDK,API具有轻量、跨语言的特点;相较于HTTP API,Websocket API协议有原生支持跨域的优势。
请求地址 :ws[s]: //tts-api.xfyun.cn/v2/tts
请求方法:POST
# -*- coding:utf-8 -*-
#
# author: iflytek
#
# 本demo测试时运行的环境为:Windows + Python3.7
# 本demo测试成功运行时所安装的第三方库及其版本如下:
# cffi==1.12.3
# gevent==1.4.0
# greenlet==0.4.15
# pycparser==2.19
# six==1.12.0
# websocket==0.2.1
# websocket-client==0.56.0
# 合成小语种需要传输小语种文本、使用小语种发音人vcn、tte=unicode以及修改文本编码方式
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, Text):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.Text = Text
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": "xiaoyan", "tte": "utf8"}
self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
#使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”
#self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}
# 生成url
def create_url(self):
url = 'wss://tts-api.xfyun.cn/v2/tts'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
def on_message(ws, message):
try:
message =json.loads(message)
code = message["code"]
sid = message["sid"]
audio = message["data"]["audio"]
audio = base64.b64decode(audio)
status = message["data"]["status"]
print(message)
if status == 2:
print("ws is closed")
ws.close()
if code != 0:
errMsg = message["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
with open('./demo.pcm', 'ab') as f:
f.write(audio)
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": wsParam.Data,
}
d = json.dumps(d)
print("------>开始发送文本数据")
ws.send(d)
if os.path.exists('./demo.pcm'):
os.remove('./demo.pcm')
thread.start_new_thread(run, ())
if __name__ == "__main__":
# 测试时候在此处正确填写相关信息即可运行
wsParam = Ws_Param(APPID='输入APPID', APIKey='输入APIKey',
APISecret='输入APISecret',
Text="这是一个语音合成示例")
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
{
"code":0,
"message":"success",
"sid":"ttsxxxxxxxxxxx",
"data":{
"audio":"QAfe..........",
"ced":"14",
"status":2
}
}
(2)API比较
百度在线语音合成:目前只有中英文混合这一种语言,种类太少且语音识别会不够精确,音库也只有9个。
讯飞在线语音合成:提供中英日韩等18种多语种、川豫粤等多方言、男女声多风格的选择,音量、语速、音调等参数也支持动态调整;质量合成音频的自然度和清晰度已经超过了普通人的朗读水平。
总结分析:百度在线语音合成的语言太少,且音库种类也不丰富。相较之下,讯飞不仅语言种类音库种类丰富,合成音频的自然度和清晰度也高,因此选择了该API。
(1)API调用
接口描述:通用翻译API通过HTTP接口对外提供多语种互译服务。您只需要通过调用通用翻译API,传入待翻译的内容,并指定要翻译的源语言(支持源语言语种自动检测)和目标语言种类,就可以得到相应的翻译结果。
请求地址 :https://fanyi-api.baidu.com/api/trans/vip/translate
请求方法:GET或POST
#百度通用翻译API,不包含词典、tts语音合成等资源,如有相关需求请联系translate_api@baidu.com
# coding=utf-8
import http.client
import hashlib
import urllib
import random
import json
appid = '' # 填写你的appid
secretKey = '' # 填写你的密钥
httpClient = None
myurl = '/api/trans/vip/translate'
fromLang = 'auto' #原文语种
toLang = 'en' #译文语种
salt = random.randint(32768, 65536)
q= '簪花仕女图'
sign = appid + q + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
print (result)
except Exception as e:
print (e)
finally:
if httpClient:
httpClient.close()
{'from': 'zh', 'to': 'en', 'trans_result': [{'src': '簪花仕女图', 'dst': 'Beautiful ladies with hairpin flowers'}]}
(2)API比较
有道智云文本翻译:将一段源语言文本转换成目标语言文本,可根据语言参数的不同实现多国语音之间的互译,翻译结果可选择不同语言音色。
百度开放平台通用翻译:通用翻译API支持28种语言互译,覆盖中、英、日、韩、西、法、泰、阿、俄、葡、德、意、荷、芬、丹等;支持28种语言的语种检测。您只需调用通用翻译API,传入待翻译的内容,并指定要翻译的源语言(支持源语言语种自动检测)和目标语言,即可得到相应的翻译结果。任何第三方应用或网站都可以通过使用通用翻译API为用户提供实时优质的多语言翻译服务,提升产品体验。
总结分析:两者相比之下,有道智云文本翻译仅支持文本翻译为文本,而百度开放平台通用翻译不仅支持文本翻译为文本,还支持文本翻译为语音,更符合本产品技术需求,故选择了百度开放平台通用翻译。

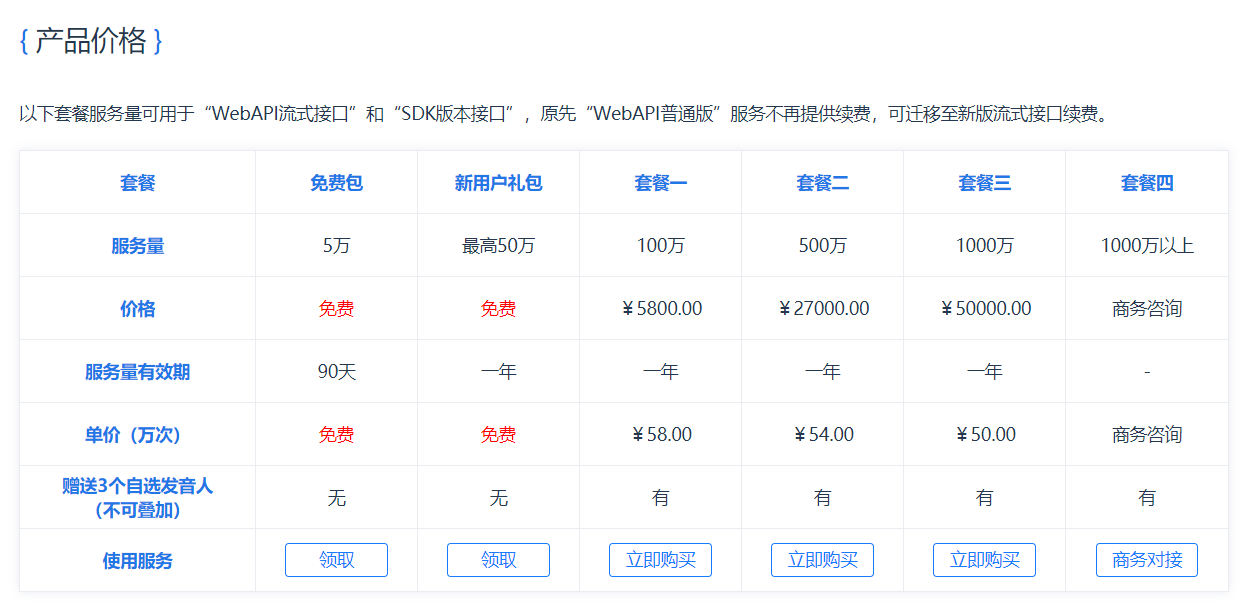

可能出现的错误及处理方法:
竞品:博物馆APP、博物官小程序
博物馆APP(简介):全球首个专业博物馆文化知识平台,汇集全球5000+著名博物馆,收集文物信息10万+件,核心亮点功能是AI文物识别、辩好、铭牌识别等智能导览、专业主播真人录音导游、每日一宝每天鉴赏一个国宝、最新博物官以疏展览资讯、线上展览等功能。其在此类产品中发展比较成熟。
博物官小程序:由腾讯艺术+行动计划推出的一款小程序,主打功能是扫描识别、语音导览、AR看展、高清作品图等等。还有开发一些小游戏增强产品趣味性。其主要优势在于是小程序,具有轻量级、利于传播的特点。
总结分析:目前市面上此种类的产品数量并不多,也存在一定的市场开发潜力。通过对此两款竞品的了解可以看到,目前此种类产品有利用人工智能技术,但是在交互方面仍然不够突出,且没有考虑到多语言多音色选择的用户需求。
V1.0
I.实现文物识别功能,能够返回文物故事
II.实现可选择语音版文物故事
III.实现可选择语言种类的语音版文物故事
V2.0
I.小规模推广,测试产品的可行性
II.在用户使用过程中收集输入图片数据及反馈缺失数据,不断丰富数据库
III.在用户使用过程中收集各方面反馈,了解用户需求,完善基础功能
V3.0
I.开始进行较大规模的市场推广,吸引大量用户
II.与博物馆进行更多合作,如开设线上文创产品商城等等
V4.0
I.继续进行产品优化,提高识别精确度和丰富文物故事
II.开启社交功能
尝试开发一些趣味小游戏,吸引更多用户
开设广告栏位收取广告费/开设线上商城模块/在后期开启一些知识付费版块
前期主要是注重拍照识别文物这一功能,收集数据丰富数据库,提高识别准确率,后期可通过开设线上商城、社交功能、小游戏等版块丰富产品,吸引更多用户。
通过本节课程的学习,我了解到设计产品时可以通过各种API接口构建和部署应用,更灵活快捷地能够获取到某些人工智能技术,节省时间成本,且能够很好地为产品进行加值,顺应API经济兴起潮流为产品进行智能加值是非常有必要的。
本产品设计目前主要采用了百度开放平台通用物体和场景识别技术、讯飞开放平台在线语音合成技术以及百度开放平台通用翻译技术,十分感谢百度开放平台和讯飞开放平台提供的技术支持。同时,本产品文档还参考了国家统计局数据、同程艺龙与同程旅游联合发布的《中国博物馆主题游消费趋势报告2019》以及猎豹用户研究中心针对参观博物馆的人群的调研结果,感谢你们的数据为本产品提供了用户研究参考。也非常感谢本节课老师的指导与帮助,谢谢!
相较于迭代一,本次迭代主要是
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。