

代码拉取完成,页面将自动刷新
| language | license | size_categories | task_categories | pretty_name | dataset_info | tags | configs | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| apache-2.0 |
|
| WebInstruct |
|
|
|
Project Page: https://tiger-ai-lab.github.io/MAmmoTH2/
Paper: https://arxiv.org/pdf/2405.03548
Code: https://github.com/TIGER-AI-Lab/MAmmoTH2
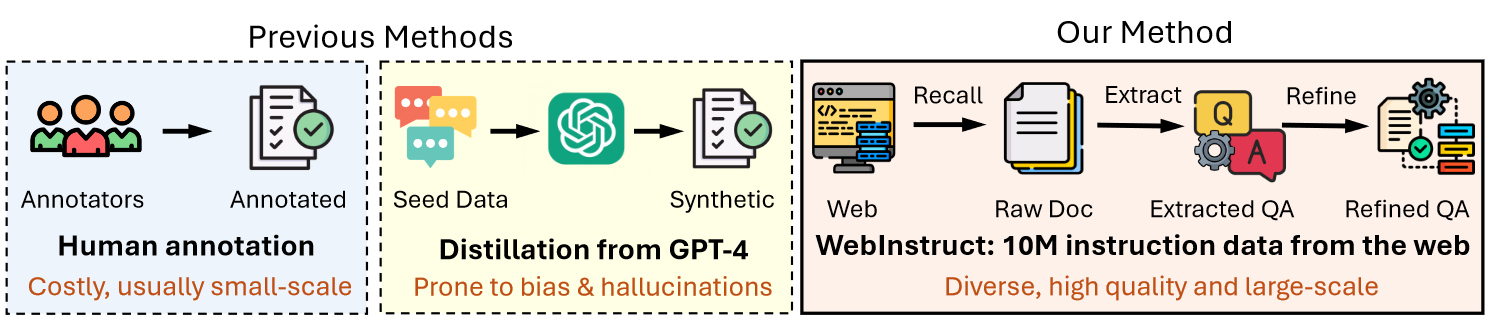
This repo partial dataset used in "MAmmoTH2: Scaling Instructions from the Web". This partial data is coming mostly from the forums like stackexchange. This subset contains very high-quality data to boost LLM performance through instruction tuning.
The field orig_question' and orig_answer' are the extracted question-answer pairs from the recalled documents. The question' and answer' are the refined version of the extracted question/answer pairs.
Regarding the data source:
| Domain | Size | Subjects |
|---|---|---|
| MathStackExchange | 1484630 | Mathematics |
| ScienceStackExchange | 317209 | Physics, Biology, Chemistry, Computer Science |
| Socratic | 533384 | Mathematics, Science, Humanties |
We propose discovering instruction data from the web. We argue that vast amounts of high-quality instruction data exist in the web corpus, spanning various domains like math and science. Our three-step pipeline involves recalling documents from Common Crawl, extracting Q-A pairs, and refining them for quality. This approach yields 10 million instruction-response pairs, offering a scalable alternative to existing datasets. We name our curated dataset as WebInstruct.
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={arXiv preprint arXiv:2405.03548},
year={2024}
}
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。