

代码拉取完成,页面将自动刷新
This chapter introduces you to the basic conception of few shot learning, and the framework of MMFewShot, and provides links to detailed tutorials about MMFewShot.
Few shot learning aims at generalizing to new tasks based on a limited number of samples using prior knowledge. The prior knowledge usually refers to a large scale training set that has many classes and samples, while the samples in new tasks are never seen in the training set. For example, in few shot image classification, a pre-trained model only can see five bird images (each class has one image and doesn't exist in the pretrained dataset) and predict the class of bird in the query image. Another example in few shot detection is that a detector needs to detect the new categories based on a few instances.
In summary, few shot learning focus on two aspects:
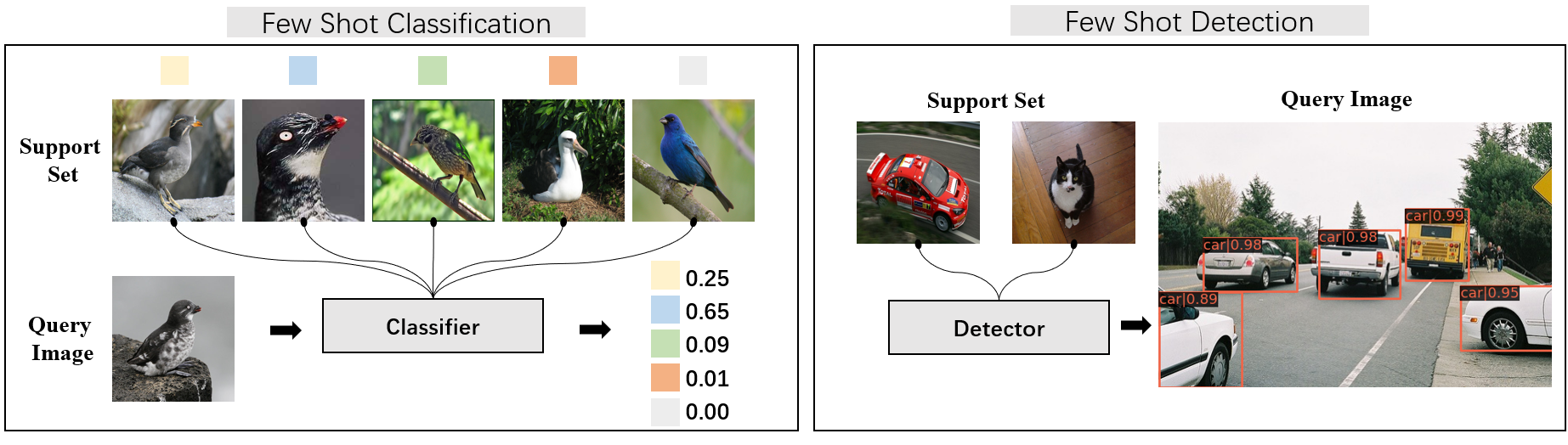
The classes of a dataset will be divided into three disjoint groups: train, test and val set. The evaluation also called meta test, will randomly sample (N way x K shot) labeled support images + Q unlabeled query images from the test set to form a task and get the prediction accuracy of query images in that task. Usually, meta test will repeatedly sample numerous tasks to get a sufficient evaluation and calculate the mean and std of accuracy from all tasks.
The classes of dataset are split into two group, base classes and novel classes. The training set contains all the annotations from base classes and a few annotations from novel classes. The novel classes performance (mAP or AP50) on test set are used for evaluating a few shot detector.
We will introduce a simple baseline for all the few shot learning tasks to further illustrate how few shot learning work. The most obvious pipeline is fine-tuning. It usually consists of two steps: train a model on a large scale dataset and then fine-tune on few shot data. For image classification, we first pretrain a model with training set using cross-entropy loss, and then we can transfer the backbone and fine tune a new classification head. For detection, we can first pretrain a faster-rcnn on training set, and then fine tune a new bbox head on a few instances to detect the novel class. In many cases, the fine-tuning is a simple but effective strategy for few shot learning.
MMFewShot is the first toolbox that provides a framework for unified implementation and evaluation of few shot classification and detection methods, and below is its whole framework:

MMFewShot consists of 4 main parts, datasets, models, core and apis.
datasets is for data loading and data augmentation. In this part,
we support various datasets for classification and detection algorithms,
useful data augmentation transforms in pipelines for pre-processing image
and flexible data sampling in datasetswrappers.
models contains models and loss functions.
core provides evaluation tools and customized hooks for model training and evaluation.
apis provides high-level APIs for models training, testing, and inference.
Here is a detailed step-by-step guide to learn more about MMFewShot:
For installation instructions, please see install.
get_started is for the basic usage of MMFewShot.
Refer to the below tutorials to dive deeper:
Few Shot Classification
Few Shot Detection
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。









